本文主要是介绍YOLOv8检测LUNA16肺结节实战(二):开始训练,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
说明:训练的过程,参考了DeepLung的训练形式,进行交叉训练。但不太明白,交叉训练有什么意义和优势?欢迎大家告知。
1、将注释文件(.xml)转化为YOLO格式:xml2txt.py
classes = ["nodule"]# 定义一个函数,将坐标信息转换为YOLO格式
def convert(size, box):dw = 1./(size[0])dh = 1./(size[1])x = (box[0] + box[1])/2.0 - 1y = (box[2] + box[3])/2.0 - 1w = box[1] - box[0]h = box[3] - box[2]x = x * dww = w * dwy = y * dhh = h * dhreturn x, y, w, h# 定义一个函数,接受 XML 文件和输出的文本文件作为参数
def convert_annotation(xml_file, txt_file):in_file = open(xml_file, 'r') # 打开 XML 文件,'r' 表示读取模式out_file = open(txt_file, 'w') # 打开输出的文本文件,'w' 表示写入模式tree = ET.parse(in_file) # 使用 ElementTree 解析 XML 文件root = tree.getroot() # 获取 XML 树的根节点size = root.find('size') # 在根节点中找到 'size' 元素w = int(size.find('width').text) # 获取图像宽度h = int(size.find('height').text) # 获取图像高度# 遍历 XML 文件中的每个 'object' 元素for obj in root.iter('object'):difficult = 0 # difficult默认为0cls = obj.find('name').text # 获取 'name' 元素的文本内容,即物体类别if cls not in classes or int(difficult)==1:continuecls_id = classes.index(cls) # 获取类别在类别列表中的索引xmlbox = obj.find('bndbox') # 获取 'bndbox' 元素b = (float(xmlbox.find('xmin').text),float(xmlbox.find('xmax').text),float(xmlbox.find('ymin').text),float(xmlbox.find('ymax').text)) # 获取边界框坐标信息# 调用 convert 函数,将坐标信息转换为YOLO格式bb = convert((w, h), b)# 将转换后的信息写入输出文本文件out_file.write(f"{cls_id} {' '.join(map(str, bb))}\n")in_file.close() # 关闭输入文件out_file.close() # 关闭输出文件# 指定 bsse 文件目录和 base 保存目录
xml_base_dir = r'/media/bsuo/Seagate/CT_image/LUNA_YOLOv8/data/'
save_base_dir = r'/media/bsuo/Seagate/CT_image/LUNA_YOLOv8/data/'# 历遍所有子集,生成*.txt文件
for subset_num in range(10):# 获取文件列表xml_files = glob(os.path.join(xml_base_dir, "subset{}".format(subset_num), "annotations", "*.xml"))print(xml_files)# 指定保存路径save_dir = os.path.join(save_base_dir, "subset{}/".format(subset_num), "labels")# 如果保存路径不存在,则创建if not os.path.exists(save_dir):os.makedirs(save_dir)# 遍历 XML 文件列表中的每个文件for xml_file in xml_files:# 调用 convert_annotation 函数,将 XML 转换为 YOLO 格式,并保存到指定目录convert_annotation(xml_file, os.path.join(save_dir, os.path.basename(xml_file)[:-3] + 'txt'))2、生成训练集、测试集、验证集:config_training0.py - config_training9.py
