本文主要是介绍【大模型 数据增强】Evol-Instruct 应用:扩充大模型数据多样性,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Evol-Instruct 应用:扩充大模型数据多样性
- 提出背景
- 流程步骤
- 总结
- Evol-Instruct 代码复现
- Evol-Instruct 应用:扩充大模型数据多样性
提出背景
论文:https://arxiv.org/pdf/2304.12244.pdf
代码:https://github.com/nlpxucan/WizardLM
Evol-Instruct 利用大模型生成指令的方法,可生成相对复杂和多样的指令数据集。
- 子问题1:初始指令集的限制(人类懒得写复杂指令)
子解法1:指令数据演化- 特征: 需要将初始指令集(D(0))升级,以产生更多样化的指令。
- 目的: 通过演化提高指令的复杂度和响应性,增强模型对不同类型指令的处理能力。
现在有一个创业方向,就是给带货行业写指令,一条好的指令可以卖到 5000-几万块,但复杂的指令十分烧脑。
-
子问题2:生成复杂指令的需求
子解法2:指令演化者(Instruction Evolver)- 特征: 使用特定提示(prompts)来使指令更复杂和困难。
- 目的: 产生高质量的、难度逐步增加的指令,避免过度复杂化影响模型泛化性能。
-
子问题3:指令多样性不足
子解法3:广度演化(In-Breadth Evolving)- 特征: 通过创建与给定指令基于同一领域但更为罕见的全新指令来增加主题和技能覆盖面。
- 目的: 扩展数据集的主题和技能多样性,增强模型的综合应用能力。
-
子问题4:演化失败的指令的筛选
子解法4:淘汰演化(Elimination Evolving)- 特征: 识别和过滤那些没有提供信息增益、难以生成响应、只包含标点和停止词、或明显复制了演化提示词汇的指令。
- 目的: 保证指令集的质量,提供有效的数据用于模型训练。
-
子问题5:如何有效地微调LLM
子解法5:在演化指令上微调LLM- 特征: 将所有演化的指令数据与初始指令集合并,随机洗牌以创造最终的微调数据集。
- 目的: 确保在数据集中指令难度级别的均匀分布,最大化模型微调的平滑性。
流程步骤
Evol-Instruct方法的示例,这是一种使用大型语言模型(LLMs)代替人类来自动生成各种难度级别的开放域指令的新方法。
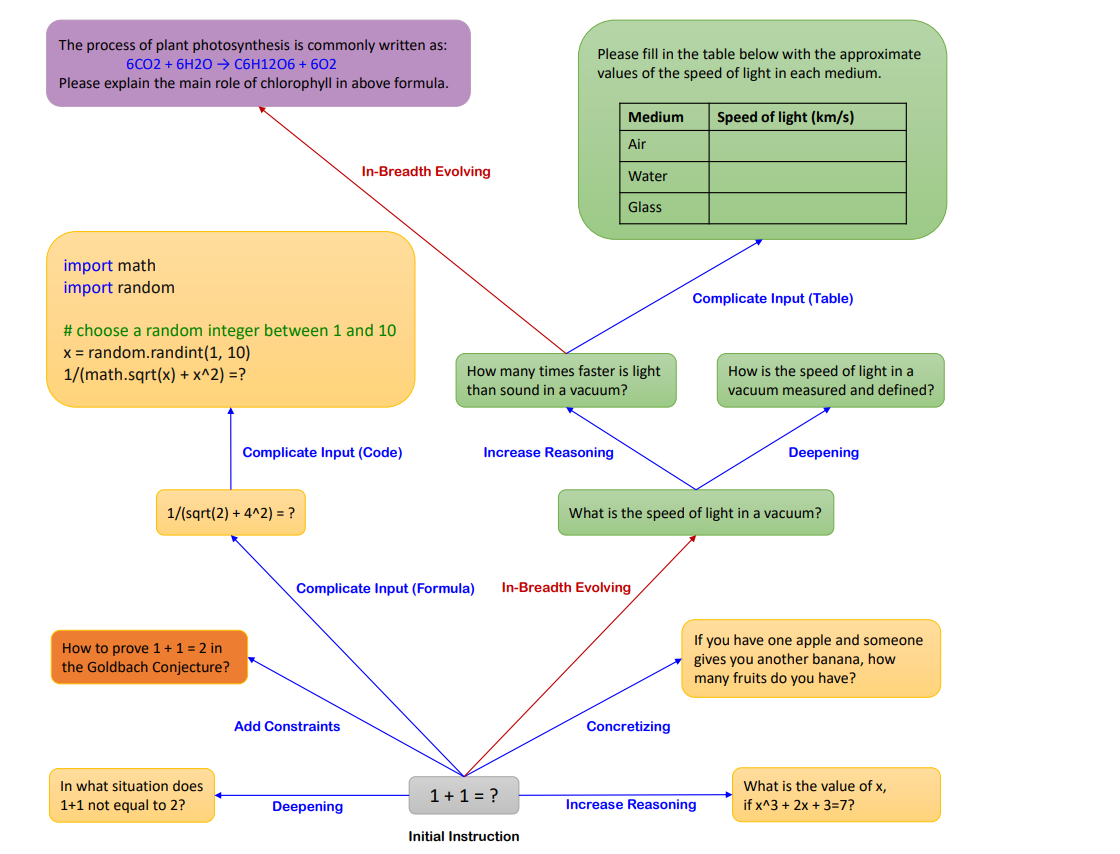
从一个简单的初始指令“1+1=?”开始,如何通过两种演化方式——“In-depth Evolving”(深度演化,蓝色方向线)和“In-breadth Evolving”(广度演化,红色方向线)——来提升指令的复杂性或创造新的指令以增加多样性。
图中给出了五种深度演化操作和一种广度演化操作,具体如下:
-
深度演化(In-depth Evolving) 包括五种类型的操作:
- 添加约束(Add Constraints):如将“1+1=?”演化为“在哪种情况下1+1不等于2?”
