本文主要是介绍Branch Vanguard:Decomposing Branch Functionality into Prediction and Resolution Instructions,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Branch Vanguard: Decomposing Branch Functionality into Prediction and Resolution Instructions
-
摘要:
- 问题:控制推测在乱序处理器中能够产生非常有效的调度,但是对于按序处理器却不够有效,因为编译在遇到无偏置分支的情况时会出现错误的调度,尽管这些分支具有很高的可预测性
- 解决:论文提出了一种新的体系结构分支解耦方法,能够将分支的预测点和分支解决时的去分歧点分开,从而能够使得编译器能够跨域那些非偏置却可预测的分支进行有效的调度
- 这种方式对硬件的改动非常小,只需要一些很少的扩展即可
- 论文同时描述了一种简单的代码转换过程,以展示如何利用这种体系结构支持
- 主要应用领域:二进制翻译,例如Project Denver(ARM的)
- 实验评估:在按序处理器配置中,对spec 2006进行转换,然后进行性能评估
- spec 2006定点程序,加速比的几何平均为11%,最大加速比35%
- spec 2006浮点程序,加速比的几何平均为7%, 最大加速比26%
-
介绍
-
控制相关在按序处理器是影响性能的一个主要挑战,尤其是发射宽度大于1时(超标量,VLIW,DSP,GPU)。虽然有些处理器可以将分支之后的指令与分支指令并行发射,但是获得的好处有限,因为控制相关的主要影响是对编译的代码调度产生的影响
-
跨基本块调度的两个挑战:hoisted instruction(提升的指令,应该是指分支之后的指令被提到分支之前执行,即提升)
- 提升的指令不能具有违反源程序语义的用户可见的副作用
- 提升指令的好处必须与执行从错误路径上提升的指令所带来的成本相平衡
-
针对与非偏置分支的在编译中的解决办法:将条件分支转换为断言的形式(predication)。在某些情况下,将控制相关转换为数据相关并且执行两条路径的开销小于分支错误恢复的平摊代价。但是如果分支是可预测的,则使用错误谓词执行带来的开销将会是本可以被避免的

-
论文贡献:
- 提出了一种新的在体系结构层面上对分支的解耦和,即分支被解耦为一条分支预测指令和一条分支解决指令(resolution)
- 论文给出了一种低复杂度的转换过程,能够在按序超标量处理器显示的利用分支的可预测性
- 论文进一步探讨了实现这种转换的硬件支持,并且在几种按序的配置下,评估了在spec2000和spec2006上的性能改进
- 最后论文证明了该技术对分支预测准确率的敏感性
-
-
分解分支的行为(decomposing)
-
之前研究中对分支的分解:三个部分
- 目标指令TS(target specification):提供构建分支目标所需要的信息
- 条件计算CC(condition computation):单个或者多个值上的比较操作,用于决定是否跳转
- 控制流转移CFT(control flow transfer):控制流改变实际发生的程序点
-
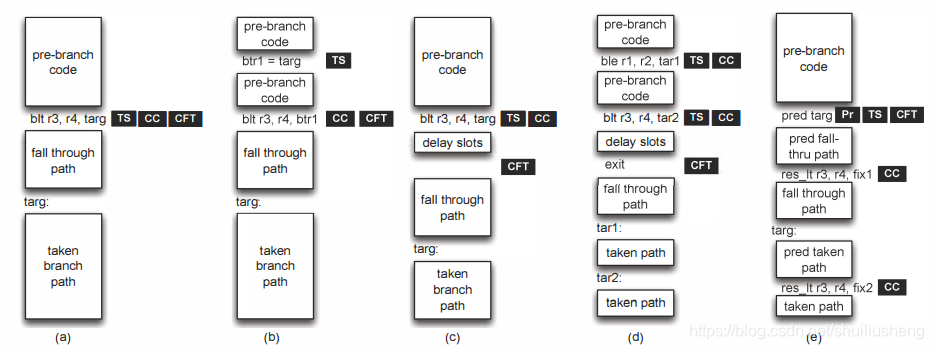
之前技术的图解:
- 图a中是正常三个部分在同一个操作中完成的情形,普通的体系结构的案例
- 图b是将TS和剩下的两个部分分开。对于直接分支,分支目标是静态的,所以可以在分支指令之前利用这个信息(包括预测信息)预取分支目标处的指令
