本文主要是介绍Occupancy Head 以 Surroundocc 为例,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Surroundocc framework
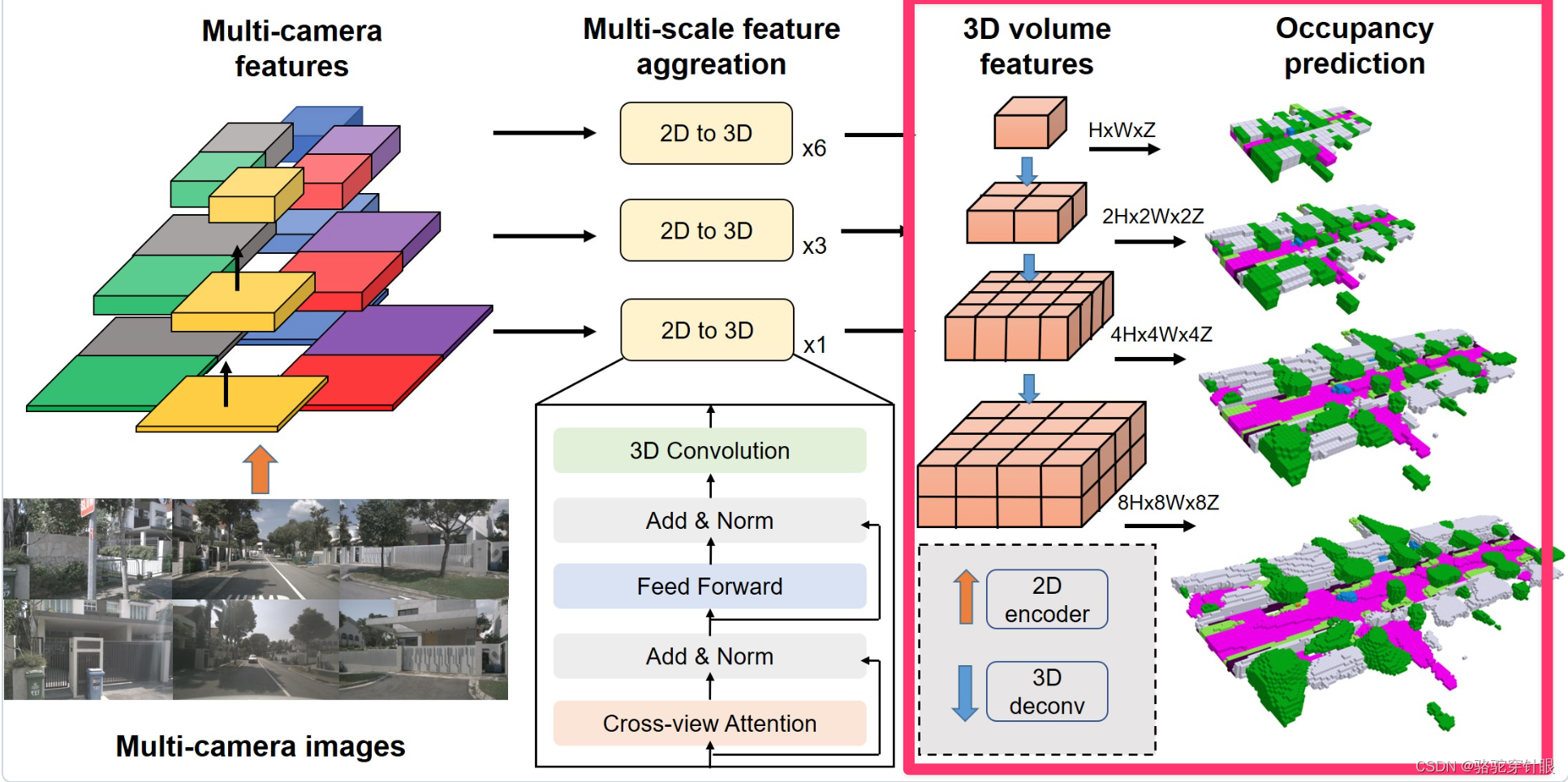
让我们以SurroundOcc为例,详细探讨整个处理流程,以便大家更好地理解Occupancy HEAD的概念。
-
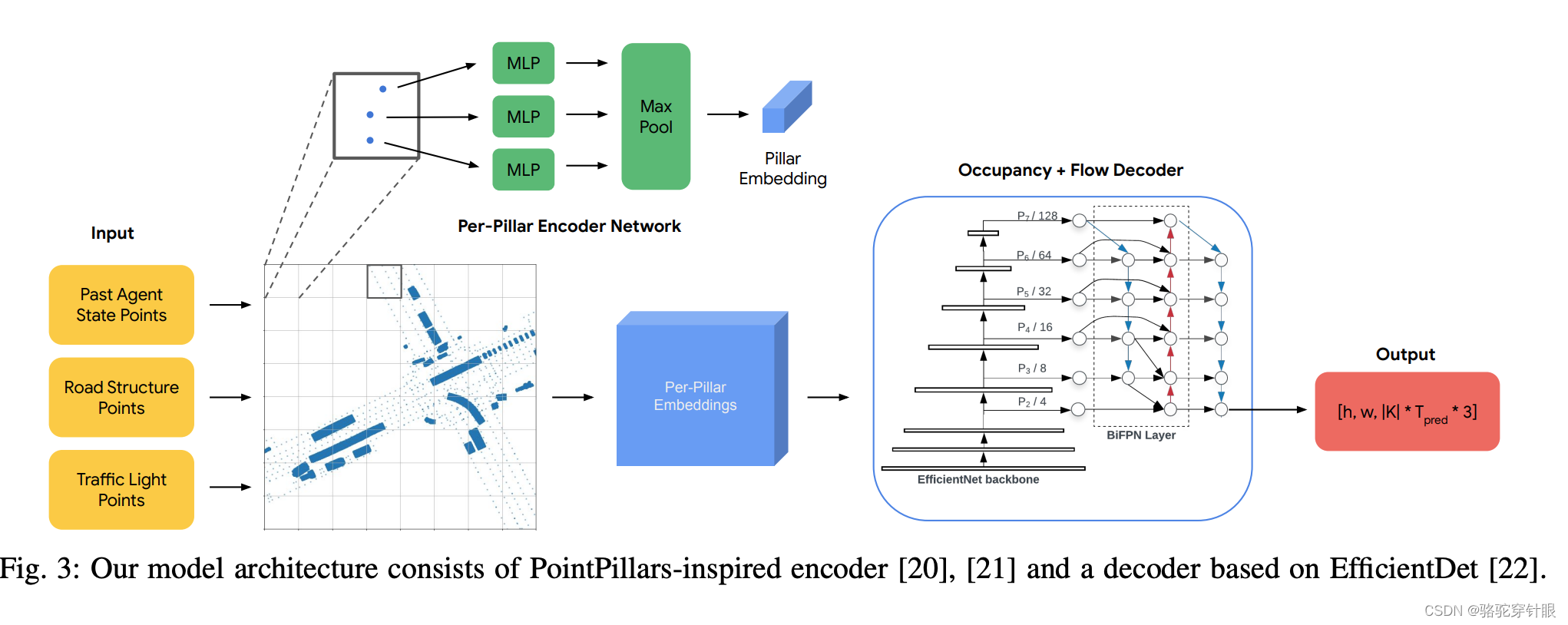
在流程的最左端,我们有多摄像头特征(Multi-camera features),这对应于我们先前提到的图像视图编码器(Image-View Encoder)。这实际上是类似于U-net的结构,用于多尺度RGB图像的二维特征提取。简而言之,它通过深度学习的方法,从不同尺度上抽取图像的关键特征。
-
流程的中间部分是多尺度特征聚合(Multi-scale Feature Aggregation),这对应于我们之前描述的视图变换器(View Transformer)和占用率编码器(Occupancy Encoder)。在这一步骤中,每个从二维到三维的转换都是通过跨视图注意力(Cross-view Attention)机制实现的,该机制将二维特征转换为三维特征。接下来,通过前馈网络(Feed Forward)和三维卷积(3D Convolution)来聚合邻近的特征。这一复杂的过程涉及到了从不同视图中提取并整合信息。和 bevfromer 相似
-
在得到多尺度的三维特征后,我们进入了流程中的最后一个部分,即之前提到的占用率头(Occupancy Head)。在这一部分,通过三维反卷积(3D Deconvolution)来聚合特征,并进行多尺度监督。这意味着,我们不仅在不同的尺度上聚合了特征,还在这些尺度上施加了监督学习。
