本文主要是介绍吴恩达机器学习-可选实验室:简单神经网络(Simple Neural Network),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在这个实验室里,我们将使用Numpy构建一个小型神经网络。它将与您在Tensorflow中实现的“咖啡烘焙”网络相同。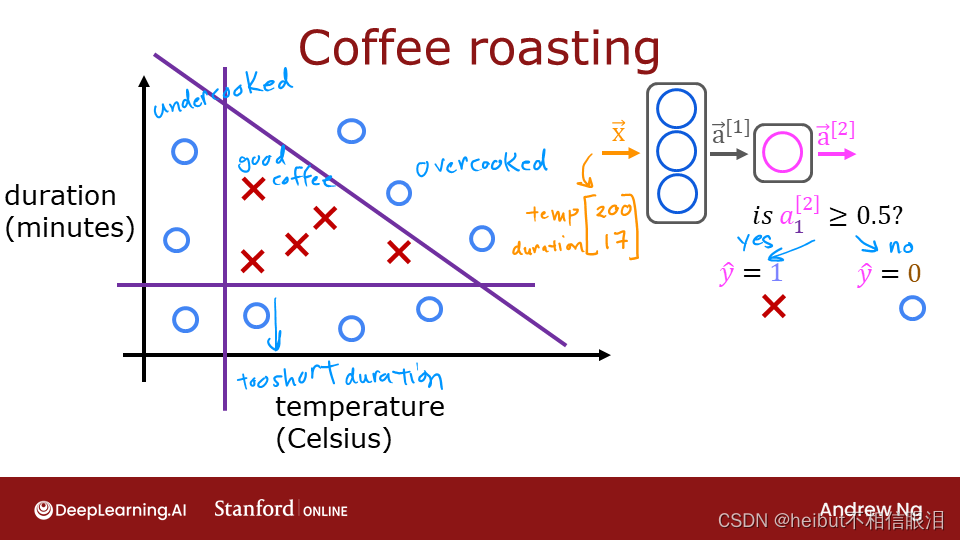
import numpy as np
import matplotlib.pyplot as plt
plt.style.use('./deeplearning.mplstyle')
import tensorflow as tf
from lab_utils_common import dlc, sigmoid
from lab_coffee_utils import load_coffee_data, plt_roast, plt_prob, plt_layer, plt_network, plt_output_unit
import logging
logging.getLogger("tensorflow").setLevel(logging.ERROR)
tf.autograph.set_verbosity(0)
数据集
这是与前一个实验室相同的数据集。
X,Y = load_coffee_data();
print(X.shape, Y.shape)

让我们在下面绘制咖啡烘焙数据。这两个功能是以摄氏度为单位的温度和以分钟为单位的持续时间。在家烤咖啡建议时间最好保持在12到15分钟之间,而温度应该在175到260摄氏度之间。当然,随着温度的升高,持续时间应该会缩短。
plt_roast(X,Y)
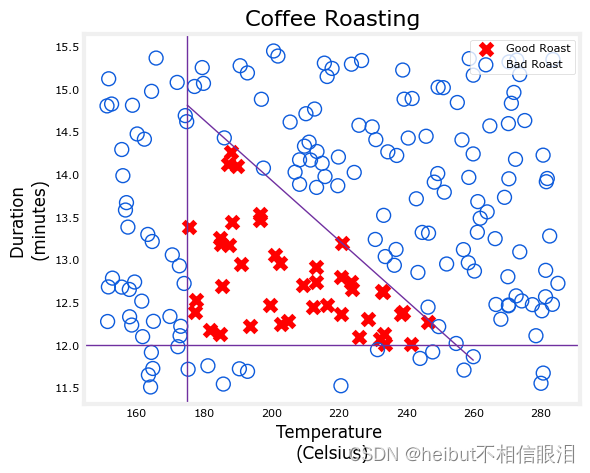
标准化数据
为了与之前的实验室相匹配,我们将对数据进行规范化。请参考该实验室了解更多详细信息
print(f"Temperature Max, Min pre normalization: {np.max(X[:,0]):0.2f}, {np.min(X[:,0]):0.2f}")
print(f"Duration Max, Min pre normalization: {np.max(X[:,1]):0.2f}, {np.min(X[:,1]):0.2f}")
norm_l = tf.keras.layers.Normalization(axis=-1)
norm_l.adapt(X) # learns mean, variance
Xn = norm_l(X)
print(f"Temperature Max, Min post normalization: {np.max(Xn[:,0]):0.2f}, {np.min(Xn[:,0]):0.2f}")
