instructions专题

Assembly instructions 汇编指令解析 AAT
Assembly instructions 汇编初步学习 汇编0基础的戳上面,刷一遍,包治百病 %eax寄存器的值与C语言的return的值相对应 (%esp)地址处储存的是函数的返回地址 return addre

【论文笔记】Training language models to follow instructions with human feedback B部分
Training language models to follow instructions with human feedback B 部分 回顾一下第一代 GPT-1 : 设计思路是 “海量无标记文本进行无监督预训练+少量有标签文本有监督微调” 范式;模型架构是基于 Transformer 的叠加解码器(掩码自注意力机制、残差、Layernorm);下游各种具体任务的适应是通过在模型架

【论文笔记】Training language models to follow instructions with human feedback A部分
Training language models to follow instructions with human feedback A 部分 回顾一下第一代 GPT-1 : 设计思路是 “海量无标记文本进行无监督预训练+少量有标签文本有监督微调” 范式;模型架构是基于 Transformer 的叠加解码器(掩码自注意力机制、残差、Layernorm);下游各种具体任务的适应是通过在模型架

The TensorFlow library wasn't compiled to use SSE4.1 instructions, but these are available...
跑 tensorflow 官方教程时报warning: 2017-06-08 22:36:18.809242: W tensorflow/core/platform/cpu_feature_guard.cc:45]The TensorFlow library wasn't compiled to use SSE4.1 instructions, but these are availabl

Training language models to follow instructions with human feedback
Abstract 使语言模型变得更大并不意味着它们本身就能更好地遵循用户的意图。模型的输出结果可能存在以下问题 不真实有毒对用户没有帮助 即这些模型没有和用户 “对齐”(aligned) 在给定的 Prompt 分布上,1.3B 的 InstructGPT 的输出比 175B GPT-3 的输出更好(尽管参数量相差 100 多倍)。 1 Introduction 语言建模的目标:pr
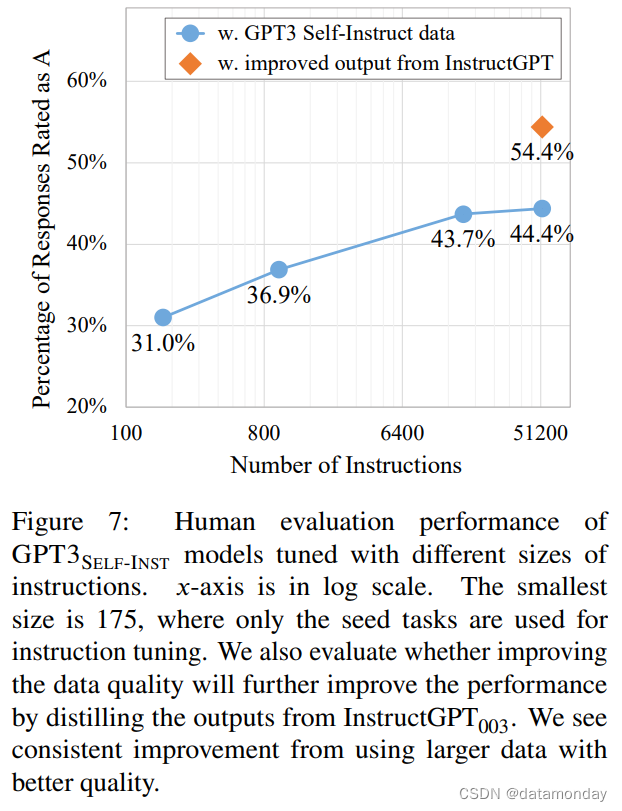
【EAI 023】Self-Instruct: Aligning Language Models with Self-Generated Instructions
Paper Card 论文标题:Self-Instruct: Aligning Language Models with Self-Generated Instructions 论文作者:Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A. Smith, Daniel Khashabi, Hannaneh Hajishi
tensorflow | Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX
报错: Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX AVX2 解决: 1.重新安装python3.7.2 2.打开 https://github.com/fo40225/tensorflow-windows-wheel 在里面找到对应的.whl文件 报错提示
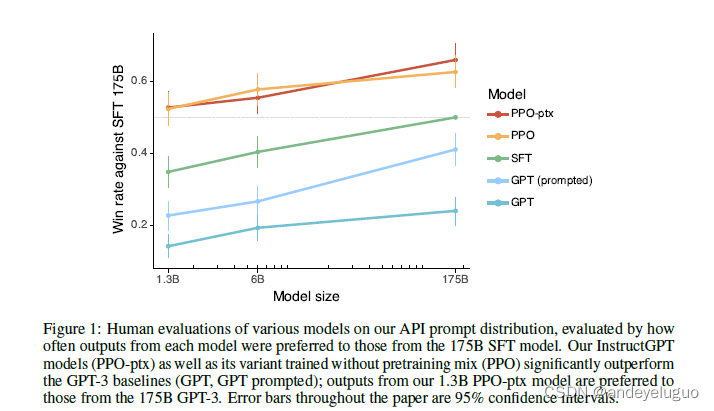
《Training language models to follow instructions》论文解读--训练语言模型遵循人类反馈的指令
目录 1摘要 2介绍 方法及实验细节 3.1高层次方法论 3.2数据集 3.3任务 3.4人体数据收集 3.5模型 3.6评价 4 结果 4.1 API分布结果 4.2公共NLP数据集的结果 4.3定性结果 问题 1.什么是rm分数 更多资料 1摘要 使语言模型更大并不能使它们更好地遵循用户的意图。例如,大型语言模型可能生成不真实的、有害的或对用户

