本文主要是介绍AI大模型额外学习一:斯坦福AI西部世界小镇笔记(包括部署和源码分析),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 一、简单介绍
- 1)项目代码介绍
- 2)重新播放模拟
- 3)适当修改分叉模拟
- 二、部署斯坦福小镇Demo
- 1)准备工作
- 2)解决遇到的bug
- 3)启动服务器和前端
- 三、源码剖析
- 1)主题顺序
github链接
一、简单介绍
①背景介绍
This repository accompanies our research paper titled “Generative Agents: Interactive Simulacra of Human Behavior.” It contains our core simulation module for generative agents—computational agents that simulate believable human behaviors—and their game environment.
②总体逻辑
让小镇的NPC自由交流、开party、生活有条不紊
③总结:
Ai会感知周边环境,并将视野里发生的事件记录下来,加入自己的记忆流。之后,不论是Ai计划要做的事,还是对外界的反应,都会受到这个记忆的影响,并依靠ChatGPT进行决策,最后决策的事件也会加入记忆流,形成新的记忆。让NPC具备记忆系统,并依靠大语言模型来帮助NPC做出行动决策
https://github.com/joonspk-research/generative_agents/tree/main
https://www.zhihu.com/question/425708656
https://github.com/joonspk-research/generative_agents/tree/main
https://github.com/search?q=generative-agents&type=repositories
1)项目代码介绍
①项目有后端服务器backend_server和前端服务器frontend_server
②storage会保存程序运行的记录信息
