本文主要是介绍从2-3树到红黑树,B/B+/B*树,唉!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
又跟人讨论起了红黑树…于是就又扯到了2-3树,顺便再聊一聊B树…
二叉树就是2树;
三叉树就是2-3树;
四叉树就是2-3-4树;
五叉树就是2-3-4-5树;
…
N N 叉树就是2-3-4-…树;
唉…
其实,所谓的数据结构里的树,归根结底就是上面这些。然而,要想表现高逼格,总是离不开一些复杂的概念,比如红黑树,比如B+树,比如B*树…
很早以前,我写过一篇文章,描述了红黑树其实就是2-3树:
《真正理解红黑树》:https://blog.csdn.net/dog250/article/details/46665743
2015年的事了,那段时间正好在面试一家伟大的公司的好几个部门,有一天下午面试中我被要求回答红黑树的一些细节,立有间,我曰(yue,not ri)2-3树的操作换一些措辞就是红黑树,可是面试官貌似不知道我在说什么便怼我,于是我就简单说了一下什么是2-3树以及2-3树是如何变成红黑树的,就任性地离开了那幢伟大的四四方方的大楼,楼层不算太高,但很宏伟,然而也不算太矮,有院子,位于上海浦东金桥…
如果我们抛开早就已经印到脑子里的“提到树多指的是二叉树”这么一个先入为主的印象,仅仅从查找效率来考虑,那么下面的结论是明显的:
- 树越矮,查找次数越少,但在每一层所做的工作越多;
- 树越高,查找次数越多,但在每一层所做的工作越少。
