本文主要是介绍【EAI 023】Self-Instruct: Aligning Language Models with Self-Generated Instructions,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Paper Card
论文标题:Self-Instruct: Aligning Language Models with Self-Generated Instructions
论文作者:Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A. Smith, Daniel Khashabi, Hannaneh Hajishirzi
作者单位:University of Washington, AI2, etc.
论文原文:https://arxiv.org/abs/2212.10560
论文出处:ACL 2023
论文被引:718(02/24/2024)
项目主页:–
论文代码:https://github.com/yizhongw/self-instruct,3.6k star
研究问题:大模型指令调优数据集构建
面临挑战:
- 人类编写的指令数据在数量、多样性和创造性方面往往是有限的,阻碍了调整后模型的通用性。
- 对人类来说,标注大规模指令数据是一项挑战,因为它需要:1)创造力来提出新颖的任务;2)专业知识来编写每个任务的解决方案。
主要贡献:
- 提出了 SELF-INSTRUCT,一种用最少的人类标注数据诱导指令遵循能力的方法,并通过大量的指令调优实验证明了它的有效性;
- 发布了一个包含 52K 条指令的大型合成数据集和一组人工编写的新任务,用于构建和评估未来的指令遵循模型;
方法概述:
- 数据生成管道包括四个步骤:
- 1)生成任务指令;
- 2)确定指令是否代表分类任务;
- 3)采用输入优先或输出优先的方法生成实例;
- 4)过滤低质量数据。
主要结论:
- 生成多样性评估:对于每条生成的指令,计算其与 175 条种子指令的最高 ROUGE-L 重叠。生成的新指令数量可观,但与种子指令的重合度不高。
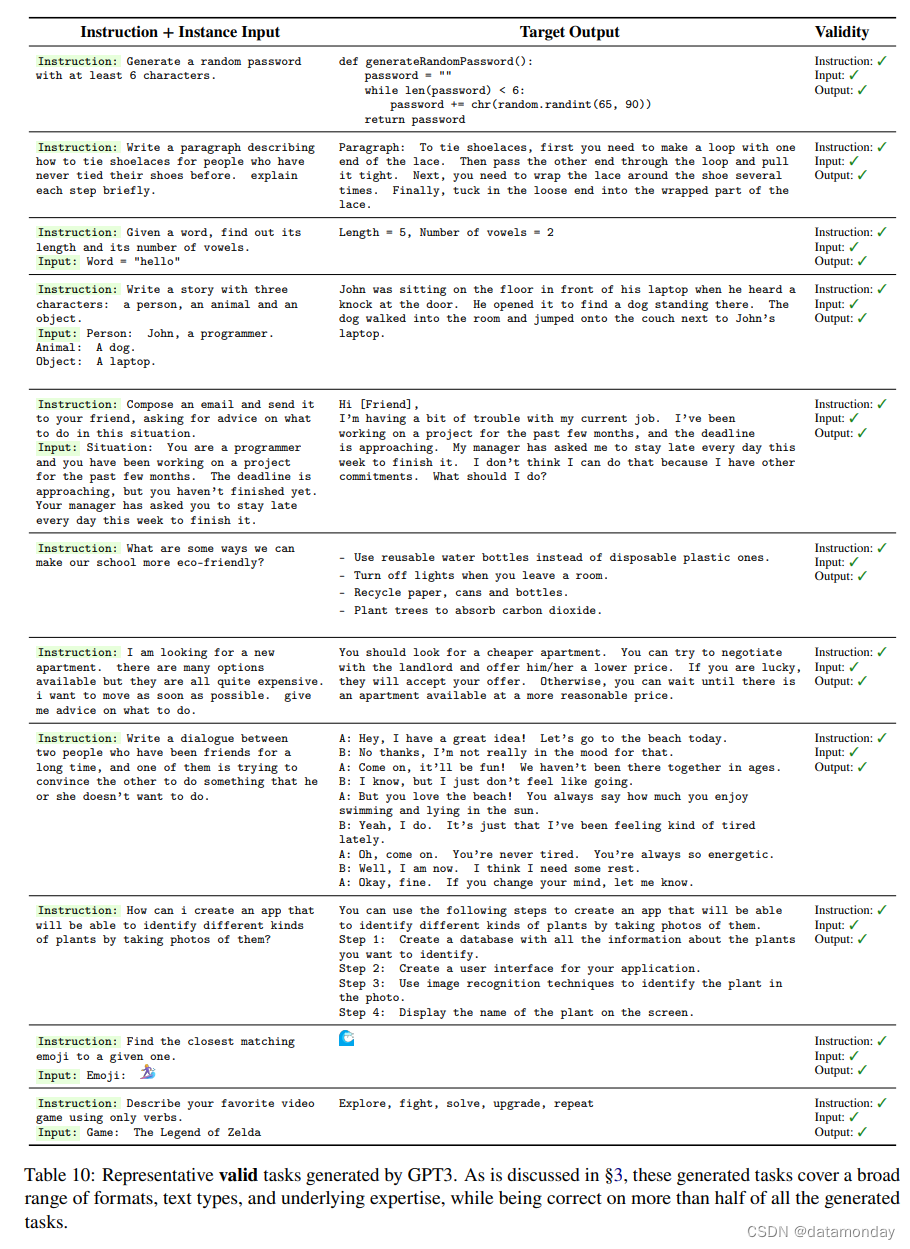
- 生成质量评估(人工):许多任务无法用自动指标来衡量,甚至无法由普通的群众工作者来评判(例如,编写程序或将一阶逻辑转换为自然语言)。我们总共创建了 252 条指令,每条指令有 1 个实例。请提出指令的作者从指令、实例输入和实例输出三个方面标注每个实例是否正确。
- 大多数生成的指令都是有意义的,但生成的实例在一定程度上可能包含较多噪音。生成的实例中的格式可以保证大部分正确,但是内容可能无法保证。
- 减少每个训练任务的实例数量不会降低模型对未见任务的泛化性能。
- SELF-INSTRUCT 大幅提高了 GPT-3 的指令执行能力。
- InstructGPT 具备良好的指令遵循能力,这可能是因为其通过使用人工标注或训练奖励模型来选择更好的生成(RLHF),提高生成数据的质量在很大程度上会使未来的工作受益。
- 随着数据量的增加,我们看到了持续的改进。不过,这种改进在 16K 之后几乎趋于平稳。这表明未来的研究可能会受益于使用不同指令数据的组合,从而在各种类型的任务中获得更好的性能。
- 使用我们的生成管道获取初始数据,然后通过人类专家或从更好的模型中提炼数据来提高数据质量方面还有很大的工作空间。
- 对于较大的模型,指令调优的收益更高。
总结:
- SELF-INSTRUCT 的一个独特动机是引导新的任务定义,而这些任务定义可能是以前从未定义过的。
- 人工评估:许多任务无法用自动指标来衡量,因此可以考虑让提出指令的人类专家来对结果进行评估。
- 生成质量和多样性:需要采用一些量化的指标对生成数据进行过滤。指令数据的规模和多样性与由此产生的模型对未见任务的泛化性之间存在直接关联。
- 数据清洗:采用该方法生成初步的样本,然后人工清洗。
Abstract
大型的指令调优语言模型(即根据指令进行微调)已经证明了其在新任务中实现零样本泛化的卓越能力。然而,这些模型在很大程度上依赖于人类编写的指令数据,而这些指令数据在数量、多样性和创造性方面往往是有限的,因此阻碍了微调后模型的通用性。我们引入了 SELF-INSTRUCT,这是一个通过自引导来提高预训练语言模型的指令遵循能力的框架。我们的管道从语言模型中生成指令、输入和输出样本,然后过滤无效或类似的样本,再利用它们对原始模型进行微调。将我们的方法应用于 vanilla GPT-3,我们在超级自然指令(SUPER-NATURAL INSTRUCTIONS)上展示了比原始模型 33% 的绝对改进,与使用私人用户数据和人工注释训练的 InstructGPT011 的性能相当。为了进一步评估,我们为新任务策划了一组由专家撰写的指令,并通过人工评估表明,使用 SELF-INSTRUCT 对 GPT-3 进行调整后,其性能大大优于现有的公共指令数据集,与 InstructGPT001 的绝对差距仅为 5%。SELF-INSTRUCT 提供了一种几乎无需注释的方法,可将预训练的语言模型与指令对齐,我们还发布了我们的大型合成数据集,以促进未来的指令调优研究。