- 图c和图d是将CFT和分支的其它部分分开,如果分支条件能够尽早的计算出来,这种分解将很有效,因为可以避免分支预测。图c中使用分支延迟槽来缓解分支条件计算时处理器的等待。图d是IBM ACS分支的处理方式,通过利用exit指令来指示控制流转移的位置,这种方式还允许多个分支指令和单个exit指令相关联,即图中的多路分支
- 图e是论文提出的解耦方式,能够在分支解决之前就进行控制流转移
-
预测-解决解耦和(prediction-resolution)
- 论文在之前提出的分支的三个组成部分的基础上增加了一个新的部分:预测(Pr),前端预测分支结果的点
- 具体而言,论文将一条分支分解成两条指令:
- 预测指令(predict):该指令只包括操作码和目标地址,当取值时,使用BP进行预测,如果预测发生跳转,根据目标地址进行跳转
- 解决指令(resolve):类似于正常的分支指令,但是有一个特殊的操作码,在前端总预测为不跳转。如果解决指令的结果和预测指令的预测不同,则控制流从新转移到解决指令指定的目标地址,同时预测指令对应的分支预测器部分需要被更新
-
通过DBT改变体系结构(dynamic binary translation)
- 论文提出的技术仅用于解决按序微架构中的问题,因此不建议在主流ISA中使用该技术。并且论文的根本攻击是基于动态二进制翻译类的结构,例如Transmeta Crusoe和Project Denver。在这些结构中主流的ISA都会在运行时由软件翻译成特定于微体系结构(通常为VLIW)的隐藏ISA。 因为在这种情况下,扩展ISA几乎没有成本
- 基于VLIW的DBT结构的一些有用的特点:
- 非故障/故障延迟load指令:允许将load指令提升到原始程序不会执行到的路径上
- 支持数据推测:允许将load指令提升到可能会引起混叠(aliasing)的store之后
- 额外用于保存推测值的寄存器:在编译时可以不需要将利用堆栈进行数据保存
-
-
分支解耦的转换过程
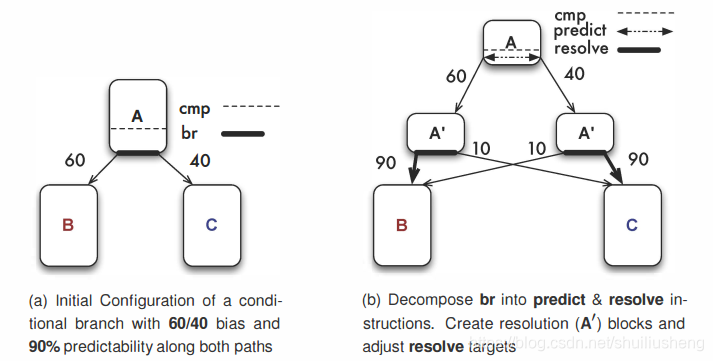
-
图a是一个正常代码的结构,基本块A中包括一个条件分支指令(比较指令CMP和分支指令Br),有两个可能的方向B/C,在每个方向上的偏置程度为60/40,即属于低偏置分支,但是有90%的可能预测正确
-
图b将BR指令分解为predict指令和resolve指令,同时基本块A也被分解成三个块A和两个A‘,predict指令在A块中,resolve指令在每一个A’块的出口处,并且此时A‘中只包括resolve指令。图中左侧的A’直接后续是B(很有可能直接执行),同时将resolve的目标地址设置为C(发现错误预测时跳转到C)。此时左侧的A’和B,右侧的A‘和C组成了两对高偏置分支
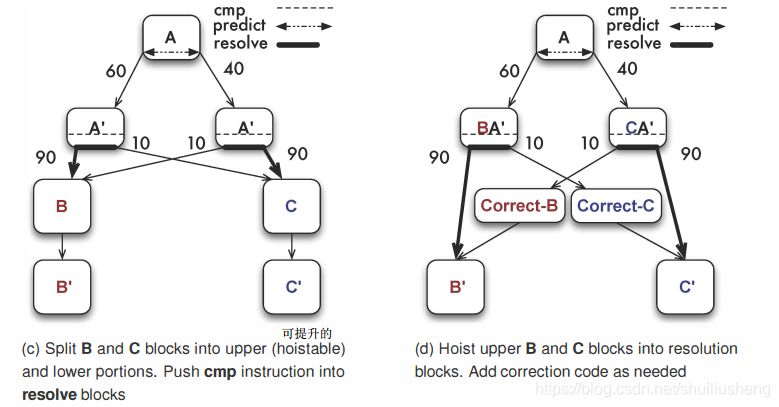
-
图c:在b的基础上,由于A‘和B/C有高偏置的属性,因此将B/C分解成两个部分,B和B’。B为上半部分包含着可以被提升的指令,B‘则是不能够被提升的指令(提升意味着可以在resolve指令之前执行,但是不会带来负面影响)。同时原条件分支的CMP部分被下移到每个A’中,即在predict指令之后
-
图d:将之前B/C分解得到的可提升的指令放到对应的A‘中的resolve指令之前,和CMP组合在一起,可以被编译器统一调度(例如组成VLIW)。此时组成的BA’块将会指向B’和Correct-C。Correct-C是在resolve发现结果和predict指令不同时,首先跳转到不包含resolve指令的可提升的C的代码,即Correct-C,然后Correct-C执行完成之后再执行C‘(剩余的代码)