print(f"Duration Max, Min post normalization: {np.max(Xn[:,1]):0.2f}, {np.min(Xn[:,1]):0.2f}")

上面的这部分跟上一篇文章一样
Numpy模型(Numpy中的正向道具)
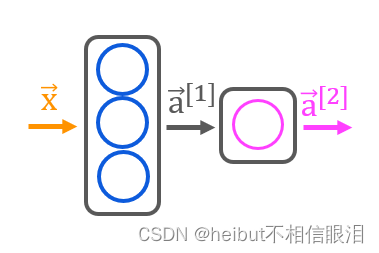
让我们构建讲座中描述的“咖啡烘焙网络”。有两层Sigmoid激活。
如讲座中所述,可以使用NumPy构建自己的密集层。然后可以利用这一点来构建多层神经网络。
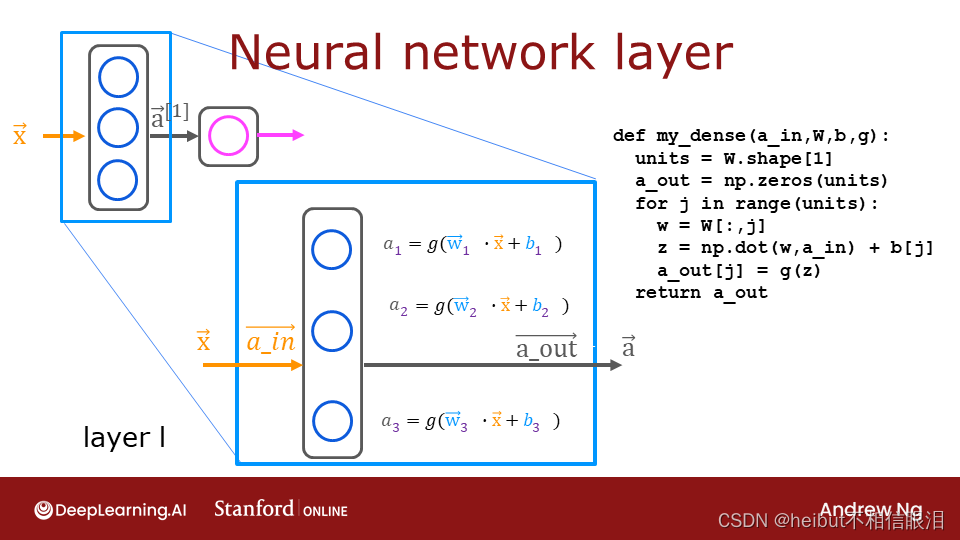
在第一个可选实验室中,您在NumPy和Tensorflow中构建了一个神经元,并注意到它们的相似性。一个层只包含多个神经元/单元。如讲座中所述,可以使用for循环访问层中的每个单元(j),并对该单元(W[:,j])执行权重的点积,并对单元(b[j])的偏差求和以形成z。然后可以将激活函数g(z)应用于该结果。让我们在下面尝试构建一个“密集层”子程序。
👇my_dense函数计算每一层的输出值
def my_dense(a_in, W, b, g):"""Computes dense layerArgs:a_in (ndarray (n, )) : Data, 1 example W (ndarray (n,j)) : Weight matrix, n features per unit, j unitsb (ndarray (j, )) : bias vector, j units g activation function (e.g. sigmoid, relu..)Returnsa_out (ndarray (j,)) : j units|"""units = W.shape[1]a_out = np.zeros(units)for j in range(units): w = W[:,j] z = np.dot(w, a_in) + b[j] a_out[j] = g(z) return(a_out)
👇下面的单元利用上面的my_dense子程序构建了一个两层神经网络。返回神经网络最终输出值。
def my_sequential(x, W1, b1, W2, b2):a1 = my_dense(x, W1, b1, sigmoid)a2 = my_dense(a1, W2, b2, sigmoid)return(a2)
我们可以在Tensorflow中复制以前实验室中训练过的权重和偏差。
W1_tmp = np.array( [[-8.93, 0.29, 12.9 ], [-0.1, -7.32, 10.81]] )
b1_tmp = np.array( [-9.82, -9.28, 0.96] )
W2_tmp = np.array( [[-31.18], [-27.59], [-32.56]] )
b2_tmp = np.array( [15.41] )
预测
