本文主要是介绍探索可扩展指令式多世界代理(SIMA):谷歌DeepMind在通用游戏AI领域的新里程碑,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领域的领跑者。点击订阅,与未来同行! 订阅:https://rengongzhineng.io/

在最新的科技研究领域,谷歌DeepMind团队推出了一项名为“可扩展指令式多世界代理”(Scalable Instructable Multiworld Agent,以下简称SIMA)的研究,这是一种能够根据自然语言指令在多种视频游戏设置中执行任务的代理。
视频游戏被视为人工智能(AI)系统的重要试验场。与现实世界类似,游戏提供了丰富的学习环境,其中包含了响应式的实时场景和不断变化的目标。
从谷歌DeepMind早期在雅达利游戏上的工作,到其AlphaStar系统在星际争霸II游戏中达到人类大师级水平,该团队在AI与游戏领域拥有长期的研究历史。
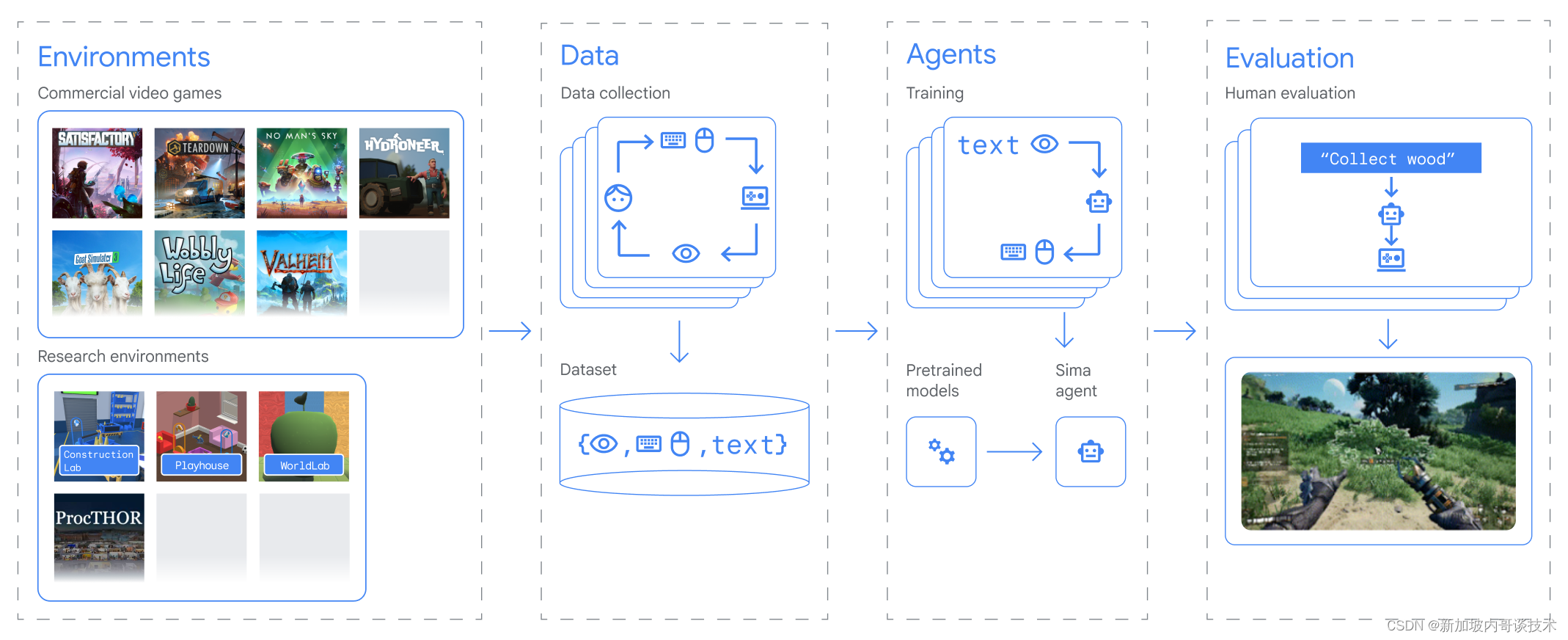
如今,谷歌DeepMind宣布了一个新的里程碑——其研究重点从针对单一游戏的研究转变为开发一个能够理解和执行多种游戏指令的通用AI代理。
在一份新的技术报告中,谷歌DeepMind团队介绍了“可扩展指令式多世界代理”,这是一种针对3D虚拟环境设计的通用AI代理。谷歌DeepMind与游戏开发商合作,训练SIMA在多种视频游戏中学习。这项研究首次证明了一种代理能够理解广泛的游戏世界,并能够根据自然语言指令在这些游戏世界中执行任务,如同人类可能做的那样。
该项工作的重点并不是在游戏中获得高分。对于AI系统而言,学会玩一个视频游戏本身就是一个技术挑战,但学会在多种游戏环境中根据指令执行任务可能会开启更多有用的AI代理,用于各种环境。该团队的研究展示了如何将先进AI模型的能力通过语言界面转化为实用的、现实世界中的行动。谷歌DeepMind希望,通过SIMA及其他代理的研究,可以利用视频游戏作为沙盒,更好地理解AI系统如何变得更加有益。
为了使SIMA接触到多样的环境,谷歌DeepMind与游戏开发商建立了合作伙伴关系。团队与八家游戏工作室合作,训练和测试SIMA在九种不同的视频游戏上,例如Hello Games的《无人深空》和Tuxedo Labs的《Teardown》。SIMA的投资组合中的每款游戏都开启了一个新的互动世界,其中包括从简单的导航和菜单使用到采矿资源、驾驶太空船或制作头盔等多种技能学习。
谷歌DeepMind还使用了四个研究环境,包括与Unity合作建立的一个名为建筑实验室的新环境,代理需要在此环境中从建筑块中构建雕塑,测试其物体操作和对物理世界的直观理解能力。
通过学习不同的游戏世界,SIMA能够理解语言与游戏行为之间的联系。谷歌DeepMind的首次尝试是记录其投资组合中游戏的人类玩家配对,其中一位玩家观察并指导另一位玩家。玩家还可以自由玩游戏,然后回顾他们的游戏行为,并记录下能够导致这些游戏行为的指令。
SIMA包括预训练的视觉模型和一个主模型,后者包含内存并输出键盘和鼠标动作。
