本文主要是介绍execl数据多维度建模(二)--透视表、分类汇总、柱形图(选项控件筛选),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
源数据

目的:
1.选择数据
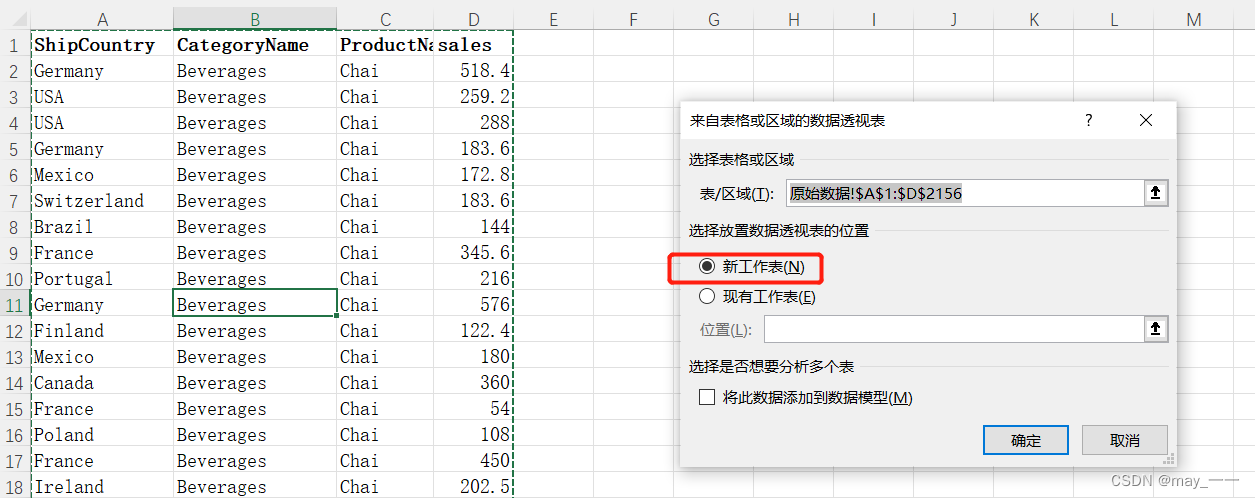
1)插入透视表
选中源数据的数据区域--插入--数据透视表(新的工作表名:透视表)
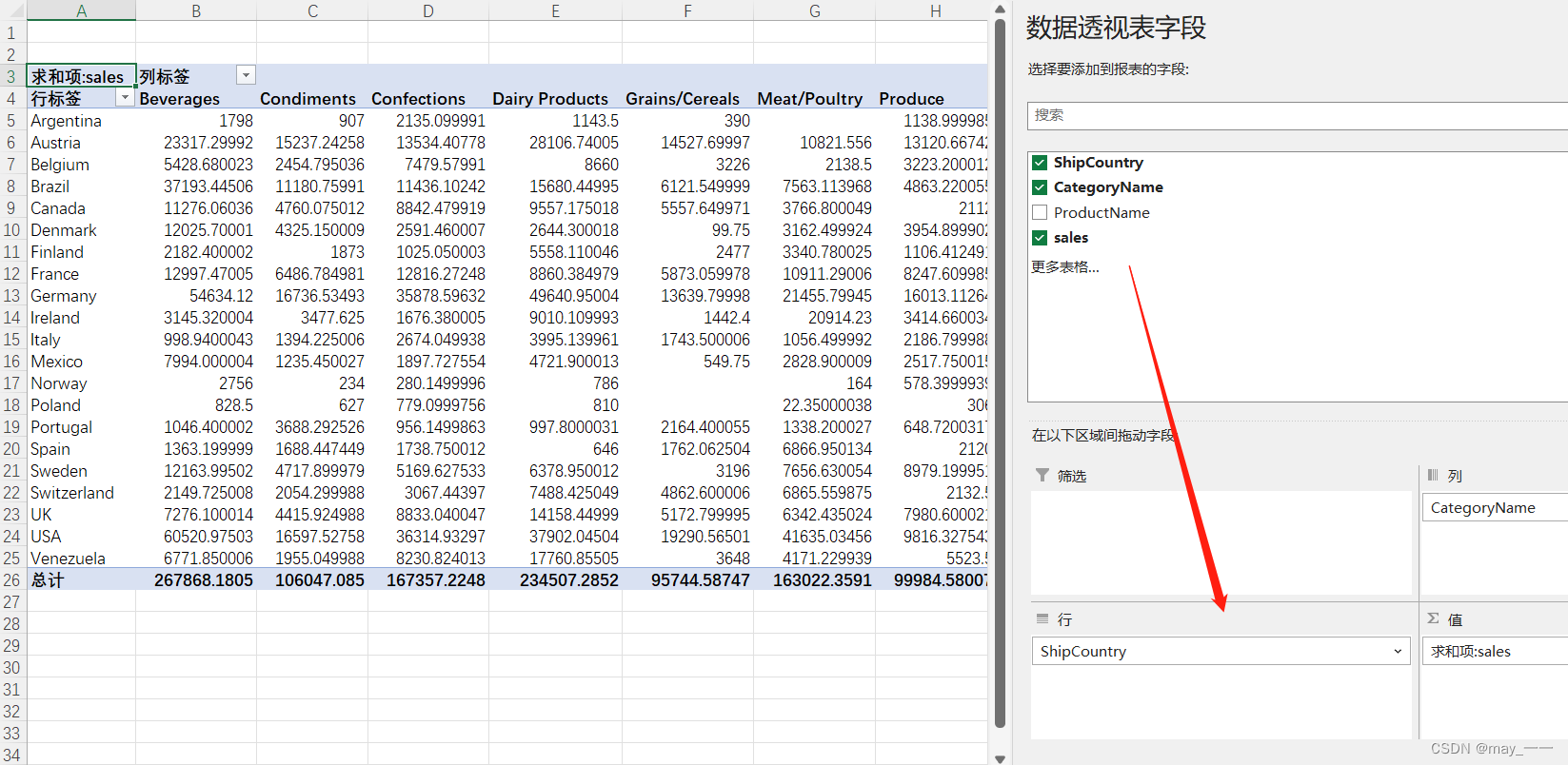
2)透视表设置
ShipCountry拉入行标签;CategoryName拉入列标签;sales拉入值的位置
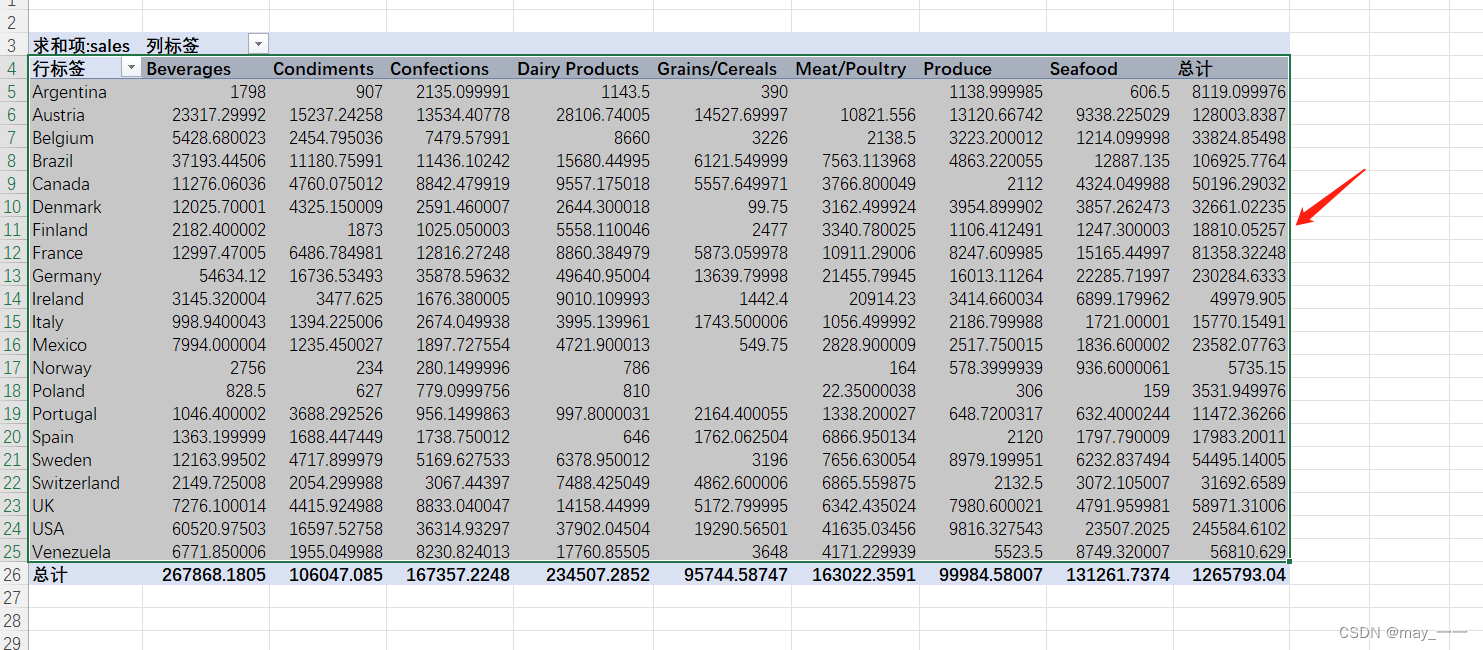
3)将透视表的数据复制到新的标签页(一般我们不在透视表上操作数据)
