本文主要是介绍Modeling Influence Diffusion over Signed Social Networks,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

关键词——社会系统、影响力扩散、建模、签名社交网络、影响力最大化
Abstract
在离线或在线世界中,许多社交系统可以表示为签名社交网络,包括积极和消极关系。尽管由于独特极性特征的巨大应用价值,人们对签名社交网络进行了各种研究,但如何对签名社交网络上的影响力传播过程进行建模仍然是一个仍然悬而未决的重要问题。目前,一些研究将传统的扩散模型(例如独立级联模型和线性阈值模型)从未签名的社交网络扩展到签名的社交网络,以估计用户集的积极和消极影响。然而,上述所有可拓模型都是随机的描述性模型。为了确保估计影响的准确性,现有模型需要进行大量的蒙特卡罗模拟,这非常耗时且不可扩展。针对这个问题,我们提出了极性相关的线性影响扩散(PLID)模型,该模型可以快速准确地计算用户集的极性相关影响,而无需模拟。为了验证我们提出的模型的有效性和效率,我们利用 PLID 模型在严格的数学证明下解决签名社交网络中的积极影响最大化问题。大量实验表明,使用 Epinions 和 Slashdot 数据集,我们的 PLID 模型和近似算法在积极影响传播和运行时间方面显着优于最先进的方法。
1 NITRODUCTION
社会系统是一个涉及多个个体的相互行为和社会关系的复杂系统”[1]。近年来,各种网络网站不断涌现,为世界各地的用户提供了交友、信息传播、众包的新平台,可视为网络社交系统。在一些在线社交系统(例如,Epinions、Slashdot)中,允许用户在与其他用户的关系上标记积极的信号或消极的信号。在其他一些系统(例如Twitter、微博)中,极性符号无法直接获得,但是可以从用户之间的交互数据中检测到。上述包含正向和负向关系的系统通常被建模为签名社交网络,它比忽略关系极性的未签名社交网络更准确地描述真实的社会系统。
用户之间关系的极性特性有助于理解网络演化、分析用户偏好、预测用户行为。除此之外,在线社交数据前所未有的可用性为签名社交网络研究提供了机会。因此,迄今为止,一系列经典的研究问题(例如社区检测[2]、[3]、链接预测[4]、用户排名[5]和推荐系统[6]、[7])已经在签署社交网络。然而,对签名社交网络上的影响力传播过程进行建模仍然是一个仍然悬而未决的重要问题。扩散模型可以用来估计用户集的影响力,这对于解决一些实际应用问题(例如病毒式营销、谣言控制)起着至关重要的作用。签名社交网络中存在的关系的正负极性导致用户集合的非极性影响力会分为正向影响力和负向影响力。如何区分这两种类型的影响并准确、快速地估计它们是对签名社交网络上的影响扩散进行建模的关键挑战。
目前,一些研究[8]、[9]、[10]试图通过将一些经典模型(例如独立级联模型、投票者模型和线性阈值模型)从未签名社交网络扩展到签名社交网络来解决上述挑战。然而,上述所有扩展模型都是随机的描述性模型。为了估计用户集的积极和消极影响,这些模型必须运行一定数量的蒙特卡罗模拟。当模拟次数较少时,估计的影响并不准确。当模拟数量(10,000-20,000)足够大以获得准确的影响力时,模拟过程会消耗大量时间,这导致这些模型不适用于大规模社交网络。因此,现有的签名社交网络扩散模型无法考虑极性相关影响力估计的准确性和效率。
为此,我们提供了一种基于线性迭代思维的新影响力扩散模型,以实现有效且高效的影响力扩散模型。
极性相关的影响估计。与[8]、[9]、[10]中的随机和描述性模型不同,我们提出的模型是一种计算模型,直接计算用户集的极性相关影响,无需大量模拟。由于无法获得用户集影响力的基本事实,因此很难直接评估不同的扩散模型。因此,本文采用间接评价方式。具体来说,我们将模型与贪婪解决方案相结合,以在严格的数学证明下解决积极影响最大化(PIM)问题。 “PIM问题是签名社交网络中传统影响力最大化问题的延伸”[10],拥有完整、标准的评价标准。如果我们提出的模型在解决 PIM 问题方面比其他模型表现更好,这意味着我们模型的效率和有效性得到了验证。
综上所述,本文做出以下贡献:
我们在签名社交网络中提出了一种新颖的极性相关线性影响扩散(PLID)模型,它是一种计算模型,能够准确快速地估计节点集的正面和负面影响。 PLID模型融合了“我朋友的朋友是我的朋友,我敌人的朋友是我的敌人,我朋友的敌人是我的敌人,我敌人的敌人是我的朋友”的社会原则[10 ]。
我们利用 PLID 模型来解决 PIM 问题。具体来说,我们在数学上证明了 PIM 问题的目标函数在 PLID 模型下保持单调性和子模性,这使得贪婪种子节点选择策略能够为 PIM 问题提供 1 1=e 近似。
我们对 Epinions 和 Slashdot 数据集进行了一系列全面的实验来评估我们的方法。实验结果表明,我们的方法在解决 PIM 问题时实现了更好的积极影响传播性能,并且运行速度比最先进的方法 [10] 快 7-35 倍。
我们对本文的其余部分进行了如下组织:第二部分总结了相关研究;第3节介绍PLID模型;第 4 节展示了如何利用我们提出的 PLID 模型来解决 PIM 问题;第 5 节介绍了我们验证实验的细节;第六节总结了本研究并展望了未来的研究方向。
2 RELATED WORK
在本节中,我们从以下三个方面介绍与我们的研究密切相关的现有工作:
影响力最大化问题。多明戈斯等人。 [11] 2001 年首次引入影响力最大化问题。Kempe 等人。 [12]首先将影响最大化定义为离散优化问题。他们还提出了一种贪婪的解决方案,并说明它比其他一些简单的方法表现得更好。有很多研究致力于解决[12]中方法的效率问题。莱斯科维奇等人。 [13]开发了成本-充分利用影响函数的子模性质的有效惰性前向(CELF)选择策略,其运行速度比原始贪婪解快约七百倍。金等人。 [14]开发了一种独立的路径算法来近似IC模型估计的影响。同样,陈等人。提出了 PMIA [15] 和 DegreeDiscountIC [16] 启发式方法来估计使用网络结构的种子节点集的影响。程等人。 [17]提出了一种 StaticGreedy 算法来避免大量使用快照的蒙特卡洛模拟。他们等人。 [18]还发现了一种迭代排序方法,它具有贪心法和启发式方法的优点。刘等人。 [19]开发了Group-PageRank方法来快速计算IM问题中影响力的上限。唐等人。 [20]提出了一种鞅方法来解决近线性时间内的影响最大化问题。
人们从各个方面对影响力最大化问题进行了广泛的研究。影响力扩散是一个时间动态过程,一些研究[21]、[22]主要关注如何在时间约束下从社交网络中识别有影响力的节点。文献[23]、[24]、[25]、[26]、[27]积极研究了多种信息的竞争影响力最大化。此外,卢等人。 [28]将竞争延伸至互补,研究比较影响力扩散和最大化。陈等人。 [29],阿斯雷等人。 [30] 和陈等人。 [31]探讨了主题感知影响最大化问题。李等人。 [32] 和李等人。 [33]试图最大化社交网络特定用户的影响力传播。郭等人。 [34]研究了轨迹数据库中与位置相关的影响最大化。尽管影响力最大化引起了极大的关注,但上述所有研究都是基于未签名的社交网络,并忽略了用户之间关系的正负两极。
签名社交网络的研究。维克多等人。 [6] 和唐等人。 [7]利用正向和负向关系来增强推荐系统的性能。陈等人。 [35]提出了一种集成信任和不信任关系的用户模型,有助于解决推荐系统中的冷启动问题。杨等人。 [2] 和刘等人。 [3] 研究了如何从签名的社交网络中检测社区。唐等人。 [4]研究了一个有趣的问题,即仅基于积极关系和交互内容的消极关系预测。宋等人。 [36]提出了一种广义AUC(GAUC)来量化基于部分观察的签名社交网络的各种潜在链接的排名性能。莱斯科维奇等人。 [37]研究了基于在线社交网络的经典结构平衡理论。吴等人。 [5] 提出了 Troll-Trust 模型来对签名社交网络中的用户进行排名。社交网络中的扩散模型。选民模型、独立级联模型和线性阈值模型是信息扩散研究中广泛应用的三种模型[12]、[13]、[38]。三个经典模型也有多种扩展,例如Repulsive Voter模型[39]、Latency Aware Independent Cascade模型[21]、Linear Threshold model with Meeting events[22]、MultiCampaign Independent Cascade模型[23],用于探索互动动态或解决新的不同方面的影响最大化问题。基于真实扩散数据提出了一些其他扩散模型来预测信息扩散过程。李等人。 [40]、[41]提出了一种利用用户收益来预测信息扩散过程的时间动态的 GT 模型。欢等人。 [42]尝试对多关系网络中的信息传播进行建模。杨等人。 [43]将社会角色整合到扩散模型中以预测扩散规模。拉加万等人。 [44]提出了一种耦合隐马尔可夫模型来模拟用户的时间活动。包等人。 [45]将结构多样性度量纳入独立级联模型中,并从真实数据中学习新模型的参数进行预测。
有一些研究探讨了签名社交网络上的信息建模或影响力扩散问题。李等人。 [9]提出了一种适用于签名社交网络的改进选民模型。然而,扩展投票者模型中的节点只有两种状态选择:积极状态和消极状态,忽略非活动状态的存在。李等人。 [10]开发了极性相关独立级联(IC-P)模型,解决了上述缺陷。遵循文学的思想[10],王等人。 [8]将另一个经典的线性阈值模型扩展到签名社交网络。然而,上述两个扩展模型都是随机模型。为了估计候选用户集的正面和负面影响,需要进行大量的蒙特卡洛模拟。这会消耗太多时间并且不可扩展。针对这一问题,本文提出了一种新的极性相关线性影响扩散模型,该模型可以用更少的时间准确计算节点集的极性相关影响。
3 POLARITY-RELATED LINEAR INFLUENCE DIFFUSION MODEL
本节首先介绍如何将签名社交网络建模为图[10]的过程,然后在图上提出与极性相关的线性影响扩散模型。
3.1 Modeling Signed Social Networks
在本文中,我们将签名社交网络建模为有向、加权和签名图 G 1⁄4ðV; E; T; PÞ。 V是社交网络中对应于用户的节点集合(本文中“用户”和“节点”是可选的)。 E是对应于用户之间的关系的边的集合。 T是一个非负邻接矩阵,其元素Tu;v表示边ðu的扩散概率;图中vÞ。当且仅当边缘 ðu; vÞ2E,Tu;v 的值将为正值,否则为零。 P 是另一个矩阵,其中每个元素 Pu;v 代表边 ðu; 的符号。图中vÞ。 Pu;v的值有三个选项f1; 1; 0g分别对应正关系、负关系、无关系。我们将 Eþ 表示为所有符号为 +1 的正边的集合,将 E 表示为所有符号为 -1 的负边的集合,E 1⁄4 Eþ [ E 。我们还将 Tþ 表示为正边的邻接矩阵设Eþ对应,T为邻接矩阵下降沿集合E对应。有向、加权和符号图中的节点之间的关系不是对称的,即 Tu;v 61⁄4 Tv;u 和 Pu;v 61⁄4 Pv;u。
图1显示了签名社交网络建模的解释示例。图1a和1b分别呈现了签名的社交网络和相应的建模图。 Jordan 喜欢图 1a 中的 Bryant,因此 Pu;v 1⁄4þ1(图 1b 中靠近边缘 ðu; vÞ 的正方形中的左侧值)。边缘的重量 ðu; vÞ 表示从 u 到 v 的影响扩散概率,其值 Tu;v 1⁄4 0:2(靠近边缘 ðu; vÞ 的正方形中的右侧值)。同样,乔丹不喜欢詹姆斯、Pw;v 1⁄4 1 和 Tw;v 1⁄4 0:1;科比和詹姆斯之间不存在任何关系,因此 Pu;w 1⁄4 Tu;w 1⁄4 0。