2)重新播放模拟
打开浏览器,输入
http://localhost:8000/replay/<simulation-name>/<starting-time_step>
3)适当修改分叉模拟
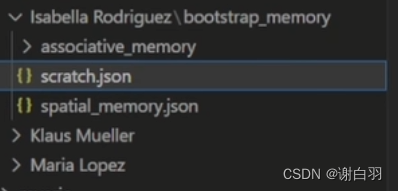
这里的模拟是Isabella,scratch.json里面包括人物性格描述、居住地点、生活方式等,
spatial_memory.json里面还有房间布局等等
二、部署斯坦福小镇Demo
1)准备工作
①安装aneconda
②下载仓库代码
git clone https://github.com/joonspk-research/generative_agents.gitcd generative_agents
③用vscode打开generative_agents目录
④在reverie目录的backend_server下载创建文件utils.py文件,填入以下内容

# Copy and paste your OpenAI API
Keyopenai_api_key ="<Your OpenAI API>"
# Put your name
key_owner = "<Name>"maze assets loc ="../../enviroment/frontend_server/static_dirs/assets"
envircenv_matrix=f"{maze_assets_loc}/the_ville/matrix"
env_visuals =f"{maze assets loc}/the_ville/visuals"fs_storage ="../../environment/frontend server/storage"
fs_temp_storage ="../../environment/frontend_server/temp_storage"collision block id ="32125'# Verbose
debug = True
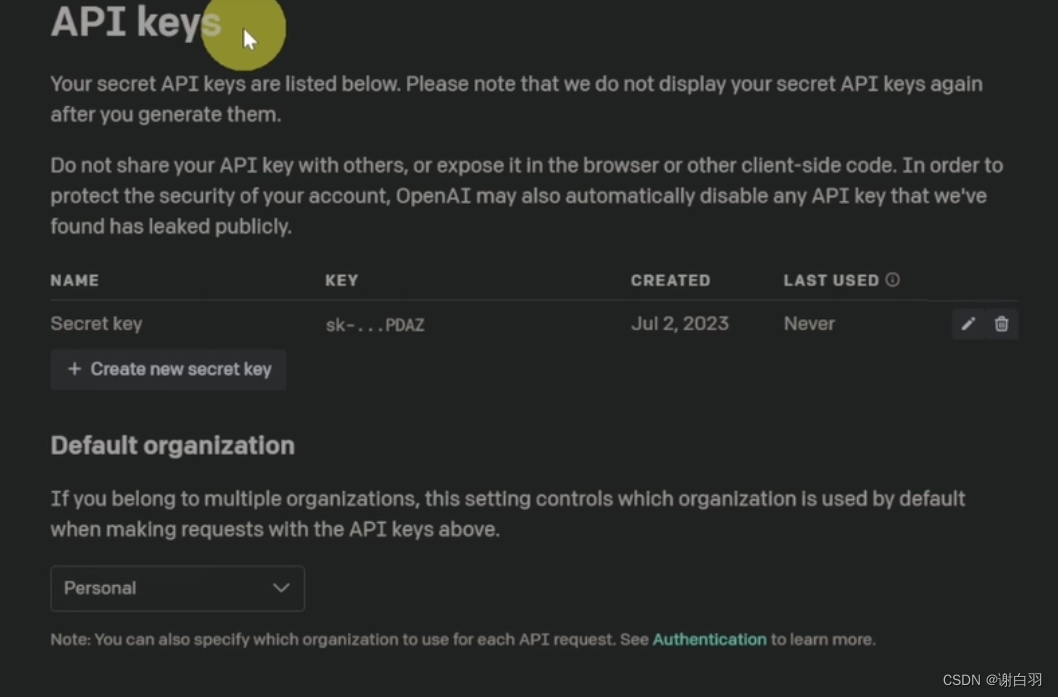
⑤填入OPEN AI API Keys和秘钥的名字
⑥创建新conda环境
