本文主要是介绍碾压LoRA!Meta CMU | 提出高效大模型微调方法:GaLore,内存可减少63.3%,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
来源: AINLPer公众号(每日干货分享!!)
编辑: ShuYini
校稿: ShuYini
时间: 2024-3-13
引言
大模型训练通常会遇到内存资源的限制。目前常用的内存减少方法低秩适应(LoRA),通过引入低秩(low-rank)适配器来更新模型的权重,而不是直接更新整个权重矩阵。然而,这种方法在预训练和微调阶段通常表现不佳,为此,本文作者提出了梯度低秩映射(Gradient Low-Rank Projection ,GaLore),这是一种允许全参数学习的训练策略,并且比 LoRA 等常见的低秩适应方法更节省内存,内存最高可减少了 63.3% 。

论文获取,GZ: AINLPer公众号 回复:GaLore论文
背景介绍
大型语言模型(LLMs)在对话式人工智能和语言翻译等领域展现出了令人印象深刻的性能。训练这些大模型(LLMs)不仅需要大量的计算资源,而且对内存的需求也非常大。这里的内存需求不仅仅是指数十亿个可训练的参数,还包括它们的梯度和优化器状态,比如Adam中的梯度动量和方差,这些往往比参数本身占用的存储空间还要大。
举个例子,如果我们从头开始训练一个LLaMA 7B模型,即使是用最小的批量大小,也需要至少58GB的内存,其中14GB用于存储可训练的参数,42GB用于存储Adam优化器的状态和权重梯度,还有2GB用于存储激活值。这样的内存需求使得在像NVIDIA RTX 4090这样只有24GB内存的消费级GPU上进行训练变得不太现实。
除了工程和系统方面的努力,比如梯度检查点和内存卸载等技术来实现更快更高效的分布式训练,研究人员还在寻求开发各种优化技术,以减少预训练和微调过程中的内存使用。
高效参数微调(Parameter-efficient fine-tuning,PEFT )技术让我们能够高效的将预训练语言模型(PLMs)适配至不同的下游任务中,从而无需对模型的所有参数进行调整。其中,当前较火的低秩适应(LoRA)技术将权重矩阵 W ∈ R m × n W\in \mathbb{R} ^{m\times n} W∈Rm×n重新参数化为 W = W 0 + B A W = W_0 + BA W=W0+BA,这里的 W 0 W_0 W0是一个固定的全秩矩阵,而 B ∈ R m × r B\in \mathbb{R} ^{m\times r} B∈Rm×r和 A ∈ R r × n A\in \mathbb{R} ^{r\times n} A∈Rr×n是待学习的附加低秩适配器。因为秩 r ≪ m i n ( m , n ) r\ll min(m,n) r≪min(m,n),所以A和B包含的可训练参数数量较少。
当前LoRA已经被广泛使用,其中 W 0 W_0 W0是固定的预训练权重。它的变体ReLoRA也用于预训练,通过定期使用之前学到的低秩适配器来更新 W 0 W_0 W0。然而对于微调来说,有研究表明LoRA并没有显示出与全秩微调相当的性能。对于从头开始的预训练,它被证明需要一个全秩模型训练作为热身,然后才能在低秩子空间中进行优化。这其中可能有两个原因:(1)最优的权重矩阵可能不是低秩的;(2)重新参数化改变了梯度训练的动态。
为了解决上述挑战,本文作者提出了Gradient Low-Rank Projection(GaLore)训练策略,它允许全参数学习,同时比LoRA等常见低秩适应方法更节省内存。
GaLore介绍
GaLore的核心思想是在训练过程中利用梯度的低秩特性,而不是直接对权重矩阵进行低秩近似。具体来说:
在LLMs的训练过程中,权重矩阵W的梯度G( W ∈ R m × n W\in \mathbb{R} ^{m\times n} W∈Rm×n)通常具有低秩结构。这意味着梯度矩阵可以通过较小的子空间来近似表示,从而减少内存占用。GaLore通过计算两个投影矩阵 P ∈ R m × r P\in \mathbb{R} ^{m\times r} P∈Rm×r和 Q ∈ R n × r Q\in \mathbb{R} ^{n\times r} Q∈Rn×r,将梯度矩阵G投影到一个低秩形式 P ⊤ G Q P^⊤GQ P⊤GQ。这样的投影操作可以显著降低优化器状态的内存成本,因为P 和 Q 的低频率更新(例如,每 200 次迭代)会产生最小的额外计算成本。
在训练过程中GaLore可以动态的切换低秩子空间,这意味着模型可以在不同的子空间中学习,而不是局限于单一的低秩空间。这种动态切换通过定期更新投影矩阵P和Q来实现,以适应梯度的变化。此外,GaLore在内存使用上进行了优化,例如,它只使用一个投影矩阵P或Q,而不是同时使用两个,这进一步减少了内存需求。
不仅如此GaLore还可以与现有技术结合,例如:与8位优化器的结合:GaLore可以与8位优化器(如8位Adam)结合使用,这些优化器已经在内存使用上进行了优化。结合使用GaLore和8位优化器可以在保持性能的同时,进一步降低内存占用。逐层权重更新:GaLore还与逐层权重更新技术结合,这种技术在反向传播期间执行权重更新,从而减少了存储整个权重梯度的需要。
GaLore引入了少量额外的超参数:除了Adam的原始超参数外,GaLore引入了秩 r r r、子空间切换频率 T T T和缩放因子 α α α。这些超参数有助于调整GaLore的行为,以适应不同的训练需求。其中在Adam引入GaLore如下所示。

