本文主要是介绍使用tensorflow进行完整的DNN深度神经网络CNN训练完成图片识别案例,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在深度学习中,比传统的机器学习领域更成功的应用之一是图像识别。我们使用广泛使用的MNIST手写数字图像数据集。
数据集官网:
http://yann.lecun.com/exdb/mnist/
使用tensorflow进行完整的DNN深度神经网络CNN训练完成手写图片识别
MNIST_data_bak文件下载来源


程序里面介绍解释很清楚。
配图说话,自行理解>


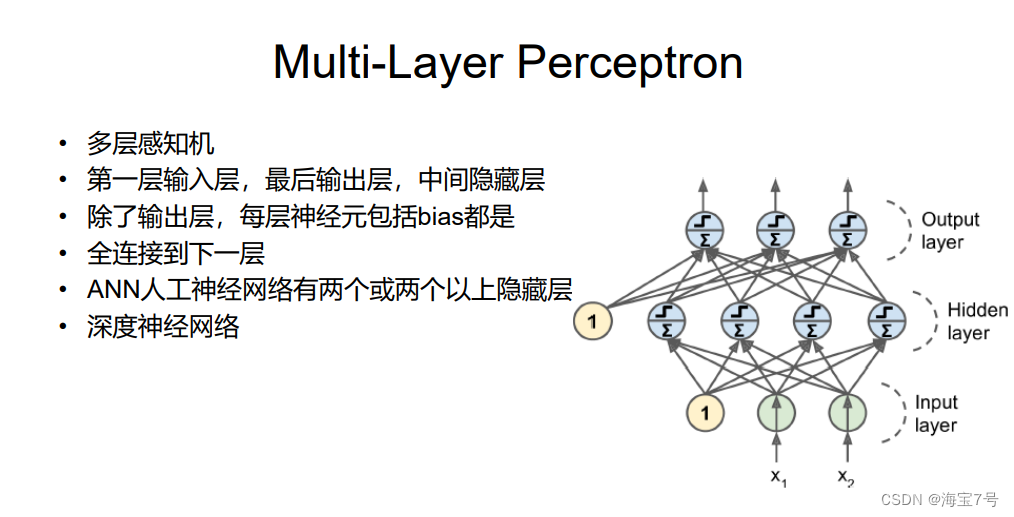


Backpropagation
反向传播,就是梯度下降使用reverse-mode autodiff
• 前向传播,就是make predictions,然后计算输出误差,然
后计算出每个神经元节点对误差的贡献
• 求贡献就是反向传播是根据前向传播的误差来求梯度
• 然后根据贡献调整原来的权重
代码如下:
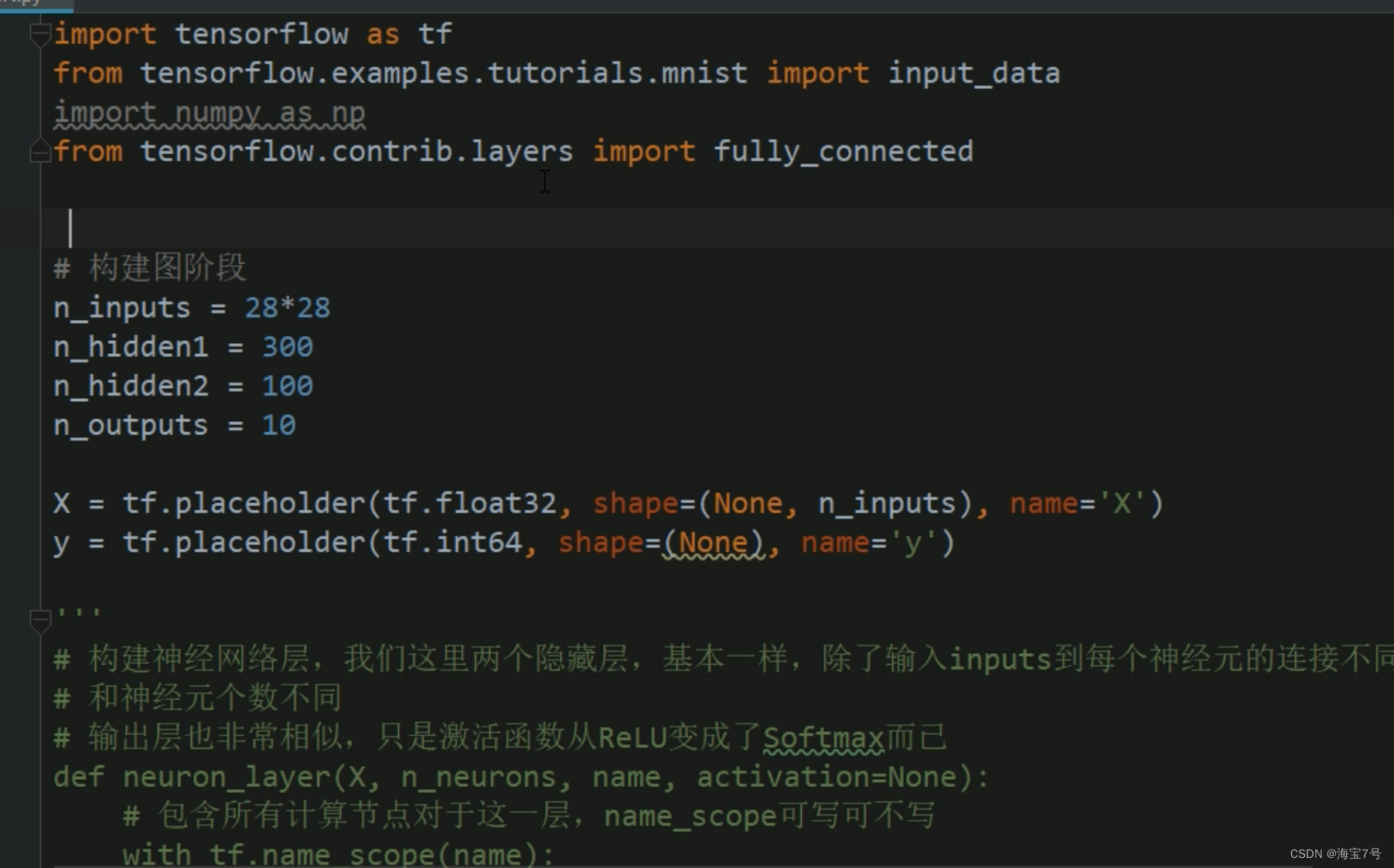
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import numpy as np
from tensorflow.contrib.layers import fully_connected# 构建图阶段
n_inputs = 28*28
n_hidden1 = 300
n_hidden2 = 100
n_outputs = 10X = tf.placeholder(tf.float32, shape=(None, n_inputs), name='X')
y = tf.placeholder(tf.int64, shape=(None), name='y')# 构建神经网络层,我们这里两个隐藏层,基本一样,除了输入inputs到每个神经元的连接不同
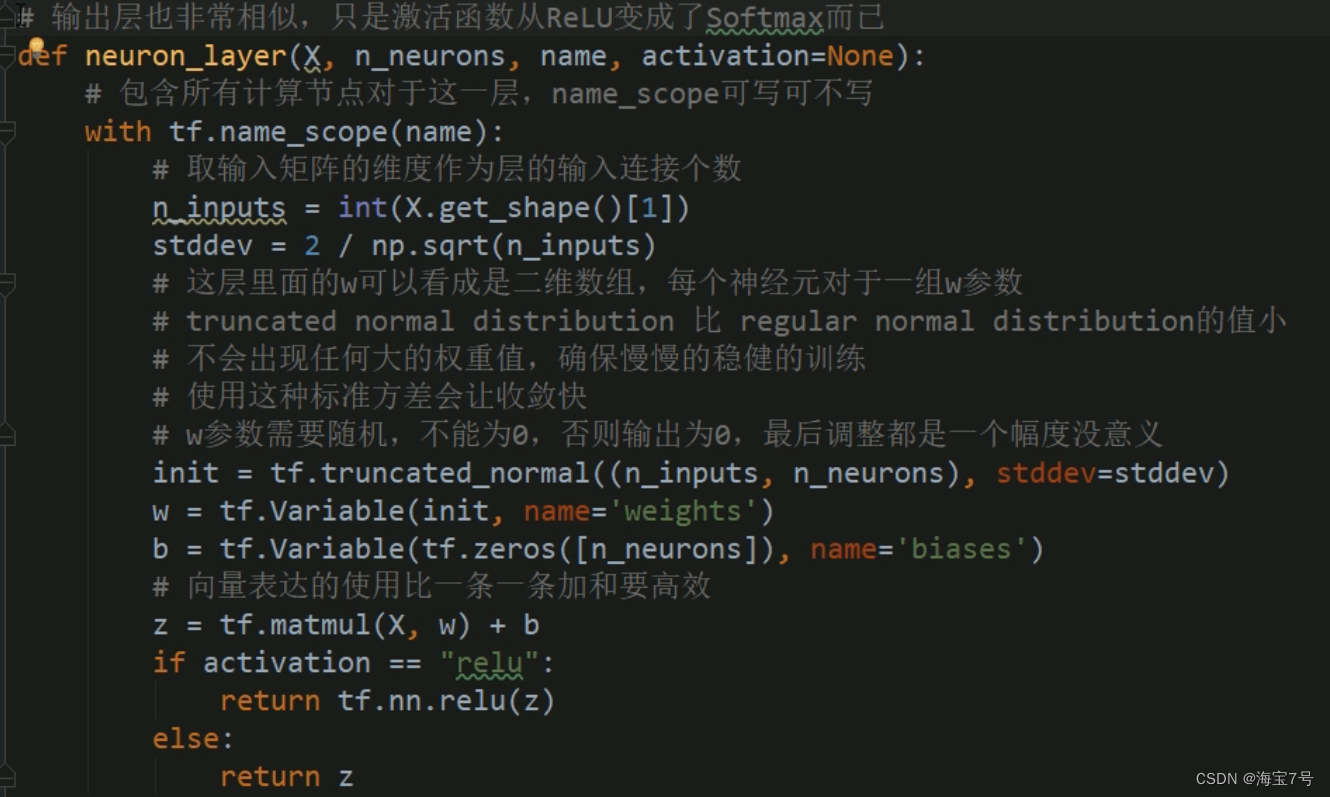
