本文主要是介绍Scrapy框架之Crawlspider爬取刺猬实习职位信息,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
点击查看要爬取的网页
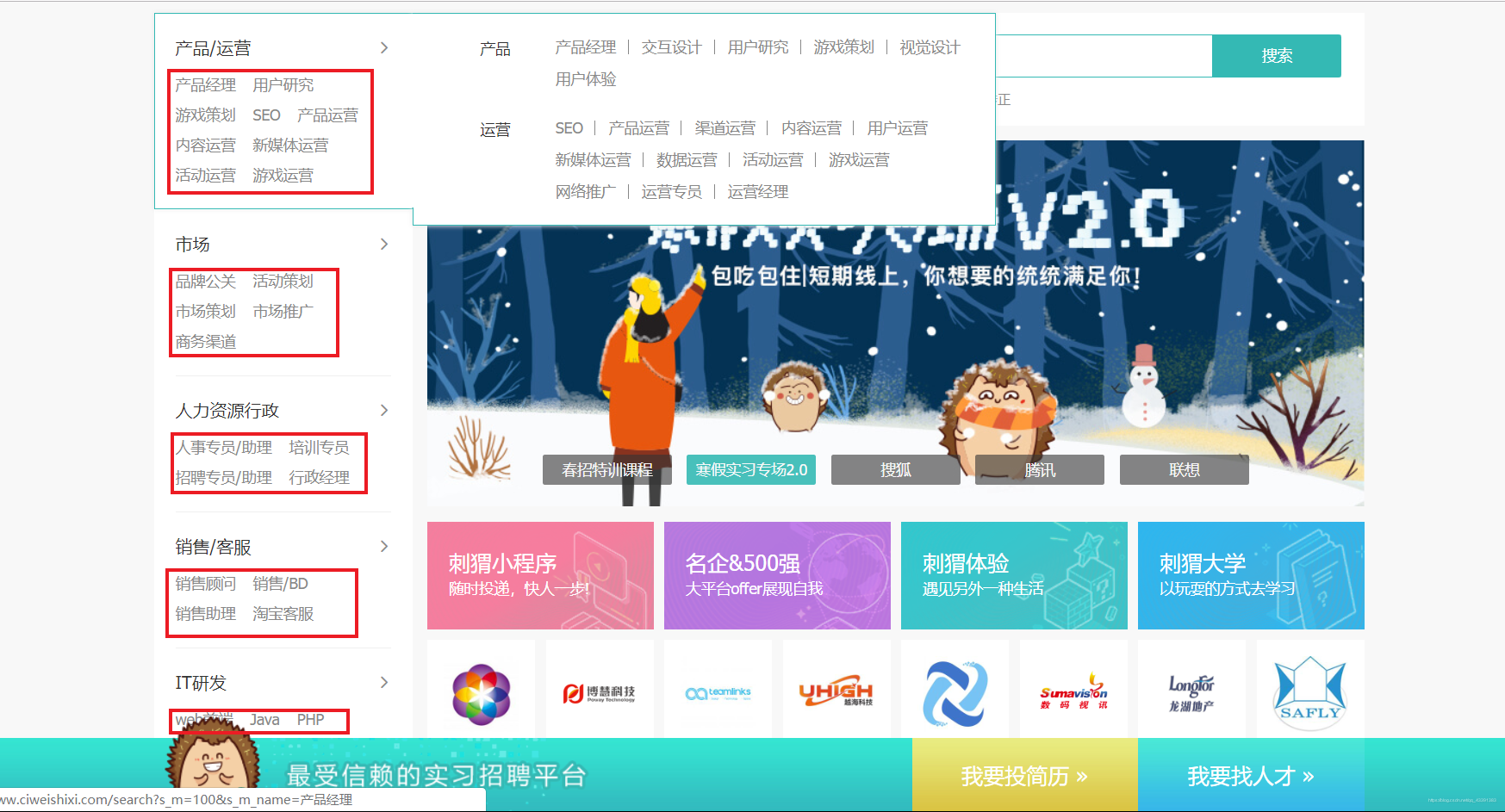
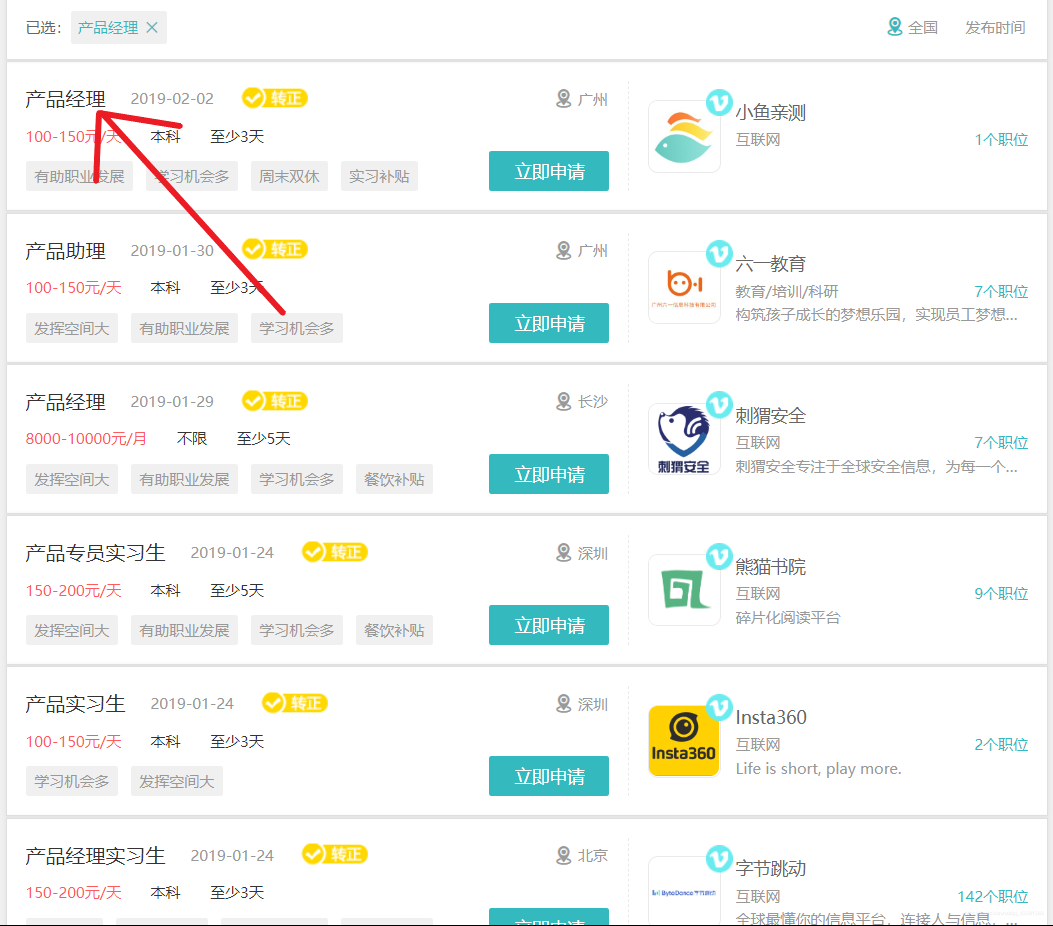
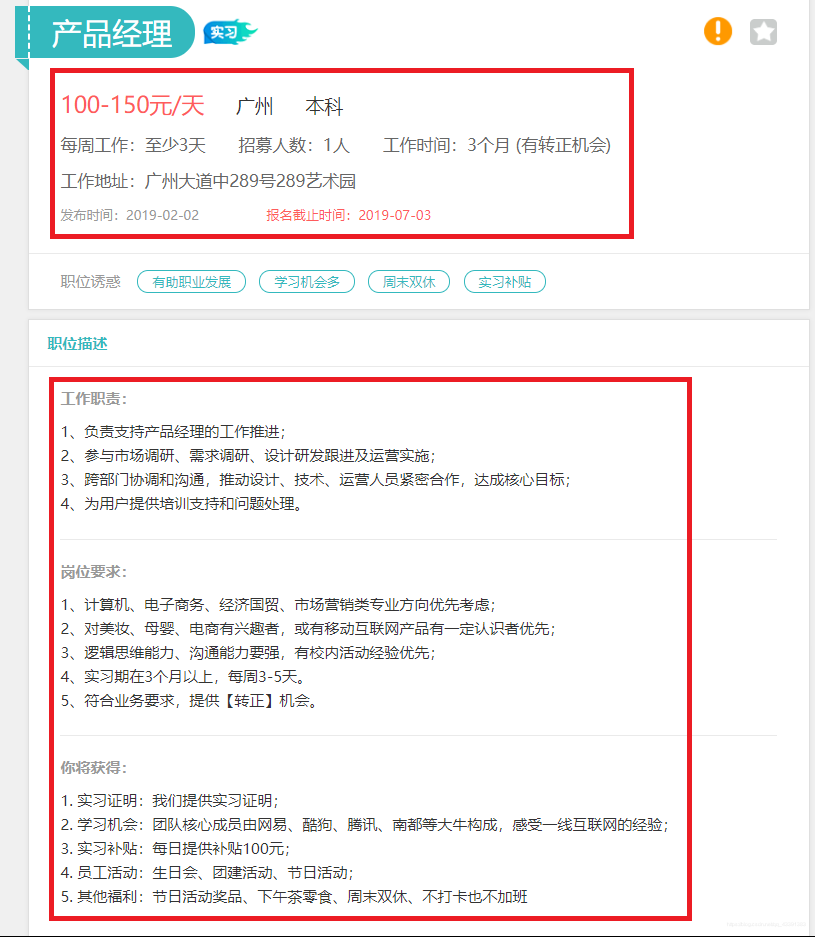
目标:利用Crawspider的特性在首页找到所有的职位分类的url,进入分页,再从分页进入详细页面获取所有的信息。
首先打开cmd或者powershell
scrapy startproject ciweishixi
cd ciweishixi
scrapy genspider -t crawl Crawlspider ciweishixi.com
生成一只继承了Crawlspider的爬虫
然后开始做填空题···
Crawlspider.py
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from scrapy.selector import Selectorclass CrawlspiderSpider(CrawlSpider):name = 'Crawlspider'allowed_domains = ['ciweishixi.com']start_urls = ['https://www.ciweishixi.com']#如果要LinkExtractor里用xpath的方法,restrict_xpaths到属性所在的标签即可,不要/@href了rules = (Rule(LinkExtractor(restrict_xpaths = '//div[@class="menu"]//a',unique=True), callback='parse_entrance_url', follow=False),)# allow='https://www.ciweishixi.com/search?s_m=\d+?