本文主要是介绍【机器学习小论文】sklearn随机森林RandomForestRegressor代码及调参,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、前言
前一篇是写的线性回归模型,这一篇为随机森林,下一篇为xgboost。
二、算法简介
2.1 随机森林概述
随机森林是集成学习方法bagging类中的翘楚。与集成学习boosting类的GBDT分庭抗礼。
bagging类集成学习采用的方法是:用部分数据 or 部分特征 or 多个算法 训练一些模型;然后再组合这些模型,对于分类问题采用投票多数表决,回归问题采用求平均。
各个模型训练之间互不影响,天生就适合并行化处理。在如今大数据时代背景下很有诱惑力。
主要效果:重点关注降低方差,防止过拟合。
适用于高噪声数据 (相对于GBDT等boosting类)
2.2 随机森林框架参数
在scikit-learn中,RF的分类器是RandomForestClassifier,回归器是RandomForestRegressor。和GBDT的调参类似,RF需要调参的参数也包括两部分,第一部分是Bagging框架的参数,第二部分是CART决策树的参数。具体的参数参考随机森林分类器的函数原型
classsklearn.ensemble.RandomForestRegressor(
n_estimators=10, criterion='gini',
max_depth=None,min_samples_split=2,
min_samples_leaf=1, min_weight_fraction_leaf=0.0,
max_features='auto', max_leaf_nodes=None,
min_impurity_split=1e-07,bootstrap=True,
oob_score=False, n_jobs=1,
random_state=None, verbose=0,
warm_start=False, class_weight=None)
- (1)n_estimators:
也就是弱学习器的最大迭代次数,或者说最大的弱学习器的个数。一般来说n_estimators太小,容易过拟合,n_estimators太大,又容易欠拟合,一般选择一个适中的数值。默认是100。
- (2)oob_score:
即是否采用袋外样本来评估模型的好坏。默认识False。个人推荐设置为True,因为袋外分数反应了一个模型拟合后的泛化能力。
- (3) criterion:
即CART树做划分时对特征的评价标准。分类模型和回归模型的损失函数是不一样的。分类RF对应的CART分类树默认是基尼系数gini,另一个可选择的标准是信息增益。回归RF对应的CART回归树默认是均方差mse,另一个可以选择的标准是绝对值差mae。一般来说选择默认的标准就已经很好的。
再把调参具体说下:

1、首先先调既不会增加模型复杂度,又对模型影响最大的参数n_estimators(学习曲线)
2、找到最佳值后,调max_depth(单个网格搜索,也可以用学习曲线)
一般根据数据的大小来进行一个试探,乳腺癌数据很小,所以可以采用1~10,或者1~20这样的试探但对于像digit recognition那样的大型数据来说,我们应该尝试30~50层深度(或许还不足够)
3、接下来依次对各个参数进行调参。
注:对于大型数据集,max_leaf_nodes可以尝试从1000来构建,先输入1000,每100个叶子一个区间,再逐渐缩小范围
对于min_samples_split和min_samples_leaf,一般是从他们的最小值开始向上增加10或20,面对高维度高样本量数据,如果不放心,也可以直接+50,对于大型数据,可能需要200~300的范围,如果调整的时候发现准确率无论如何都上不来,那可以放心大胆调一个很大的数据,大力限制模型的复杂度
三、代码及结果分析
随机森林中使用了k折交叉验证,并且使用了scikit-learn的网格搜索
from sklearn.impute import SimpleImputer
from sklearn.metrics import mean_absolute_error
from sklearn.model_selection import KFold
from sklearn.metrics import r2_score
from sklearn.preprocessing import *
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import PolynomialFeatures
from sklearn.metrics import mean_squared_error
from sklearn.ensemble import RandomForestRegressor
import importlib
from sklearn.model_selection import GridSearchCV
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
import pandas as pd
import datetime
from numpy import nan as NaN
from sklearn import metrics
from pylab import *
mpl.rcParams['font.sans-serif'] = ['SimHei']
mpl.rcParams['axes.unicode_minus'] = Falsestarttime = datetime.datetime.now()
df_merge = pd.read_csv('D:/myCode/spark/spark_ML/df_merge.csv')
# 打乱数据顺序
df_merge=df_merge.reindex(np.random.permutation(df_merge.index))#1.用常数填充
