本文主要是介绍资源隔离调度算法测试(isolated_scheduler)及openstack集群开发环境搭建,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
感谢朋友支持本博客,欢迎共同探讨交流,由于能力和时间有限,错误之处在所难免,欢迎指正!
如有转载,请保留源作者博客信息。
如需交流,欢迎大家博客留言。
1、环境:
| centos6.5 openstack icehouse |
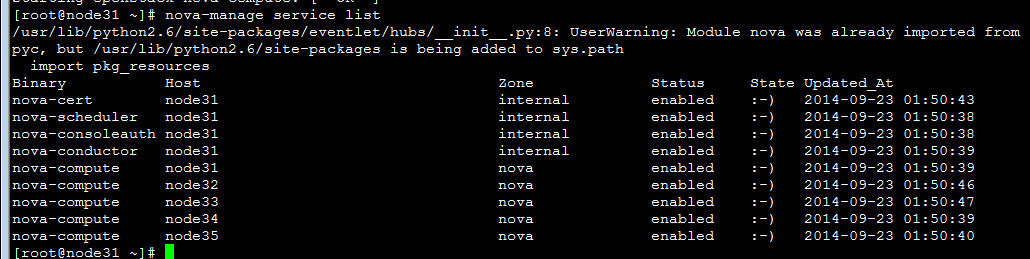
2、集群
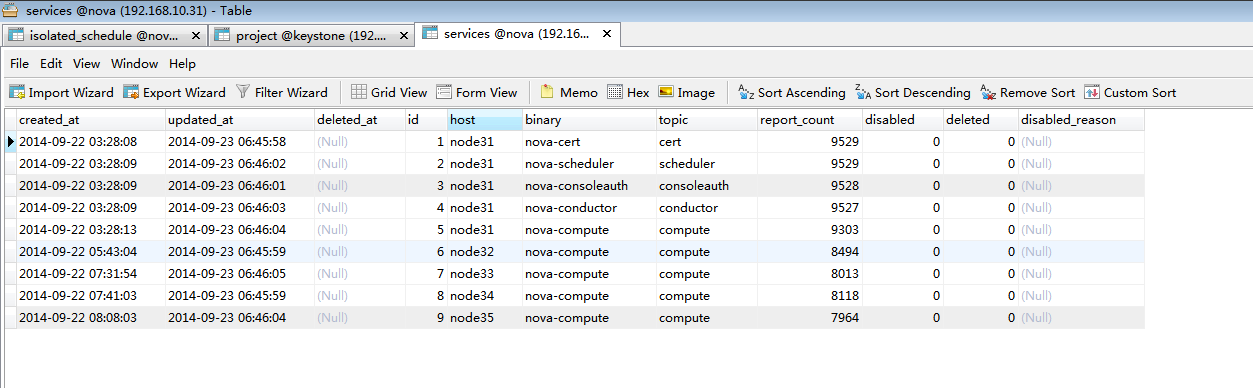
| nova-manage service list  |
3、测试虚拟机生成:
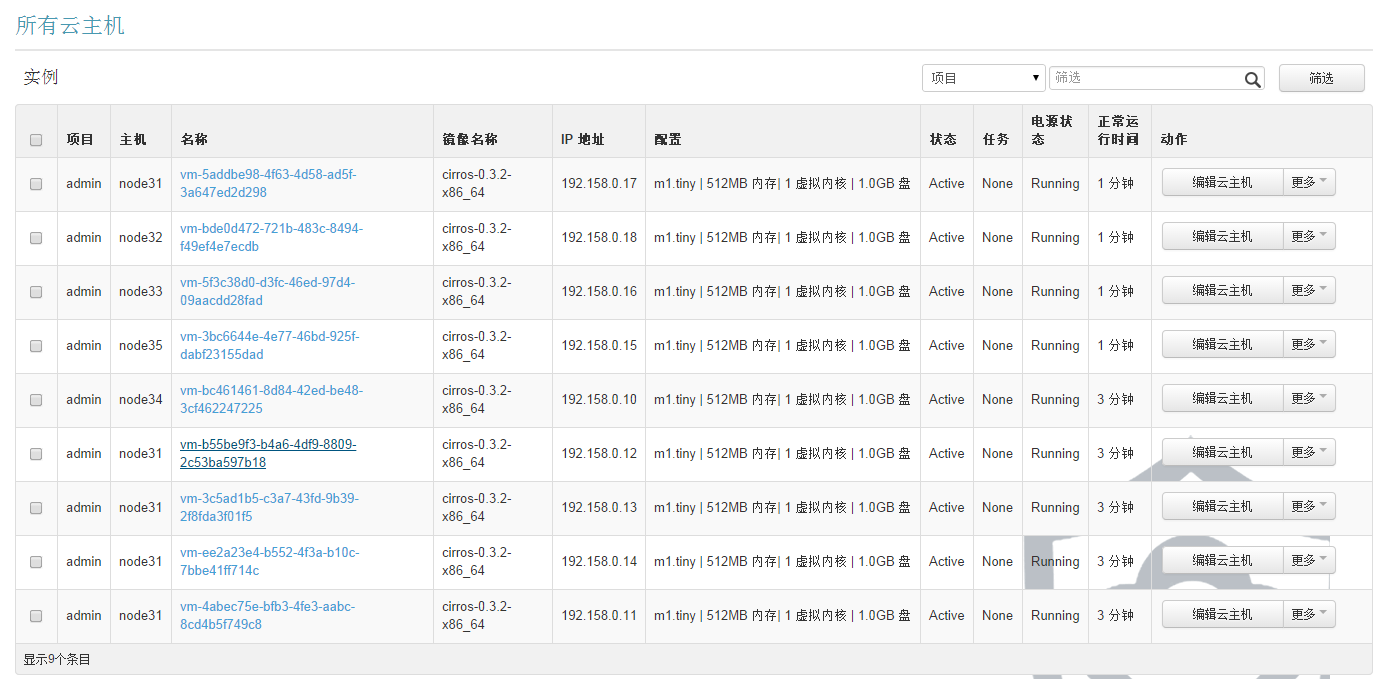
一切正常。(原生默认的虚拟机调度策略为:生成到逻辑剩余内存最大的计算节点。)
4、安装samba环境,请参考相应博文。


将源码重定向到samba文件中(ln -s)
5、windows中共享samba中的代码
6、访问页面:
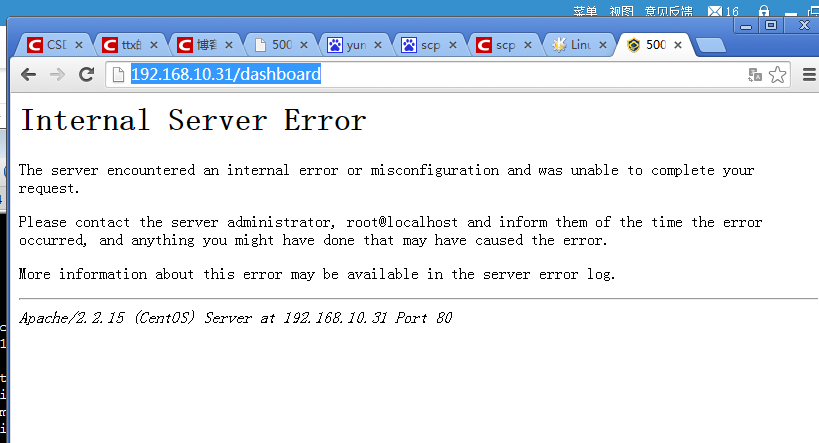