考虑一棵叶子节点数位 N N 的完全树,我们可以发现,二叉树的高度是最高的。现在设树高为,则树高与树的叉数 k k 之间的关系是:
注意,这个公式中, N N 仅为叶子节点的数量,而不包括中间节点,如果把中间节点算进去,最终的树高公式就是从一个等比数列求和推导出来了。之所以这么写,是为了简化树高与的关系,使之一目了然。
保持高度 h h 的稳定性是维持查找树高效的关键,即任何时候,需要保持为可能的最小的值,并且不到万不得已的情况下,不增加 h h ,此所谓维持树的平衡。后面我们可以推论,越大,越容易保持平衡。
我感觉以上就是关于树的一切了。我们可以得到的推论非常多。
- 任何 k k 叉树仅考虑水平维度的话,元素值都是递增的
对于叉树而言,任何插入/删除操作都可以维持树的平衡
值得一提的是,树杈越多,即 k k 越大,维持平衡的操作步骤就越少,因为一个叉树的节点最多有 k−1 k − 1 个键值,假设当前节点拥有 x(x<k) x ( x < k ) , k k 越大,键值数可能的取值就越多,那么直接作为孩子加入该节点而不影响平衡性的可能性就越大(这个过程是递归的,即便在最底层不得不由于孩子已满进而增加树高,在递归向根部平衡的过程中,依然可以受益于 k k 值比较大而可以直接插入子树这件事),因此,可想而知,二叉树维持平衡是最不易的(下面有较为详细的分析),然而一些权衡使得二叉树被广泛应用。任何叉树均可以分裂成二叉树
-
- …(略)
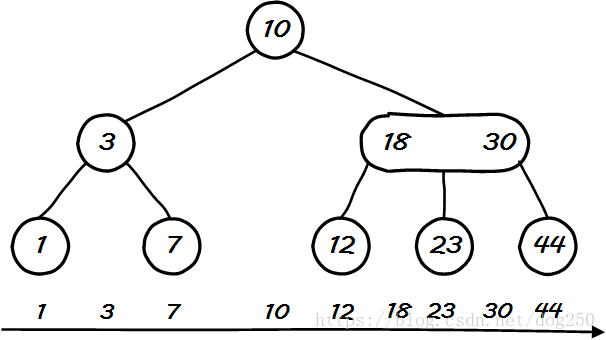