&s_m_name=[\u4e00-\u9fa5/]+?'def parse_entrance_url(self,response):item = {}selector = Selector(response)urls = selector.xpath('//div[@class="major"]/a/@href').extract()# 由于发现我下面提取的内容会缺少职位的名字,所以在这里分页面这补上# 利用了meta这个方法,它可以让你的信息传到下一个函数,再一次性处理数据names = selector.xpath('//div[@class="major"]/a[1]/text()').extract()for url,name in zip(urls,names):item['name'] = namerequest = scrapy.Request(url,callback=self.parse_item)request.meta['item'] = itemyield requestdef parse_item(self, response):selector = Selector(response)item = response.meta['item']contents = selector.xpath('//div[@class="widget"]')x = 0for content in contents:# 由于我要用xpath('string(.)')的方法提取所有文本信息# 而所有有用的信息只在每个循环节点的前两个,所以循环两次就ok了x += 1if x > 2:breakcontent_list = content.xpath('string(.)').extract()mylist = list()for i in content_list:j = i.strip(' ')# 这里是及其恶心的地方,不知为啥就是有一种像空格的东西一直站位if j != '立即申请' or '收藏成功,查看收藏':mylist.append(j)real_content = '\n'.join(mylist)item['content'] = item['name'] + '\n' + real_contentprint(real_content)yield item要注意的是Rule里面的xpath只用提取到href的标签名就可以了,不用到属性
这里利用meta方法可以将前一次网页解析的信息往后传,等到下一个函数要yield item的时候再一次性写入数据。
piplins.py
class CiweishixiPipeline(object):def __init__(self):self.file = open('D://ciweishixi.txt','a+',encoding='utf-8')def process_item(self, item, spider):self.file.write(item['content'].strip())return itemdef closefile(self):self.file.close()settings.py
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.162 Safari/537.36'
LOG_LEVEL = 'WARNING'
ITEM_PIPELINES = {'ciweishixi.pipelines.CiweishixiPipeline': 300,