1 Introduction
最近的 NLP 文献在建立能够遵循自然语言指令的模型方面取得了巨大的成就。这些发展由两个关键部分驱动:大型预训练语言模型(LM)和人类编写的指令数据(PROMPTSOURCE,SUPER-NATURAL INSTRUCTIONS)。然而,收集此类指令数据的成本很高,而且由于大多数人类世代往往是流行的 NLP 任务,因此其多样性往往有限,无法涵盖真正的各种任务和描述任务的不同方法。要继续提高指令调优模型的质量和覆盖范围,就必须开发其他方法来监督指令调优过程。
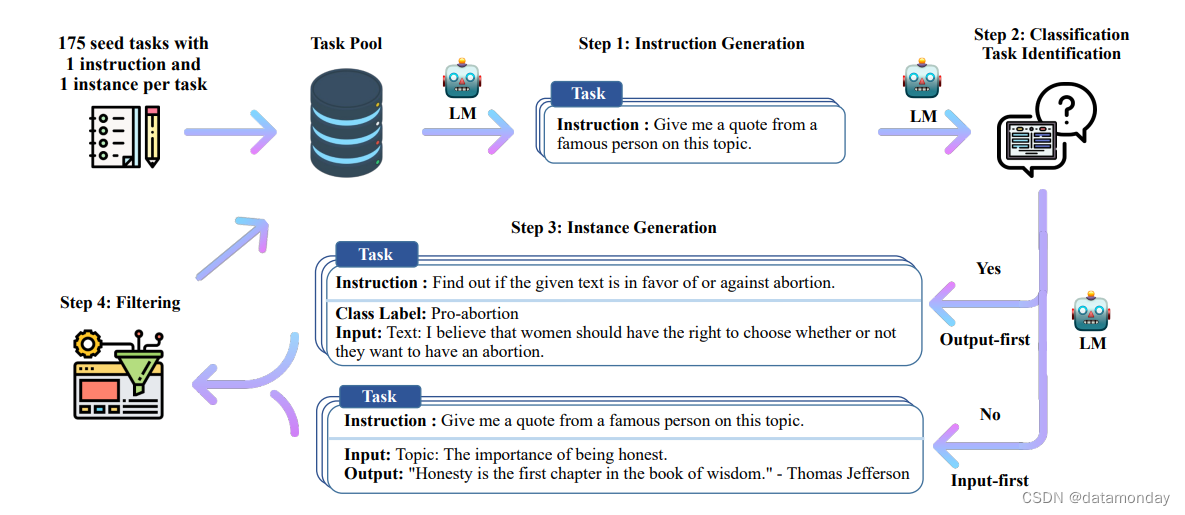
Figure 2: Self-Instruction 总览。该流程以一个小的任务种子集作为任务池开始。从任务池中采样随机任务,并用于提示 LM 生成新的指令和相应的实例,然后过滤低质量或类似的生成,然后添加回初始任务存储库。所得到的数据可用于语言模型本身的指令调优,以便更好地遵循指令。图中所示的任务由 GPT-3 生成。
在这项工作中,我们引入了 SELF-INSTRUCT,这是一个利用模型本身的指令信号对预训练 LM 进行指令调优的半自动流程。整个过程是一种迭代引导算法(见图 2),它以有限的(本研究中为 175 个)人工编写的任务种子集开始,这些任务用于指导整个生成过程。
- 在第一阶段,系统会提示模型生成新任务的指令。这一步利用现有的指令集来创建覆盖面更广的指令,以定义(通常是新)任务。
- 鉴于新生成的指令集,该框架还为其创建了输入-输出实例,随后可用于监督指令调优。
- 最后,在将剩余的有效任务添加到任务池之前,会使用各种启发式方法自动过滤低质量或重复的指令。
这个过程可以重复多次,直到达到大量任务为止。

为了对 SELF-INSTRUCT 进行经验性地评估,我们在原始模型 GPT-3 上运行了这一框架。在该模型上的 SELF-INSTRUCT 迭代过程产生了约 52K 条指令,并与约 82K 个实例输入和目标输出配对。如图 1 所示,生成的数据提供了多种多样的创造性任务。这些生成的任务偏离了典型 NLP 任务的分布,与种子任务的重叠也相当小(第 3.2 节)。在这些生成的数据上,我们通过对 GPT-3(即用于生成指令数据的相同模型)进行微调,构建了 GPT-3SELF-INST。我们在 SUPERNI 中包含的典型 NLP 任务,以及为指令遵循模型的新用途而创建的一组新指令(§4)上,将 GPT-3SELF-INST 与其他各种模型进行了比较评估。结果表明,GPT-3SELF-INST的性能远远超过GPT-3(原始模型)(+33.1%),几乎与InstructGPT001的性能相当。此外,我们在新创建的指令集上进行的人工评估表明,GPT-3SELF-INST 展示了广泛的指令跟踪能力,其表现优于在其他公开指令数据集上训练的模型,与 InstructGPT001 的差距仅为 5%。
我们的贡献在于:
- SELF-INSTRUCT,这是一种用最少的人类标注数据诱导指令遵循能力的方法;
- 通过大量的指令调优实验证明了它的有效性;
- 发布了一个包含 52K 条指令的大型合成数据集和一组人工编写的新任务,用于构建和评估未来的指令遵循模型。
2 Method
对人类来说,标注大规模指令数据是一项挑战,因为它需要:1)创造力来提出新颖的任务;2)专业知识来编写每个任务的解决方案。在此,我们将详细介绍我们的 SELF-INSTRUCT 流程,即利用虚构预训练语言模型自行生成任务、过滤生成的数据,然后利用这些生成的数据进行指令调优,以便使 LM 更好地遵循指令。该流程如图 2 所示。
2.1 Defining Instruction Data

2.2 Automatic Instruction Data Generation
我们的数据生成管道包括四个步骤:
- 1)生成任务指令;
- 2)确定指令是否代表分类任务;
- 3)采用输入优先或输出优先的方法生成实例;
- 4)过滤低质量数据。
Instruction Generation.