实验结果
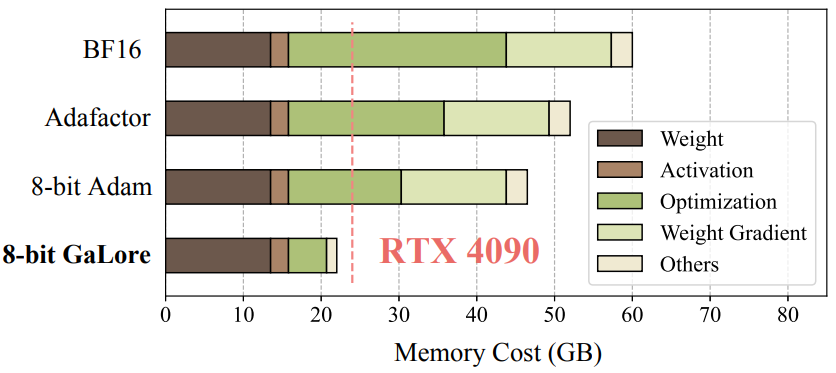
如下图,展示了在预训练LLaMA 7B模型时,不同方法的内存消耗。与 BF16 Adam 基线和 8 位 Adam 相比,8 位 GaLore 分别减少了 37.92G (63.3%) 和 24.5G (52.3%) 总内存。。
如下图,在GLUE基准测试中,GaLore在微调预训练的RoBERTa模型时,与LoRA相比,取得了更好的性能。

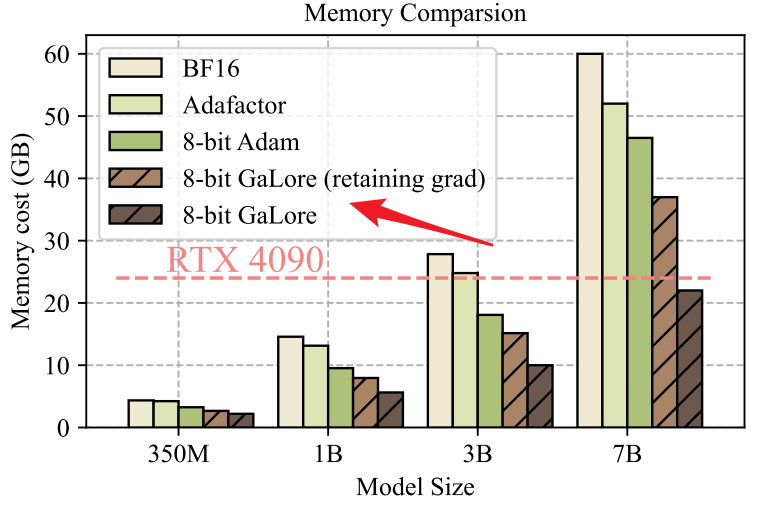
如下图,在不同模型大小下,使用不同方法时的内存使用情况。这进一步证实了GaLore在内存效率方面的优势。
这篇关于碾压LoRA!Meta CMU | 提出高效大模型微调方法:GaLore,内存可减少63.3%的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