}爬完,信息要提取的是提取到了,但是格式很恶心,我在strip()里把所有转义字符都试过,依然消除不掉这种恶心的空格???如果你知道希望你可以告诉我…谢谢~~
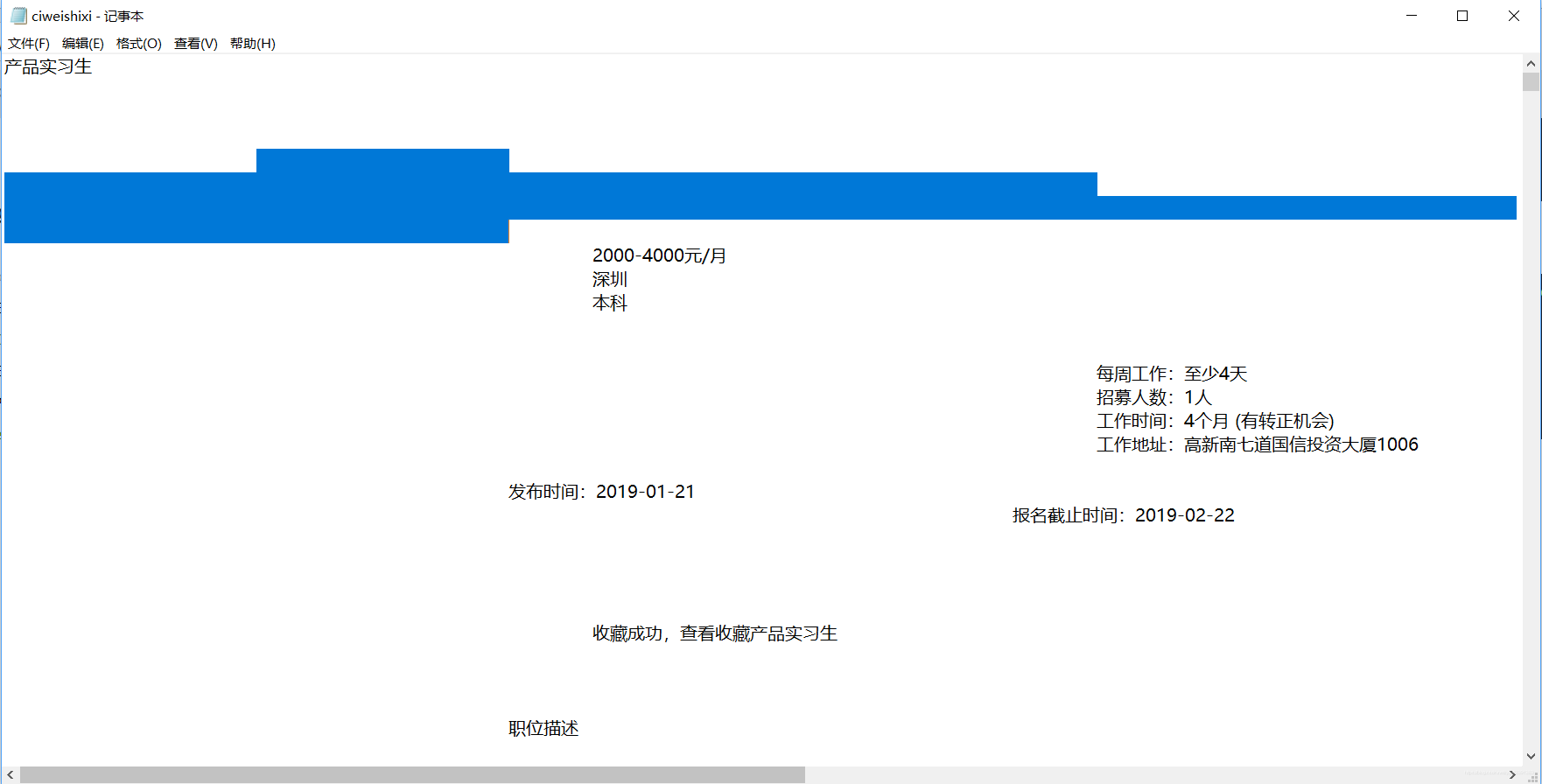
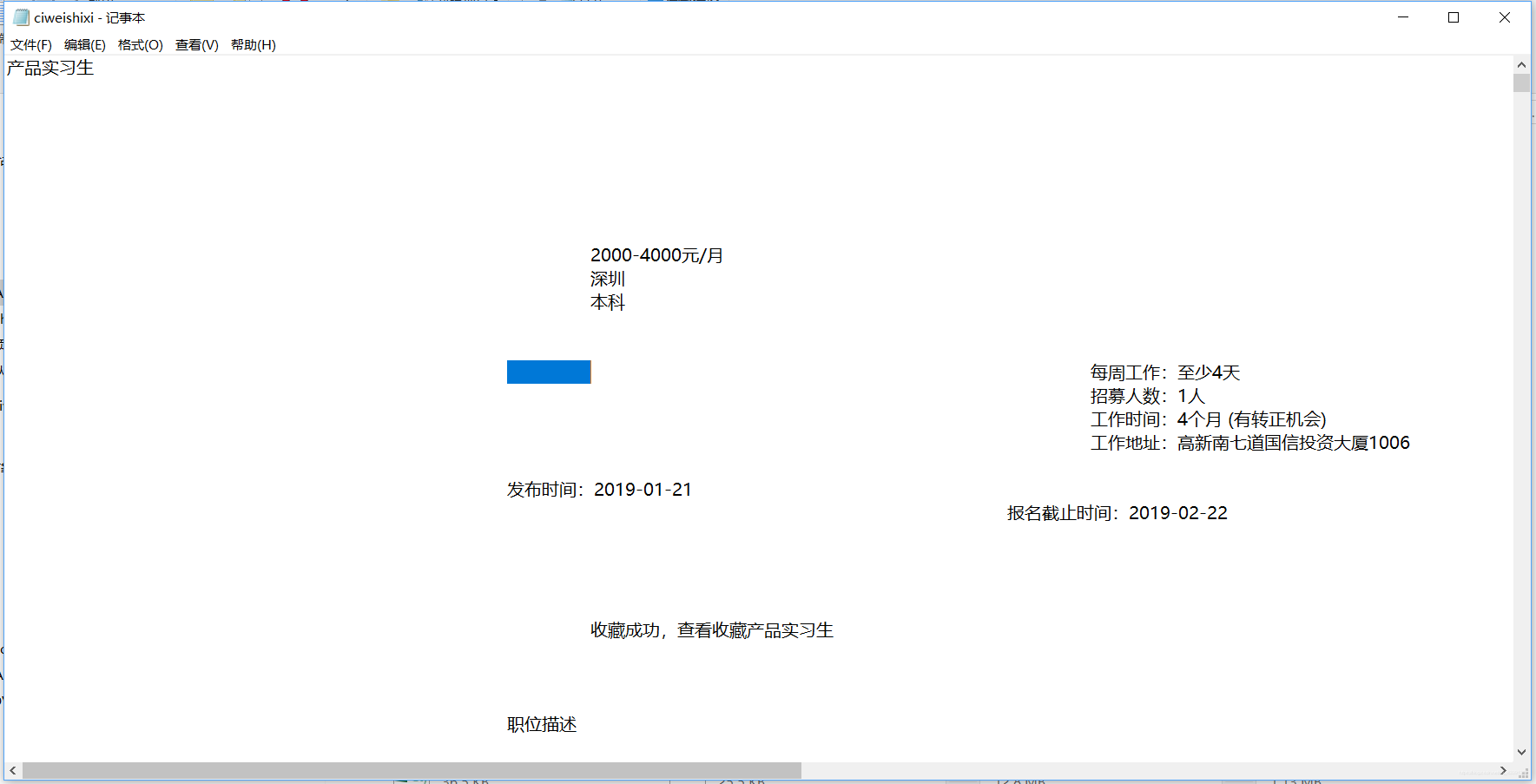
它是只有一个格的,但是又很长。。到底是什么符号\TAT/
续上:
后面改了一下,感觉好了一丢丢
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from scrapy.selector import Selectorclass CrawlspiderSpider(CrawlSpider):name = 'Crawlspider'allowed_domains = ['ciweishixi.com']start_urls = ['https://www.ciweishixi.com']rules = (Rule(LinkExtractor(restrict_xpaths = '//div[@class="menu"]//a',unique=True), callback='parse_entrance_url', follow=False),)# allow='https://www.ciweishixi.com/search?s_m=\d+?&s_m_name=[\u4e00-\u9fa5/]+?'def parse_entrance_url(self,response):item = {}selector = Selector(response)urls = selector.xpath('//div[@class="major"]/a/@href').extract()names = selector.xpath('//div[@class="major"]/a[1]/text()').extract()for url,name in zip(urls,names):item['name'] = namerequest = scrapy.Request(url,callback=self.parse_item)request.meta['item'] = itemyield requestdef parse_item(self, response):selector = Selector(response)item = response.meta['item']contents = selector.xpath('//div[@class="widget"]')x = 0for content in contents:x += 1if x > 2:break# content_list = content.xpath('.//string(.)').extract()content_list = content.re('[\u4e00-\u9fa5:,、;:A-Z0-9]+')mylist = list()stoplist = ['立即申请','收藏职位','收藏成功','A','F','举报','查看收藏',':',',',',','1','2','3','4','5','6','7','8','9','0']for i in content_list:j = i.strip()if j not in stoplist:mylist.append(j)real_content = '\n'.join(mylist)item['content'] = item['name'] + '\n' + real_contentprint(real_content)yield item这篇关于Scrapy框架之Crawlspider爬取刺猬实习职位信息的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