图 1. 签名社交网络建模示例 [10]。
在图1中,边缘方向与关系方向相反。原因是我们建模的图是影响力传播图,用户之间的影响力扩散方向与他们之间的社会关系方向相反。例如,图1a呈现了从乔丹到科比的关系,在图1b中影响力将从科比传播到乔丹。由于乔丹受到科比的影响,因此,对应的边应该是ðu; vÞ 但不是 ðv;图中uÞ。
3.2 Diffusion Model Description
如前所述,签名社交网络 [8]、[9]、[10] 中现有的影响力扩散模型是描述性的随机模型。当采用这些随机模型来估计用户集的极性相关影响时,我们必须模拟扩散过程约10,00020,000次,这会消耗大量时间。针对现有模型的缺陷,我们提出了极性相关线性影响扩散模型。与现有的随机模型[8]、[9]、[10]不同,PLID模型可以直接基于线性迭代思维计算用户集的正面和负面影响,并且不需要蒙特卡洛模拟。因此,我们的新模型比现有模型更有效。接下来,我们介绍 PLID 模型的详细信息。
在PLID模型中,每个节点/用户不会被明确激活为正状态或负状态,而是有两种概率:受到正向影响的概率和受到负向影响的概率。 f+S!j表示节点集S对节点j 2 V 产生正向影响的概率值,也可以认为是节点集S对节点j的正向影响。类似地,f S!j 表示节点集合S对节点j 2 V 产生负面影响的概率值,也可以为视为节点集合S对节点j的负面影响。我们还将正向影响向量表示为 ff + S 1⁄41⁄2f+ S !1 ;f+ S!2; ... ;fþ S!jV j ,负面影响向量为 ff S 1⁄41⁄2f S!1;f S!2; ... ;f S!jV j 。
对于签名社交网络中的节点来说,它通常会同时受到种子节点集的正向和负向影响,并且正向影响和负向影响是相互转化的。因此,我们的模型将同时计算积极影响和消极影响。给定一个有符号图 G 和一个非空节点种子集 S V ,通过 PLID 模型计算种子节点集 S 对种子节点集 S 的正向和负向影响主要遵循两个假设: (1) 对于节点 j 2 S,种子集 S 受到影响节点 j 的概率为 100%。 (2) 对于节点 j= 2 S,节点 j 受到正面或负面影响的概率取决于其邻居从节点集 S 中得到的正面和负面影响,以及它们之间关系的极性。基于以上两个假设,我们介绍如何计算f+S!j和fS!j,具体公式如下:

等式。 (1)和(2)表示节点集合S对节点j 2 S 的正影响和负影响分别为1和0。等式。 (3) 表示初始集合S对节点j=2S的正向影响,它是集合S对j的邻居的正向影响和负向影响的线性组合。计算过程考虑节点 j 与其邻居之间关系的极性和权重。负面影响f S!j 的计算过程如下式所示: (4) 类似。 djþ 是正阻尼因子。 djþ 越大,节点集 S 中对节点 j 的正面影响越大。dj 是负阻尼因子。 dj越大,对节点集合S中的节点j的负面影响越大。
从方程式。 (1)和(2),我们可以看到种子集肯定对任何种子节点产生 100% 的正向影响。这个假设是根据我们提出的 PLID 模型的特定应用场景(即病毒式营销、谣言控制等)而设计的。这里我们以病毒式营销为例进行说明。如果我们提出的 PLID 模型用于推广公司的一种产品,那么如何设计种子集 S 对每个种子节点 j 2 S 的影响有两种选择。第一个是每个种子节点受到种子集的概率为 100%。另一种是每个种子节点可能以两种概率受到种子集的正向或负向影响。在后一种选择中,如果一个种子节点受到负面影响根据种子节点集合,这意味着该选定的种子节点根本不支持该产品,并且可能会发布对该产品的负面意见。显然,后一种选择是不合理且不适用的。因此,本文选择第一种方案。如果我们不考虑所提出模型的应用场景,而仅专注于纯粹使用该模型计算与极性相关的影响。 PLID 模型还可以处理其他假设,其中种子集 S 对种子节点 j 的正向和负向影响不等于 1 或 0。我们的 PLID 模型的广义形式已在第 4.2 节中介绍。
我们的PLID模型融合了“我朋友的朋友是我的朋友,我敌人的朋友是我的敌人,我朋友的敌人是我的敌人,我敌人的敌人是我的朋友”的社会原则[10 ]。节点集合S对节点j=2S的正向影响主要包含两部分:与节点j关系极性为正的j邻居的正向影响(式(3)前部分)和负向影响j 的邻居与节点 j 的关系极性为负(式(3)的后半部分)。类似地,节点集S对节点j=2S的负面影响也可以分为两部分:与节点j的关系极性为正的j的邻居的负面影响(式(4)的前一部分), j 与节点 j 的关系极性为负的邻居的正向影响(式(4)后半部分)。
从方程式。 (3)和(4),我们可以发现我们提出的PLID模型的运行时间与签名社交网络中正负关系的比例无关。对于种子节点集 S 和节点 j= 2 S,PLID 模型利用所有正关系 ði; jÞ2Eþ 和所有负面关系 ði;节点j的jÞ2E,计算节点集合S对节点j的正向和负向影响。如果仅连接到节点j的正负关系的比例发生变化,而连接到节点j的关系数量不变,则数量在 PLID 模型下,计算中包含的元素数量不会改变。当然,PLID模型的运行时间不受签名社交网络中正负关系比例变化的影响.

在这里,我们用图2来解释PLID模型下与极性相关的影响传播过程。图 2 是签名社交网络的本地部分,其中节点 1 有四个邻居(节点 2-5)。我们假设初始种子节点集合为S,图2中的5个节点均不属于S。在节点附近的方格中,橙色方格中的值为该节点从节点集合中受到的正向影响,绿色方块中的值为节点集S中节点的负面影响。在靠近边缘的方块中,左值和右值分别对应两个节点之间链路的极性和影响扩散概率。这里,我们假设节点1的正阻尼因子和负阻尼因子分别为0.1和0.3。即 d+1 1⁄4 0:1 和 d1 1⁄4 0:3。基于方程式。 (3)和(4)中,S对节点1的正向影响和负向影响如下:

事实上,上面的例子只展示了一个迭代过程中与极性相关的影响力计算。最终的影响通常需要多次迭代计算。具体而言,第 ðt × 1×轮迭代时节点 j= 2 S 的正向影响力的迭代计算过程如下:

其中,fþ;ðtþ1Þ S!j 表示 j 在 ðt × 1 轮时从节点集 S 受到的正向影响,fþ;ðtÞ S!i 和 f;ðtÞ S!i 分别表示节点集 S 对 i 的正向影响和负向影响在第 tÞ 轮迭代中。同理,第 ðt × 1 轮节点 j= 2 S 的负面影响力迭代计算过程如下:

对于节点j 2 S 来说,S 对j 的正向影响和负向影响不变,不需要迭代计算。 fþ S!j 1⁄4 1 和 f S!j 1⁄4 0。
以上内容展示了如何计算一组节点对一个节点的极性相关影响。实际上,种子节点集S不仅可以影响单个节点,还可以影响节点集A V 。我们将 f+S!A 和 fS!A 表示为节点集 S 对 A 的正向影响和负向影响。 (9) 式中,f+S!A为A中各节点从S受到的正向影响力的总和。S对A的负向影响力的计算与式(9)类似。 (10)。
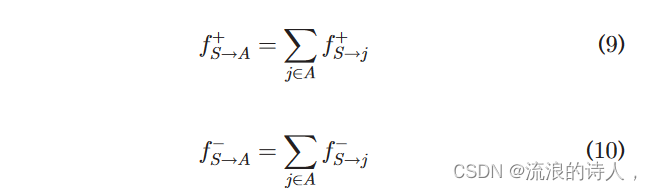
4 POSITIVE INFLUENCE MAXIMIZATION BASED ON PLID MODEL
在本节中,我们利用我们提出的 PLID 模型来解决积极影响最大化问题。具体来说,我们首先介绍PIM问题的定义,然后在严格的数学证明下开发PIM的贪心解决方案。
4.1 Definition of the PIM Problem
Li等人提出了积极影响最大化问题。 [10],这是签名社交网络的原始影响力最大化问题[12]的扩展。传统的影响力最大化研究仅考虑如何选择具有最大非极性影响力的节点集,而忽略了用户影响力具有正负极性的关键问题。 PIM问题考虑了由用户之间关系的极性引起的用户影响的极性。 PIM问题的研究能够在实际应用中取得更好的性能。
我们首先假设 fþð Þ 和 f ð Þ 分别为正影响函数和负影响函数。给定节点集S,fþðSÞ为S的正向影响值,fðSÞ为S的负向影响值。节点S的无极性影响力等于fþðSÞ与fðSÞ之和。 fþðSÞ 和 fþðSÞ 可以通过我们的 PLID 模型进行估计。在 PLID 模型下,fþðSÞ1⁄4fþ S!V 和 fþðSÞ1⁄4f S!V 。
正如李等人。 [10]在他们的研究中指出,“给定一个有符号图G和一个扩散模型,对于非负参数k,PIM问题是选择一个具有最大正影响且其大小等于k的集合S”。 PIM 问题可以形式化为:

在 PIM 问题中,集合 S 中的每个种子节点都被设置为正状态或 100% 受到正向影响。这个假设是由PIM问题的具体应用场景决定的。解释这种设计的具体例子可以在文献[10]中找到。除此之外,该设计也对应于式(2)。 PLID模型的(1)和(2)。
Theorem 1. The PIM problem is NP-hard for the PLID model.
证明。如果一个问题的限制版本被证明是一个 NP 难问题,那么这个问题本身就是 NP 难问题 [46]。 PLID模型的正影响最大化问题可以被认为是非极性线性模型的传统影响最大化的特殊版本,其中给定社交网络中的所有关系都是正的。因此,如果能够证明传统影响力最大化问题在非极性线性模型下是NPhard问题,则定理1得以证明。非极性线性模型描述如下:

其中fS!j是节点集合S对节点j的影响力,E是社交图的关系集合。 Ti;j表示影响力从节点i到节点j的传播概率,dj是节点j对影响力转移的阻尼因子,其值在(0, 1)范围内。有关该模型的更多详细信息可以在[47]中找到。
接下来,我们尝试将集合覆盖问题作为影响力最大化问题的特例,证明非极性线性模型下影响力最大化的难度。集合覆盖问题是最具代表性的NP完全问题之一,其定义如下:有一个基集U 1⁄4 u1;u2; ...;un f、g 和 S1;S2; ... ;Sm 是集合 U 的子集,目标是确定是否有 k 个子集的并集等于 U
给定集合覆盖问题的任意实例,我们定义相应的具有 n × m 个节点的有向二分图。图中,每个节点i对应每个集合Si,每个节点j对应每个元素uj。如果fuj 2 Si,二分图中存在从节点i到节点j的链接。另外,各环节的影响转移概率ði;假设jÞ为1,即Ti;j 1⁄4 1。我们将V表示为图的节点集,并假设每个节点j 2 V的阻尼因子为1=DðjÞ,其中DðjÞ是入度节点 j 的。 fðSÞ表示为节点集S的影响力值,即fðSÞ1⁄4P ðjÞ2V fS!j。
初始选择Set Cover解结果中子集对应的k个节点作为种子节点集合S,S对每个节点j 2 S的影响值为1。在上面构建的二部图上运行非极性线性模型,对于一个节点 j= 2 S ,如果所有与节点 j 有链接的节点都属于节点集合 S,则 S 对节点 j 的影响值为 1。因此,如果任意 k 个节点的集合 S 具有影响力 fðSÞ k þ n,那么 Set Cover 问题一定是可以解决的。集合覆盖问题相当于判断该图中是否存在 k 个节点的集合 S,其中 fðSÞ k þ n。定理1得证。
4.2 Greedy Solution for PIM Problem
在这里,我们首先证明PLID模型下PIM问题的目标函数fþðÞ保持单调性和子模性,然后提出解决PIM问题的贪心解。为了证明目标函数是单调的和子模的,我们首先提出 PLID 模型的广义形式如下:
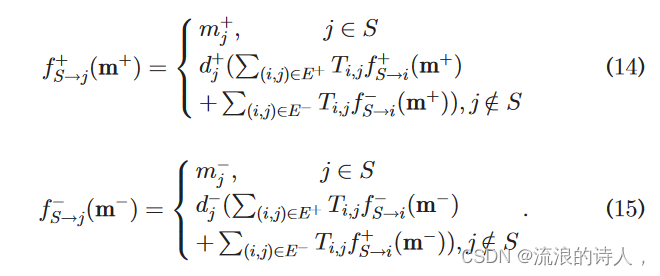
为了表述方便,fþ S!jðmmþÞ 也记为 fþ j ,f S!jðmm Þ 也记为 f j 。我们定义上述模型的解 ffþ S ðmmþÞ1⁄41⁄2fþ 1 ;fþ 2 ; ...;fþ jV j 和 ff S ðmm Þ1⁄41⁄2f 1 ;f 2 ; ...;f jV j 。 m+ m+ 是一个向量,其长度为
社交网络的节点集的大小。每个节点 j 在向量 m+ m+ 中拥有一个对应的值 mj+。向量 mþ mþ 是函数 ffþ S ð Þ 的变量,ffþ S ðmþ mþÞ 的函数值也是一个向量,其中每个元素代表种子节点集合 S 对每个节点的正向影响值。当 mþ mþ 等于每个元素等于 1 的向量 eþ eþ 时,ffþ S ðmmþÞ1⁄4ffþ S ðeeþÞ1⁄4ffþ S 和 fþ S!jðeeþÞÞ 1⁄4 fþ S!j。类似地,mm 也是一个向量,并且是函数 ff S ð Þ 的变量。那么我们就可以证明定理2 ffþ S ð Þ 是线性函数。
Theorem 2.
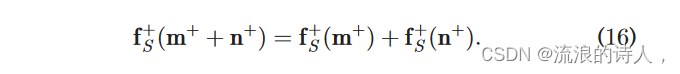
证明。 ffþ S ðmmþÞ 中的元素可以表示为
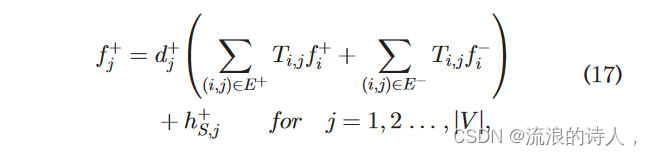
其中 hþ S;j 是确保 fþ j 1⁄4 mjþ 的值,如果节点 j 属于节点集 S(即 j 2 S),否则等于 0。类似地,ff S ðmm Þ 中的元素可以是表示为

其中 hS ;j 是一个值,如果节点 j 属于节点集 S(即 j 2 S),则确保 f j 1⁄4 mj,否则等于 0。 (17) 和 (18) 化为矩阵形式
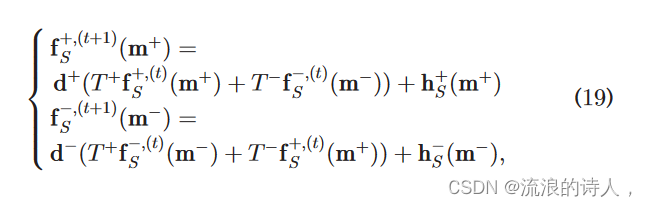
ff þ;ðtþ1Þ S ðmmþÞ 表示迭代计算过程中ðt × 1Þ轮的影响结果。当 t !1 时,ff þ;ðtþ1Þ S ðmmþÞ1⁄4ffþ;ðtÞ S ðmmþÞ。等式。 (19) 可以转化为有两个未知数的方程。通过求解方程我们可以得到如下结果:

为了证明 ffþ S ð Þ 是线性函数,我们需要证明 hhSð Þ 是线性函数。在这里,我们将证明与 PIM 问题结合起来。在PIM问题中,S中每个节点的负面影响为0,即hh ðmm Þ1⁄400。因为如果一个节点不属于节点集S,则向量hhSþðÞ中该节点对应的值为0。因此,如果能证明节点集S对应的向量函数是线性的
为了证明 ffþ S ð Þ 是线性函数,我们需要证明 hhSð Þ 是线性函数。在这里,我们将证明与 PIM 问题结合起来。在PIM问题中,S中每个节点的负面影响为0,即hh ðmm Þ1⁄400。因为如果一个节点不属于节点集S,则向量hhSþðÞ中该节点对应的值为0。因此,如果能证明节点集S对应的向量函数是线性的
从矩阵 P 中,我们删除其与 S 中的节点不对应的行和列,然后得到一个新的矩阵,命名为 PSS。从hhSðÞ中,我们删除其与S中的节点不对应的元素,然后得到一个新的向量,命名为hhSSðÞ。从mm+中,去掉与S中节点不对应的元素,得到一个新的向量,命名为mm+SS。因为S中各节点的正向影响不变,所以mm+SS 1⁄4 PSShhSSðmmSþSÞ,则hhSSðmmSþSÞ1⁄4P 1 SS mmSþS。 hhSSð Þ 是一个线性函数,因此我们可以得到 hhSð:Þ 是一个线性函数。方程中的矩阵 ðI NÞ 1 (20) 不变,因此 ffþ S ð Þ 是线性函数,即 ffþ S ðmmþ þ nnþÞ1⁄4ffþ S ðmmþÞþ ffþ S ðnnþÞ。利用定理1,我们可以证明正影响函数的单调性(引理1)和次模性(引理2)。
![]()
证明。对于种子节点集S,其影响模型为
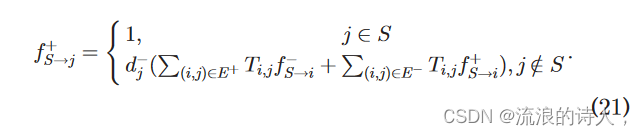
假设在此方法中 fþ S!v 1⁄4 pv,则该模型等效于

该模型是广义模型 ffþ S0 ðmÞ mÞ 其中 mm 1⁄4 1⁄21; 1; ... ;pv T 和 S0 1⁄4 S [fvg。而S0的影响模型为


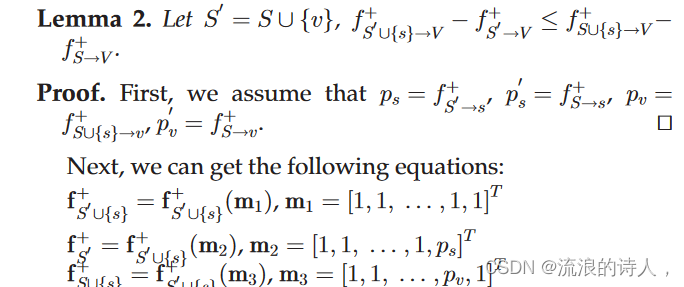
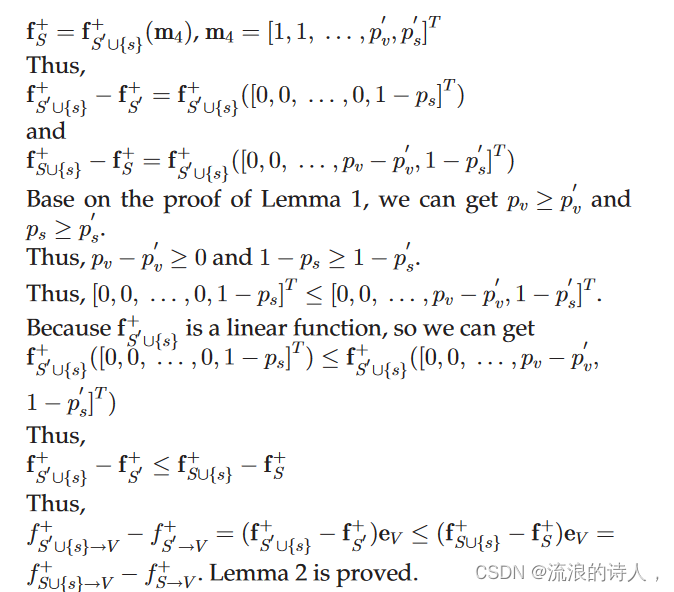
上述内容证明了我们的PLID模型下的正向影响函数保持了单调性和子模性。因此,贪心算法[48]可以用来求解近似比为1 1=e的PIM问题。算法1称为算法Greedy ðk; fþð ÞÞ 显示了贪婪算法的细节。算法 Greedyðk; fþð ÞÞ 在每一轮中选择一个带来最大边际正影响增量的节点。传统的贪心爬山算法非常耗时。针对这个问题,我们采用Cost-Effective Lazy Forward [13]选择策略,充分利用子模块性来减少运行时间。