df_merge = df_merge.replace(np.nan, 0)# 准备训练、测试集
X = df_merge.drop(['成交价'],axis=1)
y = df_merge['成交价']
# xtrain,xtest,ytrain,ytest = train_test_split(X,y,test_size=0.2,random_state=42) # random_state=42
# xtrain = xtrain.astype(np.float64)
# xtest = xtest.astype(np.float64)
# k折交叉拆分器 - 用于网格搜索
# cv = KFold(n_splits=3,shuffle=True)# print(np.isnan(df_merge).any())# Y_train=df_merge['成交价']
# X_train=df_merge.drop(['成交价'],axis=1)xtrain,xtest,ytrain,ytest = train_test_split(X,y,test_size=0.2,random_state=42) # random_state=42
xtrain = xtrain.astype(np.float64)
xtest = xtest.astype(np.float64)
# 调用scikit-learn的网格搜索,传入参数选择范围,并且制定随机森林回归算法,cv = 5表示5折交叉验证
# param_grid = {"n_estimators":[5,10,50,100,200,500],"max_depth":[5,10,50,100,200,500]}
param_grid = {"n_estimators":[500,800,1000],"max_depth":[8,9,10]}
grid_search = GridSearchCV(RandomForestRegressor(),param_grid,cv = 3)# 让模型对训练集和结果进行拟合
grid_search.fit(xtrain,ytrain)y_hat = grid_search.predict(xtest)
# y_test与y_hat的可视化
# 设置图片尺寸
plt.figure(figsize=(10, 6))
# 创建t变量
t = np.arange(len(xtest))
# 绘制y_test曲线
plt.plot(t, ytest, 'r', linewidth=2, label='真实值')
# 绘制y_hat曲线
plt.plot(t, y_hat, 'g', linewidth=2, label='预测值')
# 设置图例
plt.legend()
plt.show()# 拟合优度R2的输出方法
print("r2:", grid_search.score(xtest, ytest))# 用Scikit_learn计算MAE
print("MAE:", metrics.mean_absolute_error(ytest, y_hat))# 用Scikit_learn计算MSE
print("MSE:", metrics.mean_squared_error(ytest, y_hat))# 用Scikit_learn计算RMSE
print("RMSE:", np.sqrt(metrics.mean_squared_error(ytest, y_hat)))# 打印前20个预测值
print("*"*10)
print("真实值:")
print(ytest[0:20])
print("预测值:")
print(y_hat[0:20])
# y_hat[0:9]
print("*"*10)
endtime = datetime.datetime.now()
print (endtime - starttime)结果:
r2: 0.8848928107136049 MAE: 37.974701393581306 MSE: 3806.7734679592963 RMSE: 61.699055648845196运行时间:0:09:13.530739 9分多钟
如果再继续调参,修改param_grid = {"n_estimators":[500,800,1000],"max_depth":[8,9,10],"oob_score":[False], "n_jobs":[-1]},那么结果其实差距不大, 但是运行时间大大减少,只有2分多钟
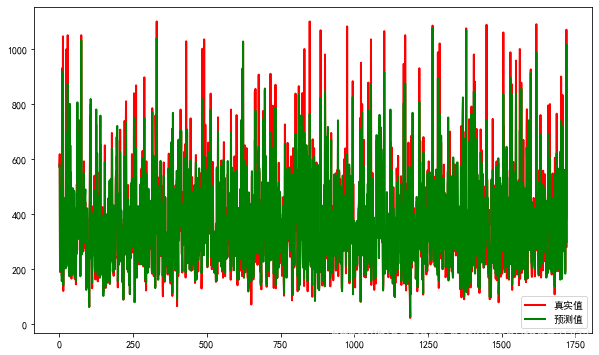
从结果看,明显比上次的线性回归模型准确多了,r2提高到了0.88,MSE的值也由8000多降到了不到4000,随机选择了几个预测值,感觉结果不错。理论上下次的xgboost模型会更好,毕竟进行了参数优化,肯定会有更好的结果。

预测值 真实值
578.73191203 573
565.71750749 618
194.05789389 190
220.47973742 248
495.0728485 425
387.77640548 373
219.75210522 238
481.36157168 507
156.54966457 177
751.57122229 930
615.83101317 537
656.35241424 726
918.71174488 1046
140.72794847 121
311.45338042 266
315.48914039 344
458.29755206 410
435.66571209 390
437.06709882 413
312.27525411 269
这篇关于【机器学习小论文】sklearn随机森林RandomForestRegressor代码及调参的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