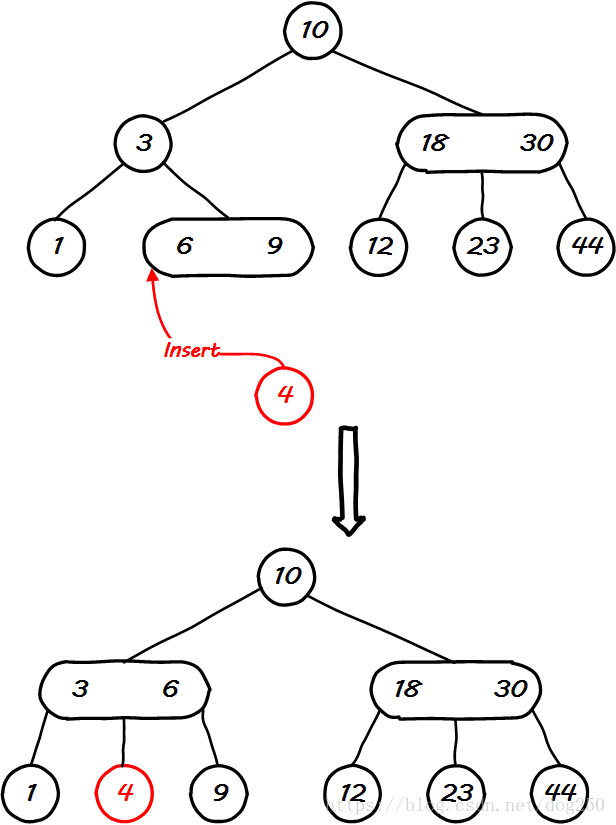
好了,理解了上述的原理和推论,接下来说一下二叉树和 k k 叉树之间的恩怨。
为什么是二叉树?在我们看来,二叉树应用地非常广泛,不管是内核或者应用程序的数据结构,还是各种考试面试题,几乎二叉树是跑不掉的,这是为什么?
答案看起来非常明确,因为二叉树非常容易分析,查找/插入/删除操作均足够简单,在代码实现上最容易。然而,代价是必须的。
代价就是二叉树维持平衡比较难!下面我们来稍微详细但不那么严谨地分析一下。
我们知道,二叉树节点有且仅有一个元素,最多仅有两个孩子节点,这意味着任何一次插入,均有50%的概率会改变整棵树或者任意子树的树高!接下来的操作便是几乎复杂的平衡操作。
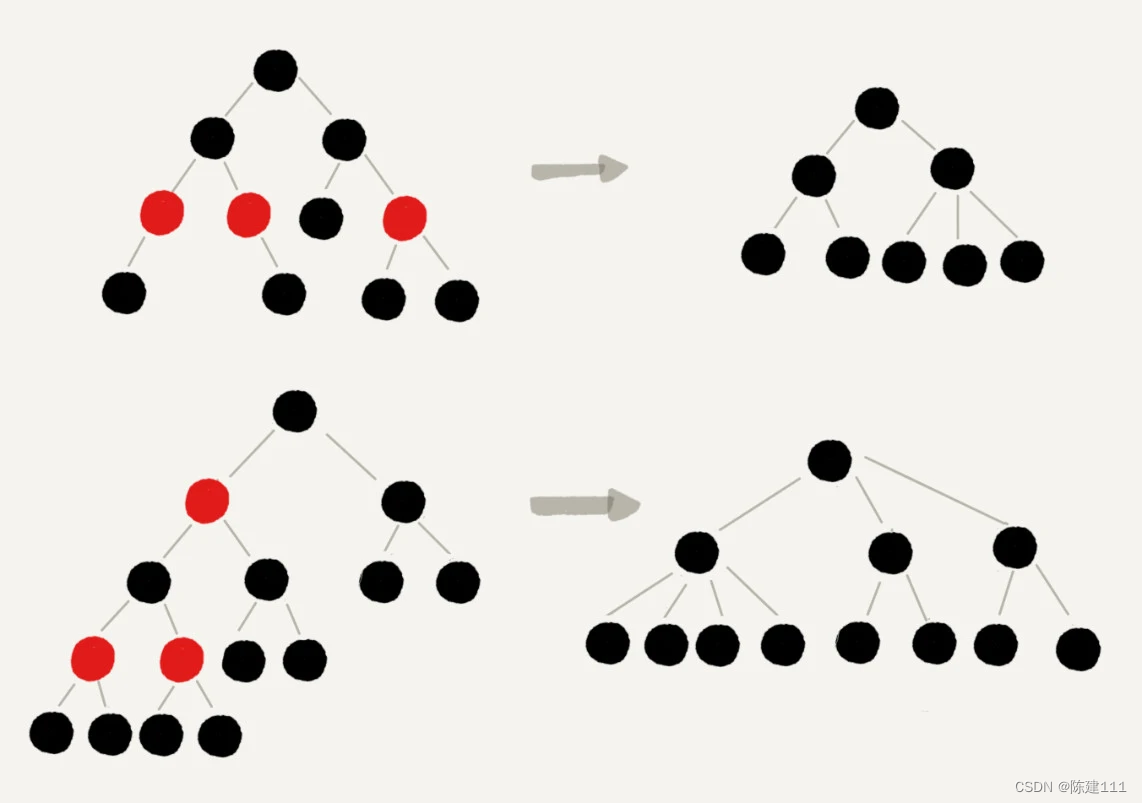
接下来的图示我们考虑新插入节点可能的位置,来大致体会一下维持树的平衡的难易程度。首先是二叉树插入新节点时树高的变化情况:
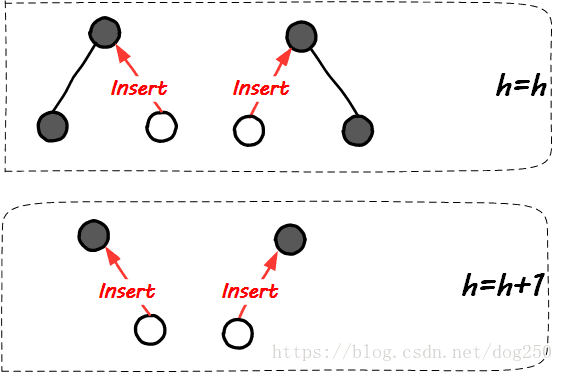
可见,很明显的在插入新节点后,50%的概率会增加树高。我们再看一下2-3树插入一个新节点时,树高的变化情况:
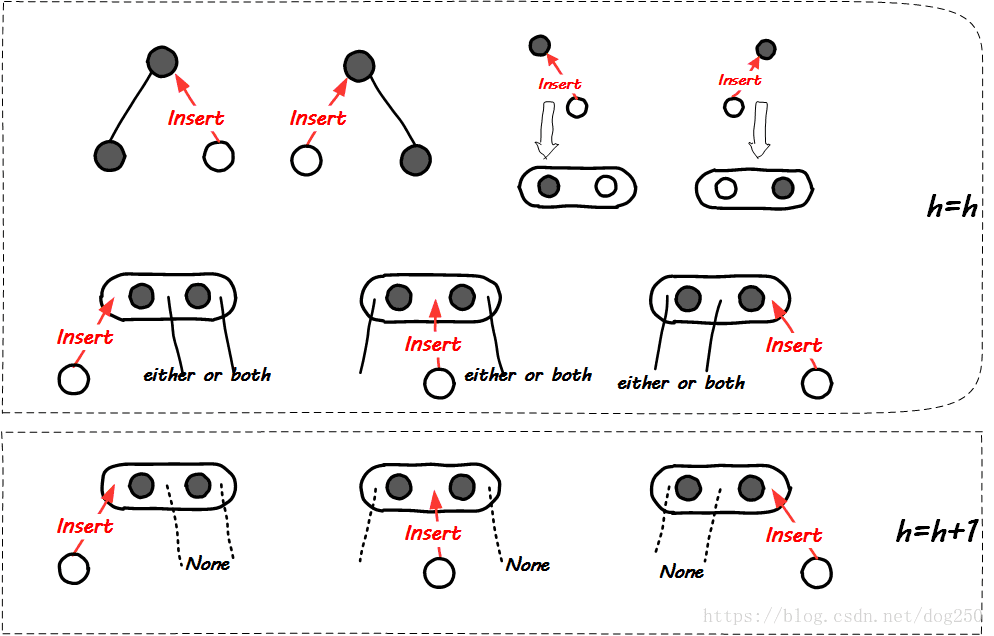
在2-3树插入新节点的情况下,大多数情况都可以维持树高不变,至少,概率小于二叉树情况下的50%。
可见,叉树在插入一个新节点时拥有更大的概率维持树的高度!