5 EXPERIMENTS
5.1 Experimental Setup
数据集。斯坦福网络分析项目(SNAP)1由斯坦福大学Jure Leskovec教授建立,提供了大量的网络数据集。我们从 SNAP 下载 Epinions 网络和 Slashdot 网络作为我们的实验数据集。在这两个签名网络中,正极性或负极性都明确地标记在用户之间的每个关系上。 Epinions 数据集包含 11,567 个用户和 93,204 个关系,其中 83,663 个是积极的,9,541 个是消极的。 Slashdot 数据集包含 10,966 个用户和 44,536 个关系,其中 32,828 个是积极的,11,708 个是消极的。
扩散概率生成。因为交互信息用来计算影响力扩散每个链接的概率 Tu;v ðu;图 G 中的 vÞ 不可用,我们在实验中使用三种流行的模型 [15]、[16] 来生成图中边缘的扩散概率。
加权级联 (WC) 模型。 dðvÞ 表示节点 v 的入度。该模型主要利用节点的入度来创建扩散概率。对于边缘 ðu; vÞ,边Tu;v的扩散概率等于1=dðvÞ。
三价模型。该模型首先创建一个扩散概率集,然后从该集中随机选择一个概率并将其分配给一条边。在我们的实验中,扩散概率集包含三个值:0:1; 0:01 和 0.001。
统一(联合国)模型。该模型为图中的所有边分配相同的扩散概率。在我们的实验中概率值设置为0.01。
比较方法。我们将我们的解决方案命名为 PLID Greedy,并将其与 IC-P Greedy 和其他几种方法进行比较。在我们的实验中,我们评估和比较的所有方法如下:
PLID 贪婪。这是我们在本文中提出的方法。
IC-P 贪婪。该方法[10]采用贪心算法来解决基于极性相关独立级联模型的积极影响最大化问题。
IC 贪婪。首先,我们删除两个签名网络的关系极性,然后得到两个未签名的社交网络。接下来,在这些无符号网络中,我们利用贪心算法来寻找在原始独立级联(IC)模型下具有最大非极性影响力的种子节点集[12]。
Out-Degree。这是一种广泛使用的基线方法[15]、[16],根据出度选择前k个节点。
我们使用每种比较方法选择一组 50 个种子节点,并比较大小范围为 1 到 50 的不同节点集的积极影响。这里,我们需要一个统一的模型来估计每个节点集的积极影响。在我们的实验中,我们采用 IC-P 模型作为标准测量,因为它是签名社交网络中最广泛使用的独立级联模型的扩展。为了保证积极影响估计的准确性,基于IC-P模型的蒙特卡罗模拟次数设置为20000次。实验在具有 3.2 GHz Intel Core(TM)i7-8700 CPU 和 32G 内存的 PC 上运行。
5.2 Experiment Result
在本节中,我们将介绍不同方法在 Epinions 和 Slashdot 数据集上对传播性能和运行时间的积极影响的实验结果
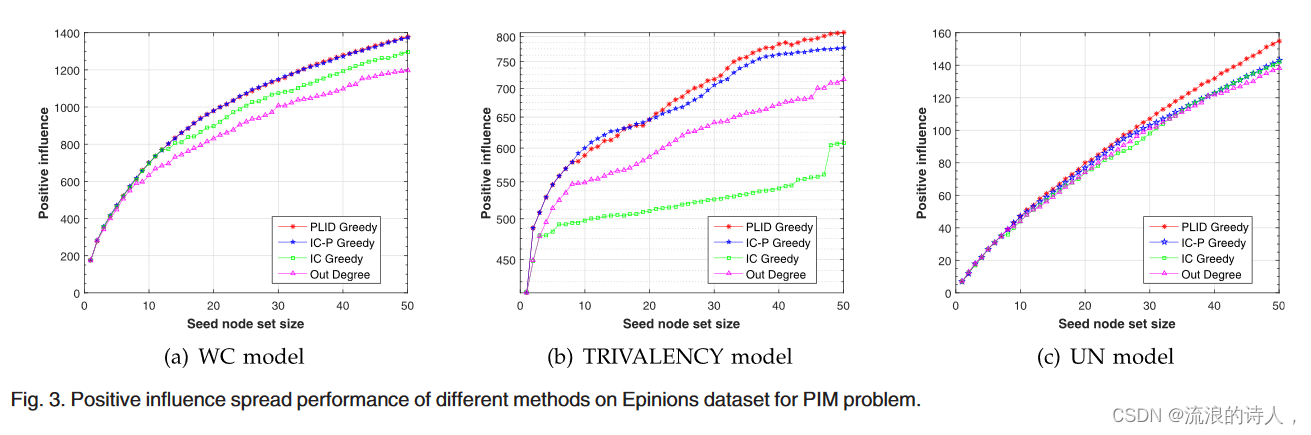
图 3. 不同方法对 PIM 问题的 Epinions 数据集的传播性能产生积极影响。
积极影响传播表现。图3显示了四种比较方法(PLID Greedy、IC-P Greedy、IC Greedy、Out-Degree)与三种不同传播概率(WC模型、TRIVALENCY模型、UN模型)在Epinions数据集上的性能。如图 3 所示,IC-P Greedy 的性能优于 IC Greedy 和 Out-Degree。 IC Greedy 的糟糕表现充分表明考虑用户之间关系极性的影响力最大化研究的必要性。我们还发现我们的 PLID Greedy 在开始时可以获得与 IC-P Greedy 相似的性能。然而,随着种子节点集大小的增加,我们的方法变得比 IC-P Greedy 表现得更好。当集合大小 k 为 50 时,与 IC-P Greedy 相比,我们的 PLID 方法在 WC 模型中优于 0.5%,在 TRIVALENCY 模型中优于 4.0%,在 UN 模型中优于 8.4%。
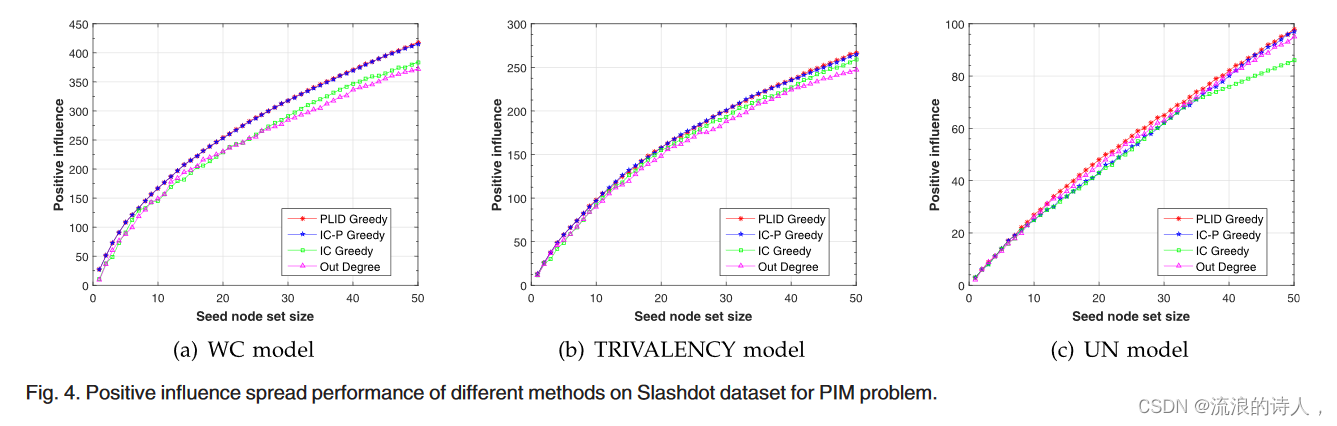
图 4. 不同方法对 PIM 问题的 Slashdot 数据集的传播性能产生积极影响。
图4显示了在Slashdot数据集上使用四种不同算法和三种传播概率的实验结果。同样,IC-P Greedy 的性能优于其他两种基线方法。当种子节点数量较少时,我们的 PLID Greedy 获得与 IC-P Greedy 相似的性能。随着种子节点集大小的增加,我们的方法比 IC-P Greedy 的性能更好。当集合大小 k 为 50 时,与 IC-P Greedy 相比,我们的 PLID 方法使用 WC 模型要好 0.6%,使用 TRIVALENCY 模型要好 1.1%,使用 UN 模型要好 1.0%。
负面影响传播表现。在包含积极和消极关系的签名社交网络中,积极影响伴随着消极影响。我们提出的PLID模型也清楚地反映了这一特征。在我们的实验中,我们不仅比较了四种不同方法的积极影响传播性能,还分析了不同方法选择的种子节点集所带来的负面影响。具体来说,我们采用采用不同的方法求解不同传播概率下的PIM问题,并得到相应的多个种子节点集。无花果。图5和图6展示了这些种子节点集的负面影响。接下来,我们尝试分析这些选定的节点集所带来的负面影响。