 4)在新的工作表页(表名:VLOOKUP匹配国家-地区数据)插入“Region”,将“行标签”改为“Counrty”
4)在新的工作表页(表名:VLOOKUP匹配国家-地区数据)插入“Region”,将“行标签”改为“Counrty”
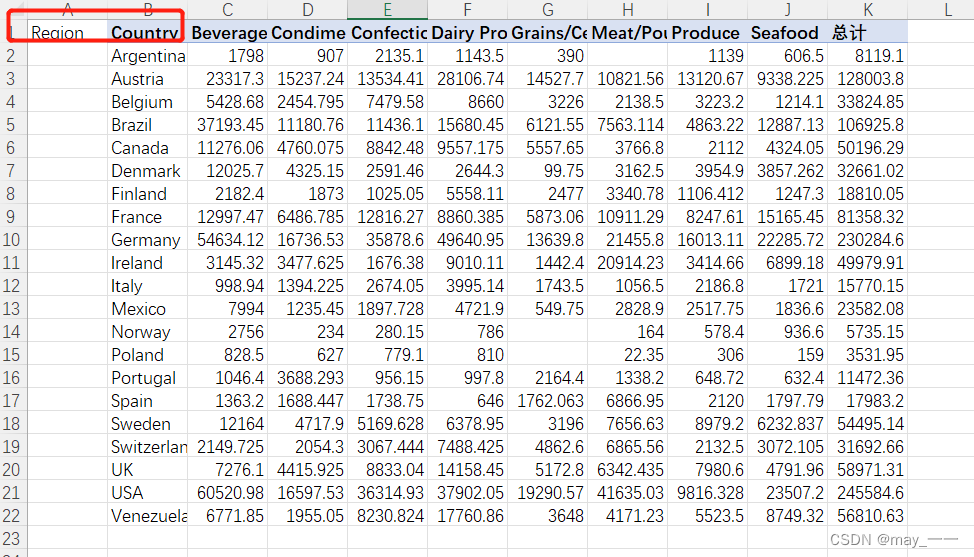
5)用VLOOKUP函数参照“洲-国家对照”表,将国家和地区对照起来。
选中A2单元格--公式--查找与应用--VLOOKUP
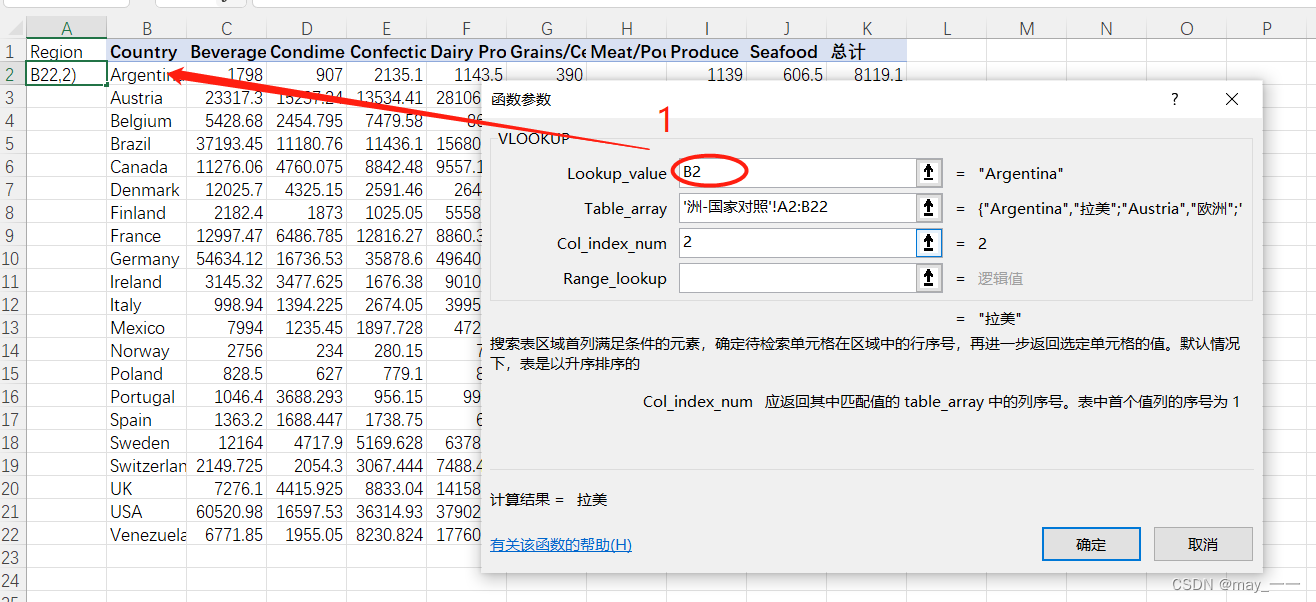
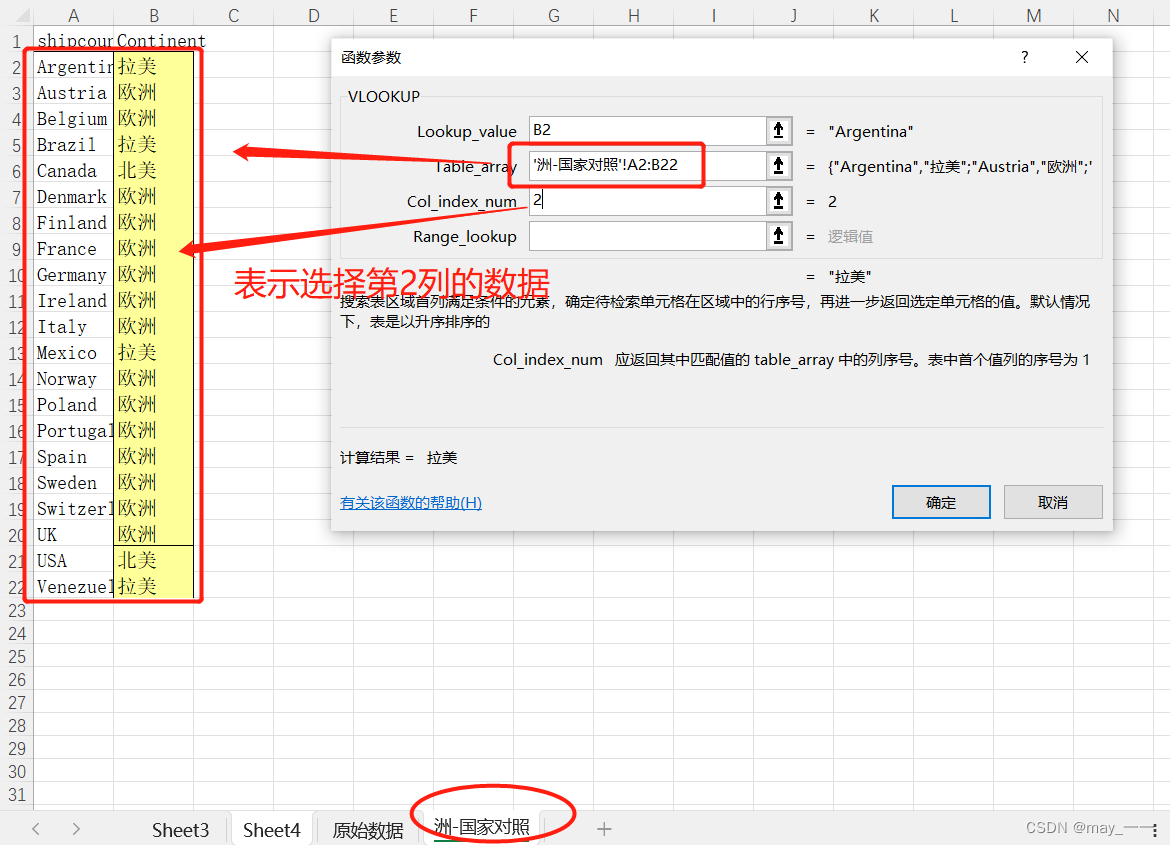
对Table_array进行定位,按F4,然后“确定”