整体结构类似于 FPN结构
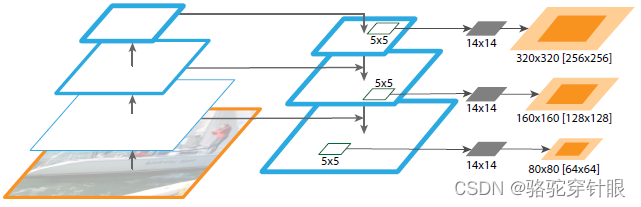
代码 projects/mmdet3d_plugin/surroundocc/loss/loss_utils.py
intersection = (nonempty_target * nonempty_probs).sum()precision = intersection / nonempty_probs.sum()recall = intersection / nonempty_target.sum()spec = ((1 - nonempty_target) * (empty_probs)).sum() / (1 - nonempty_target).sum()return (F.binary_cross_entropy(precision, torch.ones_like(precision))+ F.binary_cross_entropy(recall, torch.ones_like(recall))+ F.binary_cross_entropy(spec, torch.ones_like(spec))
Occupancy Head - Occupancy Flow
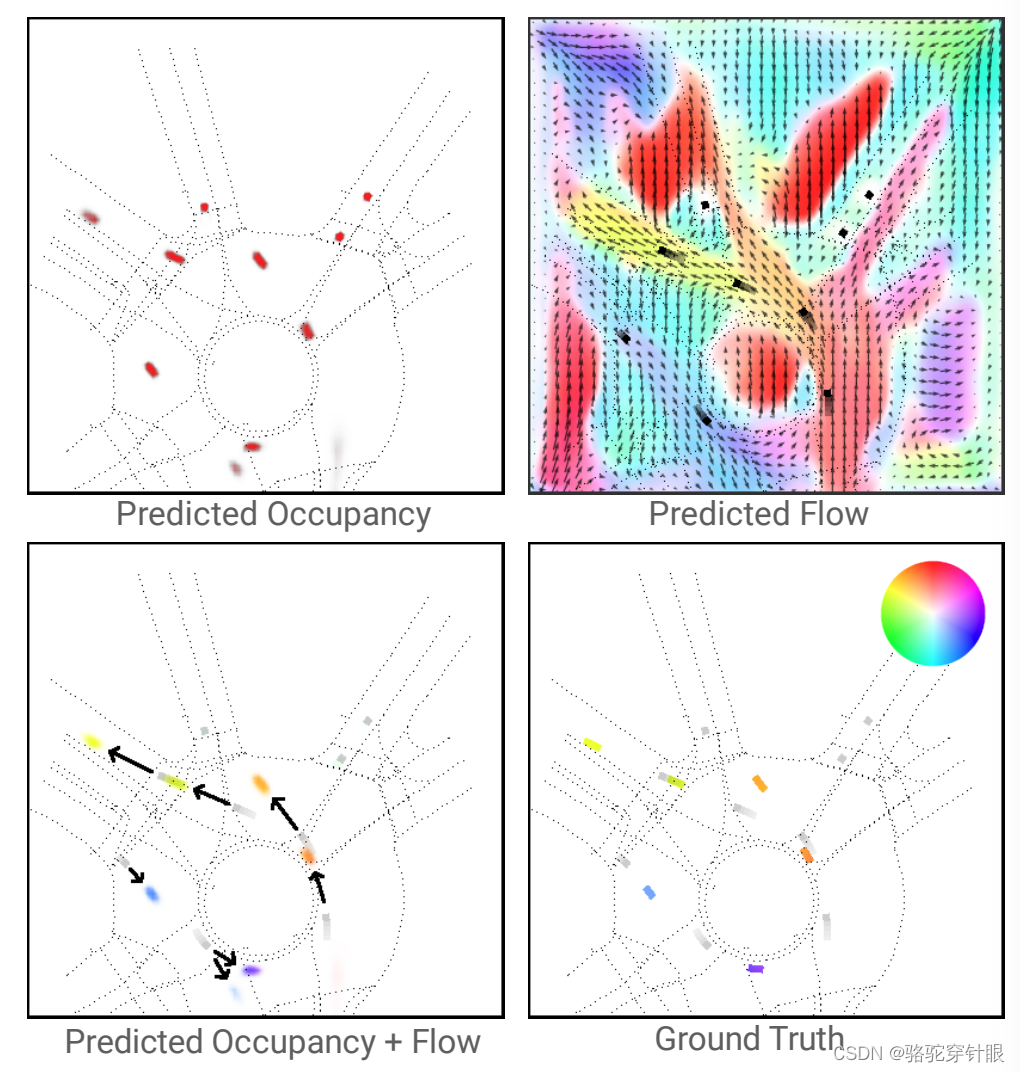
占用流(Occupancy Flow) 是一种在学术领域常见的占用网格(Occupancy HEAD)技术,虽然在工业界的应用还相对较少。它的原理与RGB图像中的光流(Optic Flow)和点云数据的场景流(Scene Flow)相似,主要用于预测未来的占用体素(Occupancy voxels)以及物体速度的估计。