图 5. 不同方法对 PIM 问题的 Epinions 数据集的传播性能的负面影响。

图 6. 不同方法对 PIM 问题的 Slashdot 数据集的传播性能的负面影响。
无花果。图 5 和图 6 展示了四种比较方法(PLID Greedy、IC-P Greedy、IC Greedy、Out-Degree)与三种不同传播概率(WC 模型、TRIVALENCY 模型、UN 模型)对 Epinions 和Slashdot 数据集。从这两个图中,我们发现我们的 PLID Greedy 所受到的负面影响与 IC-P Greedy 所受到的负面影响相似或更少。 IC Greedy 和 Out-Degree 造成的负面影响比 PLID Greedy 和 IC-P Greedy 大得多。
在实际应用中,正面影响越大,负面影响越小越好。同时最大化积极影响和最小化消极影响应该是最终目标。我们提出的方法比基线方法获得了更大的积极影响和更小的消极影响,因此,在实际应用中将取得更好的经济或政治效益。
 图 7. 针对 PIM 问题的 Epinions 数据集上不同方法的运行时间。
图 7. 针对 PIM 问题的 Epinions 数据集上不同方法的运行时间。
运行时间。图 7 显示了四种比较方法在 Epinions 数据集上三种不同传播概率的运行时间。在每个子图中,x轴表示种子节点集大小,y轴表示选择不同大小的种子节点集所消耗的运行时间。从图7中我们发现,Out-Degree方法在四种方法中需要的运行时间最少,但就积极影响传播而言,其性能也是最差的。关于其他三个方法中,随着种子节点集大小的变化,我们的 PLID Greedy 总是比 IC-P Greedy 和 IC Greedy 方法消耗更少的时间。当种子节点集大小为50时,PLID Greedy在WC模型、TRIVALENCY模型和UN模型下的执行速度分别比IC-P Greedy快35.1倍、26.5倍和7.2倍。图7还表明,上述三种贪心方法的运行时间并不是随着种子节点集大小的增加而线性增长的。这是因为上述三种贪心方法都采用了成本有效的惰性前向[13]策略。 CELF策略下,贪心法在选择第一个种子节点的过程中只需要循环遍历图的每个节点,而在后续的选择过程中不再需要计算所有候选种子节点集的影响力
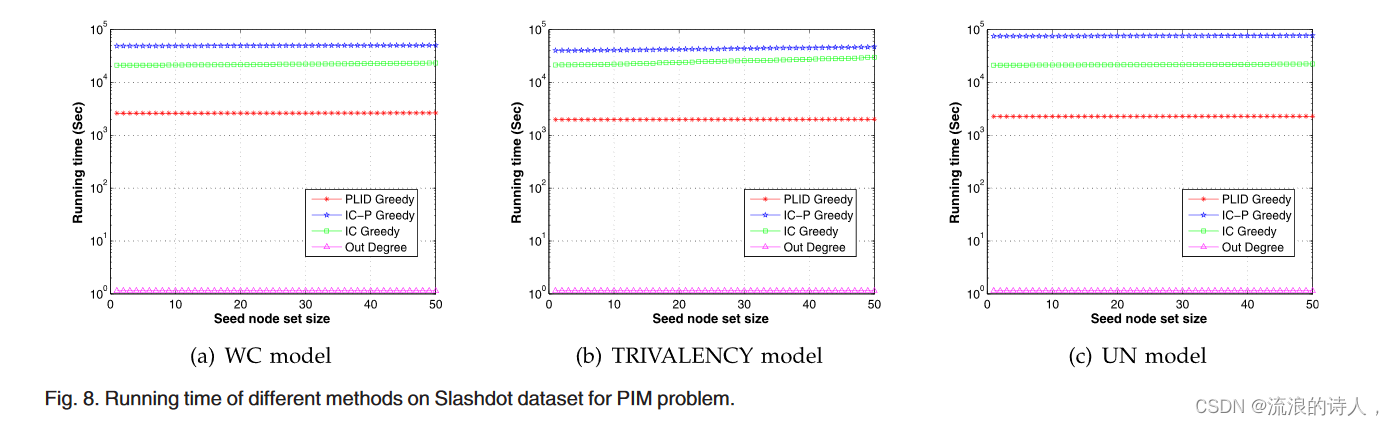
图 8. 针对 PIM 问题,不同方法在 Slashdot 数据集上的运行时间。
图 8 显示了四种比较方法在 Slashdot 数据集上三种不同传播概率的运行时间。与Epinions数据集类似,我们的PLID Greedy在运行时间方面比IC-P Greedy和IC Greedy方法表现得更好。当查看节点集大小为50时,PLID Greedy的执行速度分别比WC模型、TRIVALENCY模型和UN模型的IC-P Greedy快23.4倍、19.1倍和33.4倍。
从上面的比较结果中,我们发现我们的PLID Greedy方法在正面和负面影响扩散方面比IC-P Greedy方法能够在更少的运行时间内获得更好的性能。因此,我们可以得出结论,我们提出的 PLID 模型比 IC-P 模型更适合解决 PIM 问题。
参数设置。 PLID模型工作于线性迭代思维,本文将实际迭代次数设置为5次。在这里,我们通过一些实验来展示我们的 PLID 模型的收敛性,并解释为什么迭代次数设置为 5。在实验中,我们首先利用 IC-P 模型来解决 PIM 问题,然后获得 50 个种子节点在 Epinions 和 Slashdot 数据集上。接下来,我们从选定的种子节点中选择前k个作为测试集,并使用不同迭代次数的PLID模型计算测试集的积极影响。数字k从1到50。由于空间有限,社交网络的传播概率由Uniformly模型生成。