# 和神经元个数不同
# 输出层也非常相似,只是激活函数从ReLU变成了Softmax而已
def neuron_layer(X, n_neurons, name, activation=None):# 包含所有计算节点对于这一层,name_scope可写可不写with tf.name_scope(name):# 取输入矩阵的维度作为层的输入连接个数n_inputs = int(X.get_shape()[1])stddev = 2 / np.sqrt(n_inputs)# 这层里面的w可以看成是二维数组,每个神经元对于一组w参数# truncated normal distribution 比 regular normal distribution的值小# 不会出现任何大的权重值,确保慢慢的稳健的训练# 使用这种标准方差会让收敛快# w参数需要随机,不能为0,否则输出为0,最后调整都是一个幅度没意义init = tf.truncated_normal((n_inputs, n_neurons), stddev=stddev)w = tf.Variable(init, name='weights')b = tf.Variable(tf.zeros([n_neurons]), name='biases')# 向量表达的使用比一条一条加和要高效z = tf.matmul(X, w) + bif activation == "relu":return tf.nn.relu(z)else:return zwith tf.name_scope("dnn"):hidden1 = neuron_layer(X, n_hidden1, "hidden1", activation="relu")hidden2 = neuron_layer(hidden1, n_hidden2, "hidden2", activation="relu")# 进入到softmax之前的结果logits = neuron_layer(hidden2, n_outputs, "outputs")# with tf.name_scope("dnn"):