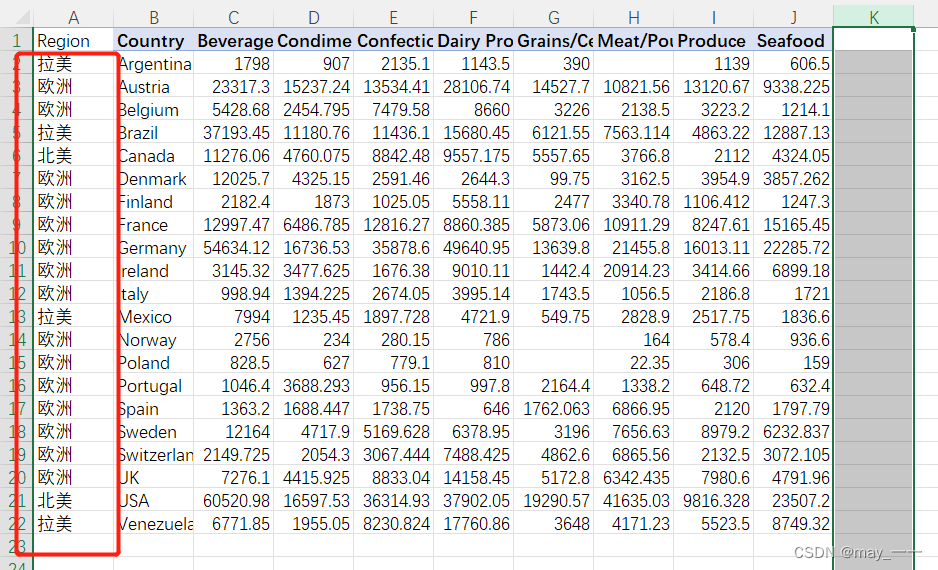
第一个设置以后,下面的下拉就可以,最右列的“总计”不需要,可以删除
2. 排序
将上面匹配后的数据复制到新的工作表(表名:分类汇总数据),然后进行排序
步骤:选中数据部分--开始--排序于筛选--自定义排序--选择排序依据
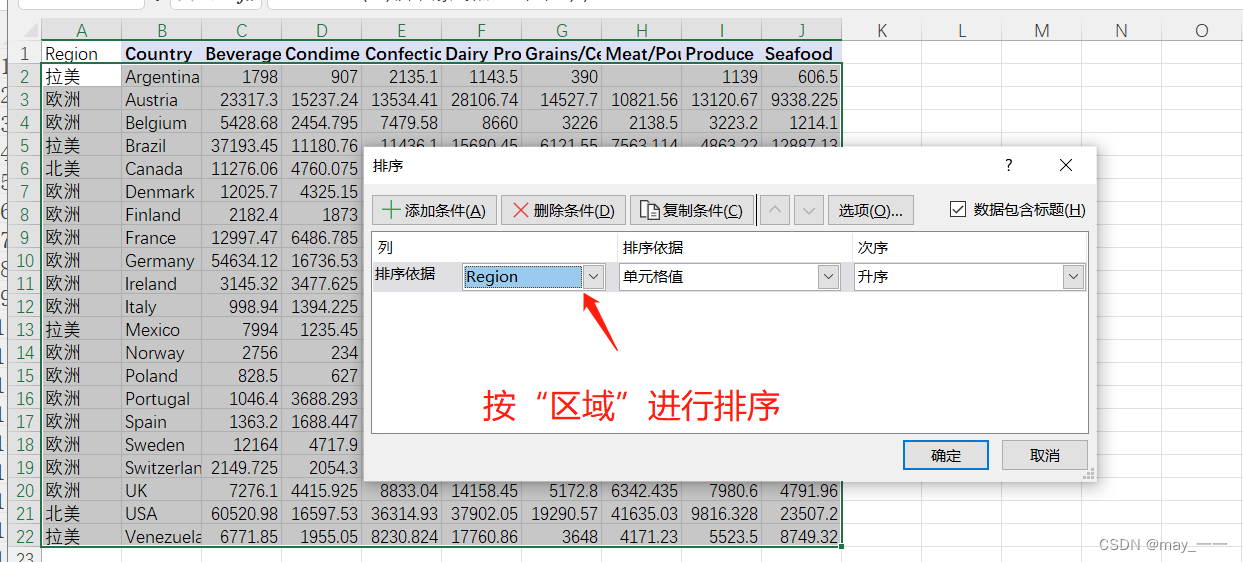
排序结果如下
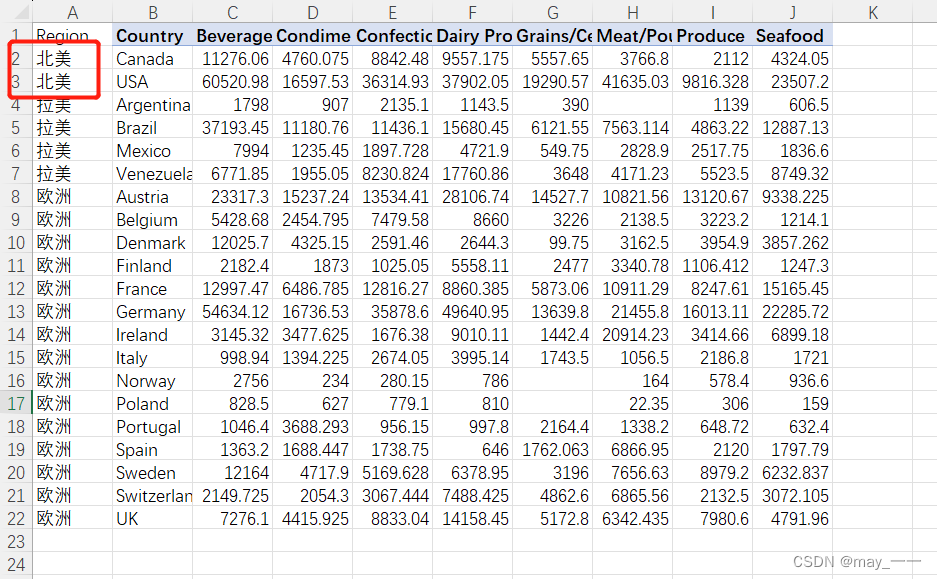
3.分类汇总
将点击数据区域,然后点击“数据”--“分类汇总”(macOS上是“小计”):汇总项除了国家和地区不选,其他都要打勾

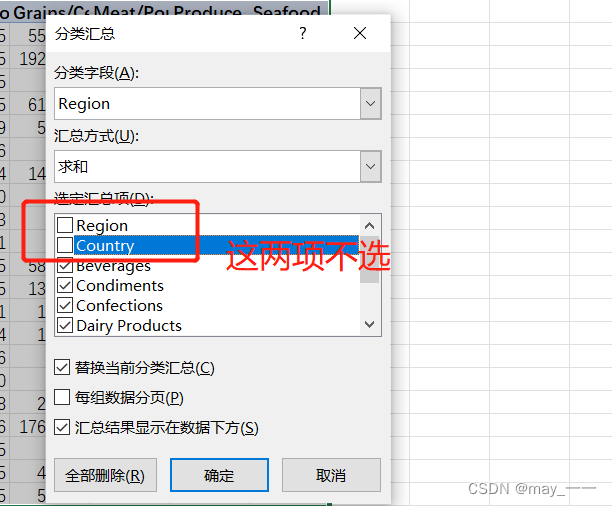
效果如下:

点击“+”,叫“向下钻取”;点击“-”,叫“向上钻取”
全部“上卷”后,效果如下

将上卷后的上图数据复制到新的工作表中:
选中需要复制的区域--搜索“定位条件”---选择“可见单元格”
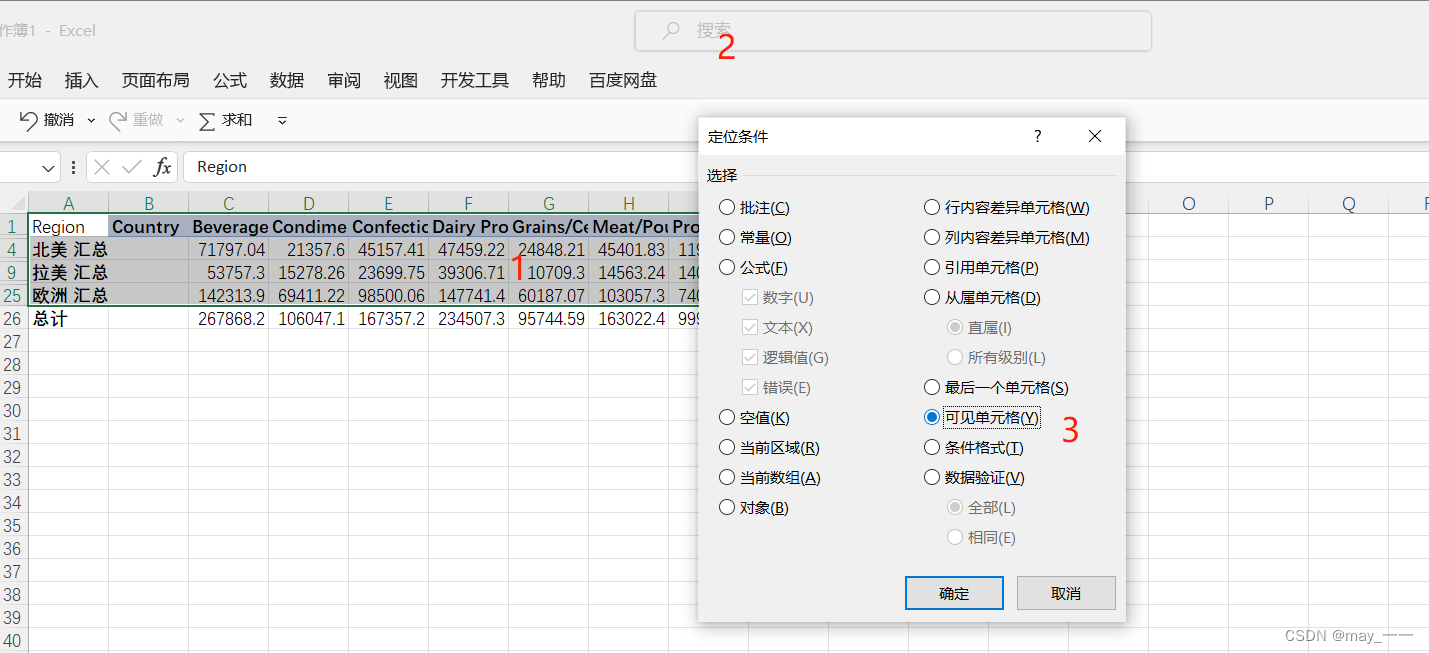
确定

复制到新的工作表(表名:报表与可控图形):
| Region | Country | Beverages | Condiments | Confections | Dairy Products | Grains/Cereals | Meat/Poultry | Produce | Seafood |
| 北美 汇总 | 71797.04 | 21357.6 | 45157.41 | 47459.22 | 24848.21 | 45401.83 | 11928.33 | 27831.25 | |