转 -安装tensorflow遇到:Your CPU supports instructions that this TensorFlow binary was not compiled to use
本文转自:https://www.cnblogs.com/theWinter/p/8244685.html 感谢原作者分享。 正文如下: 为了提升CPU计算速度的。若你有支持cuda的GPU,则可以忽略这个问题,因为安装SSE4.1, SSE4.2, AVX, AVX2, FMA, 仅仅提升CPU的运算速度(大概有3倍)。 解决方法: 忽视警告,并屏蔽警告 开头输入如下: import

ICLR 2024 | Mol-Instructions: 面向大模型的大规模生物分子指令数据集
发表会议:ICLR 2024 论文标题:Mol-Instructions: A Large-Scale Biomolecular Instruction Dataset for Large Language Models 论文链接:https://arxiv.org/pdf/2306.08018.pdf 代码链接:https://github.com/zjunlp/Mol-Instructio
《Training language models to follow instructions》论文解读--训练语言模型遵循人类反馈的指令
1摘要 使语言模型更大并不能使它们更好地遵循用户的意图。例如,大型语言模型可能生成不真实的、有害的或对用户没有帮助的输出。换句话说,这些模型与它们的用户并不一致。在本文中,我们展示了一种方法,通过对人类反馈进行微调(核心idea),在广泛的任务中使语言模型与用户意图保持一致。从一组标注器编写的提示和通过OpenAI API提交的提示开始,我们收集了一个标注器演示所需模型行为的数据集,我们使用它来
Principled Instructions Are All You Need for Questioning LLaMA-1/2, GPT-3.5/4
Q: 这篇论文试图解决什么问题? A: 这篇论文旨在简化查询和提示大型语言模型(LLMs)的过程,提出了26个指导原则,以增强用户对不同规模LLMs行为的理解。这些原则旨在改善LLMs的提示设计,提高LLMs在各种任务中的表现,尤其是在生成问题答案时。论文的目标是为研究人员提供更好的指导,以便在提示LLMs时能够获得更高质量的响应。 Q: 有哪些相关研究? A: 这篇论文提到了以下相关研究:

Branch Vanguard:Decomposing Branch Functionality into Prediction and Resolution Instructions
Branch Vanguard: Decomposing Branch Functionality into Prediction and Resolution Instructions 摘要: 问题:控制推测在乱序处理器中能够产生非常有效的调度,但是对于按序处理器却不够有效,因为编译在遇到无偏置分支的情况时会出现错误的调度,尽管这些分支具有很高的可预测性解决:论文提出了一种新的体系结构分支解
Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX
Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX 警告说你的tensorflow不能使用SSE4.1 SSE4.2 AVX AVX2 FMA这些CPU矢量运算的指令码进行编译。 为了提升CPU计算速度的。若你有支持cuda的GPU,则可以忽略这个问题,因为安装SSE4
SELF-INSTRUCT: Aligning Language Models with Self-Generated Instructions
本文是LLM系列文章,针对《SELF-INSTRUCT: Aligning Language Models with Self-Generated Instructions》的翻译。 自我指导:将语言模型与自生成的指令相结合 摘要1 引言2 方法3 来自GPT3的自学数据4 实验结果5 相关工作6 结论 摘要 大型“指令调整”语言模型(即,微调以响应指令)已经证明了将零样本推广到

论文笔记:Self-Instruct: Aligning Language Model with Self Generated Instructions
论文笔记:Self-Instruct: Aligning Language Model with Self Generated Instructions Q同学 2023-04-22 08:411630 导语 本文介绍了如何使用LLM来大规模自动生成instruction。实验结果表明,这种数据增强方式非常有效,接下来就让我们看看具体是怎么做的吧。 会议:Arxiv链接:arxiv.or
Unnatural Instructions: Tuning Language Models with (Almost) No Human Labor
本文是LLM系列文章,针对《Unnatural Instructions: Tuning Language Models with (Almost) No Human Labor》的翻译。 @TOC 摘要 指令调优使预训练的语言模型能够从推理时间的自然语言描述中执行新的任务。这些方法依赖于以众包数据集或用户交互形式进行的大量人工监督。在这项工作中,我们介绍了非自然指令:一个创造性和多样化指令的
Can Large Language Models Understand Real-World Complex Instructions?
本文是LLM系列文章,针对《Can Large Language Models Understand Real-World Complex Instructions?》的翻译。 大型语言模型能理解现实世界的复杂指令吗? 摘要引言相关工作CELLO基准实验结论 摘要 大型语言模型(llm)可以理解人类指令,显示出它们在传统NLP任务之外的实用应用潜力。然而,它们仍然在与复杂的指令作