本文主要是介绍YOLOv9改进策略:注意力机制 | SKAttention注意力效果优于SENet,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
💡💡💡本文改进内容:SKAttention输入自适应地调整其感受野大小的能力
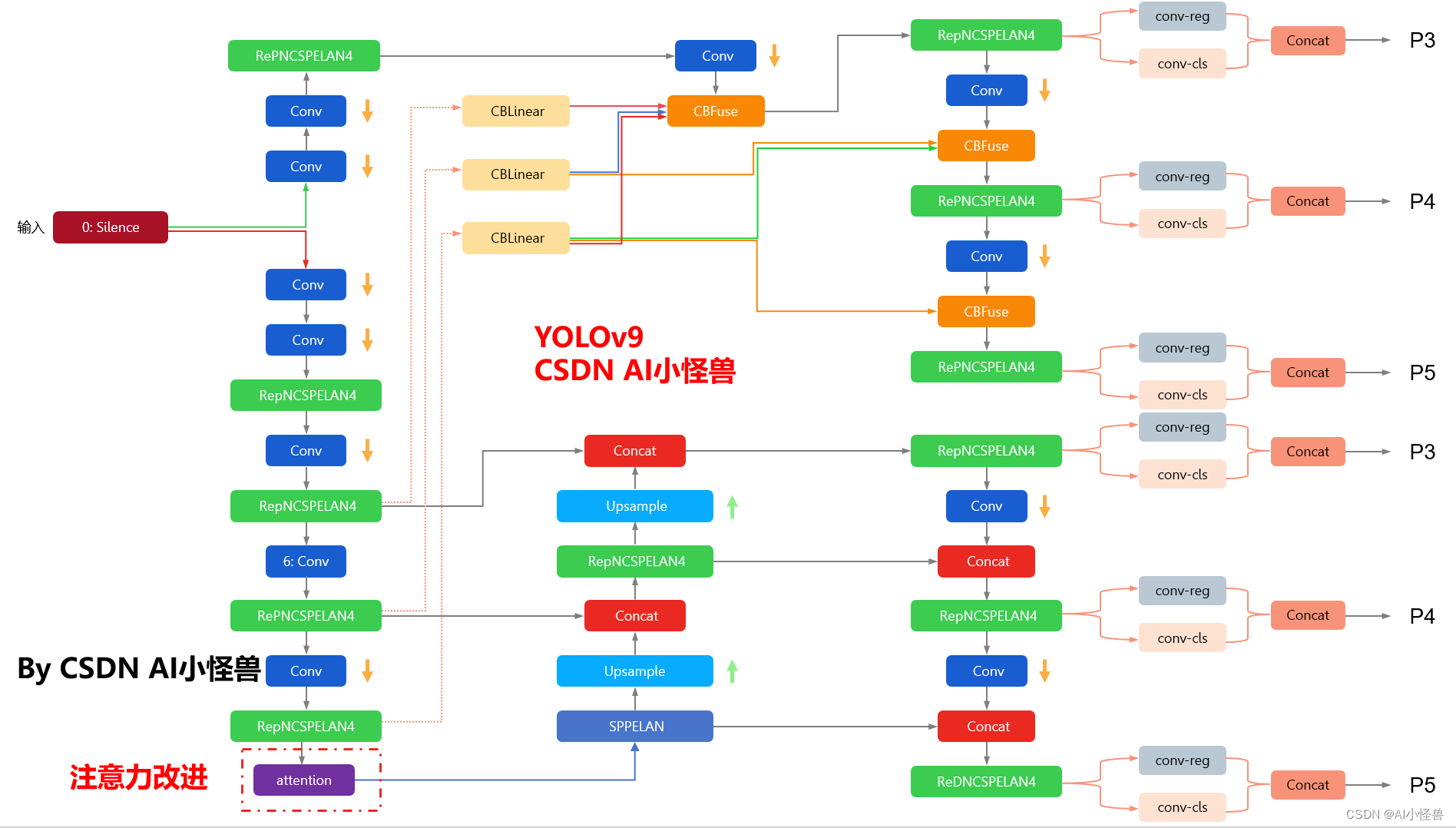
yolov9-c-SKAttention summary: 987 layers, 73109830 parameters, 73109798 gradients, 256.5 GFLOPs改进结构图如下:
YOLOv9魔术师专栏
☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️ ☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️
包含注意力机制魔改、卷积魔改、检测头创新、损失&IOU优化、block优化&多层特征融合、 轻量级网络设计、24年最新顶会改进思路、原创自研paper级创新等
☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️
✨✨✨ 新开专栏暂定免费限时开放,后续每月调价一次✨✨✨
🚀🚀🚀 本项目持续更新 | 更新完结保底≥50+ ,冲刺100+🚀🚀🚀
🍉🍉🍉 联系WX: AI_CV_0624 欢迎交流!🍉🍉🍉

YOLOv9魔改:注意力机制、检测头、blcok魔改、自研原创等
YOLOv9魔术师
💡💡💡全网独家首发创新(原创),适合paper !!!