- 深化(Deepening):如将“1+1=?”演化为“如何证明1+1=2在哥德巴赫猜想中是正确的?”
- 具体化(Concretizing):如将“如果你有一个苹果,有人给了你一个香蕉,你有多少水果?”
- 增加推理步骤(Increase Reasoning):如将“1+1=?”演化为“x的值是多少,如果3x+3=7?”
- 复杂化输入(Complicate Input):通过增加代码或公式来提高问题的复杂性,如给出一个包含数学函数和随机数的Python代码片段要求求解。
-
广度演化(In-breadth Evolving) 是突变,即基于给定指令生成一个完全新的指令:
- 例如,将“1+1=?”演化为“请填写下表,提供光速在不同介质中的近似值。”
- 另一个示例是将“请解释上述公式中叶绿素的主要作用。”演化为一个复杂化输入的表格任务。
此外,图中还显示了一个被称为“Elimination Evolving”(淘汰演化)的过程,用于过滤失败的指令。
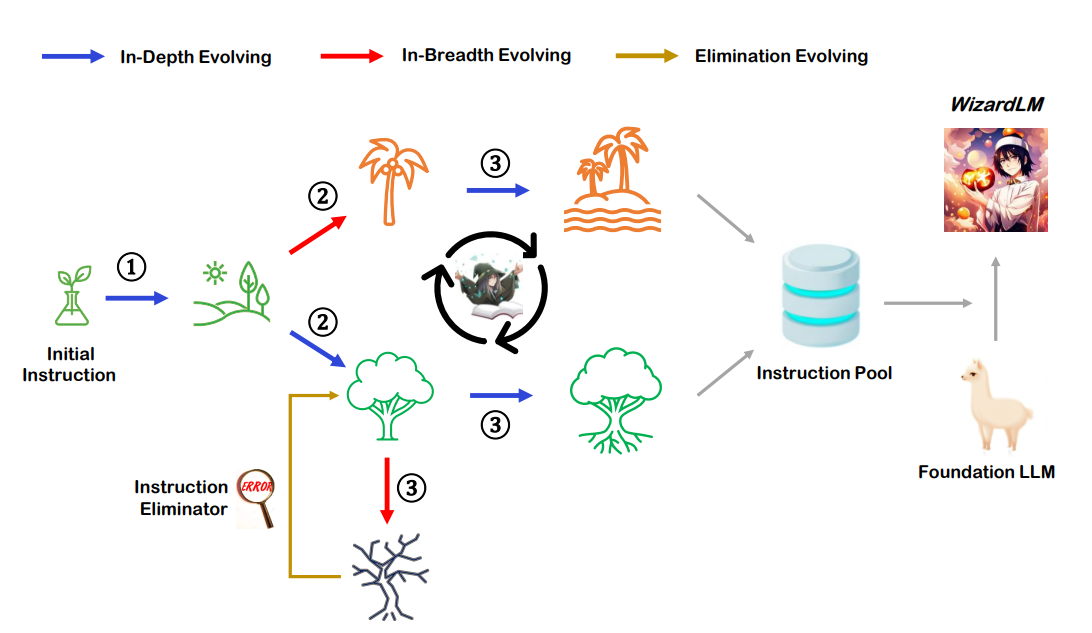
这张图提供了Evol-Instruct方法的概览,标题为“Figure 2: Overview of Evol-Instruct”。这是一个由三个主要部分组成的流程图:
-
初始指令(Initial Instruction):这是流程的起点,表示Evol-Instruct方法的开始,用一个灯泡图标表示,可能象征着一个简单的、创意的或基础的想法。
-
演化过程(Evolving Process):从初始指令出发,指令经历了三种演化过程:
- 深度演化(In-Depth Evolving):用蓝色箭头表示,指令变得更加复杂和深入。
- 广度演化(In-Breadth Evolving):用红色箭头表示,指令变得更加多样化。
- 淘汰演化(Elimination Evolving):用黄色箭头表示,不成功的指令将被淘汰。
演化过程中使用了不同的图标来表示这一过程,包括树木的图标表示生长和发展,以及一个回收符号可能表示从失败的指令中回收和重组元素。
-
指令消除器(Instruction Eliminator):这是一个用于过滤掉不成功或不合格指令的步骤,用一个带有红色错误标记的图标表示。
-
指令池(Instruction Pool):通过演化过程成功的指令被收集到指令池中,表示为一个数据库或存储图标。
-
基础LLM(Foundation LLM):指令池中的指令被用来训练或微调基础大型语言模型,这里用一只骆驼图标表示,可能代表LLM的负载能力或基础性质。
-
WizardLM:最终,经过微调的LLM被称为WizardLM,这里用一个魔术师图标表示,可能意味着模型通过Evol-Instruct变得更加强大或具有魔法般的能力。
Evol-Instruct的整个流程:从一个初始指令开始,通过多轮的演化和过滤,最终生成一个高质量的指令池,这个指令池被用于训练或微调一个更先进的LLM,即WizardLM。
总结
Evol-Instruct方法的拆解和解释如下:
主问题: 如何通过Evol-Instruct方法生成多样化和复杂度高的指令,以提升大型语言模型(LLMs)的性能。
问题与解法组成:
-
子问题1:生成复杂度更高的指令。
- 子解法1:Instruction Evolver。