conda create -n genagents python=3.11.4#激活新环境
conda activate genagents
2)解决遇到的bug
①pillow需要更新到最新的从8.4.0改到9.5.0
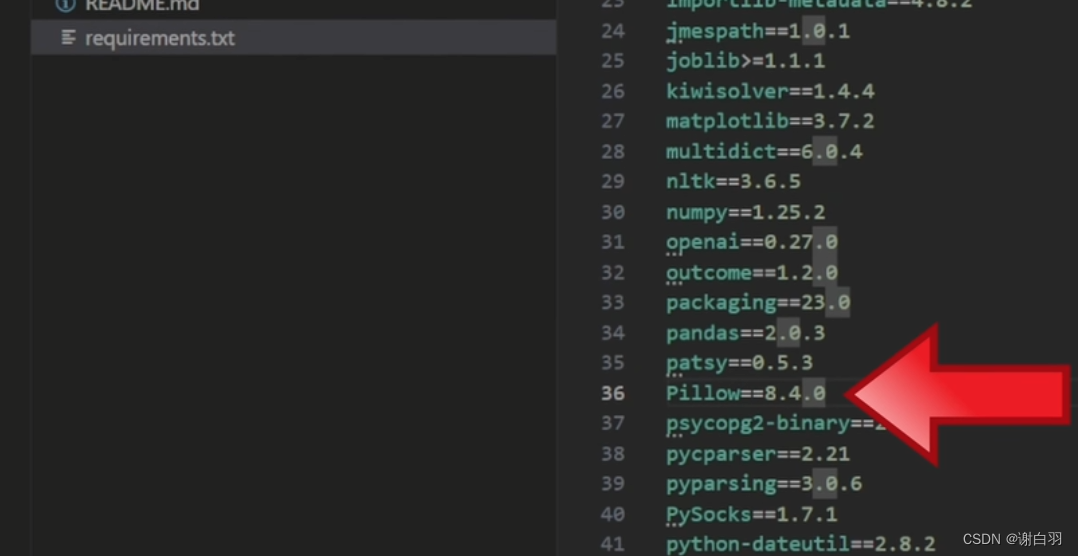
python -m pip install -r requirements.txt
②打开backend_server目录下的reverie.py文件,跳转400行
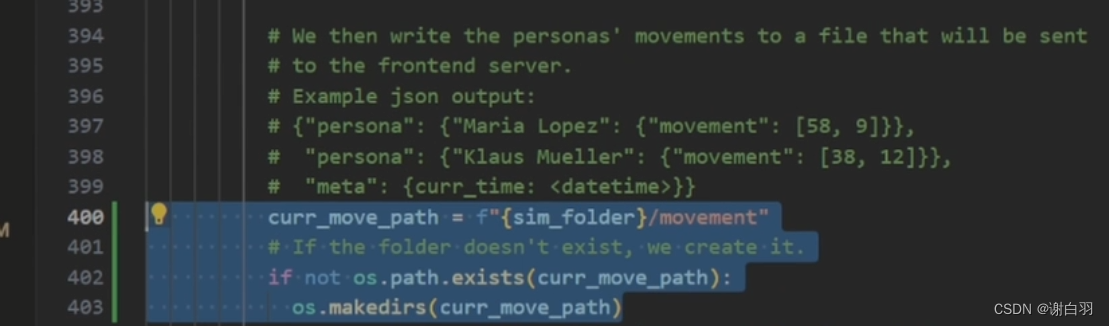
curr_move_path=f"{sim_folder}/movement"
#If the folder doesn't exist, we create it
if not os.path.exists(curr_move_path):os.makedirs(curr_move_path)
3)启动服务器和前端
①切换到前端目录,然后运行脚本
cd environment/frontend_server
python manage.py runserver
②打开浏览器,输入
1.7.0.0.1:8000

有以上图片则表示启动成功
可以看到前端url的地址是
127.0.0.1:8000
③启动新终端来开启服务器
cd generative_agents
conda activate genagents
cd reverie/backend_server#准备开启服务器
python reverie.py
④回答要进入的分叉模拟(forked simulation):
现在是用现有的模板做三个代理(agent)
base_the_ville_sabella_maria_klaus

接着命名这个分叉模拟,随意,就叫test

⑤先跑3步,注意这里的步数,如果跑太多,token消耗的次数越多,3步就几刀
就可看到输出:
三、源码剖析
1)主题顺序
-
简短说明
①根据填入的演变次数,来决定循环的次数
②便利所有的agent,每个agent执行自己的plan函数,也就是每个人作为一个agent
③根据第二步拿到的计划,然后执行计划