这样就解释了为什么 k k 越大,平衡代价越小,同时也解释了任何叉树都可以化为二叉树,所以,这里的要点就是构造一棵 k k 叉树来进行平衡,而当需要用来查找树时,则将其化作二叉树。权衡点就是到底是多少。
我们先考虑 k k 比较大的情况,对于这种情况,一棵平衡的叉树化为二叉树的方式有非常多的选择,且大多数对于二叉树而言是不平衡的(平衡 k k 叉树化为二叉树后,子树高度相差比较大)。理论证明(复杂的数学…)等于 3 3 的时候,效果比较好,子树的高度差在一个可控的比较小的范围,此时的平衡操作就是2-3树的平衡操作,化为二叉树后就是红黑树。
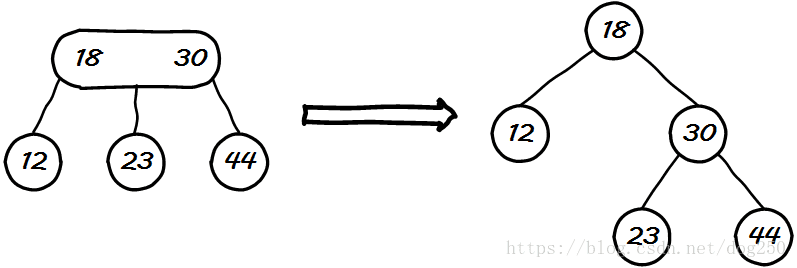
其实,我们可以从感官上很容易地体会为什么2-3树作为平衡二叉树的基础最合适。从上面解释2-3树插入一个新节点时平衡情况的图示可以看出,2-3树只有在3节点孩子为空的这唯一的情况下插入新节点会导致树高增加1,平衡操作也是异常简单和直接,只需要一个步骤,我们以最右边插入一个孩子为例,其它情况同理:

这样便确保了2-3树3节点平衡操作后直接化作了平衡二叉树,树高仅仅增加了1。2-3树是合适的,那么2-4-5树,2-3-4-5-6-7树为什么不合适呢?
首先2-3-4-5树是不合适的,因为平衡操作有未决的不确定逻辑:
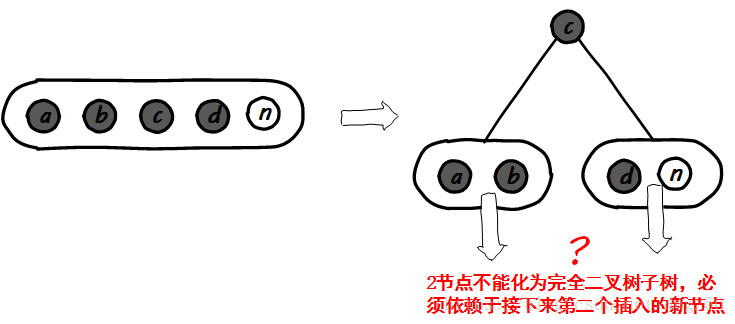
其次,可以认为2-3-4-5-6-7树是合适的,然而却需要递归执行一次2-3树的平衡操作才能化为一棵平衡二叉树,然而树高却增加了2,这便是不如2-3的地方了吧。
感官上看来,还是2-3树作为红黑树的基础,更加合适!
红黑树就是这么来的。为了构建一棵平衡的二叉树,使用2-3树做权衡,在完全平衡/不完全平衡和操作复杂/操作简单之间做权衡,虽然2-3树的平衡操作化为二叉树后不是那么完美的平衡,但也不错(子树高度差最大为一个可控的范围-红节点和黑节点的约束),然而收益却是非常简单的平衡操作!
