crawlspider专题

scrapy自动多网页爬取CrawlSpider类(五)
一.目的。 自动多网页爬取,这里引出CrawlSpider类,使用更简单方式实现自动爬取。 二.热身。 1.CrawlSpider (1)概念与作用: 它是Spider的派生类,首先在说下Spider,它是所有爬虫的基类,对于它的设计原则是只爬取start_url列表中的网页,而从爬取的网页中获取link并继续爬取的工作CrawlSpider类更适合。

scrapy--子类CrawlSpider中间件
免责声明:本文仅做分享参考~ 目录 CrawlSpider 介绍 xj.py 中间件 部分middlewares.py wyxw.py 完整的middlewares.py CrawlSpider 介绍 CrawlSpider类:定义了一些规则来做数据爬取,从爬取的网页中获取链接并进行继续爬取. 创建方式:scrapy genspider -t crawl
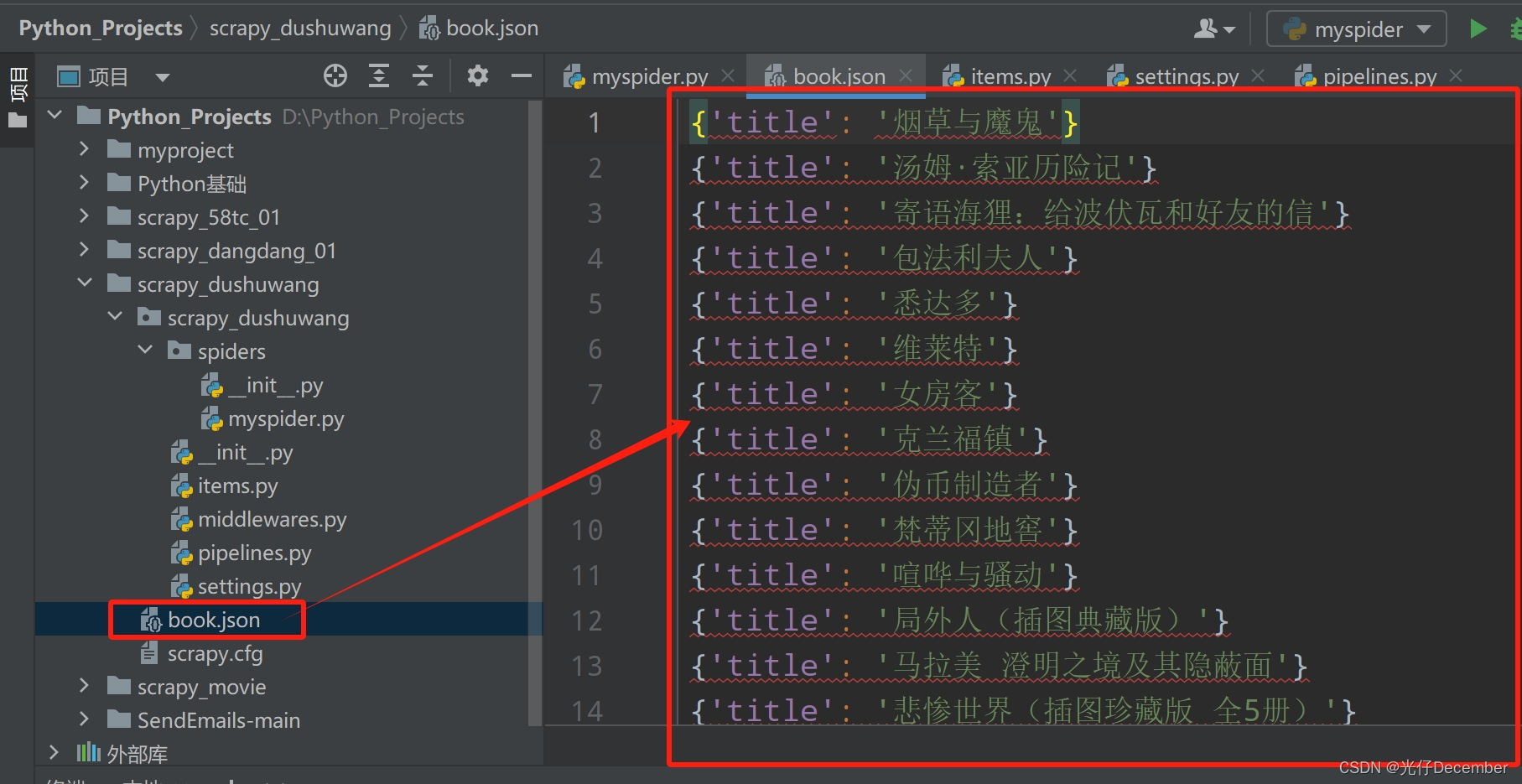
【Python从入门到进阶】52、CrawlSpider链接提取器的使用
接上篇《51、电影天堂网站多页面下载实战》 上一篇我们采用Scrapy框架多页面下载的模式来实现电影天堂网站的电影标题及图片抓取。本篇我们来学习基于规则进行跟踪和自动爬取网页数据的“特殊爬虫”CrawlSpider。 一、什么是CrawlSpider? 1、CrawlSpider的概念 CrawlSpider是Scrapy框架中的一个特殊爬虫类型,它主要用于处理需要遵循特定规则和链接提取的
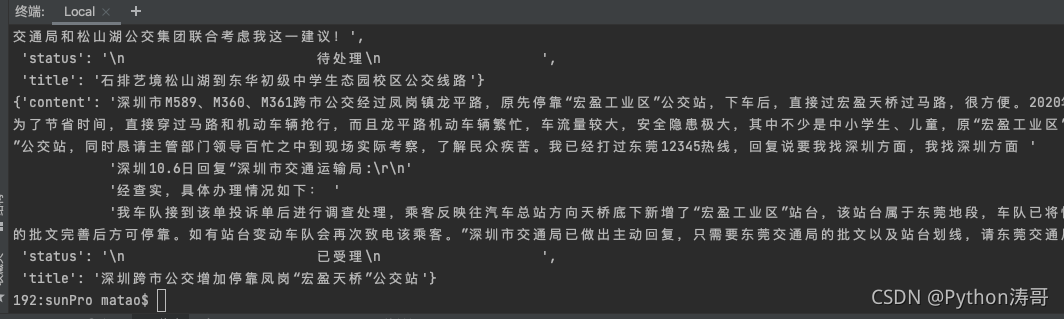
Python爬虫从入门到精通:(36)CrawlSpider实现深度爬取_Python涛哥
我们来看下CrawlSpider实现深度爬取。 爬取阳光热线标题、状态、和详情页内容。 https://wz.sun0769.com/political/index/politicsNewest?id=1&type=4&page= 创建CrawlSpider工程 scrapy startproject sunPro cd sunPro scrapy genspider -t cr