# # tensorflow使用这个函数帮助我们使用合适的初始化w和b的策略,默认使用ReLU激活函数
# hidden1 = fully_connected(X, n_hidden1, scope="hidden1")
# hidden2 = fully_connected(hidden1, n_hidden2, scope="hidden2")
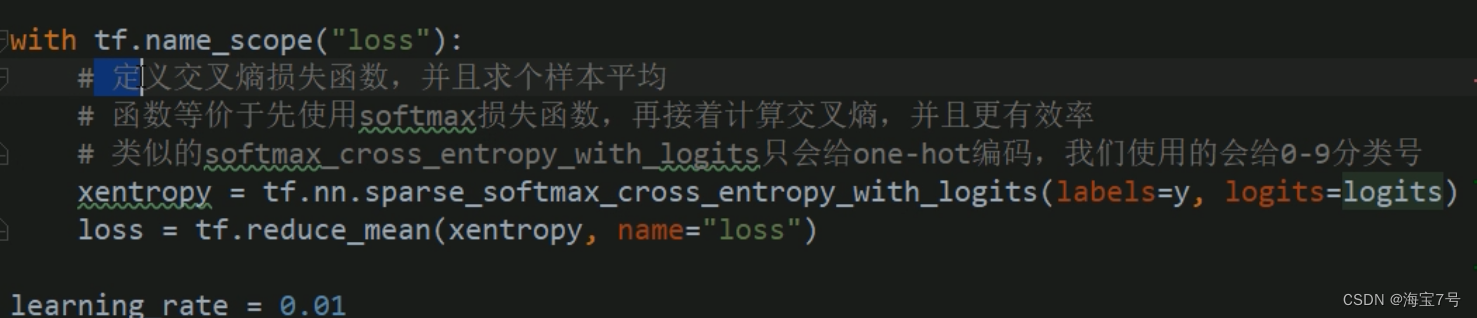
# logits = fully_connected(hidden2, n_outputs, scope="outputs", activation_fn=None)with tf.name_scope("loss"):# 定义交叉熵损失函数,并且求个样本平均# 函数等价于先使用softmax损失函数,再接着计算交叉熵,并且更有效率# 类似的softmax_cross_entropy_with_logits只会给one-hot编码,我们使用的会给0-9分类号xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y, logits=logits)loss = tf.reduce_mean(xentropy, name="loss")learning_rate = 0.01with tf.name_scope("train"):optimizer = tf.train.GradientDescentOptimizer(learning_rate)training_op = optimizer.minimize(loss)with tf.name_scope("eval"):# 获取logits里面最大的那1位和y比较类别好是否相同,返回True或者False一组值correct = tf.nn.in_top_k(logits, y, 1)accuracy = tf.reduce_mean(tf.cast(correct, tf.float32))init = tf.global_variables_initializer()
saver = tf.train.Saver()# 计算图阶段
mnist = input_data.read_data_sets("MNIST_data_bak/")