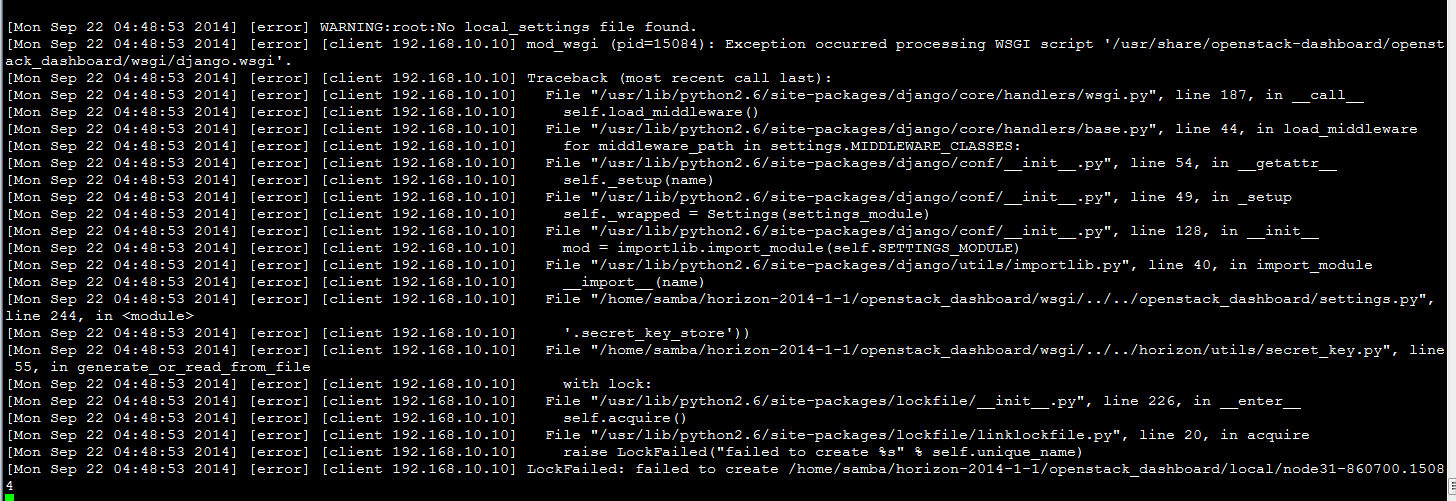

解决,出现下面错误:
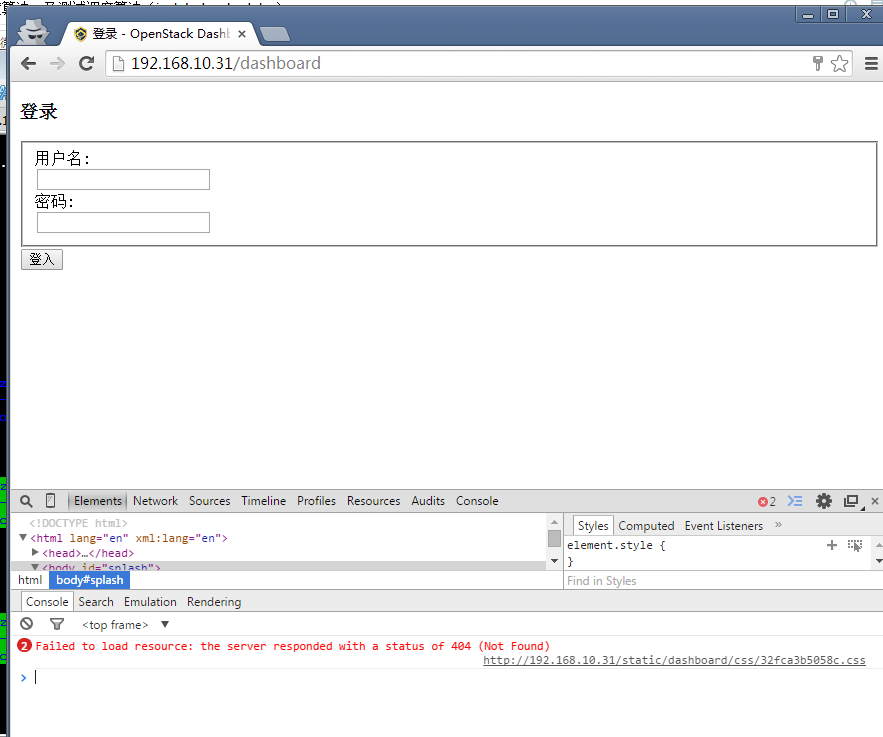

开发环境搭建完成:
7、无密码scp、rsync:
在主节点node31:
ssh-keygen -t rsa
scp .ssh/id_rsa.pub root@192.168.10.31:/root/.ssh/authorized_keys(分别复制到node32/33/34/35节点)
8、安装同步工具:(同步的所有节点都需要安装)比scp效率高
yum install rsync -y
rsync -avzP /home/samba/nova-2014-1-1/nova/ root@192.168.10.32 :/usr/lib/python2.6/site-packages/nova/
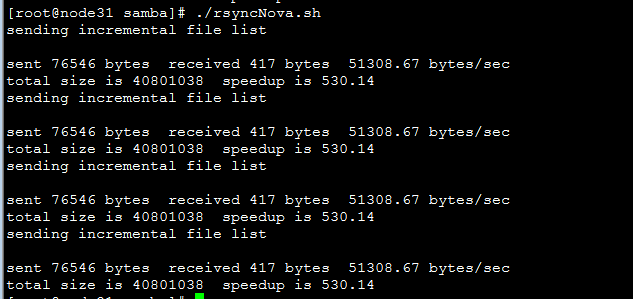
第一次同步时间比较长,后续则是差分同步
node31同步脚本:
| vi rsyncNova.sh rsync -avzP --exclude ".pyc" /home/samba/nova-2014-1-1/nova/ root@192.168.10.32:/usr/lib/python2.6/site-packages/nova/ rsync -avzP --exclude ".pyc" /home/samba/nova-2014-1-1/nova/ root@192.168.10.33:/usr/lib/python2.6/site-packages/nova/ rsync -avzP --exclude ".pyc" /home/samba/nova-2014-1-1/nova/ root@192.168.10.34:/usr/lib/python2.6/site-packages/nova/ rsync -avzP --exclude ".pyc" /home/samba/nova-2014-1-1/nova/ root@192.168.10.35:/usr/lib/python2.6/site-packages/nova/ |

9、远程重启compute服务脚本:
ssh 192.168.10.32 "service openstack-nova-compute restart"
编写脚本:
| vi allcompute-restart.sh service openstack-nova-compute restart ssh 192.168.10.32 "service openstack-nova-compute restart" ssh 192.168.10.33 "service openstack-nova-compute restart" ssh 192.168.10.34 "service openstack-nova-compute restart" ssh 192.168.10.35 "service openstack-nova-compute restart" |
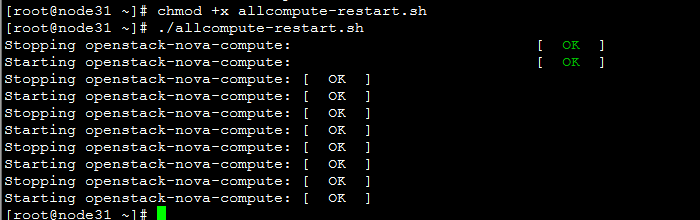
每次同步完代码,执行此脚本重启所有节点的compute服务,使代码生效。
10、接下来使用pycharm在windows上同步linux开发:
11、重启服务,访问页面
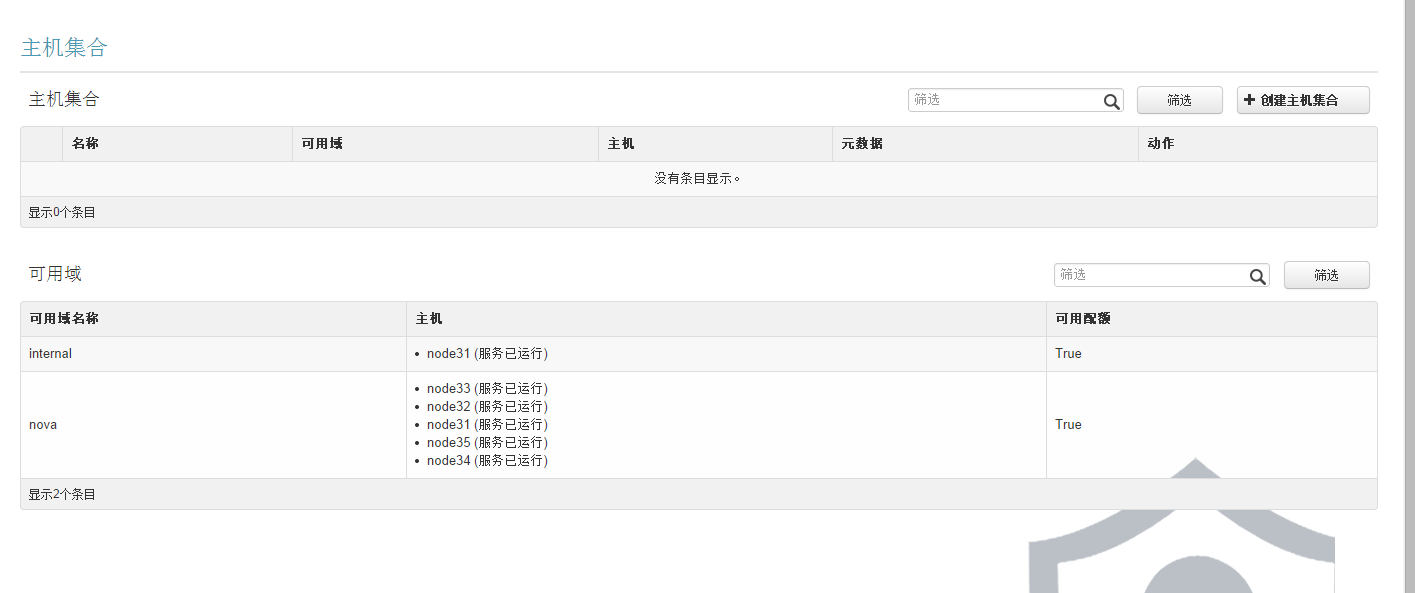
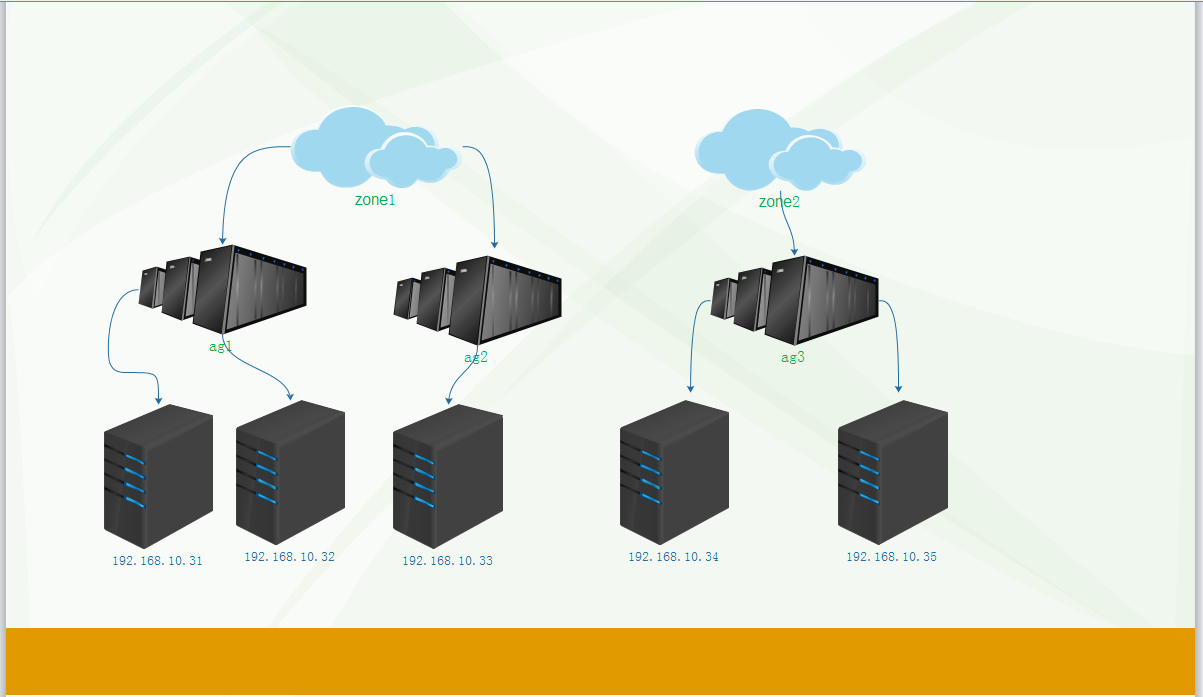
将计算节点分区域和主机集合:
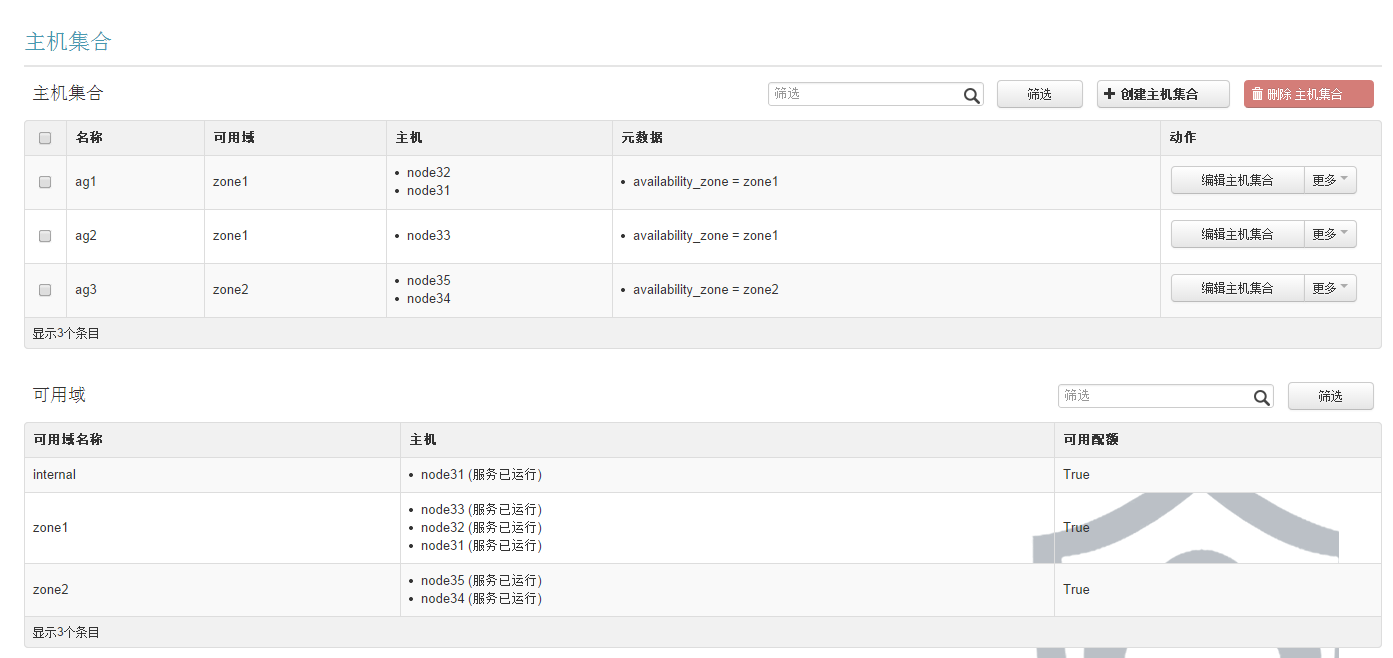