scrapy使用CrawlSpider方式爬取百度贴吧帖子跟图片
今天用CrawlSpider方式爬取百度贴吧,不得不说,这种方法太牛逼了,只用了不到二十行的代码 创建项目 scrapy startproject 项目名进入项目然后生成爬虫 scrapy genspider -t crawl 爬虫 爬取范围 主要代码 # -*- coding: utf-8 -*-import scrapyfrom scrapy.linkextractors impor

通过CrawlSpider爬取网易社会招聘信息
通过CrawlSpider爬取网易社会招聘信息 1.创建工程 scrapy startproject 项目名称 2.创建crawlspider爬虫 scrapy genspider -t crawl 爬虫名 爬虫的范围.com 3.爬虫代码如下 # -*- coding: utf-8 -*-from scrapy.linkextractors import LinkExtracto
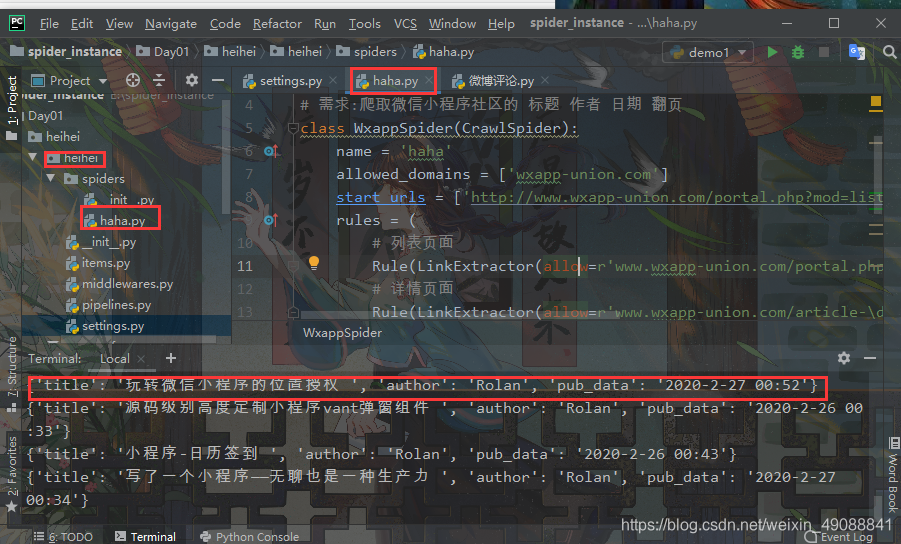
python爬虫十四:scrapy crawlspider的介绍及使用
1、scrapy crawlspider的介绍 他有着自动提取规则,内部封装的只要我们爬取的数据有规律并且在网页源码中,就可以实现他的自动抓取,我们不用管具体交给它做,下面会有案例展示 之前的代码中,我们有很大一部分时间在寻找下一页的URL地址或者内容的URL地址上面,这个过程能更简单一些吗? 思路: 1.从response中提取所有的li标签对应的URL地址 2.自动的构造自己resquest

Scrapy-CrawlSpider-MySQL-猎云网
scrapy爬取猎云网数据保存至mysql笔记 CrawlSpider爬虫:1.创建好相应的文档,文件2.对搭好的框架进行一个简单修改3.分析需求4.爬虫文件5.异步保存至mysql CrawlSpider爬虫: 作用:可以定义规则,让Scrapy自动的去爬取我们想要的链接。而不必跟Spider类一样,手动的yield Request。创建:scrapy genspider -t
Scrapy框架之Crawlspider爬取刺猬实习职位信息
点击查看要爬取的网页 目标:利用Crawspider的特性在首页找到所有的职位分类的url,进入分页,再从分页进入详细页面获取所有的信息。 首先打开cmd或者powershell scrapy startproject ciweishixi cd ciweishixi scrapy genspider -t crawl Crawlspider ciweishixi.com

使用CrawlSpider爬取全站数据。
CrawpSpider和Spider的区别 CrawlSpider使用基于规则的方式来定义如何跟踪链接和提取数据。它支持定义规则来自动跟踪链接,并可以根据链接的特征来确定如何爬取和提取数据。CrawlSpider可以对多个页面进行同样的操作,所以可以爬取全站的数据。CrawlSpider可以使用LinkExtractor用正则表达式自动提取链接,而不需要手动编写链接提取代码。 Spider和Cr