④执行计划之后,先看初始地点有那些人,然后利用prompt去跟这些人互动相互交流,跟同地点的人互动之后再用prompt修改当前的做事计划,然后让别人知道我在干嘛
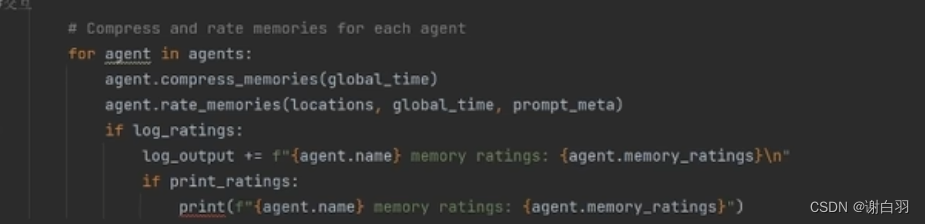
⑤然后根据之前的今日的计划安排把自己以往的记忆用prompt进行评分排序
(比如做瑜伽重要,就排前面)
⑥根据自己的计划和这个地方的场所列表,用promopt对要去的地方打分,就可以去那个排名第一的地方了 -
详细说明
①根据填入的演变次数,来决定循环的次数
for repeat in range(repeats):....
②便利所有的agent,每个agent执行自己的plan函数,也就是每个人作为一个agent
for agent in agents:agent.plan(global_time,prompt_meta)
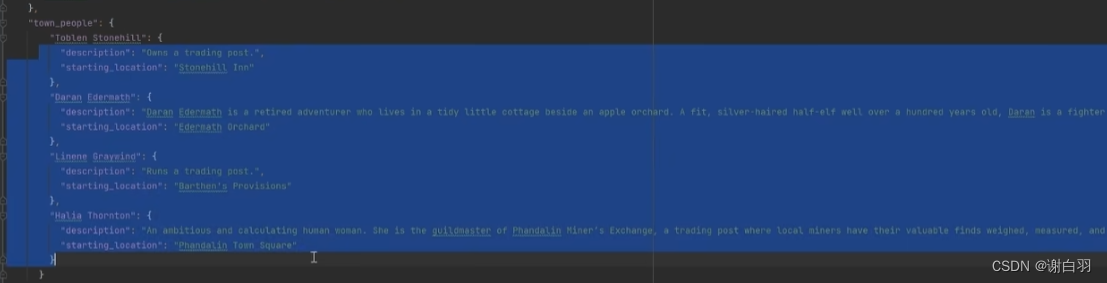
而每个agent都是由每个人的名字、描述、初始出生地点(从simulation_config.json里面读取,team_people都是镇上的人)构造出来
而这个plan函数就是给OpenAI接口一个prompt,如下:

根据今天时间写下今天的每小时计划安排
③根据第二步拿到的计划,然后执行计划
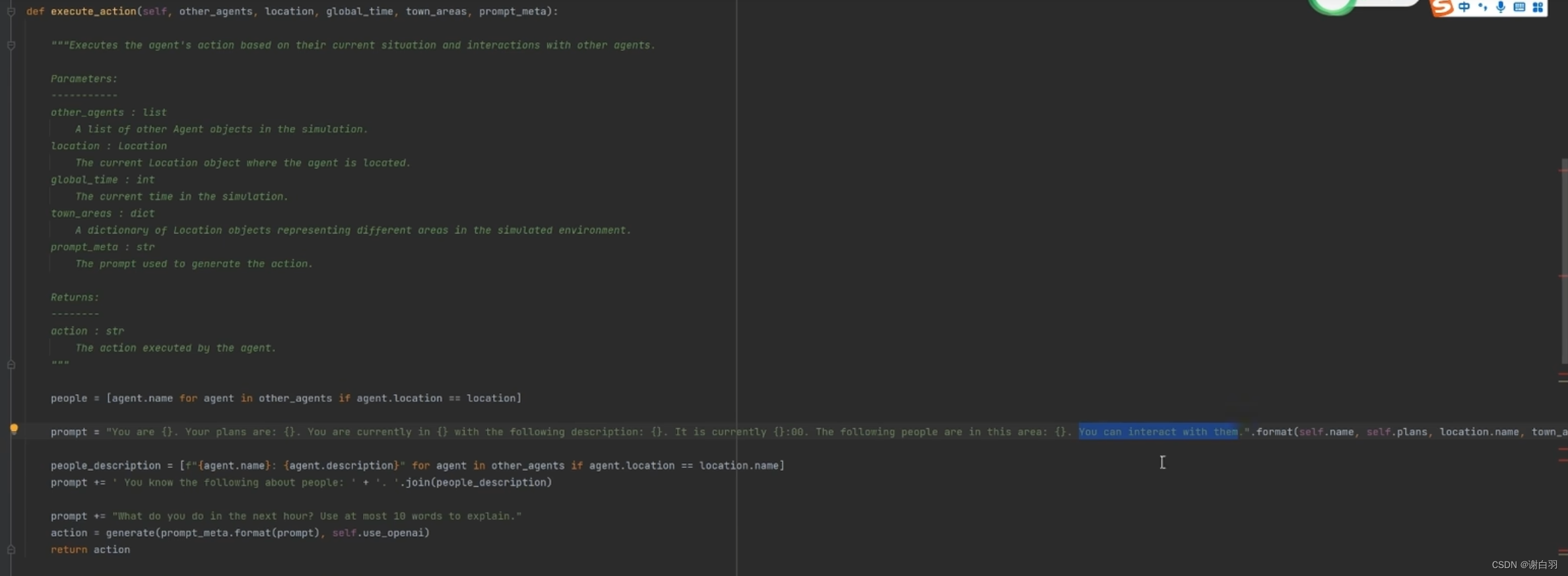
④执行计划之后,先看初始地点有那些人,然后利用prompt去跟这些人互动相互交流,跟同地点的人互动之后再用prompt修改当前的做事计划,然后让别人知道我在干嘛
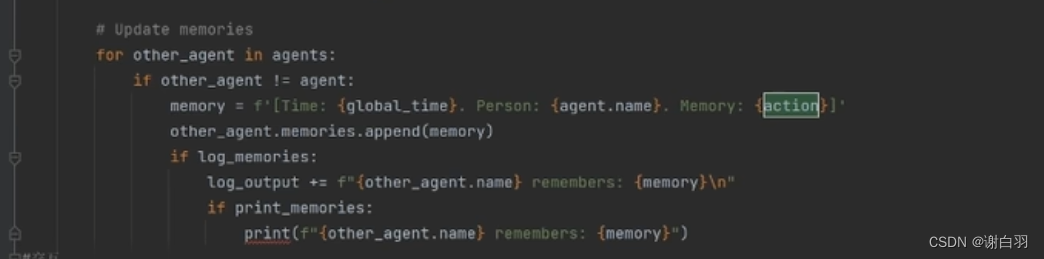
⑤然后根据之前的今日的计划安排把自己以往的记忆用prompt进行评分排序
(比如做瑜伽重要,就排前面)
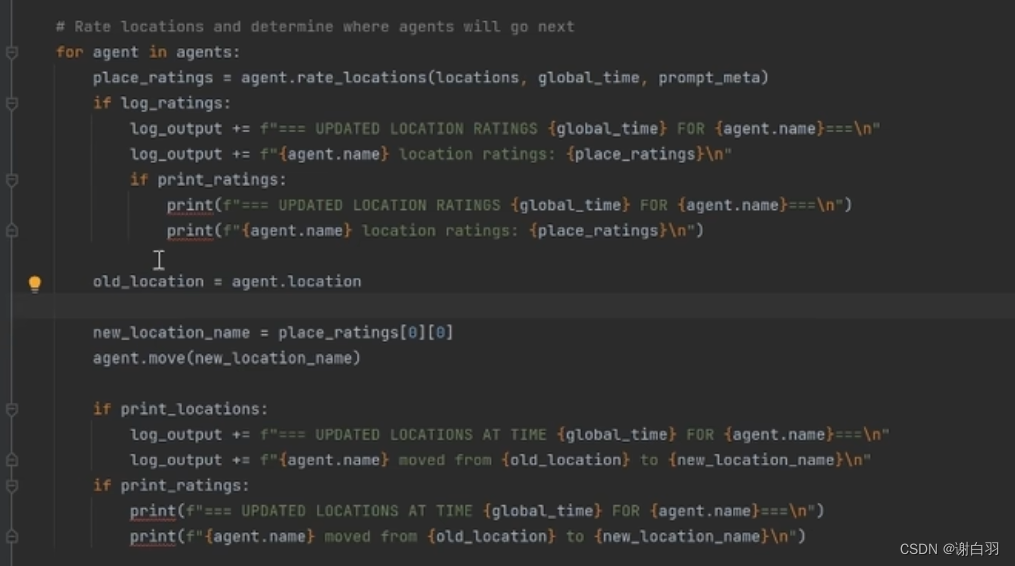
⑥根据自己的计划和这个地方的场所列表,用promopt对要去的地方打分,就可以去那个排名第一的地方了
这篇关于AI大模型额外学习一:斯坦福AI西部世界小镇笔记(包括部署和源码分析)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