n_epochs = 400
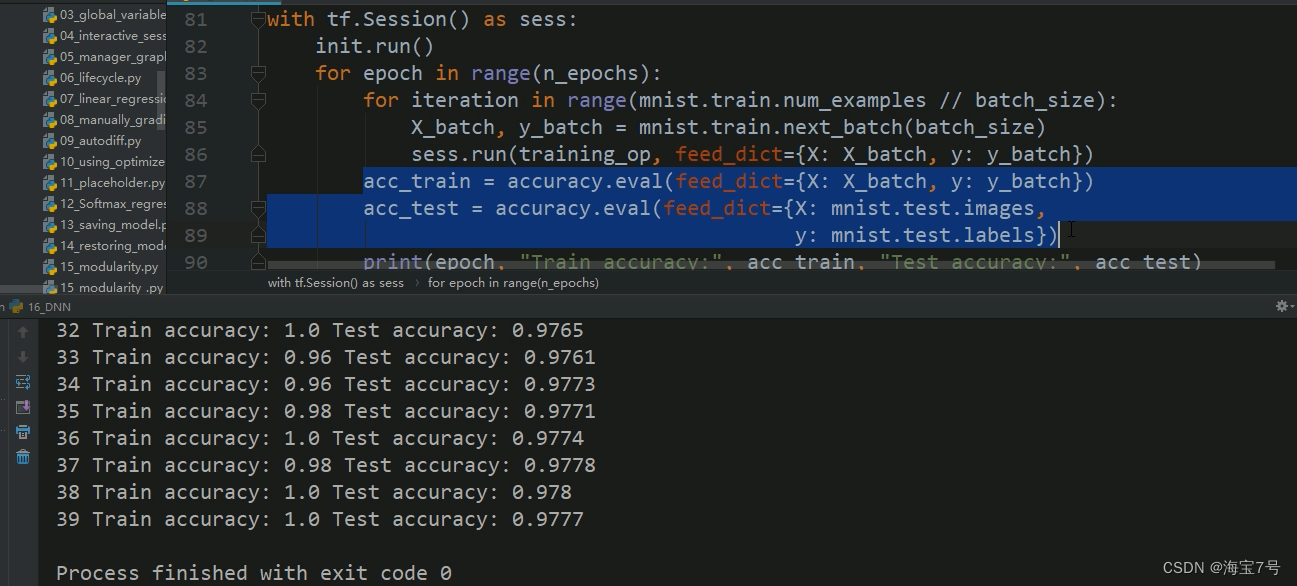
batch_size = 50with tf.Session() as sess:init.run()for epoch in range(n_epochs):for iteration in range(mnist.train.num_examples // batch_size):X_batch, y_batch = mnist.train.next_batch(batch_size)sess.run(training_op, feed_dict={X: X_batch, y: y_batch})acc_train = accuracy.eval(feed_dict={X: X_batch, y: y_batch})acc_test = accuracy.eval(feed_dict={X: mnist.test.images,y: mnist.test.labels})print(epoch, "Train accuracy:", acc_train, "Test accuracy:", acc_test)save_path = saver.save(sess, "./my_dnn_model_final.ckpt")
'''
# 使用模型预测
with tf.Session as sess:saver.restore(sess, "./my_dnn_model_final.ckpt")X_new_scaled = [...]Z = logits.eval(feed_dict={X: X_new_scaled})y_pred = np.argmax(Z, axis=1) # 查看最大的类别是哪个
'''

调优神经网络超参数

• 隐藏层数
• 对于许多问题,你可以开始只用一个隐藏层,就可以获得不错的结果,比如对于复杂的问题我们可以在
隐藏层上使用足够多的神经元就行了, 很长一段时间人们满足了就没有去探索深度神经网络
• 但是深度神经网络有更高的参数效率,神经元个数可以指数倍减少,并且训练起来也更快!