-
在某些情况下,需要在推测代码中BA’中使用临时寄存器保存某些值,以防止在预测错误时修改了正确的体系结构状态,同时也避免了错误预测之后的恢复问题。在resolve指令执行时,在确定预测正确时,将临时寄存器在写回体系结构寄存器
-
除了使用临时寄存器避免更改体系结构状态,也可以在Correct-X中增加补偿代码,以恢复错误路径上产生的体系结构影响,从而不需要使用临时寄存器
-
在推测的代码中,另一个需要注意的时需要使用不会产生异常的指令,例如不产生错误异常的load指令
-
-
硬件支持
-
需要在流水线的前端正确的更新分支预测器
-
论文设计的解耦和结构会使得分支预测器更新和处理器错误预测恢复方式稍微更加复杂,因为resolve指令有两个功能:
- 当predict指令预测错误时,重定位到修复状态的代码,然后才能够在正确路径上重新执行(如果使用临时寄存器,则可以直接跳转到正确路径的指令执行)
- 向分支预测器提供反馈,以更新resolve指令对应的predict指令相关联的预测器表项(因此需要找到resolve指令和predict指令之间的联系)
-
论文在前端增加一个缓冲,用于记录resolve和predict之间的联系,称之为DBB(解耦分支缓冲)
-
按序处理器中分支指令按序取值和执行,并以也不会重新调整predict和resolve指令的位置(两对指令交叉放置)
-
结构:利用一个尾指针组织成FIFO结构的环形缓冲,用于记录解耦分支的元数据
-
DBB的插入操作:predict指令在译码时被发现,然后利用预测器进行正常的分支预测。在预测结束之后,增加DBB的尾指针,将预测结果和所有在更新时需要的元数据保存在DBB中此时尾指针对应的DBB表项中
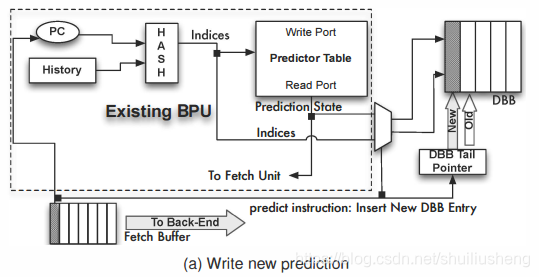
-
在predict指令之后的某个地方,相应的resolve指令被取值,此时对应的predict指令的信息将在DBB的尾指针对应的表项中。随后将DBB的尾指针随着该resolve指令保存起来,继续在流水线中传递
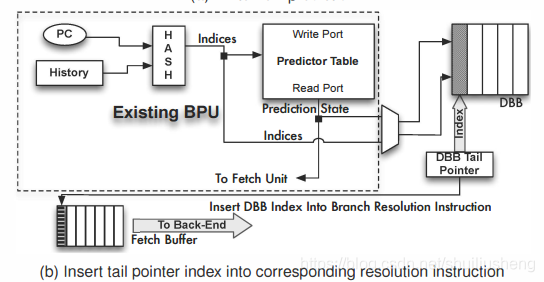
-
当resolve指令检测到预测错误时,会将正确路径的PC和DBB索引传递回取值单元。通过DBB中记录的信息,更新分支预测器即可
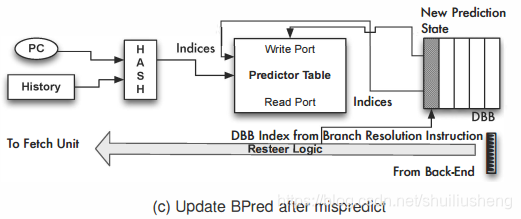
-
当发生非解耦分支的错误预测时,在恢复处理器状态时需要恢复正确的DBB尾指针,以保证predict和resolve指令之间的对应关系
-
在执行阶段遇到中断,异常和上下文切换事件,从而导致错误的predict和resolve之间的对应关系。解决:忽略这些极少出现的事件;标记DBB表项为无效表项,从而放置错误更新预测器
-
-
-
实验
-
实验平台:LLVM3.5+PTLSim(一个周期精确的全系统x86-64微结构模拟器)
-
处理器参数配置:三种不同宽度的按序超标量处理器(宽度为2,4,8)
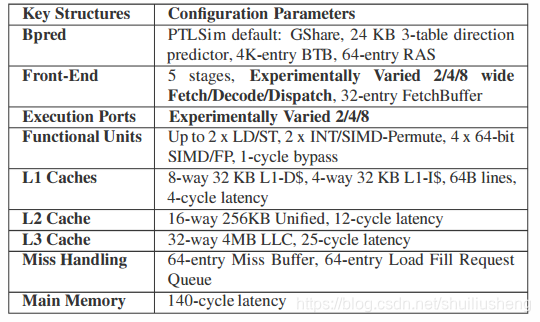
-
实验结果
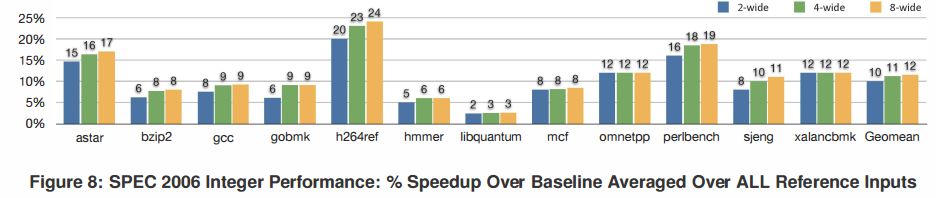

-
这篇关于Branch Vanguard:Decomposing Branch Functionality into Prediction and Resolution Instructions的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