| 拉美 汇总 | 53757.3 | 15278.26 | 23699.75 | 39306.71 | 10709.3 | 14563.24 | 14043.47 | 24079.56 | |
| 欧洲 汇总 | 142313.9 | 69411.22 | 98500.06 | 147741.4 | 60187.07 | 103057.3 | 74012.78 | 79350.93 | |
将Region中的“汇总”字眼去掉

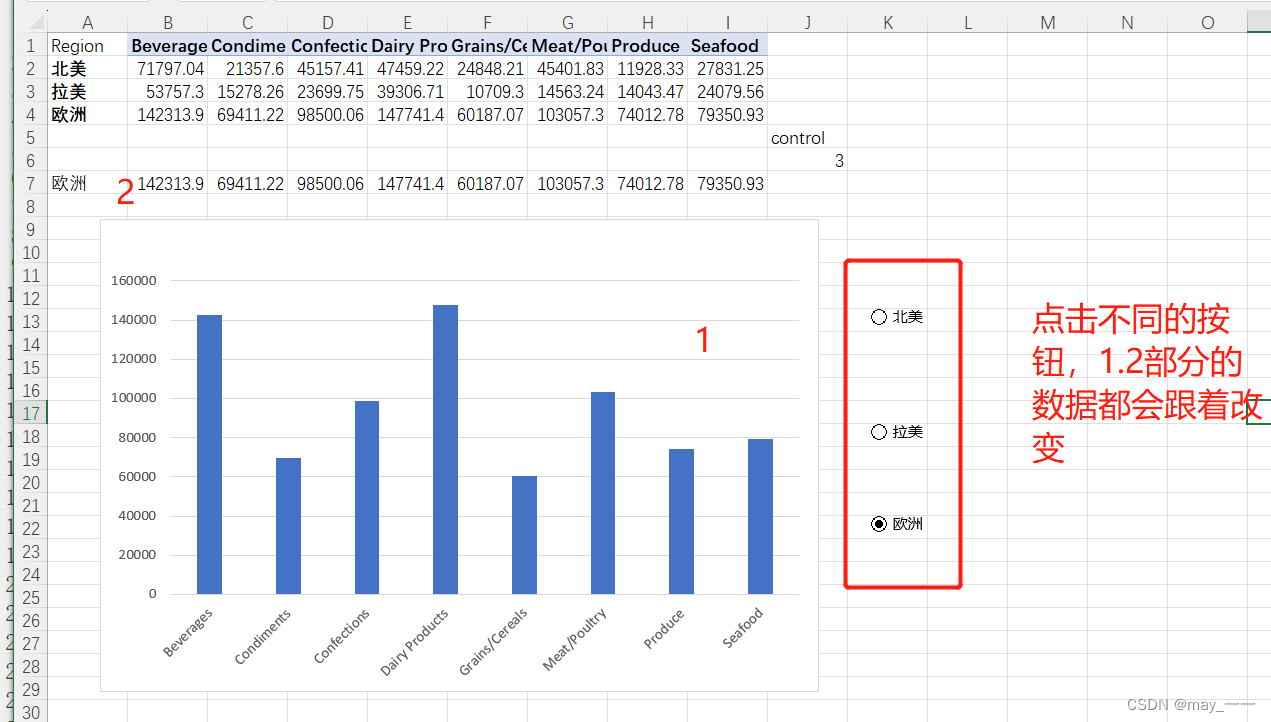
设置一个控制单元格,自己找个位置即可,为了索引的作用
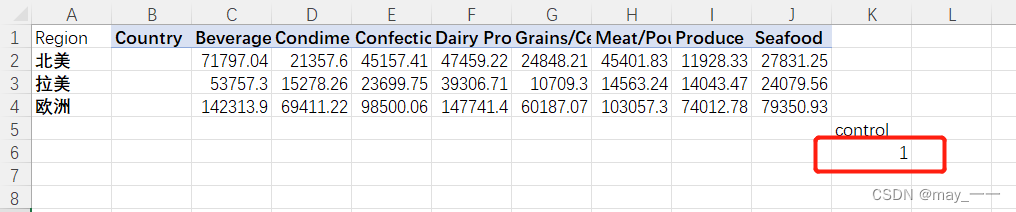
