本文主要是介绍Python爬虫从入门到精通:(36)CrawlSpider实现深度爬取_Python涛哥,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
我们来看下CrawlSpider实现深度爬取。
爬取阳光热线标题、状态、和详情页内容。
https://wz.sun0769.com/political/index/politicsNewest?id=1&type=4&page=
创建CrawlSpider工程
-
scrapy startproject sunPro -
cd sunPro -
scrapy genspider -t crawl sun www.xxx.com -
修改配置文件等
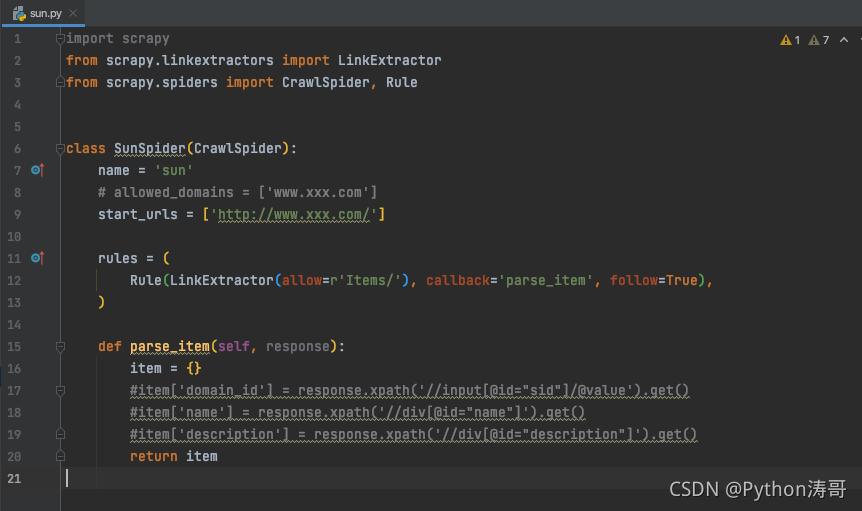
页面解析
提取下页码链接
我们看到这个网站有很多页面,我们先来提取下页码链接。

很容易分析到页面链接的规律,写下正则:
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Ruleclass SunSpider(CrawlSpider):name = 'sun'# allowed_domains = ['www.xxx.com']start_urls = ['https://wz.sun0769.com/political/index/politicsNewest?id=1&type=4&page=']# 提取页码链接link = LinkExtractor(allow=r'id=1&page=\d+')rules = (Rule(link, callback='parse_item', follow=True),)def parse_item(self, response):print(response)
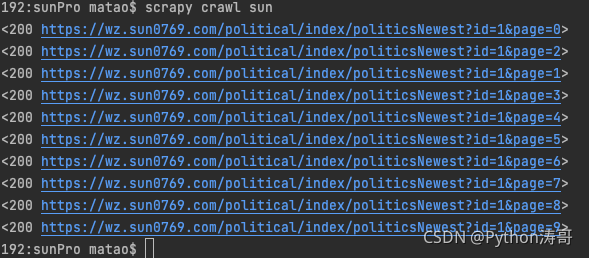
这里我们主要学习深度爬取,后面只用一页作为案例。follow=False
数据解析
我们来获取当前页的标题、详情页地址和状态

import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from sunPro.items import SunproItemclass SunSpider(CrawlSpider):name = 'sun'# allowed_domains = ['www.xxx.com']start_urls = ['https://wz.sun0769.com/political/index/politicsNewest?id=1&type=4&page=']# 提取页码链接link = LinkExtractor(allow=r'id=1&page=\d+')rules = (Rule(link, callback='parse_item', follow=False),)# 页面数据解析def parse_item(self, response):li_list = response.xpath('/html/body/div[2]/div[3]/ul[2]/li')for li in li_list:title = li.xpath('./span[3]/a/text()').extract_first()detail_url = 'https://wz.sun0769.com' + li.xpath('./span[3]/a/@href').extract_first()status = li.xpath('./span[2]/text()').extract_first()# 保存item提交给管道item = SunproItem()item['title'] = titleitem['detail_url'] = detail_urlitem['status'] = status**手动发送请求**现在我们用手动发送请求的方式解析详情页数据:```python
# 页面数据解析
def parse_item(self, response):li_list = response.xpath('/html/body/div[2]/div[3]/ul[2]/li')for li in li_list:title = li.xpath('./span[3]/a/text()').extract_first()detail_url = 'https://wz.sun0769.com' + li.xpath('./span[3]/a/@href').extract_first()status = li.xpath('./span[2]/text()').extract_first()# 保存item提交给管道item = SunproItem()item['title'] = titleitem['detail_url'] = detail_urlitem['status'] = statusyield scrapy.Request(url=detail_url, callback=self.parse_detail, meta={'item': item})# 详情页数据解析