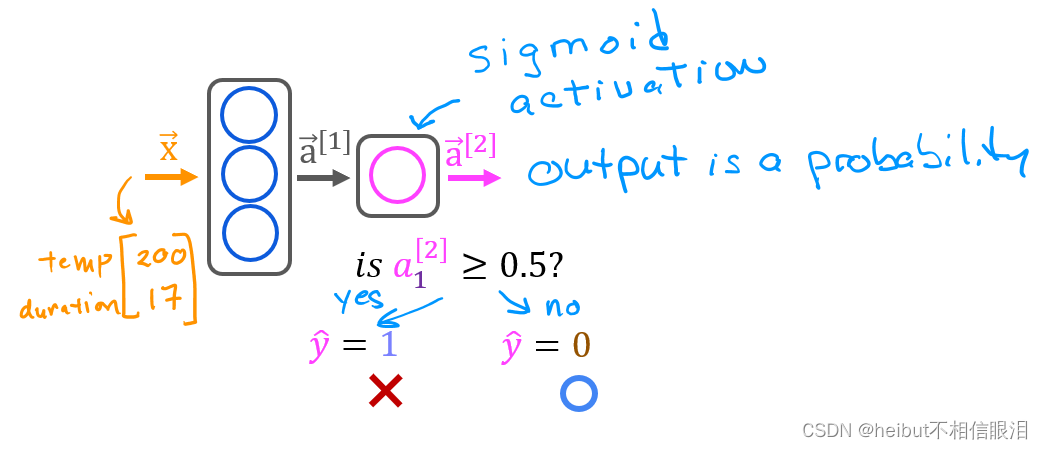
一旦你有了一个经过训练的模型,你就可以用它来进行预测。回想一下,我们模型的输出是一个概率。在这种情况下,烤得好的概率。要做出决定,必须将概率应用于阈值。在这种情况下,我们将使用0.5。
让我们从编写一个类似于Tensorflow的model.product()的例程开始。这需要一个矩阵𝑋与所有𝑚行中的示例,并通过运行模型进行预测。
my_sequential()是对一个输入进行预测,👇my_predict()是对所有的X进行预测
def my_predict(X, W1, b1, W2, b2):m = X.shape[0]p = np.zeros((m,1))for i in range(m):p[i,0] = my_sequential(X[i], W1, b1, W2, b2)return(p)
我们可以在两个例子中尝试这个例程:
👇调用函数
X_tst = np.array([[200,13.9], # postive example[200,17]]) # negative example
X_tstn = norm_l(X_tst) # remember to normalize
predictions = my_predict(X_tstn, W1_tmp, b1_tmp, W2_tmp, b2_tmp)
为了将概率转换为决策,我们应用了一个阈值:
yhat = np.zeros_like(predictions)
for i in range(len(predictions)):if predictions[i] >= 0.5:yhat[i] = 1else:yhat[i] = 0
print(f"decisions = \n{yhat}")

这可以更简洁地完成:
yhat = (predictions >= 0.5).astype(int)
print(f"decisions = \n{yhat}")

网络功能
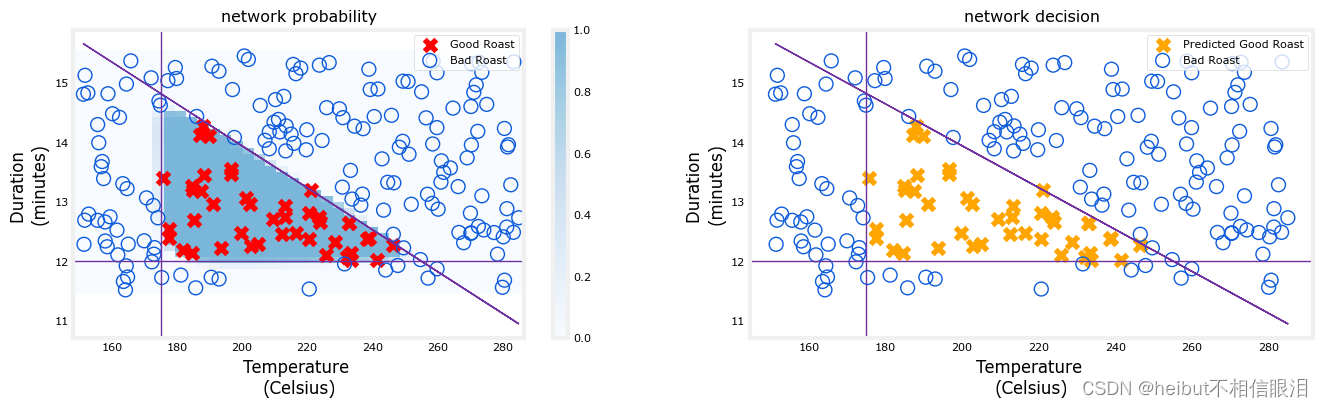
此图显示了整个网络的操作,与之前实验室的Tensorflow结果相同。左图是由蓝色阴影表示的最终层的原始输出。这覆盖在由X和O表示的训练数据上。
右图是在决策阈值之后网络的输出。这里的X和O对应于网络做出的决策。
netf= lambda x : my_predict(norm_l(x),W1_tmp, b1_tmp, W2_tmp, b2_tmp)
plt_network(X,Y,netf)
祝贺
您已经在NumPy中构建了一个小型神经网络。希望这个实验室揭示了构成神经网络一层的相当简单和熟悉的功能。
这篇关于吴恩达机器学习-可选实验室:简单神经网络(Simple Neural Network)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