类似于占用网络(Occupancy Networks),占用流技术的起源 也可以追溯到人体重建领域的研究。它最早出现在2019年的ICCV(International Conference on Computer Vision)论文《Occupancy Flow: 4D Reconstruction by Learning Particle Dynamics》中。
占用流在自动驾驶的应用 被详细介绍于2022年5月发表的论文《Occupancy Flow Fields for Motion Forecasting in Autonomous Driving》。这篇论文首次将占用流技术应用于自动驾驶领域,开辟了一个新的研究方向。
动机与创新之处:文章的作者认为,当前两种主要的动作预测方法——占用预测任务(occupancy prediction)和轨迹集预测任务(trajectory sets prediction)——可以结合起来,实现同时进行身份跟踪(id tracking)和占用预测的目标。因此,作者提出了流迹损失(flow trace loss) 来监督帧间占用的一致性,从而得到占用流场(Occupancy Flow Fields)。
文中提到的占用流预测的实验结果展示了其能够有效预测1.5秒内的动态占用情况。
论文
在探讨占用流(Occupancy Flow)技术及其在二维占用网格(2D Occupancy grids)上的应用时,值得注意的是,尽管本文研究的焦点是二维情境,但其原理与方法同样适用于三维占用体素(3D occupancy voxels)。
关于占用流相关损失(loss)的具体实现及制作地面真实值(ground truth)的方法,我们可以这样理解:
占用流相关损失的定义:
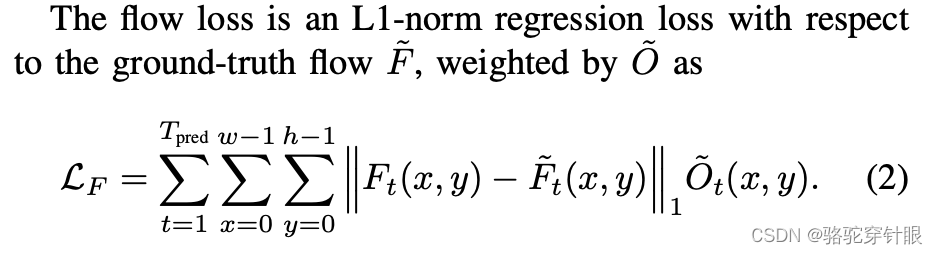