12、nova数据库中增加数据库计算资源隔离数据库表:(详情参考博文: http://blog.csdn.net/tantexian/article/details/39156803 )
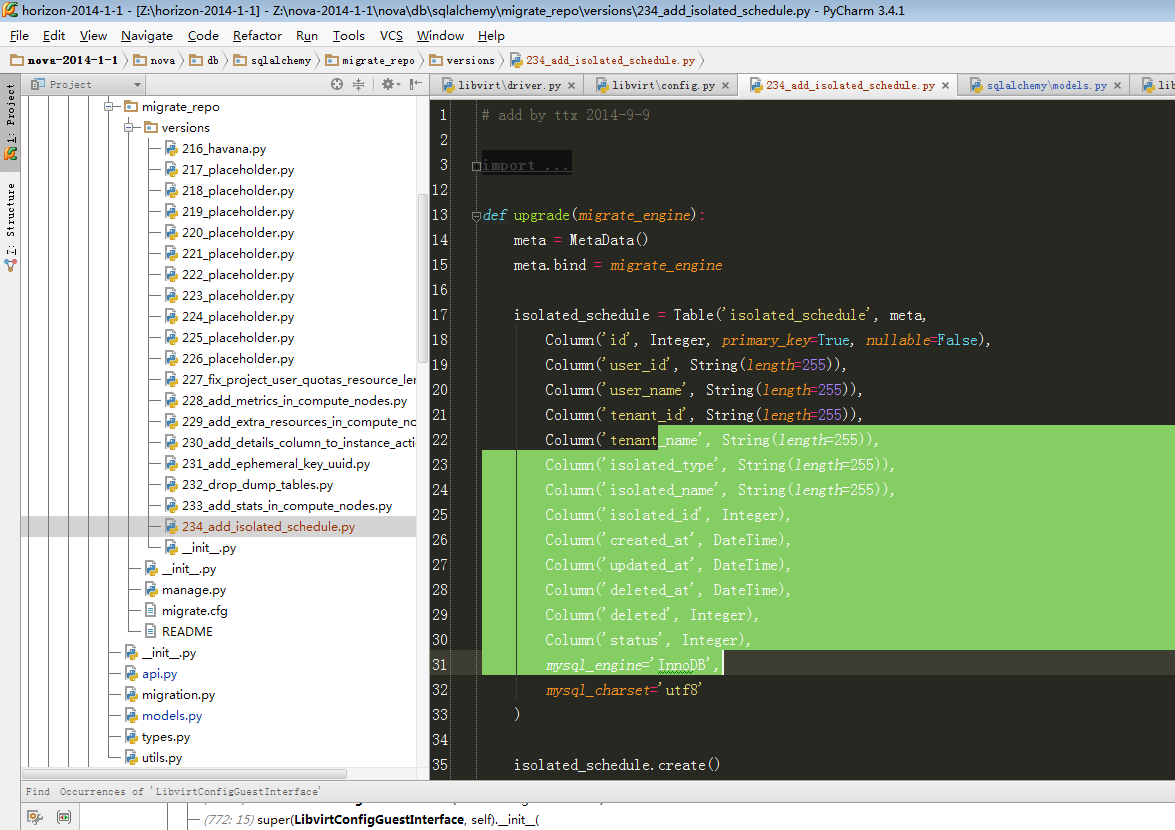

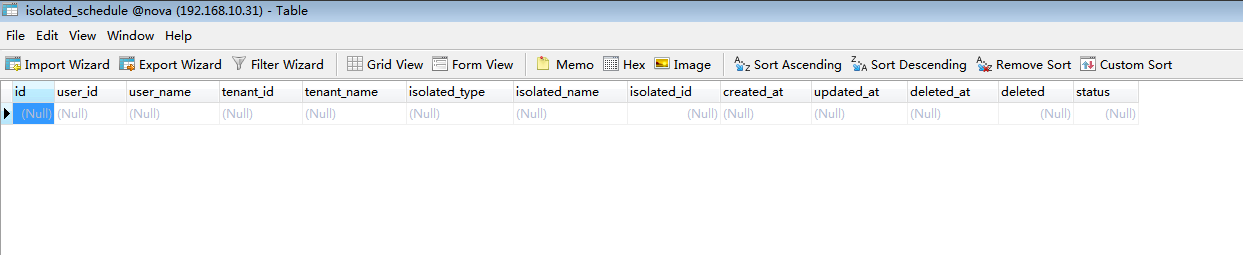
数据库字段注释:
| user_id:用于扩展、暂且保留 tenant_id #租户id,表示该租户只能使用某些zone、aggregate、host的计算节点生成虚拟机 isolated_type = Column(String(36))##0==host, 1 ==aggregate,2==zone isolated_name = Column(String(255))#zone or aggregate or host name isolated_id = Column(Integer)#zone or aggregate or service tables'id status = Column(Integer) #0 == down 1==active,用于扩展、暂且保留 |
13、验证增删字段到isolated_schedule数据库表中:
获取token值,加入到环境变量:
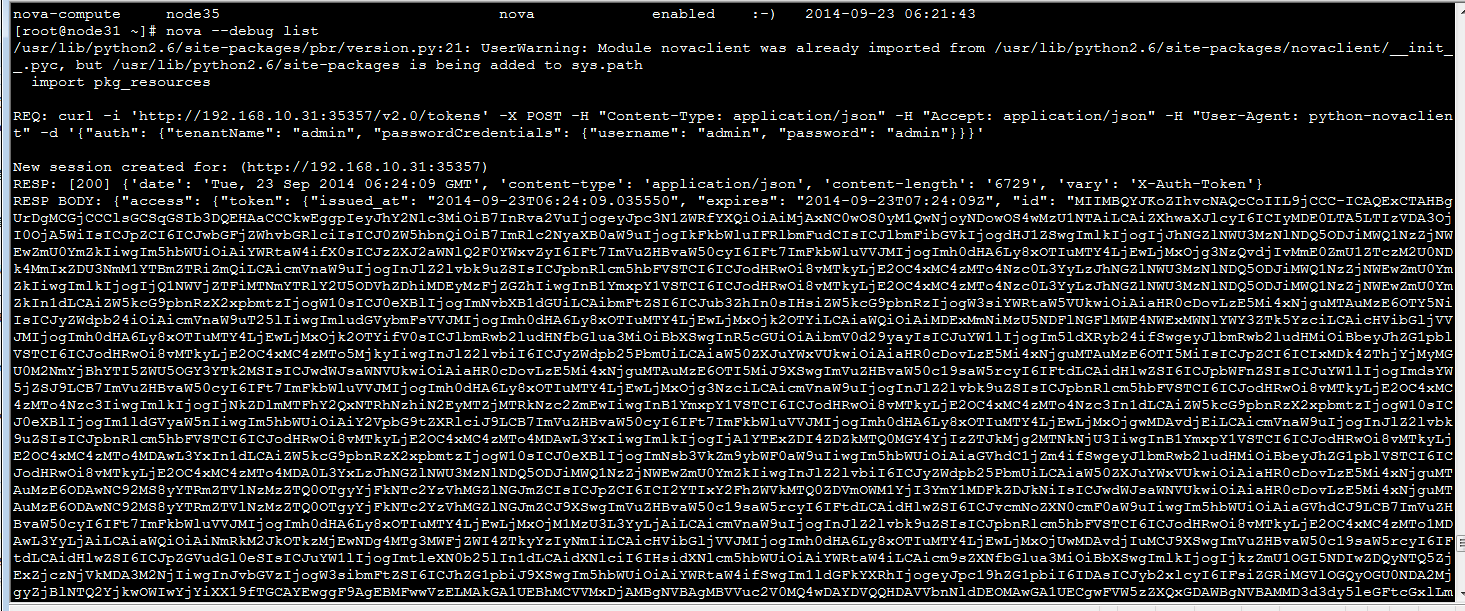
| vi .bashrc 添加内容:  环境变量生效: source .bashrc 验证TOKEN变量是否生效:  |
发布操作隔离资源的api:
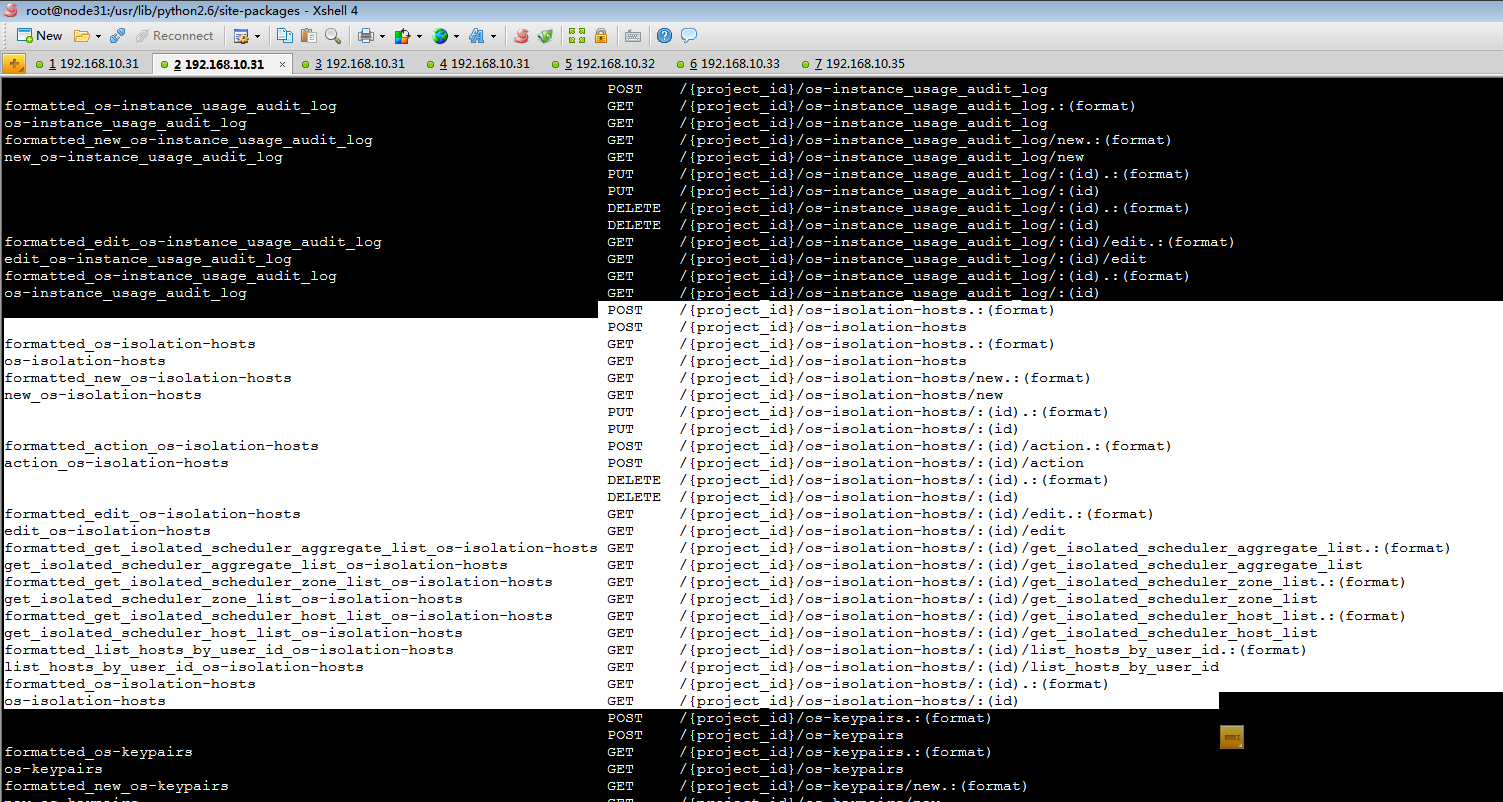
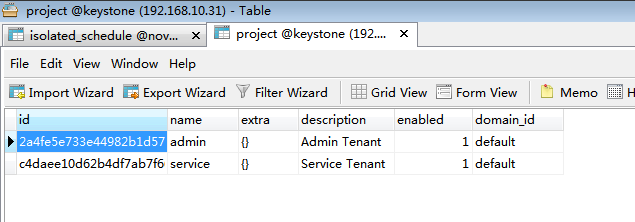
查看下keystone的租户信息表:
查看所有可用zone:
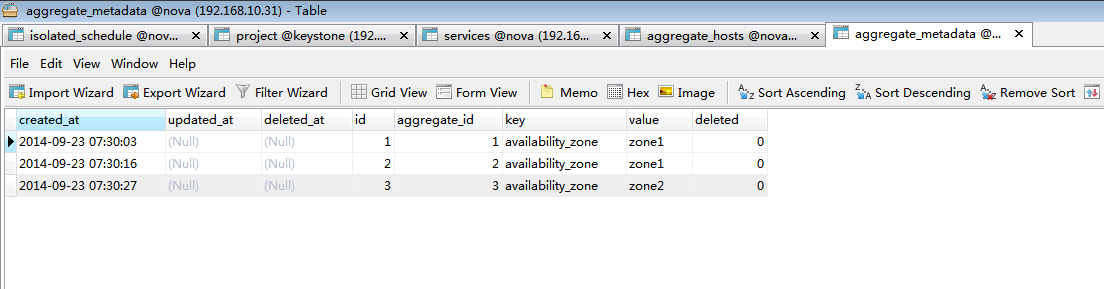
查看所有可用aggregate:
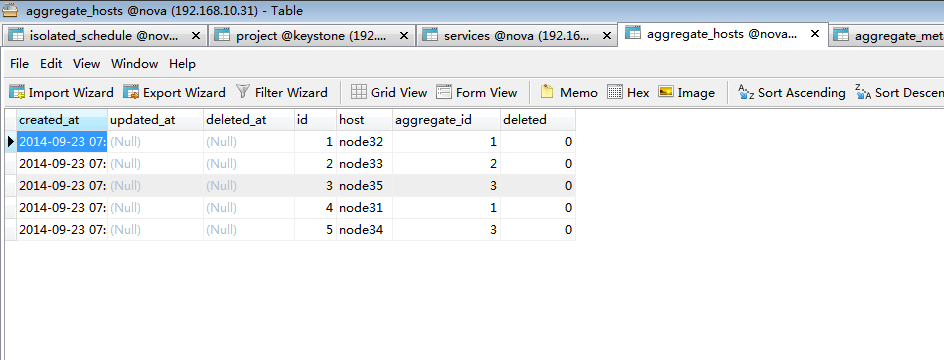
查看所有可用host:
| 添加一个host到数据库: (其中第一个值2a4fe5e733e44982b1d576c5a0fe4bfd为当前用户属于的tenant_id主要用来做权限认证, 第二个值2a4fe5e733e44982b1d576c5a0fe4bfd为所操作计算资源隔离的对象,本次环境为admin租户)
  api测试成功。 |
| 删除一个host从数据库:
|