💡💡💡 2024年计算机视觉顶会创新点适用于Yolov5、Yolov7、Yolov8等各个Yolo系列,专栏文章提供每一步步骤和源码,轻松带你上手魔改网络 !!!
💡💡💡重点:通过本专栏的阅读,后续你也可以设计魔改网络,在网络不同位置(Backbone、head、detect、loss等)进行魔改,实现创新!!!
1.YOLOv9原理介绍

论文: 2402.13616.pdf (arxiv.org)
代码:GitHub - WongKinYiu/yolov9: Implementation of paper - YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information摘要: 如今的深度学习方法重点关注如何设计最合适的目标函数,从而使得模型的预测结果能够最接近真实情况。同时,必须设计一个适当的架构,可以帮助获取足够的信息进行预测。然而,现有方法忽略了一个事实,即当输入数据经过逐层特征提取和空间变换时,大量信息将会丢失。因此,YOLOv9 深入研究了数据通过深度网络传输时数据丢失的重要问题,即信息瓶颈和可逆函数。作者提出了可编程梯度信息(programmable gradient information,PGI)的概念,来应对深度网络实现多个目标所需要的各种变化。PGI 可以为目标任务计算目标函数提供完整的输入信息,从而获得可靠的梯度信息来更新网络权值。此外,研究者基于梯度路径规划设计了一种新的轻量级网络架构,即通用高效层聚合网络(Generalized Efficient Layer Aggregation Network,GELAN)。该架构证实了 PGI 可以在轻量级模型上取得优异的结果。研究者在基于 MS COCO 数据集的目标检测任务上验证所提出的 GELAN 和 PGI。结果表明,与其他 SOTA 方法相比,GELAN 仅使用传统卷积算子即可实现更好的参数利用率。对于 PGI 而言,它的适用性很强,可用于从轻型到大型的各种模型。我们可以用它来获取完整的信息,从而使从头开始训练的模型能够比使用大型数据集预训练的 SOTA 模型获得更好的结果。对比结果如图1所示。

YOLOv9框架图
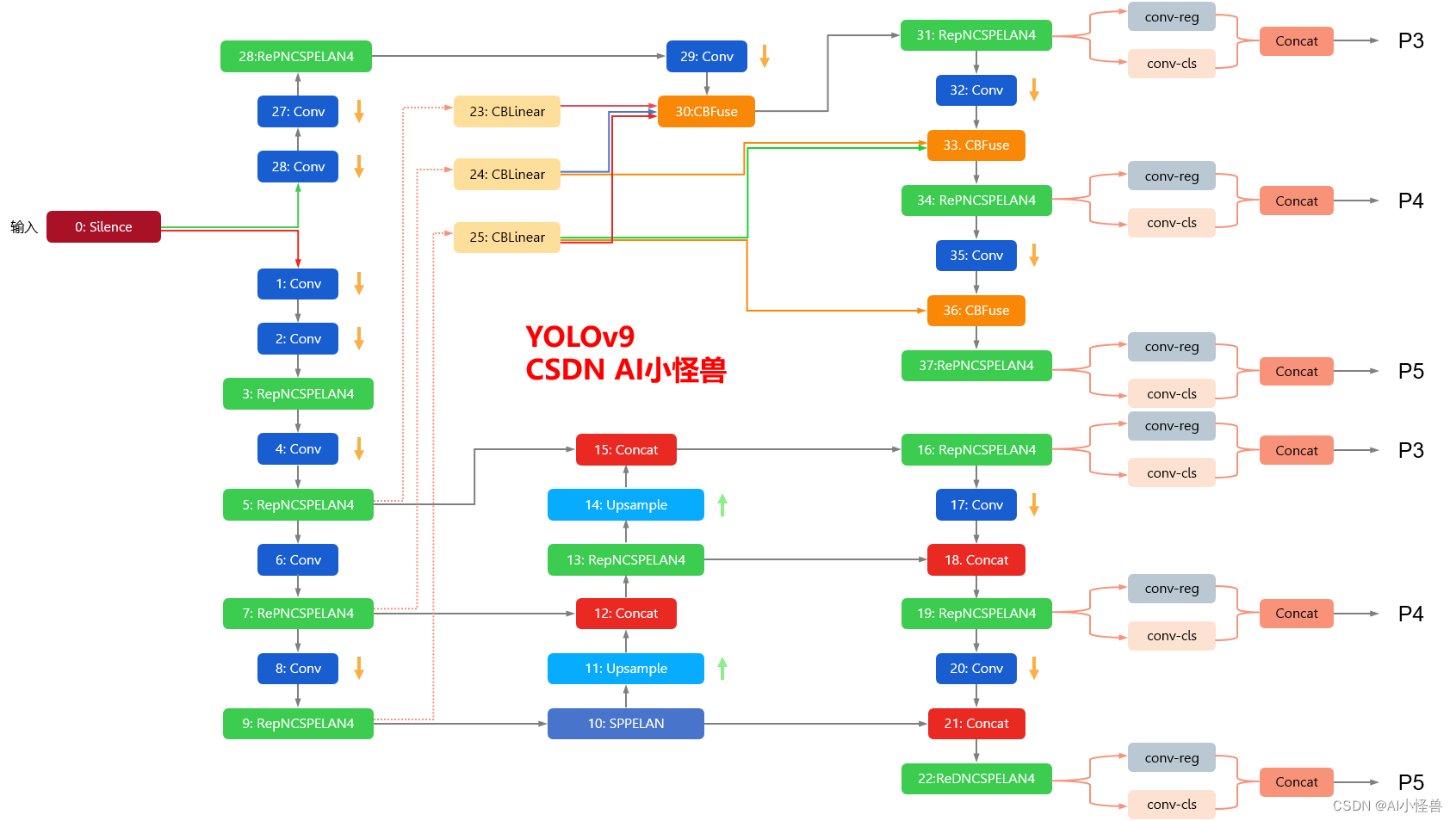
1.1 YOLOv9框架介绍
YOLOv9各个模型介绍

2. SKAttention

论文:https://arxiv.org/pdf/1903.06586.pdf
多个 SK 块的堆叠得到 SKNet,这个名字也是为了致敬 SENet。
SKNet 在 ImageNet、CIFAR 数据集上都取得了 SOTA。
详细的实验分析表明,SKNet 中的神经元可以捕获具有不同比例的目标对象,实验验证了神经元根据输入自适应地调整其感受野大小的能力。

本文的方法分为三个部分:Split,Fuse,Select。Split就是一个multi-branch的操作,用不同的卷积核进行卷积得到不同的特征;Fuse部分就是用SE的结构获取通道注意力的矩阵(N个卷积核就可以得到N个注意力矩阵,这步操作对所有的特征参数共享),这样就可以得到不同kernel经过SE之后的特征;Select操作就是将这几个特征进行相加。
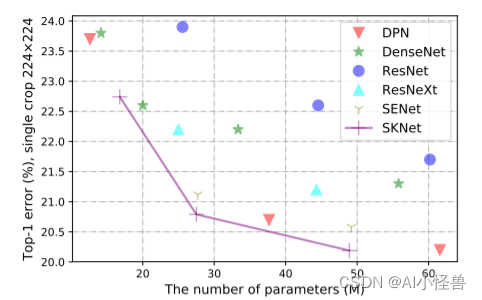
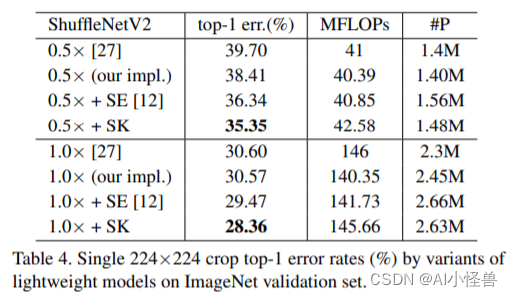
3.SKAttention加入到YOLOv9
3.1新建py文件,路径为models/attention/attention.py
###################### SKAttention #### start by AI&CV ###############################from torch.nn import init