如果说红黑树作为一种准平衡二叉树在查找,插入,删除操作中非常有用,那么对于存储而言,二叉树便不是那么灵了。
我们都知道CPU访问内存和访问磁盘等IO外设之间拥有数量级的延迟差异。因此在访问磁盘数据的时候,尽量减少访问次数便是一个必然的要求。然而同时我们也知道,访问磁盘数据避不开查找和定位操作,因此采用一棵查找树方式进行磁盘存储便是一个比较合理的策略。二叉树由于节点存储信息较少,树高比较高,因此定位数据所经历的查找次数就会比较多,非常不适合来来回回的磁盘操作,为了使得这种来回操作减少到最小,一眼望去,貌似越大,效果越好。
然而,从磁盘IO的原理上看,磁盘的IO是以Block为基本单位的,如果信息跨越了Block边界,那么将会导致不必要的磁盘IO,这是需要避免的。所以,如果 k k 过小,IO次数多,访问磁盘次数多,延迟大,而过大的话,一个节点存储的信息超过了磁盘Block的大小,也会平添磁盘IO的操作延迟,因此, k k 的值满足叉树节点保存的信息不超过磁盘Block大小是一个不错的选择。在这种情况下,树的布局和磁盘布局如下:
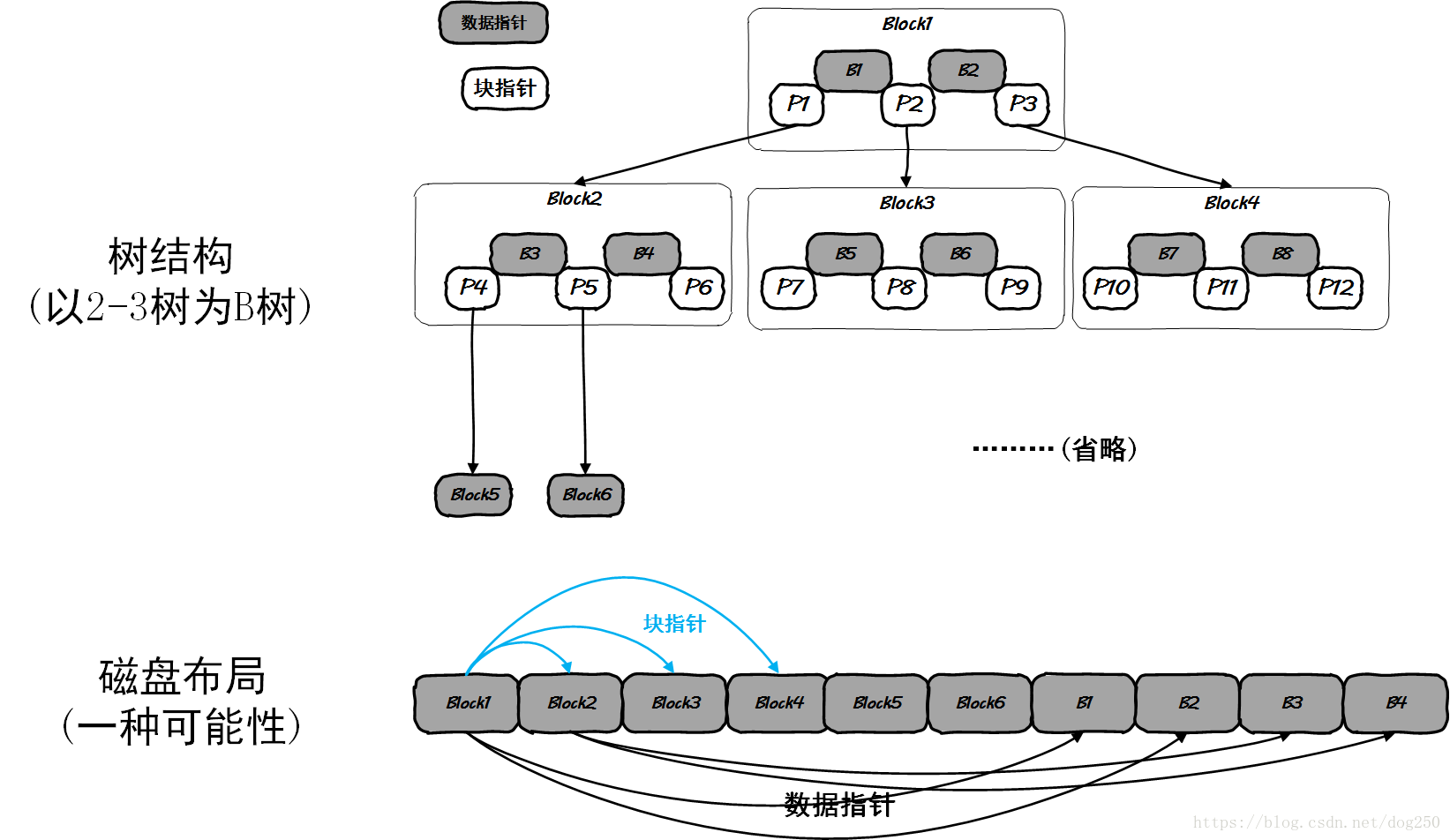