| 添加一个aggregate从数据库:
|
| 删除一个aggregate从数据库:
|
| 添加一个zone从数据库:
|
| 删除一个zone从数据库:
|
根据tenant_id获取数据库表isolated_schedule host、aggregate、zone:
| 获取host从数据库:
 |
| 获取aggregate从数据库:
|
| 获取zone从数据库:
|
所有API测试通过
14、测试计算资源过滤调度算法:
scheduler.filter增加过滤算法:
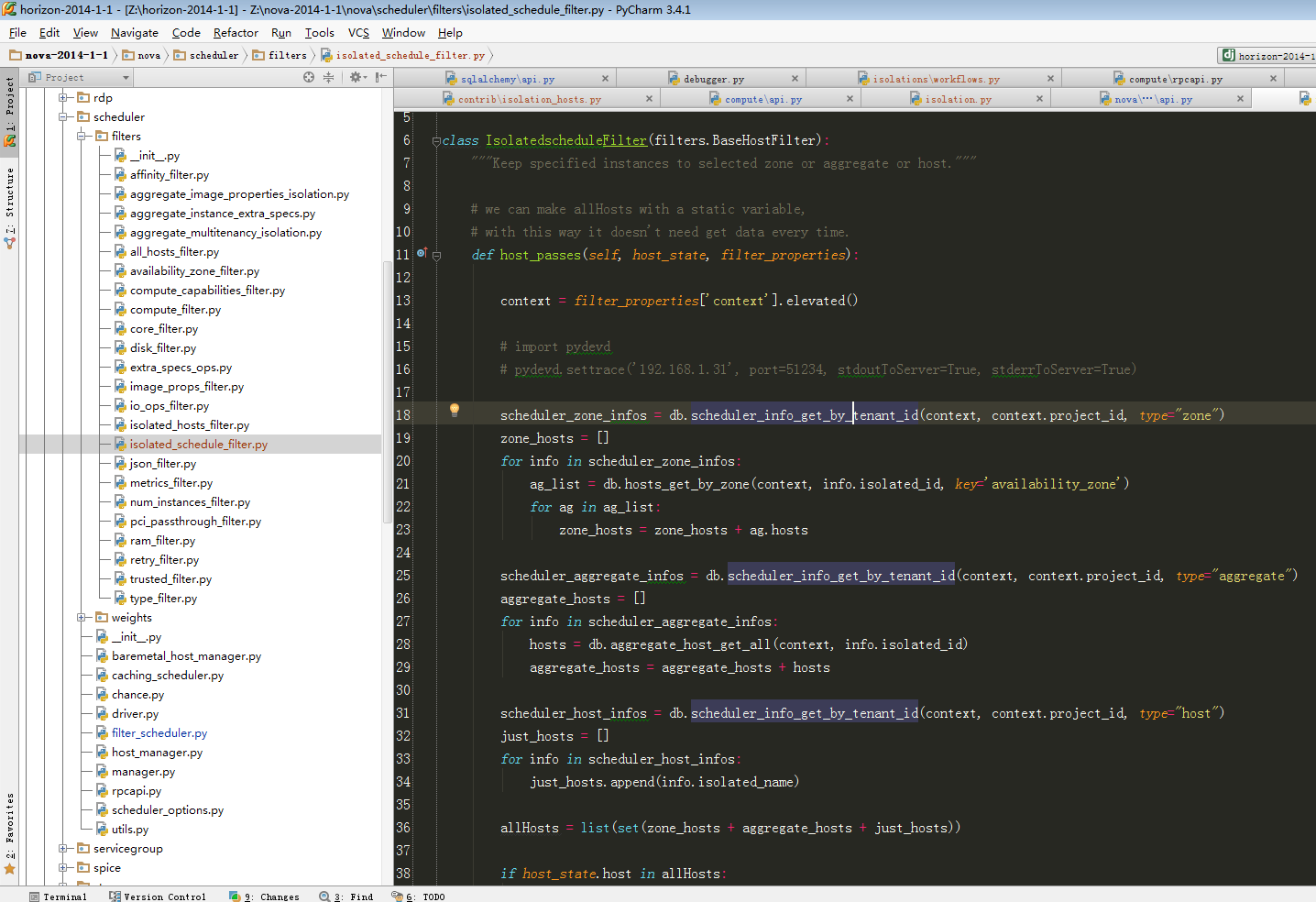
要使用该算法,则应该在/etc/nova.conf增加配置项:
scheduler_default_filters配置项修改为:
| scheduler_default_filters=IsolatedscheduleFilter,RetryFilter,AvailabilityZoneFilter,RamFilter,ComputeFilter,ComputeCapabilitiesFilter,ImagePropertiesFilter,ServerGroupAntiAffinityFilter,ServerGroupAffinityFilter |