# 指定训练集、验证集、测试集和保存文件夹路径
train_folder_list = ['/media/bsuo/Seagate/CT_image/LUNA_YOLOv8/data/subset1/images','/media/bsuo/Seagate/CT_image/LUNA_YOLOv8/data/subset2/images','/media/bsuo/Seagate/CT_image/LUNA_YOLOv8/data/subset3/images','/media/bsuo/Seagate/CT_image/LUNA_YOLOv8/data/subset4/images','/media/bsuo/Seagate/CT_image/LUNA_YOLOv8/data/subset5/images','/media/bsuo/Seagate/CT_image/LUNA_YOLOv8/data/subset6/images','/media/bsuo/Seagate/CT_image/LUNA_YOLOv8/data/subset7/images','/media/bsuo/Seagate/CT_image/LUNA_YOLOv8/data/subset8/images','/media/bsuo/Seagate/CT_image/LUNA_YOLOv8/data/subset9/images']
val_data_path = r'/media/bsuo/Seagate/CT_image/LUNA_YOLOv8/data/subset0/images'
test_data_path = r'/media/bsuo/Seagate/CT_image/LUNA_YOLOv8/data/subset0/images'
output_dir = r"/media/bsuo/Seagate/CT_image/LUNA_YOLOv8/training/subset0/"
os.makedirs(output_dir, exist_ok=True) # 如果保存路径不存在,则创建# 获取文件夹中所有图片文件的路径
image_train_paths = []
for folder in train_folder_list:image_train_paths.extend([os.path.join(folder, file) for file in os.listdir(folder) if file.endswith(('.jpg', '.png', '.jpeg'))])
image_val_paths = [os.path.join(val_data_path, file) for file in os.listdir(val_data_path) iffile.endswith(('.jpg', '.png', '.jpeg'))]
image_test_paths = [os.path.join(test_data_path, file) for file in os.listdir(test_data_path) iffile.endswith(('.jpg', '.png', '.jpeg'))]# 指定保存路径
output_train_file = os.path.join(output_dir, "train.txt")
output_val_file = os.path.join(output_dir, "val.txt")
output_test_file = os.path.join(output_dir, "test.txt")# 将训练集每个图片的路径写入文本文件
with open(output_train_file, 'w') as file:for path in image_train_paths:file.write(path + '\n')
print(f"图片路径已保存到 {output_train_file}")# 将验证集每个图片的路径写入文本文件
with open(output_val_file, 'w') as file:for path in image_val_paths:file.write(path + '\n')
print(f"图片路径已保存到 {output_val_file}")# 将测试集每个图片的路径写入文本文件
with open(output_test_file, 'w') as file:for path in image_test_paths:file.write(path + '\n')
print(f"图片路径已保存到 {output_test_file}")修改以上代码的文件夹路径,生成10个训练集,进行交叉验证
