本文主要是介绍GlobalMapper20修补地形数据噪点教程,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
序:
很多拿到手的DEM数据,会有空洞或者噪点,部分引擎可以自动处理,部分引擎不可以,总之影响使用。这里使用GlobalMapper进行漏洞填充
一、打开数据:

二、右键图层-选择有数据的范围
Layer->BBox/COVERAGES-Create…

在弹出的对话框中选择【否】
Create polygonal coverage Areas

等待数据处理
处理后的结果如下:

三、反向选择获取空洞区域
先用数字化工具,选择上一步生产得要素

右键-》反向选择

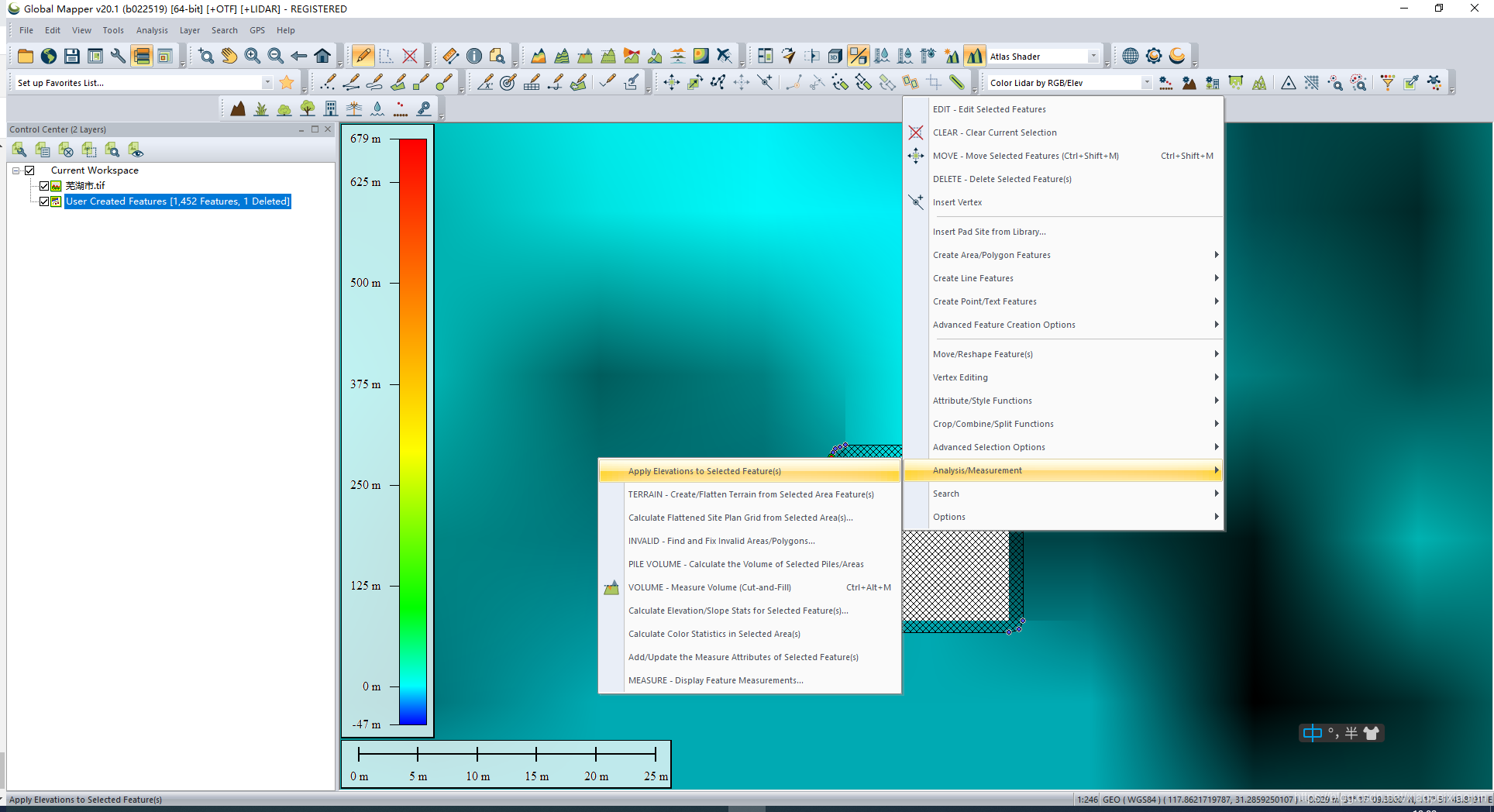
四、对选择的对象计算高程
Analys/Measurement->caulate elevation…


五、创建地形格网



六、调整图层顺序-删除矢量
调整图层顺序

删除矢量

七、导出数据
直接导出


八、注:20.1以上版本此处有所区别,会生成一个multipolygon,是一个要素

选中,
然后右键选择所有空洞

右键创建缓冲区


创建一米的缓冲区



删除选中的这个对象(或者直接选中删除)

选中所有的面对象,进行高程赋值
和之前一样,在分析下面创建地形个格网

调整顺序输出。
这篇关于GlobalMapper20修补地形数据噪点教程的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