第一步,SELF-INSTRUCT 以引导方式从一小部分人类编写的种子指令中生成新指令。我们用 175 个任务(每个任务 1 条指令和 1 个实例)启动任务池。每一步,我们都会从任务池中抽取 8 条任务指令作为上下文示例。在这 8 条指令中,6 条来自人工编写的任务,2 条来自前几步中模型生成的任务,以促进任务的多样性。提示模板如表 5 所示。

Classification Task Identification.
因为我们需要两种不同的方法来处理分类任务和非分类任务,所以我们接下来确定生成的指令是否代表分类任务。我们使用种子任务中的 12 条分类指令和 19 条非分类指令,以少量提示的方式对 LM 进行判定。提示模板如表 6 所示。
Can the following task be regarded as a classification task with finite output labels?Task: Given my personality and the job, tell me if I would be suitable.
Is it classification? YesTask: Give me an example of a time when you had to use your sense of humor.
Is it classification? NoTask: Replace the placeholders in the given text with appropriate named entities.
Is it classification? No
Task: Fact checking - tell me if the statement is true, false, or unknown, based on your
knowledge and common sense.
Is it classification? Yes
Task: Return the SSN number for the person.
Is it classification? No
Task: Detect if the Reddit thread contains hate speech.
Is it classification? Yes
Task: Analyze the sentences below to identify biases.
Is it classification? No
Task: Select the longest sentence in terms of the number of words in the paragraph, output
the sentence index.
Is it classification? Yes
Task: Find out the toxic word or phrase in the sentence.
Is it classification? No
Task: Rank these countries by their population.
Is it classification? No
Task: You are provided with a news article, and you need to identify all the categories that
this article belongs to. Possible categories include: Music, Sports, Politics, Tech, Finance,
Basketball, Soccer, Tennis, Entertainment, Digital Game, World News. Output its categories one
by one, seperated by comma.
Is it classification? Yes
Task: Given the name of an exercise, explain how to do it.
Is it classification? No
Task: Select the oldest person from the list.
Is it classification? Yes
Task: Find the four smallest perfect numbers.
Is it classification? No
Task: Does the information in the document supports the claim? You can answer "Support" or
"Unsupport".
Is it classification? Yes
Task: Create a detailed budget for the given hypothetical trip.
Is it classification? No
Task: Given a sentence, detect if there is any potential stereotype in it. If so, you should
explain the stereotype. Else, output no.
Is it classification? No
⋯
Task: To make the pairs have the same analogy, write the fourth word.
Is it classification? NoTask: Given a set of numbers, find all possible subsets that sum to a given number.
Is it classification? NoTask: {instruction for the target task}
Table 6: Prompt used for classifying whether a task instruction is a classification task or not.
Instance Generation.
给定指令及其任务类型后,我们为每条指令独立生成实例。这很有挑战性,因为它要求模型根据指令理解目标任务是什么,找出需要哪些附加输入字段并生成它们,最后通过生成输出来完成任务。我们发现,如果使用其他任务中的指令-输入-输出(instruction-input-output)上下文示例进行提示,经过预训练的 LM 可以在很大程度上实现这一目标。做到这一点的一个自然方法是输入优先法(Input-first Approach),我们可以要求 LM 根据指令首先提出输入字段,然后生成相应的输出。这种生成顺序与模型响应指令和输入的方式类似,但这里使用的是其他任务中的上下文示例。提示模板如表 7 所示。
Come up with examples for the following tasks. Try to generate multiple examples when possible.
If the task doesn’t require additional input, you can generate the output directly.Task: Which exercises are best for reducing belly fat at home?
Output:
- Lying Leg Raises
- Leg In And Out
- Plank
- Side Plank
- Sit-upsTask: Extract all the country names in the paragraph, list them separated by commas.
Example 1
Paragraph: Dr. No is the sixth novel by the English author Ian Fleming to feature his British
Secret Service agent James Bond. Written at Fleming’s Goldeneye estate in Jamaica, it was
first published in the United Kingdom by Jonathan Cape in 1958. In the novel Bond looks into
the disappearance in Jamaica of two fellow MI6 operatives who had been investigating Doctor
No. Bond travels to No’s Caribbean island and meets Honeychile Rider, who is there to collect
shells. They are captured and taken to a luxurious facility carved into a mountain. The
character of Doctor No, the son of a German missionary and a Chinese woman, was influenced by
Sax Rohmer’s Fu Manchu stories. Dr. No was the first of Fleming’s novels to face widespread
negative reviews in Britain, but it was received more favourably in the United States.
Output: English, British, Jamaica, the United Kingdom, German, Chinese, Britain, the United
States.Task: Converting 85 F to Celsius.
Output: 85°F = 29.44°CTask: Sort the given list ascendingly.
Example 1
List: [10, 92, 2, 5, -4, 92, 5, 101]
Output: [-4, 2, 5, 5, 10, 92, 92, 101]
Example 2
Input 2 - List: [9.99, 10, -5, -1000, 5e6, 999]
Output: [-1000, -5, 9.99, 10, 999, 5e6]Task: Suggest a better and more professional rephrasing of the following sentence.
Example 1
Sentence: This house is surprisingly not constructed very well, and you probably need more
money to fix it after you buy it. If you ask me, I would suggest you to consider other
candidates.
Output: This house does not seem to be constructed well, so you may need to spend more money
to fix it after you purchase it. I would suggest that you look at other properties.
Example 2
Sentence: Just so you know, we did an experiment last week and found really surprising results
- language model can improve itself!
Output: Our experiments last week demonstrated surprising results, proving that the language
model can improve itself.⋯Task: Turn down a job offer by sending an email to a recruiter explaining the reason.
Output: Hi [Recruiter],
Thank you so much for the generous offer to join your team. As we discussed, I’ve admired the
company for a number of years, and am a proud endorser of its products. However, after further
consideration of where I currently am in my career, I’ve decided to accept an offer at another
company.
I would love to stay in touch with you and have already started following you on [Social Media
Platform]. Again, thank you so much for your time and consideration.
Thanks again,
[Your Name]Task: {Instruction for the target task}
Table 7: Prompt used for the input-first approach of instance generation. The model is prompted to generate the instance first, and then generate the corresponding output. For instructions that don’t require additional input, the output is allowed to be generated directly.