• 就好像直接画一个森林会很慢,但是如果画了树枝,复制粘贴树枝成大树,再复制粘贴大树成森林却很
快。真实的世界通常是这种层级的结构,DNN就是利用这种优势
• 前面的隐藏层构建低级的结构,组成各种各样形状和方向的线,中间的隐藏层组合低级的结构,譬如方
块、圆形,后面的隐藏层和输出层组成更高级的结构,比如面部
• 不仅这种层级的结构帮助DNN收敛更快,同时增加了复用能力到新的数据集,例如,如果你已经训练了
一个神经网络去识别面部,你现在想训练一个新的网络去识别发型,你可以复用前面的几层,就是不去
随机初始化Weights和biases,你可以把第一个网络里面前面几层的权重值赋给新的网络作为初始化,然后开始训练
• 这样网络不必从原始训练低层网络结构,它只需要训练高层结构。
• 对于很多问题,一个到两个隐藏层就是够用的了,MNIST可以达到97%当使用一个隐藏层上百个神经元
,达到98%使用两个隐藏层,对于更复杂的问题,你可以逐渐增加隐藏层,直到对于训练集过拟合。
• 非常复杂的任务譬如图像分类和语音识别,需要几十层甚至上百层,但不全是全连接,并且它们需要大
量的数据,不过,你很少需要从头训练,非常方便的是复用一些提前训练好的类似业务的经典的网络。
那样训练会快很多并且需要不太多的数据.
• 每个隐藏层的神经元个数
• 输入层和输出层的神经元个数很容易确定,根据需求,比如MNIST输入层28*28=784,输出层10
• 通常的做法是每个隐藏层的神经元越来越少,比如第一个隐藏层300个神经元,第二个隐藏层100个神经元,可是,现在更多的是每个隐藏层神经元数量一样,比如都是150个,这样超参数需要调节的就少了,正如前面寻找隐藏层数量一样,可以逐渐增加数量直到过拟合,找到完美的数量更多还是黑科技
• 简单的方式是选择比你实际需要更多的层数和神经元个数,然后使用early stopping去防止过拟合,还有L1、L2正则化技术,还有dropout
通过Regularization防止过拟合
典型的深度学习有成百上千的参数,有时甚至上百万,由
于这么多的超参数,网络有不可想象的自由度可以适应大