3、修改配置文件:config.yaml
找到配置文件:/home/bsuo/miniconda3/envs/yolov8/lib/python3.8/site-packages/ultralytics/cfg/datasets/coco128.yaml
复制配置文件到:/media/bsuo/Seagate/CT_image/LUNA_YOLOv8/training/subset0/
修改配置文件名为:config.yaml
修改配置文件内容:主要是train.txt、val.txt和test.txt文件路径,以及检测的names
# YOLOv8 Configuration File
train: /media/bsuo/Seagate/CT_image/LUNA_YOLOv8/training/subset0/train.txt
val: /media/bsuo/Seagate/CT_image/LUNA_YOLOv8/training/subset0/val.txt
test: /media/bsuo/Seagate/CT_image/LUNA_YOLOv8/training/subset0/test.txt# Classes
names:0: nodule重复以上步骤,让每个subset子文件夹(subset0 - subset9)都有一个不同的config.yaml配置文件(需修改相应的路径)
4、修改模型文件:yolov8.yaml
找到模型文件:/home/bsuo/miniconda3/envs/yolov8/lib/python3.8/site-packages/ultralytics/cfg/models/v8/yolov8.yaml
在原位置,将nc参数(nc: number of classes)改成1,因为只有1个分类(nodule)
nc: 1 # number of classes5、训练自己的数据集(基于预训练模型):train_all_subsets.py
# 指定基础路径和子文件夹列表
base_path = "/media/bsuo/Seagate/CT_image/LUNA_YOLOv8/training"
base_output_path = "/media/bsuo/Seagate/CT_image/LUNA_YOLOv8"
subset_folders = [f"subset{i}" for i in range(10)]# 遍历每个子文件夹,生成文件路径并运行训练
for i, subset_folder in enumerate(subset_folders):print("开始训练:", subset_folder)# 生成对应的配置文件路径config_path = os.path.join(base_path, subset_folder, "config.yaml")# 指定运行参数command = f"yolo task=detect mode=train model=yolov8x.yaml pretrained=true data={config_path} epochs=150 batch=6 workers=12 device=0"# 创建一个新的文件夹来保存每个子集的结果output_folder = os.path.join(base_output_path, "results", subset_folder)os.makedirs(output_folder, exist_ok=True)# 运行训练命令subprocess.run(command, shell=True, cwd=output_folder)print("训练完成")训练参数:yolo task=detect mode=train model=yolov8x.yaml pretrained=true data=config.yaml epochs=150 batch=6 workers=12 device=0
6、训练结果:10组交叉训练已经全部完成,花费了大概12天时间
第1组:mAP = 81.5%
第2组:mAP = 78.7%
第3组:mAP = 81.0%
第4组:mAP = 76.2%
第5组:mAP = 79.0%
第6组:mAP = 79.0%
第7组:mAP = 75.9%
第8组:mAP = 75.0%
第9组:mAP = 70.0%
第10组:mAP = 75.8%
以下是第1组训练的mAP: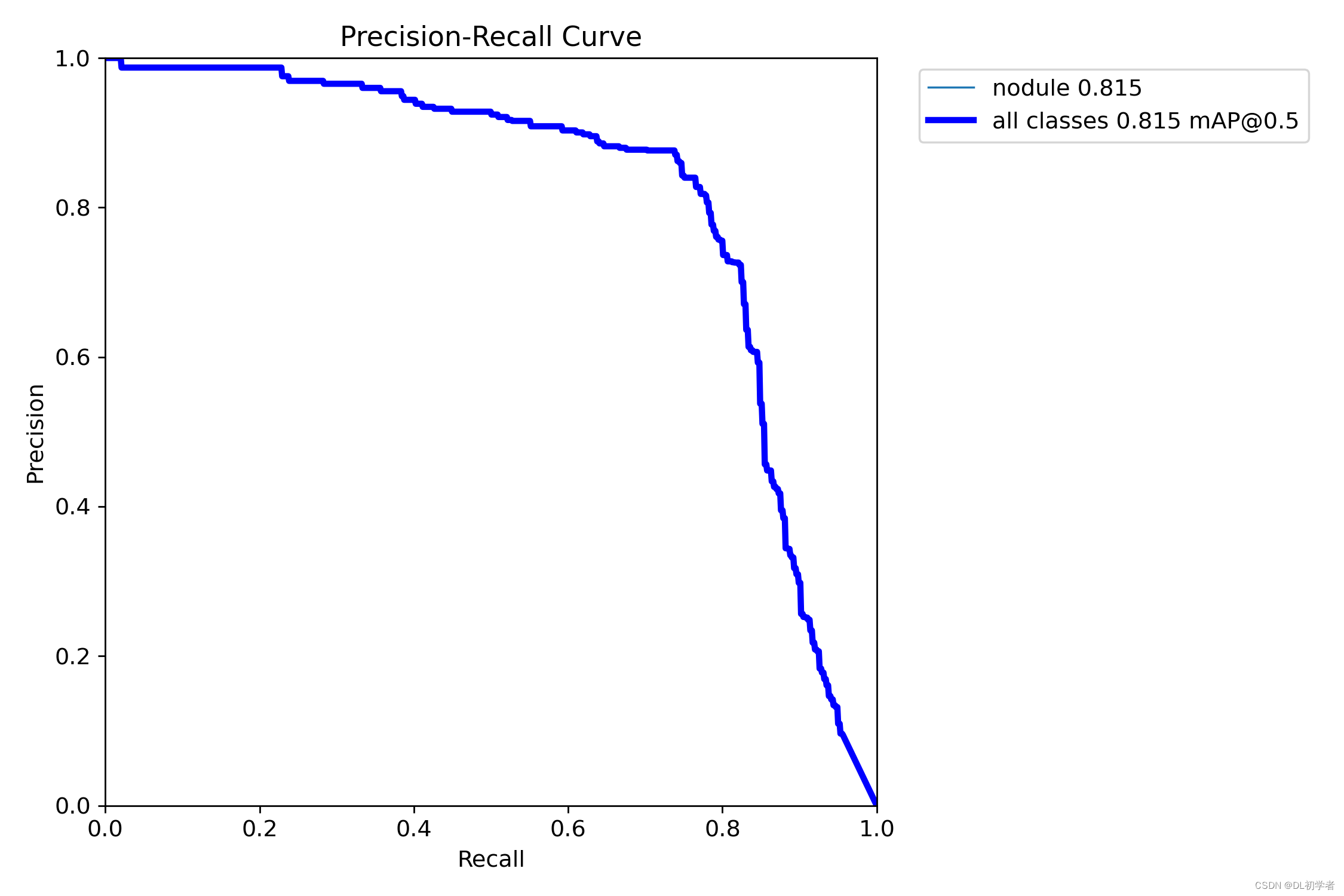
下一步,将想办法改进代码,希望能获得一个更好的训练结果。
这篇关于YOLOv8检测LUNA16肺结节实战(二):开始训练的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