def parse_detail(self, response):content = response.xpath('/html/body/div[3]/div[2]/div[2]/div[2]/pre/text()').extract_first()item = response.meta['item']item['content'] = contentyield item
运行一下,我们就获取了全部数据
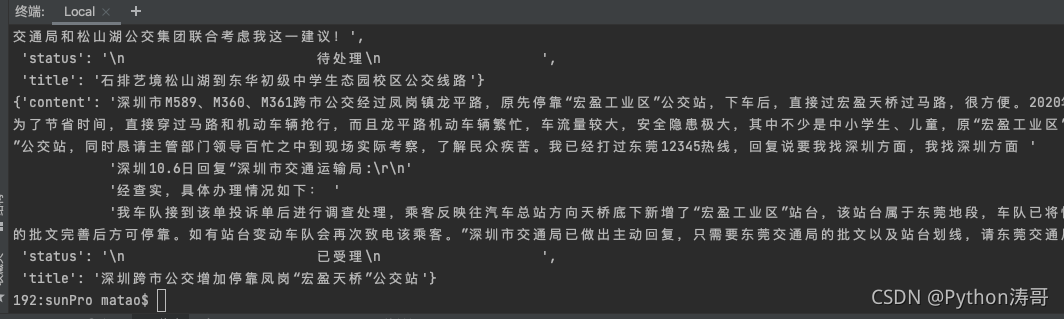
完整代码:
sum.py
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from sunPro.items import SunproItemclass SunSpider(CrawlSpider):name = 'sun'# allowed_domains = ['www.xxx.com']start_urls = ['https://wz.sun0769.com/political/index/politicsNewest?id=1&type=4&page=']# 提取页码链接link = LinkExtractor(allow=r'id=1&page=\d+')rules = (Rule(link, callback='parse_item', follow=False),)# 页面数据解析def parse_item(self, response):li_list = response.xpath('/html/body/div[2]/div[3]/ul[2]/li')for li in li_list:title = li.xpath('./span[3]/a/text()').extract_first()detail_url = 'https://wz.sun0769.com' + li.xpath('./span[3]/a/@href').extract_first()status = li.xpath('./span[2]/text()').extract_first()# 保存item提交给管道item = SunproItem()item['title'] = titleitem['status'] = statusyield scrapy.Request(url=detail_url, callback=self.parse_detail, meta={'item': item})# 详情页数据解析def parse_detail(self, response):content = response.xpath('/html/body/div[3]/div[2]/div[2]/div[2]/pre/text()').extract_first()item = response.meta['item']item['content'] = contentyield item
items.py
import scrapyclass SunproItem(scrapy.Item):# define the fields for your item here like:# name = scrapy.Field()title = scrapy.Field()status = scrapy.Field()content = scrapy.Field()
Pipeline.py
class SunproPipeline:def process_item(self, item, spider):print(item)return item
settings.py
略~请自己学会熟练配置!
总结
CrawlSpider实现的深度爬取
- 通用方式:
CrawlSpider+Spider实现
关注Python涛哥!学习更多Python知识!
这篇关于Python爬虫从入门到精通:(36)CrawlSpider实现深度爬取_Python涛哥的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