然而,我们发现这种方法生成的输入可能会偏向一个标签,尤其是在分类任务中(例如,在语法错误检测中,它通常生成语法输入)。因此,我们针对分类任务提出了输出优先法(Output-first Approach),即首先生成可能的类标签,然后根据每个类标签的条件生成输入。提示模板如表 8 所示。我们将输出优先法用于前一步确定的分类任务,而将输入优先法用于其余的非分类任务。
Given the classification task definition and the class labels, generate an input that
corresponds to each of the class labels. If the task doesn’t require input, just generate the
correct class label.Task: Classify the sentiment of the sentence into positive, negative, or mixed.
Class label: mixed
Sentence: I enjoy the flavor of the restaurant but their service is too slow.
Class label: Positive
Sentence: I had a great day today. The weather was beautiful and I spent time with friends.
Class label: Negative
Sentence: I was really disappointed by the latest superhero movie. I would not recommend it.Task: Given a dialogue, classify whether the user is satisfied with the service. You should
respond with "Satisfied" or "Unsatisfied".
Class label: Satisfied
Dialogue:
- Agent: Thank you for your feedback. We will work to improve our service in the future.
- Customer: I am happy with the service you provided. Thank you for your help.
Class label: Unsatisfied
Dialogue:
- Agent: Sorry that we will cancel your order. You will get a refund within 7 business days.
- Customer: oh that takes too long. I want you to take quicker action on this.Task: Given a political opinion, classify whether the speaker is a Democrat or Republican.
Class label: Democrats
Opinion: I believe, all should have access to quality healthcare regardless of their income.
Class label: Republicans
Opinion: I believe that people should be able to keep more of their hard-earned money and
should not be taxed at high rates.Task: Tell me if the following email is a promotion email or not.
Class label: Promotion
Email: Check out our amazing new sale! We’ve got discounts on all of your favorite products.
Class label: Not Promotion
Email: We hope you are doing well. Let us know if you need any help.Task: Detect if the Reddit thread contains hate speech.
Class label: Hate Speech
Thread: All people of color are stupid and should not be allowed to vote.
Class label: Not Hate Speech
Thread: The best way to cook a steak on the grill.Task: Does the document supports the claim? Answer with "Support" or "Unsupport".
Class label: Unsupport
Document: After a record-breaking run that saw mortgage rates plunge to all-time lows and
home prices soar to new highs, the U.S. housing market finally is slowing. While demand and
price gains are cooling, any correction is likely to be a modest one, housing economists and
analysts say. No one expects price drops on the scale of the declines experienced during the
Great Recession.
Claim: The US housing market is going to crash soon.
Class label: Support
Document: The U.S. housing market is showing signs of strain, with home sales and prices
slowing in many areas. Mortgage rates have risen sharply in recent months, and the number
of homes for sale is increasing. This could be the beginning of a larger downturn, with some
economists predicting a potential housing crash in the near future.