- 特点: 利用LLM的能力,通过深度演化和广度演化的策略来生成更复杂的指令。
- 原因: 深度和广度演化可以从不同角度增加指令的复杂性,增强LLM处理多样化任务的能力。
- 子解法1:Instruction Evolver。
-
子问题2:从深度方面增加指令复杂性。
- 子解法2:深度演化操作,包括增加约束、深化、具体化、增加推理步骤和复杂化输入。
- 特点: 这些操作通过改写现有指令,增加其复杂度和细节。
- 原因: 这些改写方法可以使指令更加具体和挑战性,迫使LLM进行更深入的思考和处理。
- 子解法2:深度演化操作,包括增加约束、深化、具体化、增加推理步骤和复杂化输入。
例子:
- 增加约束:原指令:“翻译这段文字。” ------ 改写后的指令:“翻译这段文字,并确保翻译结果在文化上是敏感和适当的。”
- 深化:原指令:“总结这篇文章的主要观点。” ------ 改写后的指令:“总结这篇文章的主要观点,并解释它们对当前政治环境的影响。”
- 具体化:原指令:“描述一个健康的饮食。” ------ 改写后的指令:“描述一个适合糖尿病患者的健康饮食计划。”
增加推理步骤:原指令:“计算10加20的结果。” ------ 改写后的指令:“如果一个人有10个苹果,每天吃掉2个,计算他需要多少天吃完这些苹果。” - 复杂化输入:原指令:“根据提供的数据绘制图表。” ------ 改写后的指令:“根据提供的数据中的趋势和异常值绘制图表,并解释可能的原因。”
- 子问题3:从广度方面增加指令复杂性。
- 子解法3:广度演化操作,即创造全新指令。
- 特点: 生成与现有指令相似但更为罕见的新指令。
- 原因: 创造新的指令可以提高数据集的多样性,促进LLM学习更广泛的应用场景。
- 子解法3:广度演化操作,即创造全新指令。
原指令:“写一个关于太空旅行的短故事。”
改写后的新指令:“创建一个关于在火星上建立殖民地的未来主义场景。”
- 子问题4:筛选有效的演化指令。
- 子解法4:Instruction Eliminator,即指令消除器。
- 特点: 剔除演化过程中产生的无效或低效指令。
- 原因: 确保数据集中的指令都是高质量的,有助于提高LLM的训练效率和性能。
- 子解法4:Instruction Eliminator,即指令消除器。
假设通过演化产生了一条指令:“编写一个故事,然后删除它。”
因为这个指令缺乏具体的目的和效用,所以被指令消除器剔除。
每个子问题和子解法在整体解法中的目的:
- 子问题1和子解法1 的目的是通过创新的演化方法生成具有不同复杂度的指令,增强LLM的处理能力。
- 子问题2和子解法2 的目的是通过深化和具体化现有指令,使LLM能够处理更复杂和具体的任务。
- 子问题3和子解法3 的目的是增加数据集的广度和多样性,使LLM能够适应更广泛的应用场景。
- 子问题4和子解法4 的目的是确保通过演化方法生成的指令是高质量的,提高LLM训练的效率和成果。
Evol-Instruct 代码复现
Evol-Instruct 应用:扩充大模型数据多样性
这篇关于【大模型 数据增强】Evol-Instruct 应用:扩充大模型数据多样性的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