量各种复杂的数据集。但是这个灵活性同时意味着倾向训
练集过拟合。
Early Stopping
参考:https://www.jianshu.com/p/9ab695d91459
https://keras.io/callbacks/#earlystopping
https://zhuanlan.zhihu.com/p/186458993
https://tensorflow.google.cn/guide/migrate/early_stopping
为了避免过拟合,经常需要用到early-stopping,即在你的loss接近收敛的时候,就可以提前停止训练了
EarlyStopping是Callbacks的一种,callbacks用于指定在每个epoch开始和结束的时候进行哪种特定操作。Callbacks中有一些设置好的接口,可以直接使用,如’acc’, 'val_acc’, ’loss’ 和 ’val_loss’等等。
EarlyStopping则是用于提前停止训练的callbacks。具体地,可以达到当训练集上的loss不在减小(即减小的程度小于某个阈值)的时候停止继续训练。
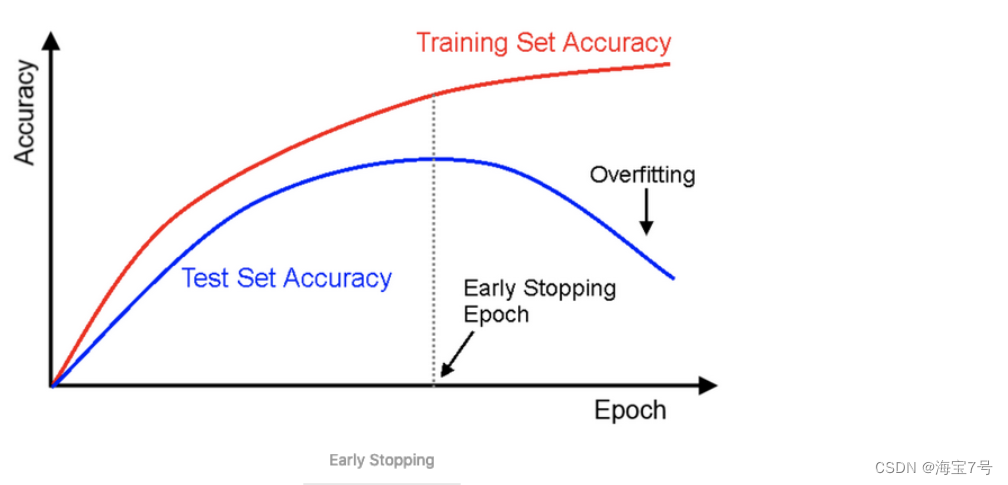
去防止在训练集上面过拟合,一个很好的手段是early
stopping,当在验证集上面开始下降的时候中断训练
• 一种方式使用TensorFlow去实现,是间隔的比如每50
steps,在验证集上去评估模型,然后保存一下快照如果输
出性能优于前面的快照,记住最后一次保存快照时候迭代
的steps的数量,当到达step的limit次数的时候,restore最
后一次胜出的快照
• 尽管early stopping实际工作做不错,你还是可以得到更好
的性能当结合其他正则化技术一起的话。
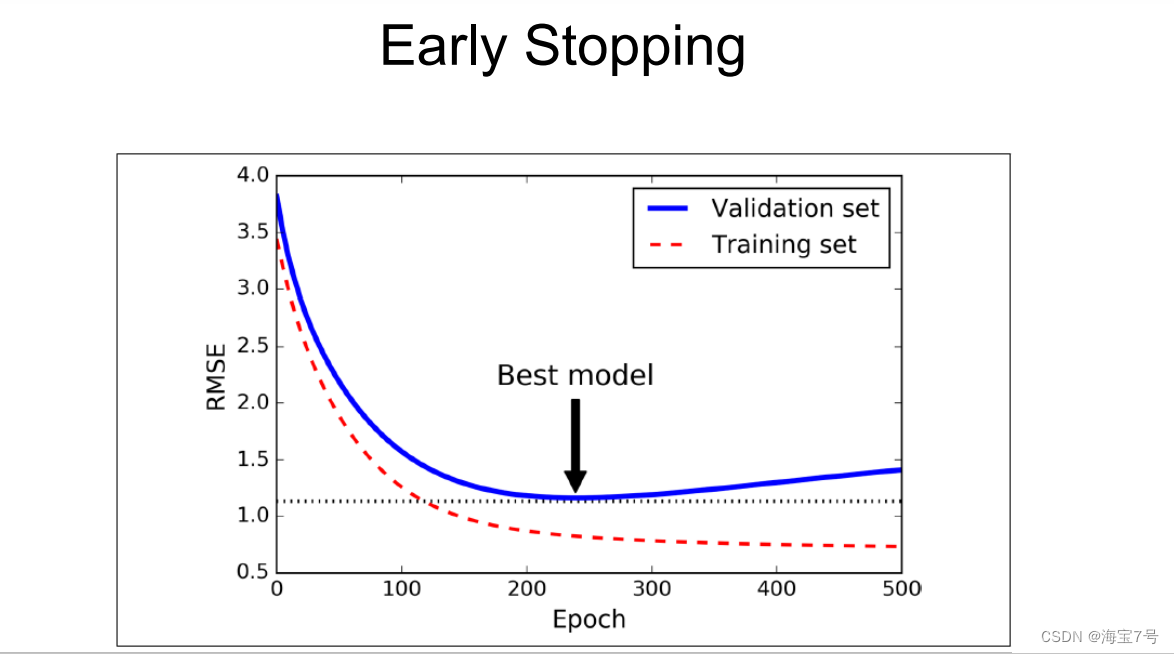
相关代码参数

L1 L2 正则化处理
• 使用L1和L2正则去限制神经网络连接的weights权重
• 一种方式去使用TensorFlow做正则是加合适的正则项到损失函数。