占用流迹损失(flow trace loss)的具体定义如下:首先,将通过时间变换(warp)后的占用信息与占用网络(Occupancy Networks)预测的结果进行相乘操作(这里的相乘是指在相同的(x, y)位置的值(0或1)相乘),然后,将这一结果与地面真实的占用情况(gt occupancy)进行比较。这样的比较能够有效衡量时间变换(warp)以及占用预测的精确度。
地面真实值的制作方法:
在制作占用流的地面真实值时,考虑到占用流主要关注动态目标,我们可以利用在不同时间点进行的三维检测和跟踪所得到的轨迹片段(tracklets)来确定目标的身份(ID)。然后,通过分析体素相对于三维物体中心点的位移,来确定与之对应的体素。这种方法为动态目标的占用预测提供了一种准确的制作地面真实值的手段。
L1-norm regression loss
L1范数回归损失,也称为平均绝对误差 (MAE),是衡量预测值与真实值之间差异的一种方法。其定义为:
L1损失 = ∑ |y_i - f(x_i)|
其中:
y_i 是真实值
f(x_i) 是预测值
n 是样本数量
L1范数回归损失具有以下特点:
鲁棒性强:对异常值不敏感,能够有效抑制噪声的影响。
稀疏性:L1范数回归损失会使模型参数变得稀疏,即部分参数为零。这有利于模型的解释和泛化能力。
L1范数回归损失常用于以下场景:
- 数据存在噪声
- 需要稀疏解
例如,在图像压缩领域,L1范数回归损失常用于图像去噪。
L1范数回归损失的缺点是:
- 不可导:这使得L1范数回归损失的优化问题难以求解。
- 不适用于回归问题:L1范数回归损失对异常值不敏感,这在回归问题中可能导致偏差。

这篇关于Occupancy Head 以 Surroundocc 为例的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!