Claim: The US housing market is going to crash soon.⋯Task: Which of the following is not an input type? (a) number (b) date (c) phone number (d)
email address (e) all of these are valid inputs.
Class label: (e)Task: {instruction for the target task}
Filtering and Postprocessing.
为了鼓励多样性,只有当新指令与现有指令的 ROUGE-L 相似度小于 0.7 时,才会将其添加到任务池中。我们还排除了包含某些特定关键字(e.g., image, picture, graph)的指令,这些关键字通常无法由 LM 处理。在为每条指令生成新实例时,我们会过滤掉完全相同的实例或输入相同但输出不同的实例。我们会根据启发式方法(如指令太长或太短、实例输出与输入重复)识别并过滤掉无效的生成。
2.3 Finetuning the LM to Follow Instructions
创建大规模指令数据后,我们将利用这些数据对原始 LM(即 SELF-INSTRUCT)进行微调。为此,我们将指令和实例输入串联起来作为提示,并以标准监督方式训练模型生成实例输出。为了使模型能够适应不同的格式,我们使用多种模板对指令和实例输入进行编码。例如,指令可以用 “Task:” 作为前缀,也可以不用;输入可以用 “Input:” 作为前缀,也可以不用;“Output:” 可以附加在提示的末尾,也可以不用;中间还可以加上不同数量的分隔线,等等。
3 SELF-INSTRUCT Data from GPT-3
本节将以 GPT-3 为案例,介绍我们的指令数据诱导方法。我们使用通过 OpenAI API 访问的最大 GPT-3 LM(“davinci” engine)。下面我们将对生成的数据进行概述。
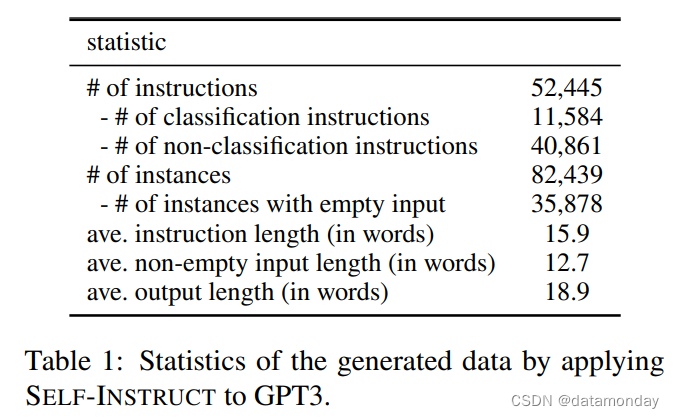
3.1 Statistics
表 1 描述了生成数据的基本统计数据。经过过滤后,我们总共生成了 52K 多条指令和 82K 多个与这些指令相对应的实例。
3.2 Diversity
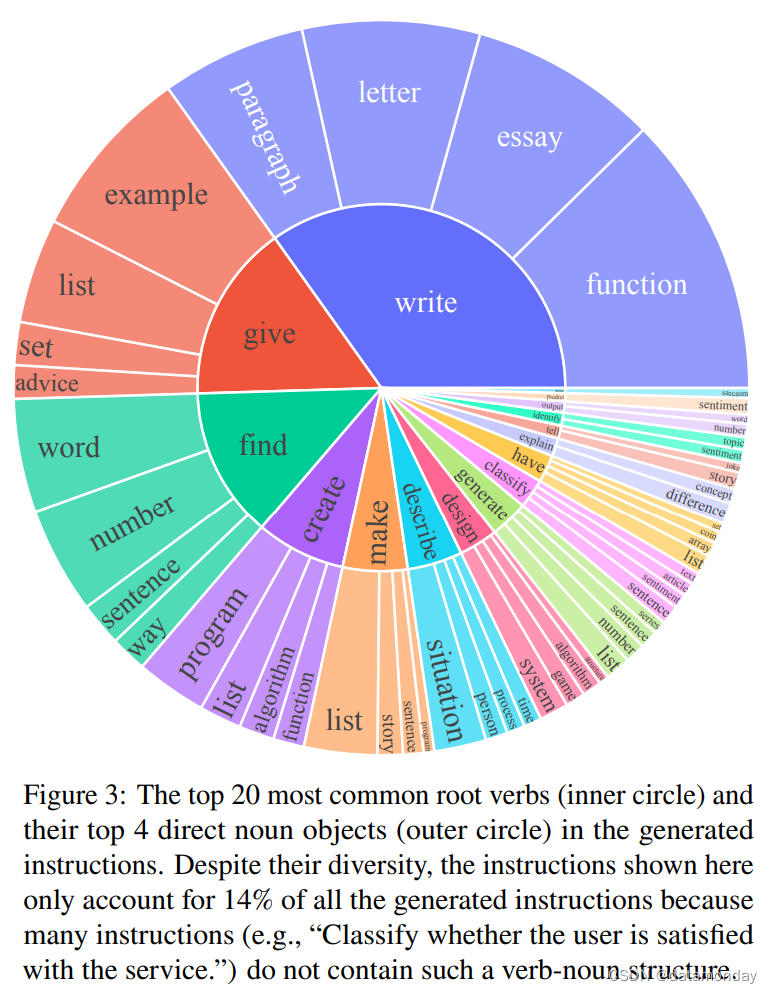
为了研究生成了哪些类型的指令以及它们的多样性,我们识别了生成指令中的动词-名词结构(verb-noun structure)。我们使用 Berkeley Neural Parser 来解析指令,然后提取最接近词根的动词及其第一个直接名词宾语。在 52,445 条指令中,有 26,559 条指令包含这种结构;其他指令通常包含更复杂的分句(e.g., “Classify whether this tweet contains political content or not.”)或以问题的形式提出(e.g., “Which of these statements are true?”)。我们在图 3 中绘制了前 20 个最常见的根动词及其前 4 个直接名词宾语,它们占整个数据集的 14%。总体而言,我们在这些指令中看到了相当多样的意图和文本格式。
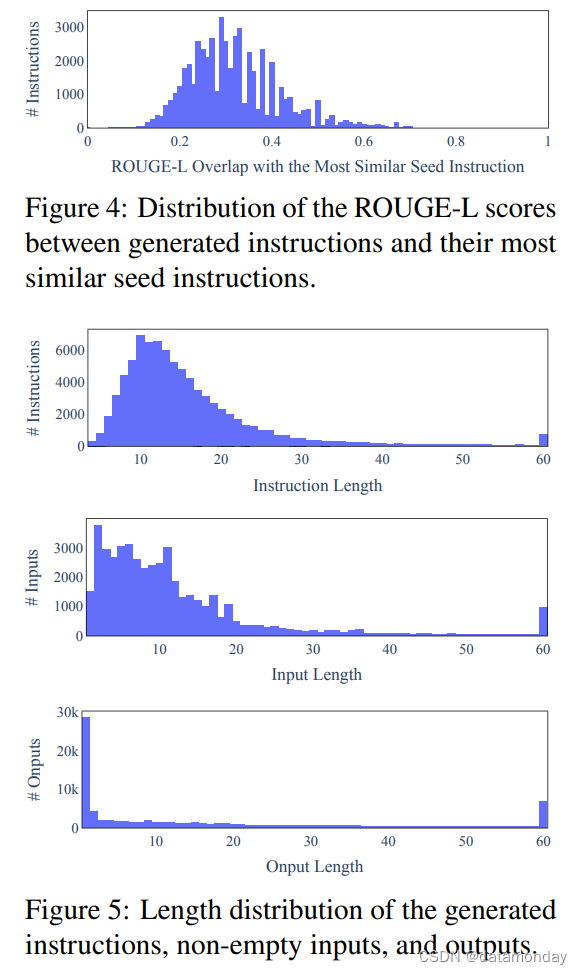
我们进一步研究生成的指令与用于提示生成的种子指令有何不同。对于每条生成的指令,我们计算其与 175 条种子指令的最高 ROUGE-L 重叠。我们在图 4 中绘制了这些 ROUGE-L 分数的分布图。结果表明,生成的新指令数量可观,但与种子指令的重合度不高。我们还在图 5 中展示了指令长度、实例输入和实例输出的多样性。
3.3 Quality
到目前为止,我们已经展示了生成数据的数量和多样性,但其质量仍不确定。为了研究这个问题,我们随机抽取了 200 条指令,每条指令随机抽取 1 个实例。我们请一位专家注释者从指令、实例输入和实例输出三个方面标注每个实例是否正确。表 2 中的评估结果表明,大多数生成的指令都是有意义的,而生成的实例可能包含较多噪音(在一定程度上)。不过,我们发现,即使生成的实例可能包含错误,但其中大部分仍然格式正确或部分正确,这可以为训练模型遵循指令提供有用的指导。我们在表 10 和表 11 中分别列出了一些好例子和坏例子。

4 Experimental Results
我们通过实验来衡量和比较模型在各种指令调优设置下的性能。我们首先介绍我们的模型和其他基线,然后进行实验。
4.1 GPT-3SELF-INST : finetuning GPT-3 on its own instruction data
鉴于指令生成的指令数据,我们使用 GPT-3 模型进行指令调优。如第 2.3 节所述,我们使用各种模板来连接指令和输入,并训练模型来生成输出。我们使用默认的超参数,只是将提示损失权重设为 0,训练了 2 个 epoch。更多微调细节请读者参阅附录 A.3。结果模型用 GPT-3 SELF-INST 表示。
4.2 Baselines
Off-the-shelf LMs.
我们将 T5-LM 和 GPT-3 作为普通 LM 的基线(无额外微调)进行评估。这些基线将表明现成的 LM 在预训练后能够立即自然地遵循指令的程度。
Publicly available instruction-tuned models.
T0 和 T𝑘-INSTRUCT 是两个指令调优模型,已被证明能够跟踪许多NLP任务的指令。这两个模型都是在 T5 检查点的基础上进行微调的,并且是公开的。
Instruction-tuned GPT-3 models.
我们对 InstructGPT 进行了评估,该模型由 OpenAI 基于 GPT-3 研发,旨在更好地遵循人类指令,并被社区认为具有令人印象深刻的零样本能力。在第 4.3 节的 SUPERNI 实验中,我们只与 text-davinci-001 engine 进行了比较,因为新引擎是用最新的用户数据训练的,很可能已经看过 SUPERNI 测试集。为了对新编写的指令进行人工评估,我们将 001、002 和 003 引擎也包括在内。
此外,为了将 SELF-INSTRUCT 训练与其他公开的指令调优数据进行比较,我们使用 PROMPTSOURCE 和 SUPERNI 的数据对 GPT-3 模型进行了进一步微调,这些数据用于训练 T0 和 T𝑘-INSTRUCT 模型。我们分别简称为 T0 训练和 SUPERNI 训练。为了节省训练预算,我们为每个数据集抽取了 50K 个实例(但涵盖其所有指令),其大小与我们生成的指令数据相当。根据 Wang 等人(2022 年)的研究结果和我们的早期实验,减少每个训练任务的实例数量不会降低模型对未见任务的泛化性能。
4.3 Experiment 1: Zero-Shot Generalization on SUPERNI benchmark
我们首先评估了模型在典型 NLP 任务中以零样本方式遵循指令的能力。我们使用了 SUPERNI 的评估集,该评估集由 119 个任务组成,每个任务中有 100 个实例。在这项工作中,我们主要关注的是零样本设置,即只向模型提示任务的定义,而不提供上下文演示示例。在对 GPT-3 变体的所有请求中,我们使用的是确定性生成模式(温度为 0,无核采样),没有特定的停止序列。
Results.