可是如果有很多层,上面的方式不是很方便,幸运的是,
TensorFlow提供了更好的选择,很多函数比如get_variable()或者fully_connected()接受一个 *_regularizer参数,可以传递任何以weights为参数,返回对应正则化损失的函数,1_regularizer(),l2_regularizer()和l1_l2_regularizer()函数返回这个的函数。

以上的代码神经网络有两个隐藏层,一个输出层,同时在
图里创建节点给每一层的权重去计算L1正则损失,
TensorFlow自动添加这些节点到一个特殊的包含所有正则
化损失的集合。你只需要添加这些正则化损失到整体的损
失中,不要忘了去添加正则化损失到整体的损失中,否则
它们将会被忽略。

Dropout操作
• keep_prob是保留下来的比例,1-keep_prob是dropout rate
• 当训练的时候,把is_training设置为True,测试的时候,设
置为False。
原理如图

代码如下:

调优神经网络超参数之激活函数
• 大多数情况下激活函数使用ReLU激活函数,这种激活函数
计算更快,并且梯度下降不会卡在plateaus,并且对于大
的输入值,它不会饱和,相反对比logistic function和
hyperbolic tangent function,将会饱和在1
• 对于输出层,softmax激活函数通常是一个好的选择对于分
类任务,因为类别和类别之间是互相排斥的,对于回归任
务,根本不使用激活函数
• 激活函数
• 大多数情况下激活函数使用ReLU激活函数,这种激活函数
计算更快,并且梯度下降不会卡在plateaus,并且对于大
的输入值,它不会饱和,相反对比logistic function和
hyperbolic tangent function,将会饱和在1
• 对于输出层,softmax激活函数通常是一个好的选择对于分
类任务,因为类别和类别之间是互相排斥的,对于回归任
务,根本不使用激活函数
• 大多数情况下激活函数使用ReLU激活函数,这种激活函数
计算更快,并且梯度下降不会卡在plateaus,并且对于大
