本文主要是介绍5分绩点转4分_国足史上最严训练!4分40秒配速跑5公里,李铁教练全程陪同,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
近日,新一期国足集训队在李铁的率领下,在广州恒大里水训练基地进行集训。
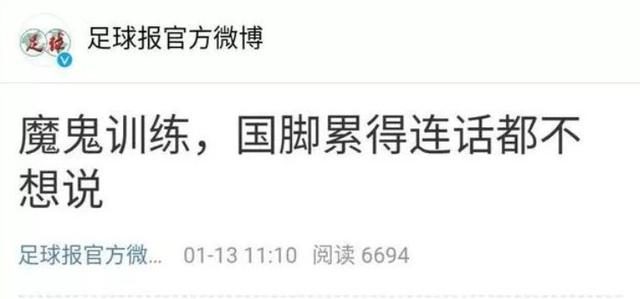
对于国足李铁也是投入了巨大的精力,并为球队安排了十分详细的训练计划,高强度的训练内容被媒体称为是"魔鬼训练"。

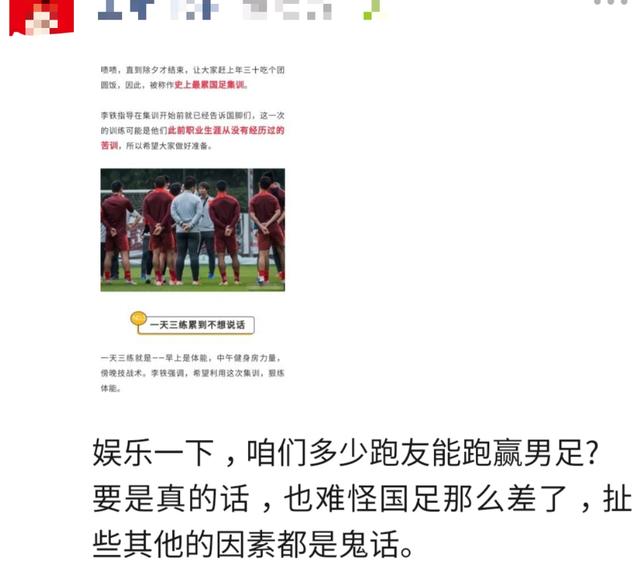
据称,"魔鬼训练"让国足球员叫苦不迭,甚至有的球员表示,在训练结束后,累得都不想说话,只想早早睡觉。
据媒体公布的这些训练中,包括有5组1000米跑训练,百米时速在25-28秒间调整,组间休息2分半钟;有12组500米间歇跑练习,每组都有不同的速度要求;甚至还有8000千米匀速跑这种看起来似乎没有什么难度的训练。
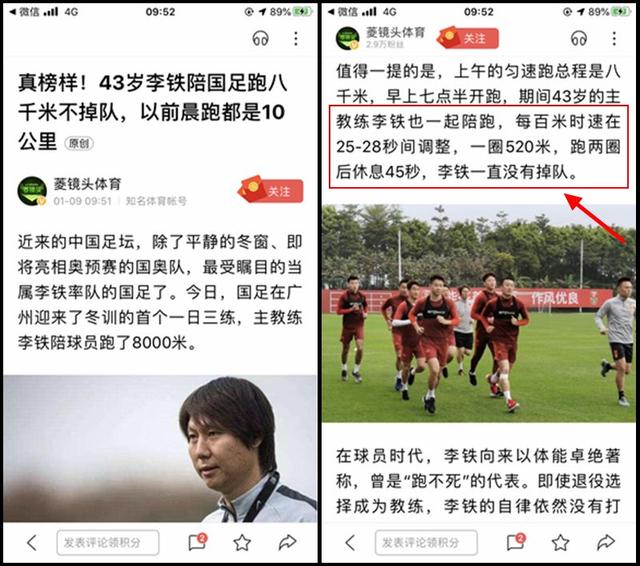
换算一下“5组1000米跑训练”就是:有5X1000米间歇跑,配速4分10到4分40之间,每段间歇1040米,中途休息45秒,再接着跑,总距离8公里,那么加上休息时间八公里跑的总耗时为38分35秒到42分35秒之间
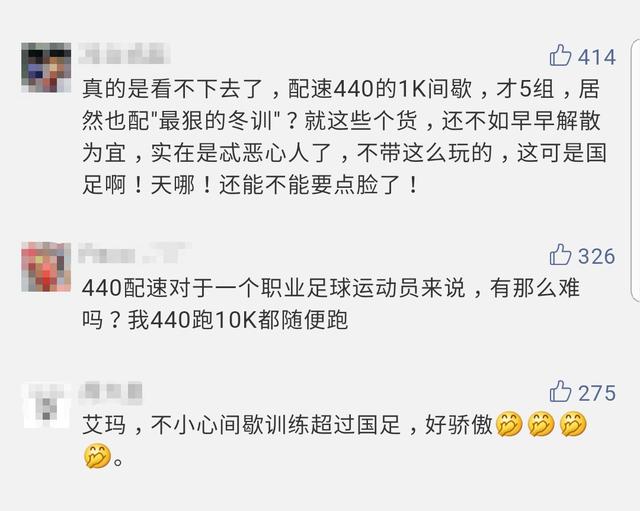
相关报道发布后后,国足的训练内容遭到了一些马拉松爱好者的嘲笑:"配速440也敢敢称最狠冬训?!"、"我440跑10K都是随便跑"、"不小心(自己)跑间歇都能超过国足了"
单从绝对配速来说,这个成绩的确不怎么样,训练强度不是很高,回去累到不想说话的话,这体能也真是不怎么样。但如果考虑背景,球员们都经历了一个疲惫的赛季,加上休假期刚刚回来,恢复必然是要从低强度开始的,一回来就高强度容易受伤,在不把人练伤的情况下,教练组这样的训练也算是合理的。也相信系统训练后,他们在体能上会有一定提高,毕竟底子还在那里放着。
近些年提到国足,不少球迷都是会觉得队伍管理很松懈,如今李铁执教,这一点上还是慢慢有了改变。
这一次集训主要是以体能储备为主,单这点来说,小编觉得李铁的思路比来得比里皮实在。

在里皮执教期间,不会对球员做体能训练要求。因为就世界名帅看来,之前身边的顶级球员都很很自律,体能训练这些事情不需要专门强调,应该把更多时间放到技战术安排上。
但是国足还是比较缺这些,如果脱离体能根基架空安排战术,战术够执行不到位一样不行,所以之后确实显得水土不服。
国足的巅峰时期也与当时严格的体测制度也不无关系,当时12分钟跑3000米不及格的话,会被取消甲A注册资格,最终国足成功冲击世界杯;2011年足协取消体测之后,国足球员身材迅速走形,被球迷戏称为为"白斩鸡"。


如今李铁愿意从实际出发,从最基本的体能开始练起,从这点来说,还真的是很赞的。凡事不可一蹴而就,就目前国足的情况,各方面的确都需要更多的时间。也希望赛场上能早日见到一支耳目一新的"铁军"的国足球队。
这篇关于5分绩点转4分_国足史上最严训练!4分40秒配速跑5公里,李铁教练全程陪同的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