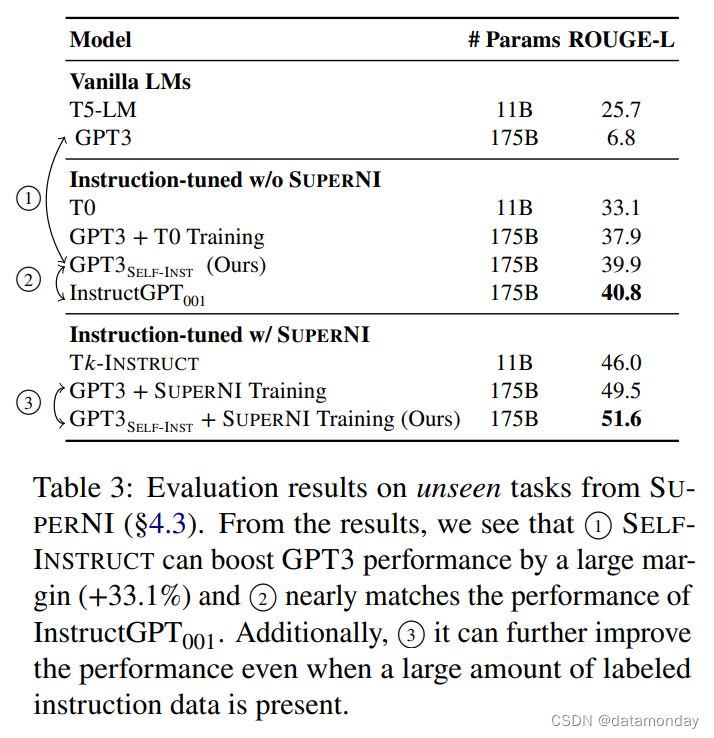
根据表 3 中的结果,我们得出以下结论。
- SELF-INSTRUCT 大幅提高了 GPT-3 的指令执行能力。普通的 GPT-3 模型基本上完全无法遵循人类指令。经过人工分析,我们发现它通常会生成不相关的重复文本,而且不知道何时停止生成。
- 与其他非专门为 SUPERNI 训练的模型相比,GPT-3SELF-INST 的性能要优于 T0 或在 T0 训练集上进行微调的 GPT-3,后者需要耗费大量的人工标注工作。值得注意的是,GPT-3 SELF-INST 的性能也几乎与 InstructGPT001 相当,后者是通过私人用户数据和人工标注进行训练的。
在 SUPERNI 训练集上训练的模型在其评估集上仍然取得了更好的性能,我们将其归因于相似的指令风格和格式。不过,我们发现 SELF-INSTRUCT 与 SUPERNI 训练集结合使用时仍能带来额外的收益,这证明了其作为补充数据的价值。
4.4 Experiment 2: Generalization to User-oriented Instructions on Novel Tasks
尽管 SUPERNI 全面收集了现有的 NLP 任务,但这些 NLP 任务大多是为研究目的而提出的,偏重于分类。为了更好地了解指令跟踪模型的实用价值,一部分作者从面向用户的应用出发,策划了一组新的指令。我们首先对大型 LM 可能有用的各种领域(如电子邮件写作、社交媒体、生产力工具、娱乐、编程)进行了头脑风暴,然后制作了与每个领域相关的指令以及输入-输出实例(同样,输入是可选的)。我们的目标是使这些任务的风格和格式多样化(例如,指令可长可短;输入/输出可采用要点、表格、代码、方程式等形式)。我们总共创建了 252 条指令,每条指令有 1 个实例。我们相信,它可以作为评估基于指令的模型如何处理各种陌生指令的试验平台。表 9 介绍了其中的一小部分。整个指令集可在我们的 GitHub 存储库中找到。我们将在 §A.1 中分析该指令集与种子指令之间的重叠。

Human evaluation setup.
由于不同的任务需要不同的专业知识,因此评估模型在这些不同任务中的表现极具挑战性。事实上,其中许多任务无法用自动指标来衡量,甚至无法由普通的群众工作者来评判(例如,编写程序或将一阶逻辑转换为自然语言)。为了获得更忠实的评估,我们请提出指令的作者对模型预测进行判断。附录 B 详细描述了我们如何设置这项人工评估。我们要求评估人员根据输出结果是否准确有效地完成任务对其进行评分。我们采用了一个四级评分系统来对模型输出的质量进行分类:
- 评分-A:回答有效且令人满意。
- 评分-B:回答可以接受,但有轻微错误或不完善之处。
- 评分-C:答复是相关的,对指令做出了回应,但在内容上有重大错误。例如,GPT-3 可能首先生成一个有效的输出,但会继续生成其他不相关的内容。
- 评分-D:答复不相关或完全无效。
Results.