作为一个多才多艺的AI代理,SIMA能够感知和理解多种环境,然后采取行动以实现指定的目标。它包括一个设计用于精确图像-语言映射的模型和一个视频模型,后者预测屏幕上接下来会发生什么。这些模型在特定于SIMA投资组合中的3D设置的训练数据上进行了微调。
谷歌DeepMind的AI代理不需要访问游戏的源代码或特定的API。它只需要两种输入:屏幕上的图像和用户提供的简单自然语言指令。SIMA使用键盘和鼠标输出来控制游戏的中心角色执行这些指令。这种简单的界面与人类使用的界面相同,意味着SIMA可以潜在地与任何虚拟环境进行交互。
SIMA当前版本在600个基本技能上进行了评估,包括导航(例如“向左转”)、物体交互(例如“爬梯子”)和菜单使用(例如“打开地图”)。谷歌DeepMind训练了SIMA执行可以在大约10秒内完成的简单任务。
谷歌DeepMind希望其未来的代理能够处理需要高级战略规划和完成多个子任务的任务,例如“找到资源并建立一个
营地”。这对于AI总体来说是一个重要的目标,因为尽管大型语言模型催生了强大的系统,这些系统可以捕获关于世界的知识并生成计划,但它们目前缺乏代表我们采取行动的能力。
在游戏和更多方面的泛化是谷歌DeepMind研究的重要部分。该团队展示了在多种游戏上训练的代理比只学会玩一个游戏的代理表现更好。在评估中,接受其投资组合中九款3D游戏训练的SIMA代理显著优于仅在每个单一游戏上训练的所有专业代理。更重要的是,除了一个游戏之外在所有游戏上训练的代理在那个未见过的游戏上的表现几乎与专门在其上训练的代理一样好,平均而言。这种在全新环境中正常工作的能力突出了SIMA的泛化能力。这是一个有希望的初步结果,然而,需要更多研究才能使SIMA在已知和未知的游戏中都能达到人类水平的表现。
谷歌DeepMind的结果还显示,SIMA的表现依赖于语言。在一个未给代理提供任何语言训练或指令的控制测试中,它以适当但无目的的方式行动。例如,一个代理可能会收集资源,这是一种频繁的行为,而不是按照指令行动。
谷歌DeepMind评估了SIMA遵循指令完成近1500个独特的游戏内任务的能力,部分使用人类评审。作为基线比较,该团队使用了环境专业的SIMA代理的表现(训练和评估以遵循单一环境内的指令)。这种表现与三种类型的通用SIMA代理进行了比较,每种都在多个环境中接受了训练。
推进AI代理研究是谷歌DeepMind的目标之一。SIMA的结果显示了开发一系列通用的、由语言驱动的AI代理的潜力。这是早期研究,该团队期待在更多训练环境中进一步构建SIMA,并整合更有能力的模型。
随着SIMA接触到更多训练世界,谷歌DeepMind预期它会变得更具泛化性和多才多艺。随着模型的进步,该团队希望提高SIMA对更高级语言指令的理解和行动能力,以实现更复杂的目标。
最终,谷歌DeepMind的研究旨在构建更通用的AI系统和代理,这些系统和代理可以理解并安全地执行广泛的任务,以一种对人类在线和现实世界有帮助的方式。
这篇关于探索可扩展指令式多世界代理(SIMA):谷歌DeepMind在通用游戏AI领域的新里程碑的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