的输入值,它不会饱和,相反对比logistic function和
hyperbolic tangent function,将会饱和在1
• 对于输出层,softmax激活函数通常是一个好的选择对于分
类任务,因为类别和类别之间是互相排斥的,对于回归任
务,根本不使用激活函数。
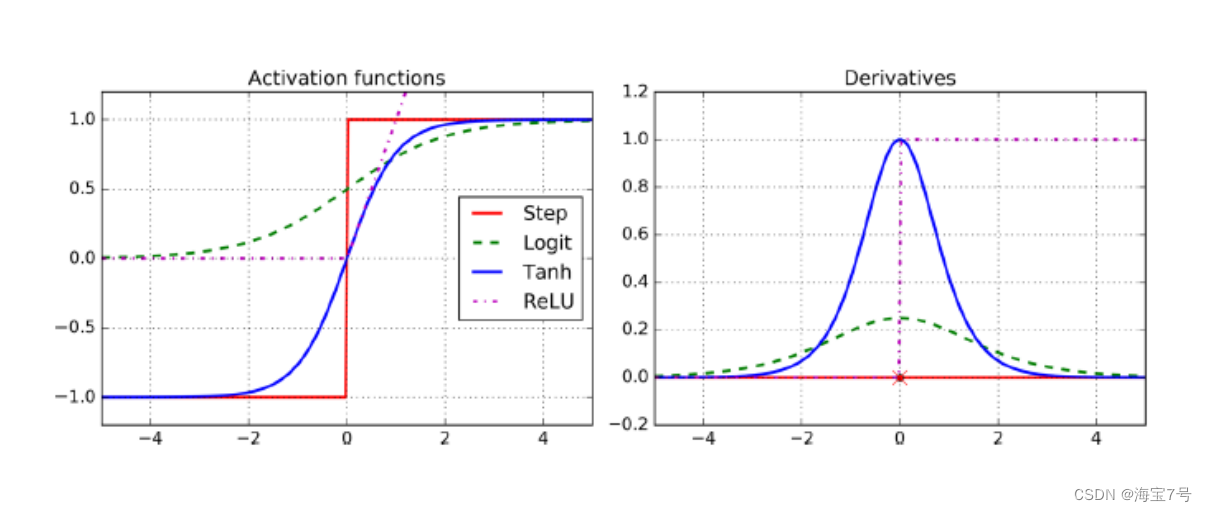
ReLU激活函数
Rectified Linear Units
• ReLU计算线性函数为非线性,如果大于0就是结果,否则
就是0
• 生物神经元的反应看起来其实很像Sigmoid激活函数,所有
专家在Sigmoid上卡了很长时间,但是后来发现ReLU才更
适合人工神经网络,这是一个模拟生物的误解。
几种激活函数及其导数:
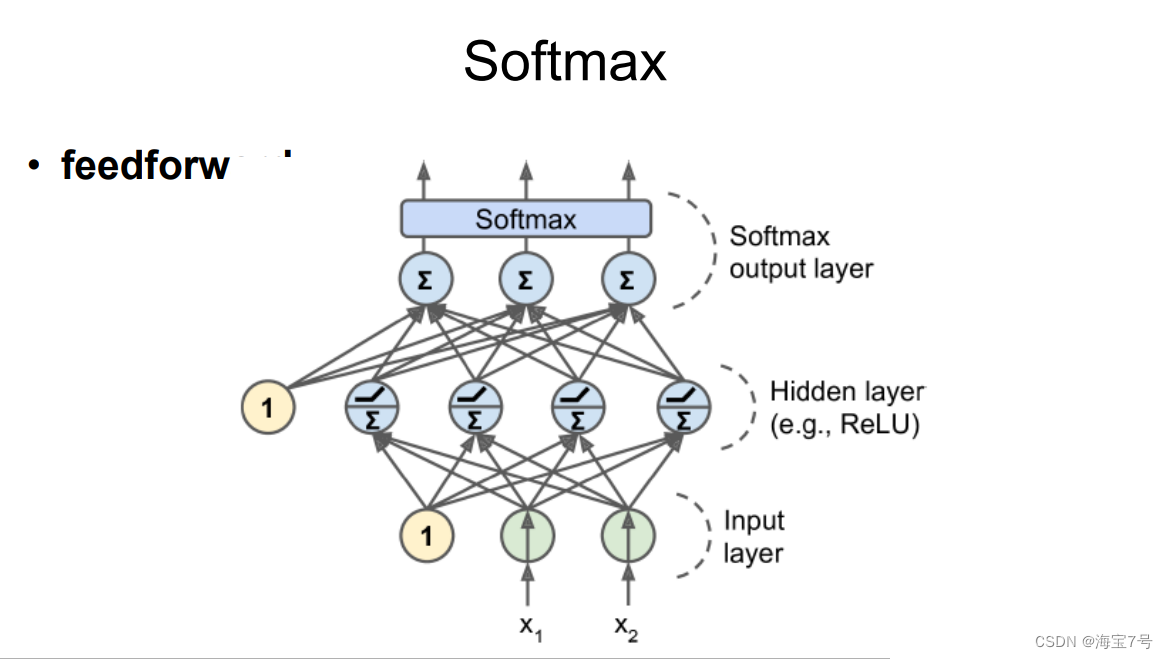
Softmax处理。
多层感知机通常用于分类问题,二分类
• 也有很多时候会用于多分类,需要把输出层的激活函数改
成共享的softmax函数
• 输出变成用于评估属于哪个类别的概率值
数据增大
• 从现有的数据产生一些新的训练样本,人工增大训练集,这将减少过拟合
• 例如如果你的模型是分类蘑菇图片,你可以轻微的平移,旋转,改变大小,然后增加这些变化后的图片到训练集,这使得模型可以经受位置,方向,大小的影响,如果你想用模型可以经受光条件的影响,你可以同理产生许多图片用不同的对比度,假设蘑菇对称的,你也可以水平翻转图片
如图所示:

• TensorFlow提供一些图片操作算子,例如transposing(shifting),> rotating,resizing,flipping,cropping,adjusting brightness,> contrast,saturation,hue
结果:
未完待续—>>>>序章
这篇关于使用tensorflow进行完整的DNN深度神经网络CNN训练完成图片识别案例的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