from collections import OrderedDictclass SKAttention(nn.Module):def __init__(self, c1,channel=512, kernels=[1, 3, 5, 7], reduction=16, group=1, L=32):super().__init__()self.d = max(L, channel // reduction)self.convs = nn.ModuleList([])for k in kernels:self.convs.append(nn.Sequential(OrderedDict([('conv', nn.Conv2d(channel, channel, kernel_size=k, padding=k // 2, groups=group)),('bn', nn.BatchNorm2d(channel)),('relu', nn.ReLU())])))self.fc = nn.Linear(channel, self.d)self.fcs = nn.ModuleList([])for i in range(len(kernels)):self.fcs.append(nn.Linear(self.d, channel))self.softmax = nn.Softmax(dim=0)def forward(self, x):bs, c, _, _ = x.size()conv_outs = []### splitfor conv in self.convs:conv_outs.append(conv(x))feats = torch.stack(conv_outs, 0) # k,bs,channel,h,w### fuseU = sum(conv_outs) # bs,c,h,w### reduction channelS = U.mean(-1).mean(-1) # bs,cZ = self.fc(S) # bs,d### calculate attention weightweights = []for fc in self.fcs:weight = fc(Z)weights.append(weight.view(bs, c, 1, 1)) # bs,channelattention_weughts = torch.stack(weights, 0) # k,bs,channel,1,1attention_weughts = self.softmax(attention_weughts) # k,bs,channel,1,1### fuseV = (attention_weughts * feats).sum(0)return V###################### SKAttention #### end by AI&CV ###############################
3.2修改yolo.py
1)首先进行引用
from models.attention.attention import *2)修改def parse_model(d, ch): # model_dict, input_channels(3)
在源码基础上加入SKAttention
elif m is nn.BatchNorm2d:args = [ch[f]]###attention #####elif m in {EMA_attention, CoordAtt,CBAM,GAM_Attention,PolarizedSelfAttention,SimAM,NAMAttention,DoubleAttention,SKAttention}:c2 = ch[f]args = [c2, *args]###attention #####3.3 yolov9-c-SKAttention.yaml
# YOLOv9# parameters
nc: 80 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
#activation: nn.LeakyReLU(0.1)
#activation: nn.ReLU()# anchors
anchors: 3# YOLOv9 backbone
backbone:[[-1, 1, Silence, []], # conv down[-1, 1, Conv, [64, 3, 2]], # 1-P1/2# conv down[-1, 1, Conv, [128, 3, 2]], # 2-P2/4# elan-1 block[-1, 1, RepNCSPELAN4, [256, 128, 64, 1]], # 3# avg-conv down[-1, 1, ADown, [256]], # 4-P3/8# elan-2 block[-1, 1, RepNCSPELAN4, [512, 256, 128, 1]], # 5# avg-conv down[-1, 1, ADown, [512]], # 6-P4/16# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 7# avg-conv down[-1, 1, ADown, [512]], # 8-P5/32# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 9[-1, 1, SKAttention, [512]], # 10]# YOLOv9 head