然后再选择一个单元格--公式--查找与引用--INDEX
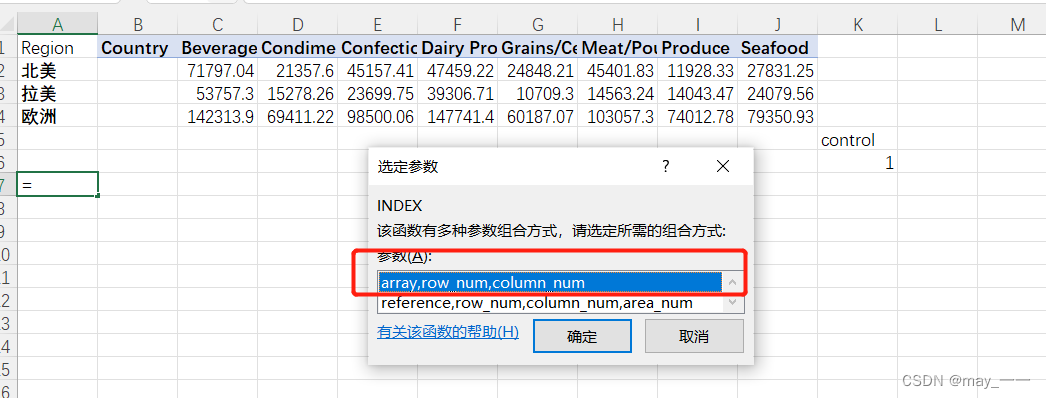
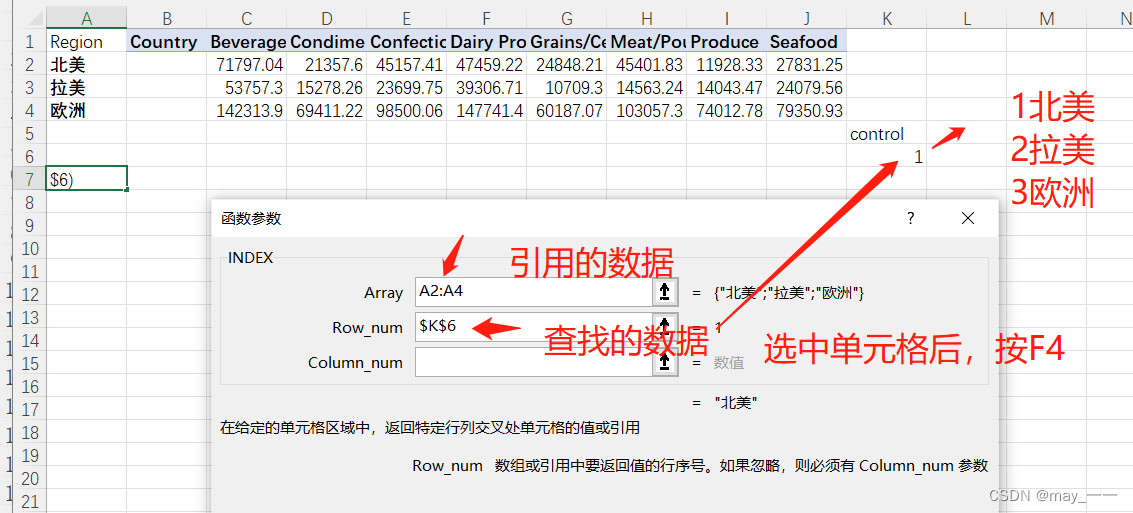
效果:
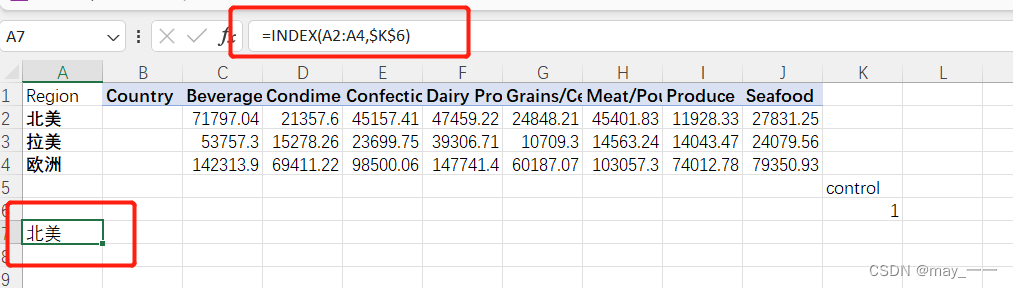 公式向右复制(鼠标移到单元格右下角的位置,出现“+”时,向右拉)
公式向右复制(鼠标移到单元格右下角的位置,出现“+”时,向右拉)
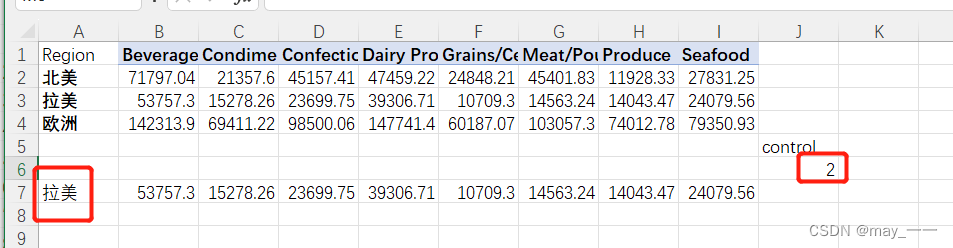
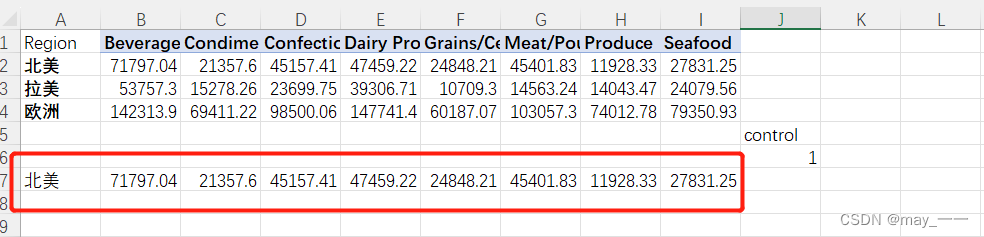 control的数据改变后,数据跟着改变:
control的数据改变后,数据跟着改变:
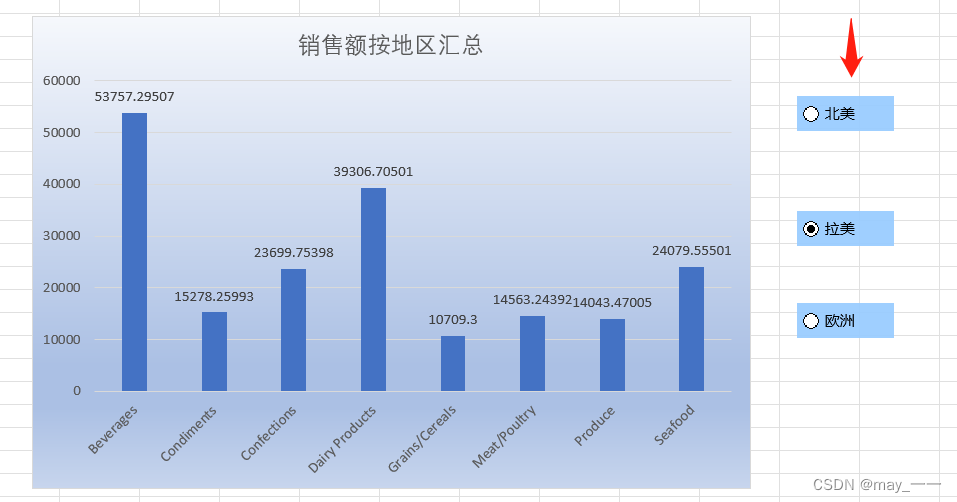
 4.制作动态图表
4.制作动态图表
1)选中数据,插入柱形图
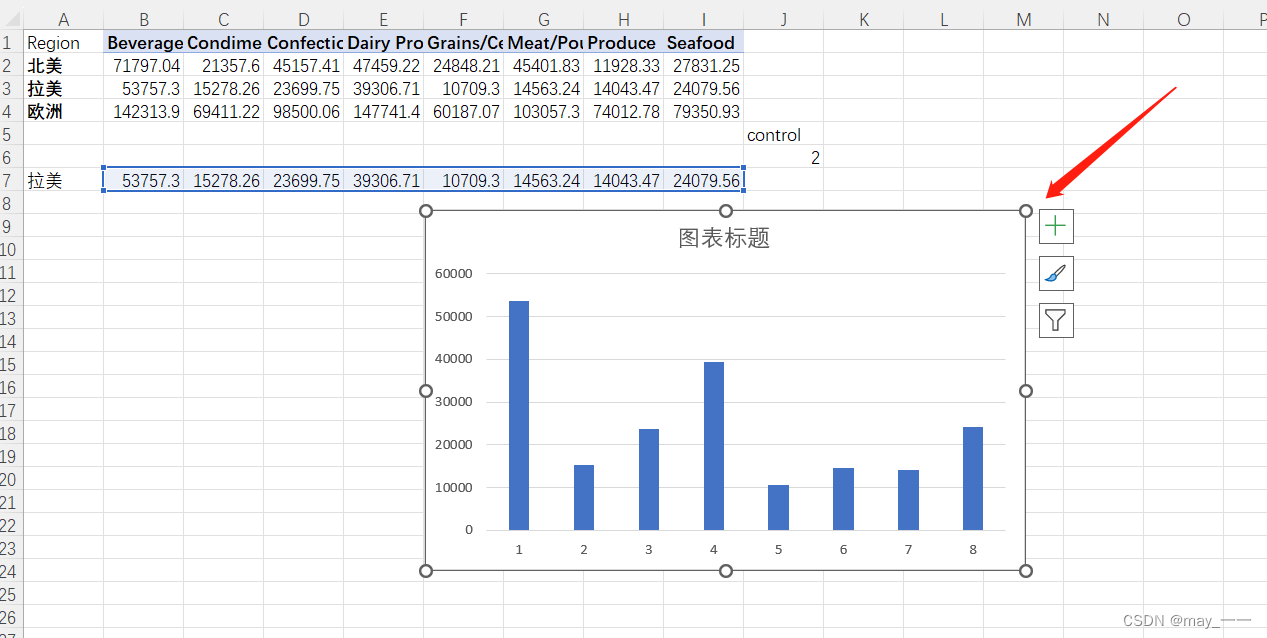
2)优化柱形图:
将水平轴坐标修改为类别(选中柱形图--图表设计--选择数据--编辑水平轴坐标--选择数据)
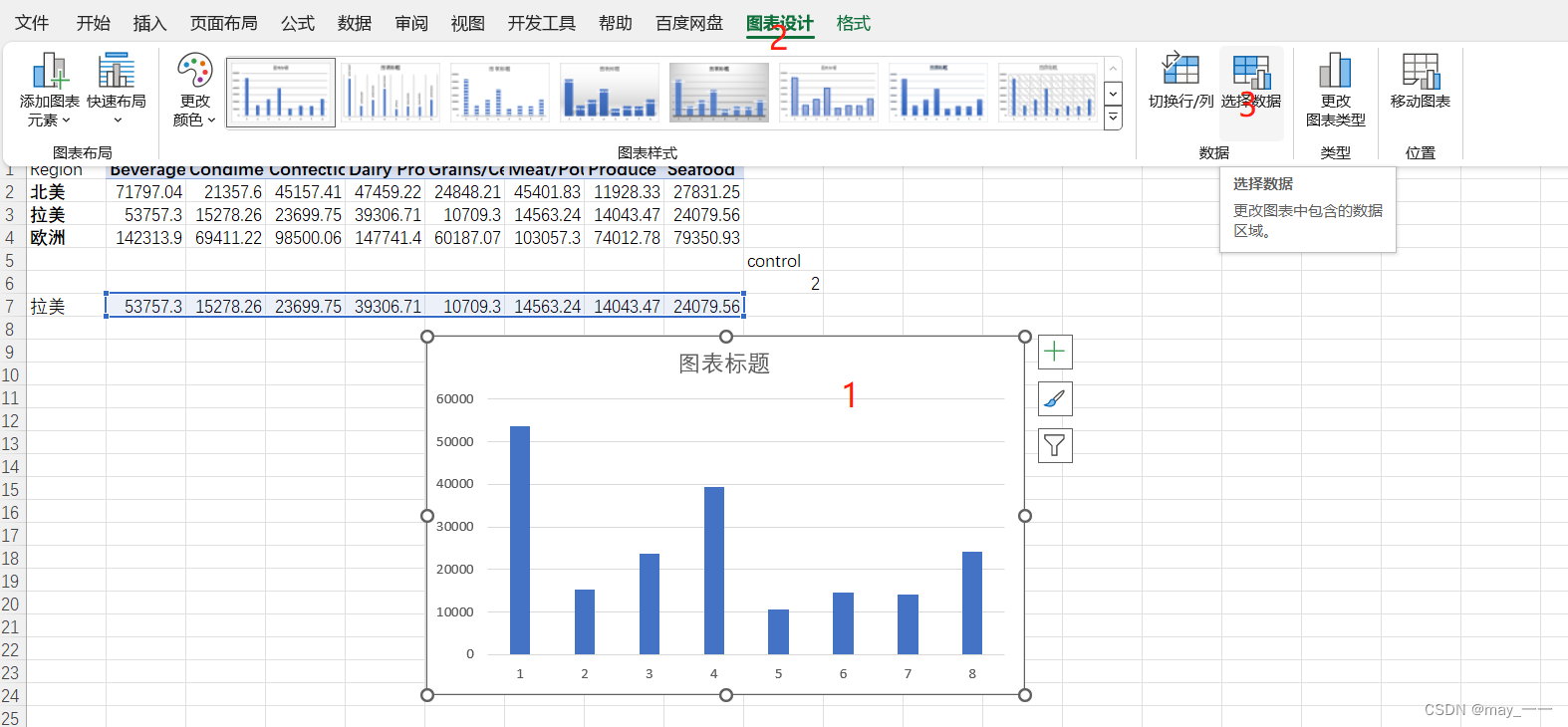
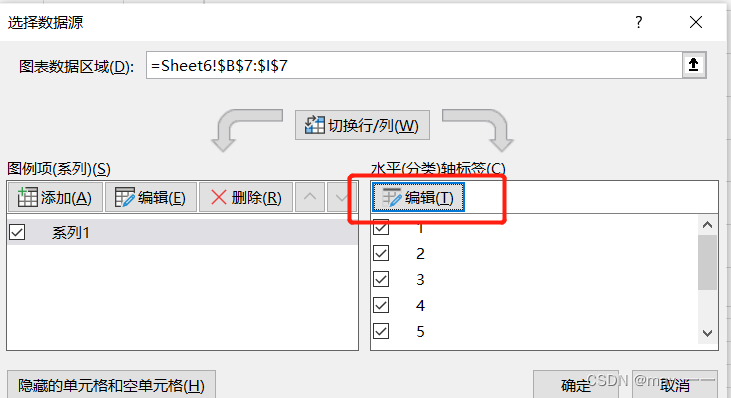
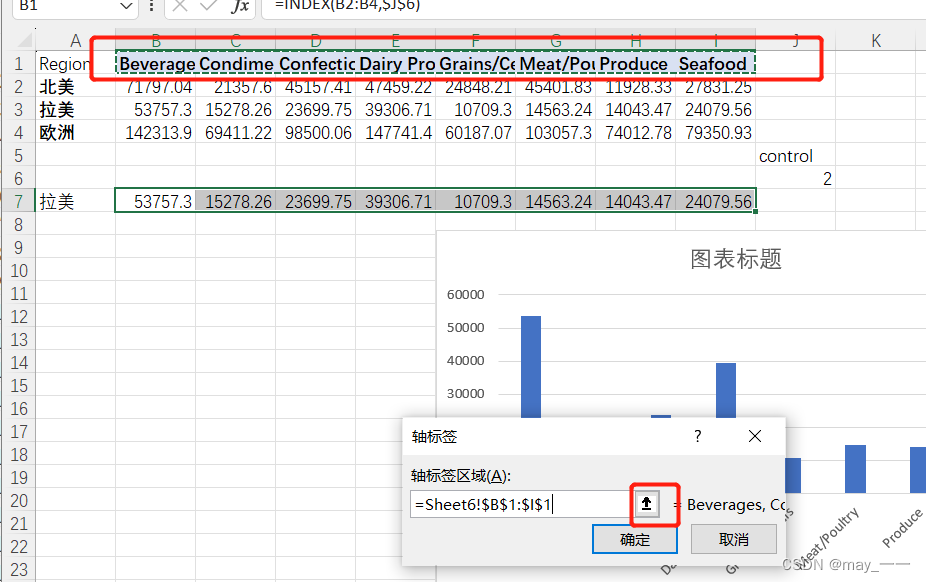
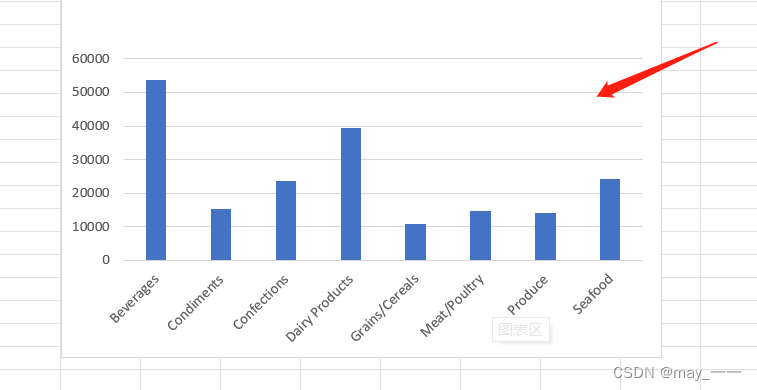
效果如下:
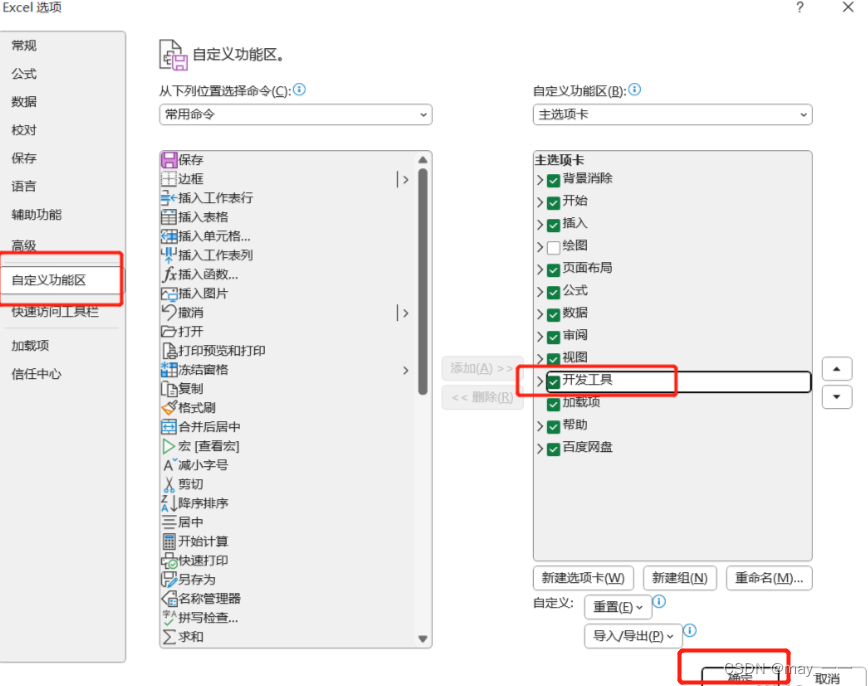