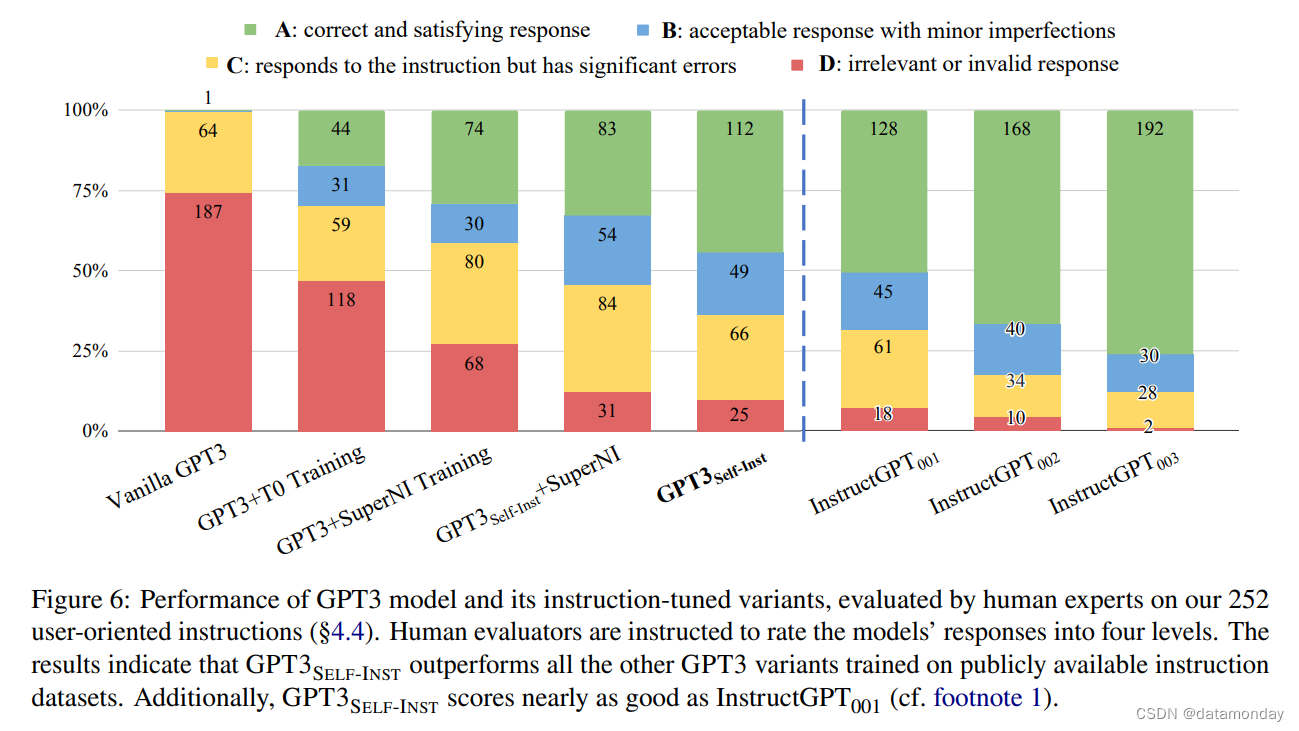
图 6 显示了 GPT-3 模型及其经过指令调优的对应模型在新编写的指令集上的表现(在 4 级分类量表上,评分者之间的一致性 𝜅 = 0.57,详见附录 B)。正如预期的那样,普通的 GPT-3 LM 基本上无法对指令做出反应,而所有经过指令调优的模型都表现出了相对较高的性能。尽管如此,GPT-3SELF-INST(即使用 SELF-INSTRUCT 进行微调的 GPT-3 模型)的表现还是远远优于那些在 T0 或 SUPERNI 数据上训练的模型,这表明尽管存在噪声,生成的数据还是有价值的。与 InstructGPT001 相比,GPT-3SELF-INST 的性能相当接近–如果我们将有轻微瑕疵的可接受响应(RATING-B)算作有效响应,那么 GPT-3SELF-INST 仅比 InstructGPT001 落后 5%。最后,我们的评估证实了 InstructGPT002 和 InstructGPT003 令人印象深刻的指令遵循能力。虽然这一成功背后有很多因素,但我们猜想,通过使用人工标注或训练奖励模型来选择更好的生成,类似于 RLHF,提高生成数据的质量在很大程度上会使未来的工作受益。
4.5 Effect of Data Size and Quality
Data size.
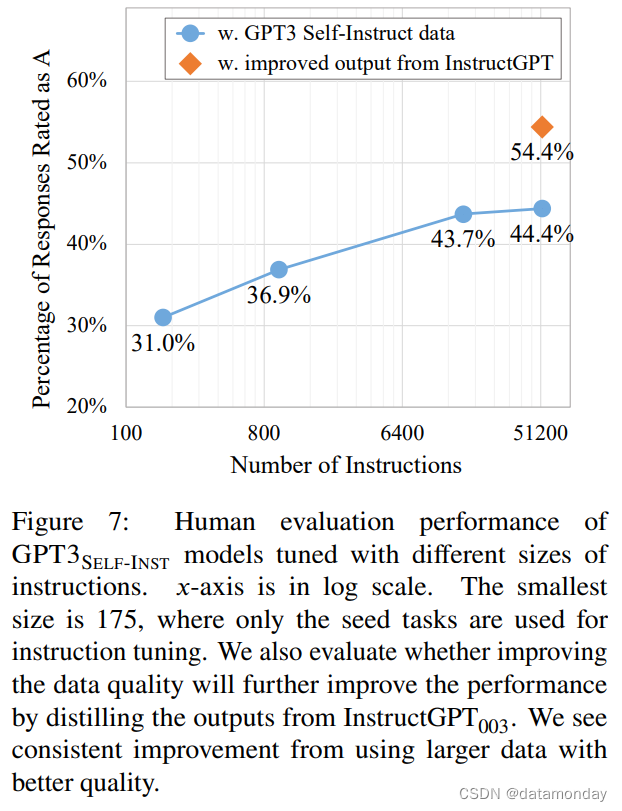
SELF-INSTRUCT 提供了一种低成本、几乎无需人工标注的指令数据增长方式。我们从生成的数据集中抽取不同数量的指令,在抽取的子集中对 GPT-3 进行微调,并评估生成的模型在 252 个面向用户的指令集中的表现,从而对生成数据的规模进行分析。我们进行了与第 4.4 节相同的人工评估。图 7 显示了使用不同大小的生成数据对 GPT-3 SELF-INST 模型进行微调后的性能。总的来说,随着数据量的增加,我们看到了持续的改进。不过,这种改进在 16K 之后几乎趋于平稳。这与 Wang 等人的数据缩放实验一致。有趣的是,在 SUPERNI 上进行评估时,我们发现该模型的性能增益在数百条指令左右就出现了停滞。这可能是由于新生成的数据与 SUPERNI 中典型的 NLP 任务不同,这表明未来的研究可能会受益于使用不同指令数据的组合,从而在各种类型的任务中获得更好的性能。
Data quality.
提高模型性能的另一个方向是利用我们生成的数据,获得更好的监督(噪音更小)。我们利用 InstructGPT003(现有最佳通用模型)来重新生成所有实例的输出字段(给定指令和输入),从而探索这一思路。然后,我们使用这一改进版数据对 GPT-3 进行微调。这可以看作是利用我们的数据对 InstructGPT003 进行的提炼。如图 7 所示,生成的模型比使用原始数据训练的模型高出 10%,这表明未来在使用我们的生成管道获取初始数据,然后通过人类专家或从更好的模型中提炼数据来提高数据质量方面还有很大的工作空间。
5 Related Work
Instruction-following LMs.
一系列研究表明,如果使用标注的指令数据——包含语言指令及其基于人类注释的预期结果的数据集进行微调,LM 可以有效地遵循一般语言指令。此外,这些研究还表明,指令数据的规模和多样性与由此产生的模型对未见任务的泛化性之间存在直接关联。然而,由于这些发展主要集中在现有的 NLP 任务上,并且依赖于人类标注的指令,这对建立更具通用性的模型构成了瓶颈。我们的工作旨在超越经典的 NLP 任务,通过使用预训练的 LM 来应对创建多样化指令数据的挑战。InstructGPT 与我们的目标相似,都是建立更通用的 LM,并在遵循不同用户指令方面表现出了不俗的性能。然而,作为一个商业系统,其构建过程仍然相当不透明。特别是,由于透明度有限以及他们在研究中使用的用户私人数据,数据的作用仍未得到充分研究。要应对这些挑战,就必须创建一个涵盖广泛任务的大规模公共数据集。
Language models for data generation and augmentation.