head:[# elan-spp block[-1, 1, SPPELAN, [512, 256]], # 11# up-concat merge[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 7], 1, Concat, [1]], # cat backbone P4# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 14# up-concat merge[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 5], 1, Concat, [1]], # cat backbone P3# elan-2 block[-1, 1, RepNCSPELAN4, [256, 256, 128, 1]], # 17 (P3/8-small)# avg-conv-down merge[-1, 1, ADown, [256]],[[-1, 14], 1, Concat, [1]], # cat head P4# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 20 (P4/16-medium)# avg-conv-down merge[-1, 1, ADown, [512]],[[-1, 11], 1, Concat, [1]], # cat head P5# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 23 (P5/32-large)# multi-level reversible auxiliary branch# routing[5, 1, CBLinear, [[256]]], # 24[7, 1, CBLinear, [[256, 512]]], # 25[9, 1, CBLinear, [[256, 512, 512]]], # 26# conv down[0, 1, Conv, [64, 3, 2]], # 27-P1/2# conv down[-1, 1, Conv, [128, 3, 2]], # 28-P2/4# elan-1 block[-1, 1, RepNCSPELAN4, [256, 128, 64, 1]], # 29# avg-conv down fuse[-1, 1, ADown, [256]], # 30-P3/8[[24, 25, 26, -1], 1, CBFuse, [[0, 0, 0]]], # 31 # elan-2 block[-1, 1, RepNCSPELAN4, [512, 256, 128, 1]], # 32# avg-conv down fuse[-1, 1, ADown, [512]], # 33-P4/16[[25, 26, -1], 1, CBFuse, [[1, 1]]], # 34 # elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 35# avg-conv down fuse[-1, 1, ADown, [512]], # 36-P5/32[[26, -1], 1, CBFuse, [[2]]], # 37# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 38# detection head# detect[[32, 35, 38, 17, 20, 23], 1, DualDDetect, [nc]], # DualDDetect(A3, A4, A5, P3, P4, P5)]这篇关于YOLOv9改进策略:注意力机制 | SKAttention注意力效果优于SENet的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