a. 先打开开发工具(文件--更多--自定义功能区--开发工具)
b. 开发工具--插入“”选项按钮“”

插入后,可输入文本信息

c. 编辑按钮
右键“控件”--设置控件格式
 然后复制2个,并修改标签
然后复制2个,并修改标签
5. 整体效果如下:
所有的工作表如下:

其他柱形图美化:
(1)增加“数据标签”

(2)增加“图表标题 ”
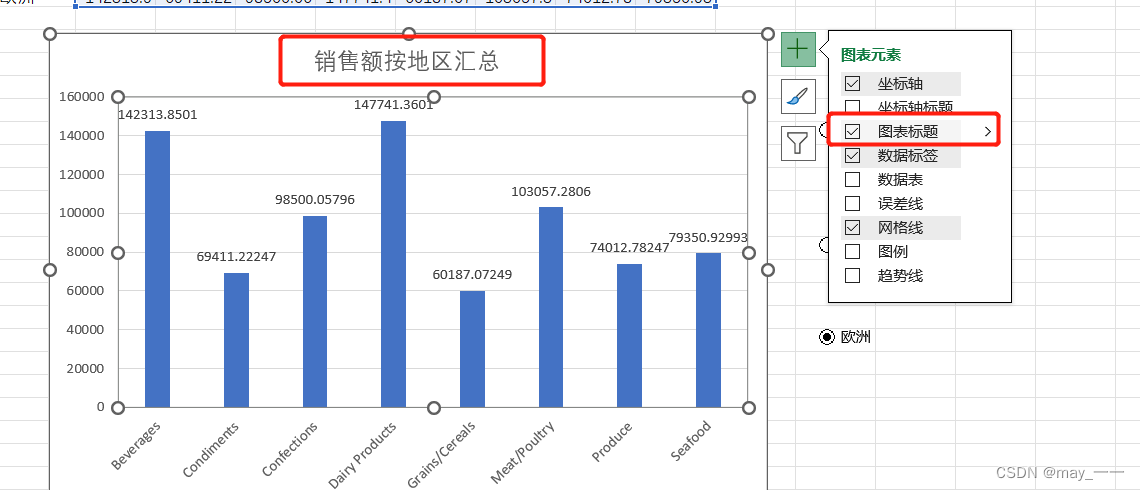
(3)背景填充
 (4) 选项控件优化
(4) 选项控件优化

这篇关于execl数据多维度建模(二)--透视表、分类汇总、柱形图(选项控件筛选)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