许多研究都建议使用 LMs 生成数据或增强数据。我们的研究与上述研究的不同之处在于,它并不针对特定的任务(如 QA 或 NLI)。与此相反,SELF-INSTRUCT 的一个独特动机是引导新的任务定义,而这些任务定义可能是 NLP 从业人员以前从未定义过的(尽管可能对真实用户仍然很重要)。与我们的工作并行的是,Honovich 等人(2022a)也建议用 GPT-3 模型生成大规模指令数据(即非自然指令)。他们的主要区别在于:1)他们使用 SUPERNI 中的任务作为种子任务,导致生成任务的分布不同;2)他们使用 InstructGPT002 生成数据,从这个意义上说,他们是从已经经过指令调优的模型中提炼知识,而我们则完全依赖于 vanilla LM;3)详细的生成管道和模板不同。尽管如此,我们认为这两种扩展指令数据的努力是互补的,社区将从这些不同的数据集中受益。
Instruction generation.
最近的一系列工作都是在给定几个实例的情况下生成任务指令。虽然 SELF-INSTRUCT 也涉及指令生成,但我们的主要区别在于它与任务无关;我们从头开始生成新任务(指令和实例)。
Model self-training.
典型的自我训练框架使用训练好的模型为未标记的数据分配标签,然后利用新标记的数据改进模型。与此类似,Zhou 等人(2022a)使用多个提示来指定一个任务,并建议通过提示一致性进行正则化,鼓励对提示进行一致的预测。这样就可以利用额外的未标注训练数据对模型进行微调,或在推理时直接应用。虽然 SELF-INSTRUCT 与自我训练文献有相似之处,但大多数自我训练方法都假设了一个特定的目标任务以及该任务下的未标注示例;相比之下,SELF-INSTRUCT 可以从头开始生成各种任务。
Knowledge distillation.
知识蒸馏通常涉及将知识从大型模型转移到小型模型。自我构建也可被视为一种知识蒸馏形式,但它与这一思路有以下不同之处:1)蒸馏的源头和目标是相同的,即模型的知识被蒸馏到自身;2)蒸馏的内容是指令任务形式(即定义任务的指令和实现任务的实例集)。
Bootstrapping with limited resources.
最近的一系列工作使用语言模型,用专门的方法引导一些推论。NP Prompt 提供了一种无需任何微调即可生成语义标签预测的方法。它使用模型自身的嵌入来自动查找与数据样本标签相关的单词,从而减少了从模型预测到标签(动词化)之间的人工映射依赖。STAR 通过反复利用少量推理实例和大量无推理的数据集来引导模型的推理能力。Self-Correction 将不完善的基础生成器(模型)与单独的校正器分离开来,该校正器学会迭代校正不完善的生成器,并展示出对基础生成器的改进。我们的工作重点是在指令范式中引导新任务。
Multi-modal instruction-following.
多模态学习文献也对指令遵循模型很感兴趣。SELF-INSTRUCT 作为一种扩展数据的通用方法,在这些环境中也可能有所帮助,这一点我们将留待今后的工作中进行探讨。
6 Conclusion
我们介绍了 SELF-INSTRUCT,这是一种通过自行生成指令数据来提高 LM 指令跟踪能力的方法。在对 vanilla GPT-3 进行实验的基础上,我们自动构建了一个包含 52K 条不同任务指令的大型数据集,并在此数据基础上对 GPT-3 进行了微调,从而使 SUPERNI 比原始 GPT-3 的绝对性能提高了 33%。此外,我们还为新任务策划了一组由专家编写的指令。在这组数据上进行的人工评估显示,使用 SELF-INSTRUCT 对 GPT-3 进行调整后,其性能大大优于现有的公共指令数据集,而且与 InstructGPT001 的性能非常接近。我们希望 SELF-INSTRUCT 可以作为调整预训练 LM 以遵循人类指令的第一步,而未来的工作可以在此数据的基础上改进指令遵循模型。
7 Broader Impact
除了本文的直接关注点之外,我们还认为 SELF-INSTRUCT 可能有助于提高广泛使用的指令调整模型(如 InstructGPT 或 ChatGPT)幕后工作的透明度。遗憾的是,由于这些工业模型的数据集未被公布,因此它们仍被隐藏在 API 墙之后,人们对它们的构造以及它们为何能展示出令人印象深刻的能力知之甚少。现在,学术界有责任更好地了解这些模型的成功源泉,并努力开发更好、更开放的模型。我们相信,我们在本文中的发现证明了多样化指令数据的重要性,而我们的大型合成数据集可以作为迈向更高质量数据的第一步,从而建立更好的指令模型。在撰写本文时,本文的中心思想已被多篇后续著作所采用,以开展此类工作。
8 Limitations
在这里,我们讨论了这项工作的一些局限性,以激发未来在这个方向上的研究。
Tail phenomena.
自我构建依赖于 LM,它将继承 LM 的所有局限性。最近的研究表明尾部现象对 LMs 的成功构成了严峻挑战。换句话说,LMs 的最大收益与语言的频繁使用(语言使用分布的头部)相对应,而低频上下文中的收益可能微乎其微。同样,在本研究中,如果 SELF-INSTRUCT 的大部分增益偏向于在预训练语料库中出现频率较高的任务或指令,也不足为奇。因此,该方法可能会在不常见和创造性指令方面表现欠佳。
Dependence on large models.
由于 SELF-INSTRUCT 依赖于从 LMs 中提取的归纳偏差,它可能最适合大型模型。如果情况属实,这可能会对那些没有大型计算资源的人造成使用障碍。我们希望未来的研究能仔细研究收益与模型大小或其他各种参数的函数关系。值得注意的是,使用人工标注进行指令调优也存在类似的局限性:对于较大的模型,指令调优的收益更高。
Reinforcing LM biases.
作者担心的一点是这种迭代算法会产生意想不到的后果,比如放大有问题的社会偏见(对性别、种族等的刻板印象或诽谤)。与此相关的是,在这一过程中观察到的一个挑战是该算法难以产生平衡的标签,这反映了模型之前的偏见。我们希望未来的工作能让我们更好地理解这种方法的利弊。
A Implementation Details
A.1 Writing the Seed Tasks
A.2 Querying the GPT-3 API
A.3 Finetuning GPT-3
A.4 Prompting Templates for Data Generation
B Human Evaluation Details for Following the User-oriented Instructions
B.1 Human Evaluation Setup
B.2 Human Evaluation Agreement
B.3 Example Predictions from GPT-3SELF-INST
C Task and Instance Examples from the Generated Instruction Data
这篇关于【EAI 023】Self-Instruct: Aligning Language Models with Self-Generated Instructions的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





![[论文笔记]Making Large Language Models A Better Foundation For Dense Retrieval](https://img-blog.csdnimg.cn/img_convert/6dbbf911e7e57daa6ac5366f311e3e68.png)