图 9.Epinions 和 Slashdot 数据集上 PLID 模型的收敛。
图 9 显示了我们的 PLID 模型在两个数据集上使用不同迭代次数计算出的积极影响。图9中,x轴表示节点集的大小,y轴表示节点集的积极影响。每条曲线代表了特定迭代次数下大小为 1 到 50 的节点集的积极影响。图 9 清楚地验证了积极影响收敛于随着迭代次数的增加而上界。迭代次数越大,计算出的正向影响越准确。但PLID模型同时也会消耗更多的运行时间。为了平衡有效性和效率,我们注意到当迭代次数为 5 时,积极影响开始收敛,并且迭代次数为 5 的 PLID 模型的运行时间也可以接受。因此,实验中迭代次数设置为5。
种子节点集分析。我们想要将PLID Greedy得到的种子节点集与IC-P Greedy得到的种子节点集进行比较,分析种子节点集差异与正向影响传播性能差异之间的关系。我们将 Sk PLID 表示为包含由 PLID Greedy 选择的 k 个节点的种子集,将 Sk IC P 表示为包含由 IC-P Greedy 选择的 k 个节点的种子集。为了便于描述,我们首先定义两个度量:节点集重合度和正向影响增量。当种子节点集大小为k时,节点集重合度等于jSk PLID \ Sk IC P j=k,正向影响增量等于fþðSk PLIDÞ fþðSk IC PÞ。
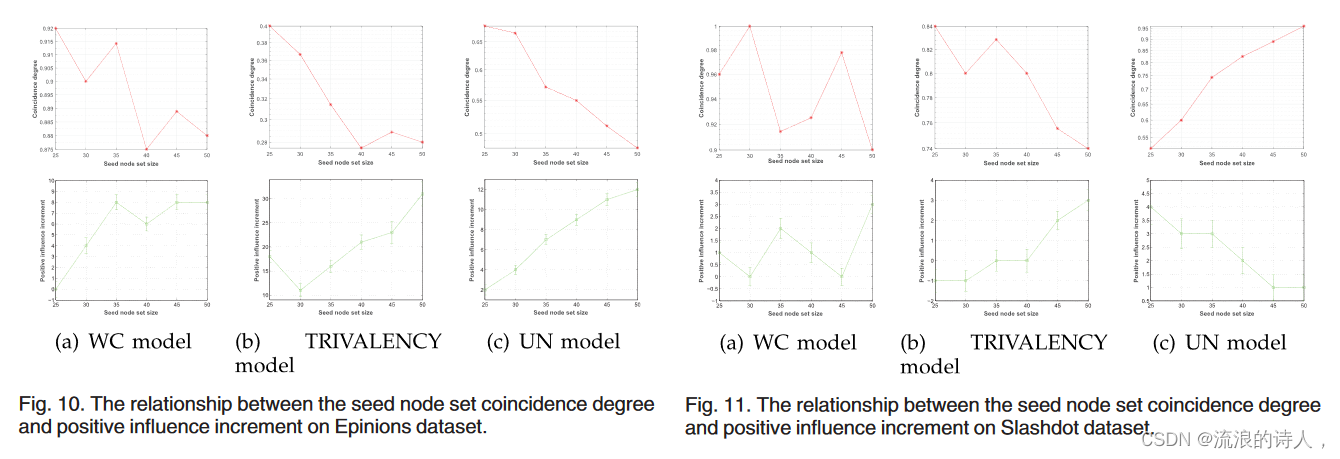
图10.Epinions数据集种子节点集重合度与正向影响增量之间的关系。

图11. Slashdot数据集上种子节点集重合度与正向影响增量之间的关系。
图。10和11在Epinions和Slashdot数据集上给出了三种扩散概率模型下的正影响增量与节点集重合度的关系。我们可以看到,每个图包含三个子图对应不同的扩散概率,每个子图也包含两部分:在子图的上半部分,x轴代表节点集的大小,y轴代表PLID Greedy相对于ICP Greedy的正影响增量;在子图的下方部分,x轴表示节点集的大小,y轴表示由PLID Greedy和IC - P Greedy提取的两个种子节点集的重合度。当节点集规模较小时,存在一定的随机性。因此,在所有这些数字中,种子的数量为了准确度量正影响增量,我们分别对IC - P模型和PLID模型选取的两个大小相同的种子节点集进行20000次模拟,然后取所有模拟的平均值。此外,为了验证正影响增量的可信性,我们还计算了图中影响增量图的标准差并标注了误差条。10和11。从这两幅图中,我们可以看出波动的情况误差条是合理的,可以接受的。因此,图中显示的正向影响增量是可信的。
从图。 10和11,我们发现一个有趣的现象。随着节点集规模的增大,重合度越小,正向影响增量通常越大;当重合度变大时,正面影响增量通常会变小。这种现象意味着当PLID Greedy和IC-P Greedy选择不同的节点作为种子时,我们的PLID Greedy选择的这些节点通常比IC-P Greedy选择的节点具有更多的正影响增量。上述结果实证验证了我们提出的模型的合理性和有效性。
在这里,我们从理论上分析了我们的 PLID Greedy 在 IC-P 模型下取得比 IC-P Greedy 更好的性能的可能性。 IC-P Greedy算法无法实现PIM问题的最优解,它仅保证IC-P模型下的1 1=e近似解。类似地,PLID Greedy 算法获得的解可证明在 PLID 模型最优解的 1 1=e 范围内。这里,我们将 SICP 和 SPLID 分别表示为 IC-P Greedy 和 PLID Greedy 算法选择的种子集,将 S 表示为 PIM 问题最优解的种子节点集。基于以上描述,我们假设 fþðSIC P Þ1⁄4uIC P fþðS Þ 和 fþðSPLIDÞ1⁄4uPLIDfþðS Þ。当出现uPLID uIC P 1 1=e的情况时,在相同测量标准下(即: ,IC-P型号)。
最后,我们尝试解释 PLID 模型和 IC-P 模型之间的相关性。首先,从影响函数性质来看,这两个模型下的正影响函数都是单调的、子模的。因此,两个模型采用相同的贪心选择策略来解决PIM问题。然而,我们的 PLID 模型可以在更短的运行时间内获得与 IC-P 模型相当或更好的正面和负面影响扩散性能。其次,从影响概率的角度来看,IC-P模型理论上也可以计算出类似于PLID模型计算值的影响概率。然而,从种子节点集到一个节点的路径太多节点,这导致直接计算影响概率非常困难。在具体计算过程中,IC-P模型需要借助蒙特卡罗模拟来估计影响。
6 CONCLUSIONS
在本文中,我们首先提出了极性相关线性影响扩散模型来估计在线社交系统中用户集的极性相关影响。接下来,我们利用 PLID 模型来解决 PIM 问题。具体来说,我们证明了 PIM 问题的目标函数保持单调性和子模性,并提出了选择种子节点的贪婪解决方案。最后,对 Epinions 和 Slashdot 数据集的综合实验表明,我们的方法在积极影响传播和运行时间方面比最先进的方法具有更好的性能。
用户的极性相关影响也与时间相关。因此,如何将时间因素引入我们的模型中来计算时间极性相关的影响将是一个有趣的问题。除此之外,虽然我们的 PLID 模型比 IC-P 模型快得多,但贪婪算法的计算量仍然很大。针对PIM问题开发更高效的种子节点选择策略将是我们未来的研究方向之一。最后,在线社交系统为社会计算研究提供了大量多样化的数据[49],如何利用大数据揭示隐含的社会现象并服务社会值得探索。
这篇关于Modeling Influence Diffusion over Signed Social Networks的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