在磁盘存储的 k k 叉树中,一般叶子节点存储实际的文件数据,而中间节点则存储数据的分级索引。视数据的实际布局,比较小的顶级稀疏索引尽可能保持常驻内存来提高计算效率,因此数据存储的局部性(保持低级稠密索引的局部性)非常重要。
哦,对了,磁盘存储的叉树,就是所谓的B树。
唉,所有的树都可以归为2-3-4-5-… N N 树。
但,B+树,B*树不是!
B+和B*树只是B树在特定应用场合为了高效操作所形成的B树变体!
先看B+树。要想理解B+树的意义,还是要从B树所存在的问题入手!
在B树中,数据块的指针(或者/甚至数据块本身…)是分布在整个B树的所有节点中的,为了定位到某个数据块,不得不对该数据块在B树中的父亲节点进行读取,而整个读取这种父亲节点包含的数据块指针是没有必要的,毕竟我们只是需要该父节点所包含的指向当前孩子节点的指针而已!
这种数据块指针和指向孩子节点的指针混在在一起的节点结构很难让系统构建常驻于内存的高效索引。
为此,依照对查找树的惯用处理方案,将所有的数据块指针全部下沉到叶子节点,中间节点仅仅保存索引,这样任何查找操作都必须经由根到叶子的全部,任何中间非叶子节点可以作为完全的索引来常驻内存,结构上更加精简和规整:
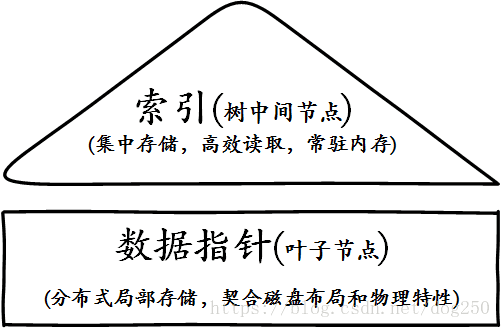
用于不同目的(分别为索引和直接寻址)的不同类型的数据可以分开集中存储,最大程度满足了局部性原则,这便是B+树的构建方式,下面是一个图示:
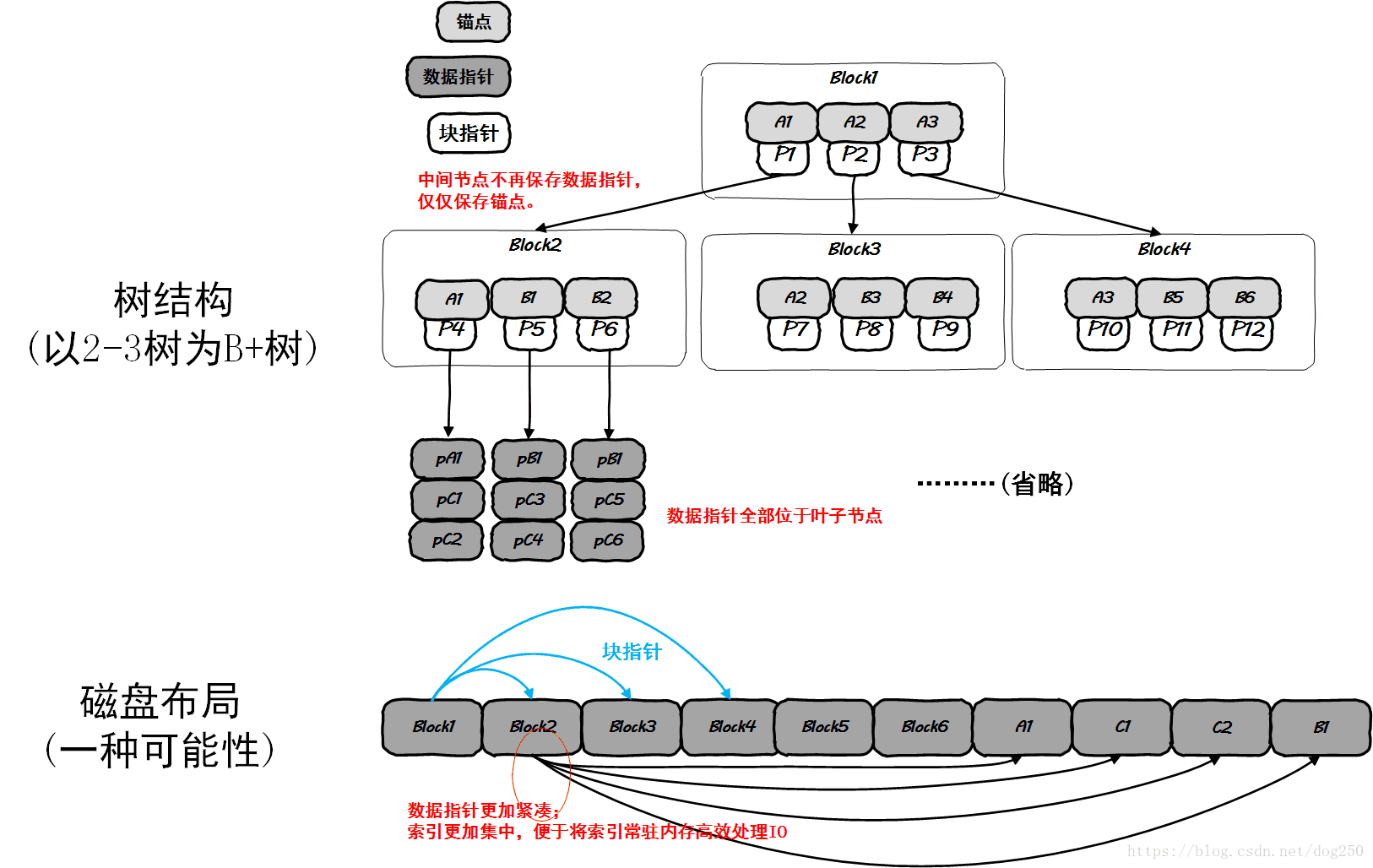
和B+树不同的地方很容易识别,将中间节点携带的数据块指针随着到达叶子节点的路径逐级下沉到叶子节点而已。可见,B+树在实际存储上要比B树的空间利用率更高。
每一个中间节点的存储减负了,负担全部集中在了叶子节点,这也达到了局部性存储的目标,整棵树完全可以作为一个独立的数据结构进行存储,顺便,这种规整的布局还非常有利于序列化操作。
此外,B+树叶子节点还有一个遍历指针,这就和树的概念无关了,本文不扯。只要记住一点,很多数据结构有些时候需要遍历,有些时候需要查找,比如Linux内核中的struct vm_area_struct,它既链接在一个list,同时又作为红黑树entry挂在红黑树上。
关于B*树,实际上也和树无关,至少和本文中抽象出来的2-3-4-5…树无关,它实际上是在B+树上更进一步的进化,其目标是在实用领域更加高效地存储和处理数据。
这就是所有,日光之下,并无新事,折腾来折腾去,就那点东西。
这篇关于从2-3树到红黑树,B/B+/B*树,唉!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!