重启服务生效。
调度算法具体分析,更多详情请参考博文:http://blog.csdn.net/tantexian/article/details/39156829
15、测试限制admin 租户只能将虚拟机生成到node31、node35上:
数据库增加两条记录:

开启远程debug,更多详情请参考之前博文。
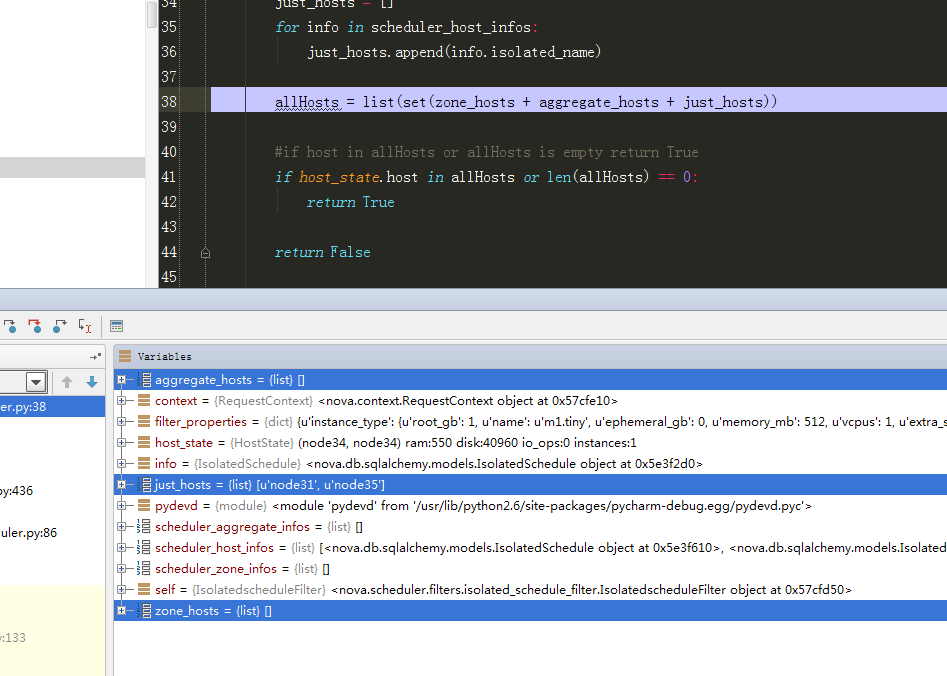
根据调试结果,与预期一致。(注,由于遵循opentack原生的调度过滤算法架构,此处有个明显的问题就是,每判断一次host都要走一次数据库,因此比较耗性能,后续考虑优化)
如果修改配置提示_member_不存在则修改:
vim /usr/share/openstack-dashboard/openstack_dashboard/local/local_settings.py
在页面生成虚拟机:
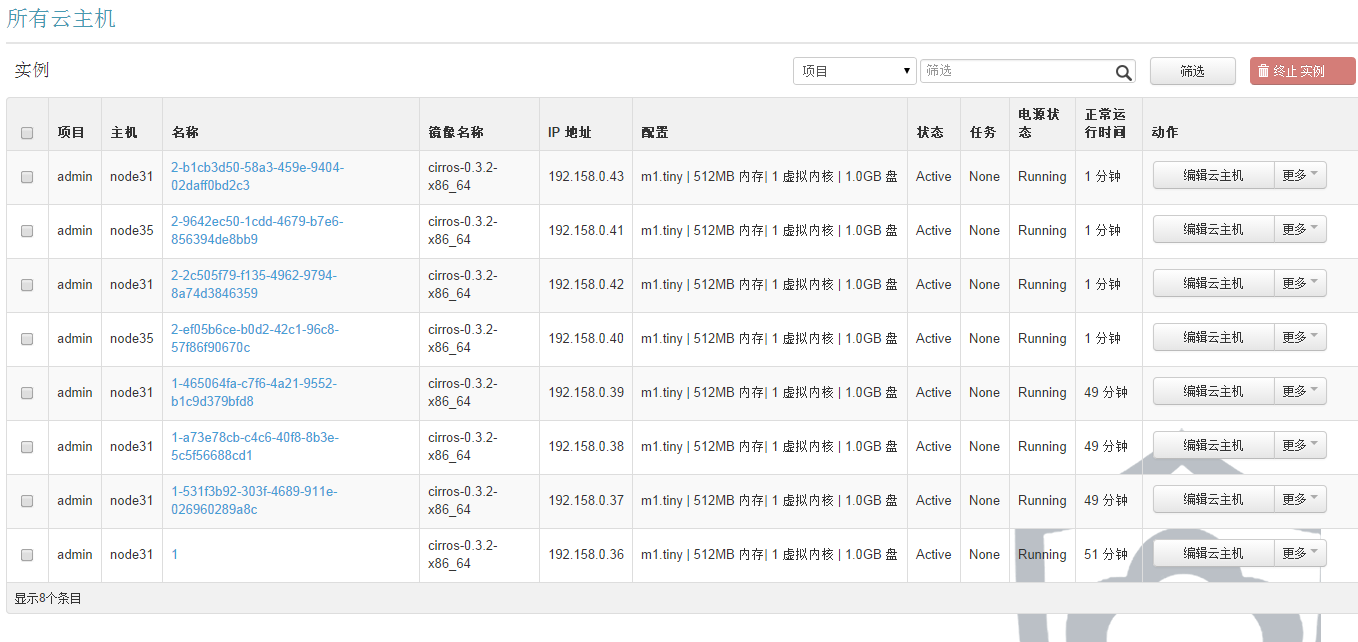
由上述结果可以知道,生成的8个虚拟机能够生成到指定的node31、node35上。
16、测试限制admin 租户只能将虚拟机生成到ag1和ag3上:
数据库信息:

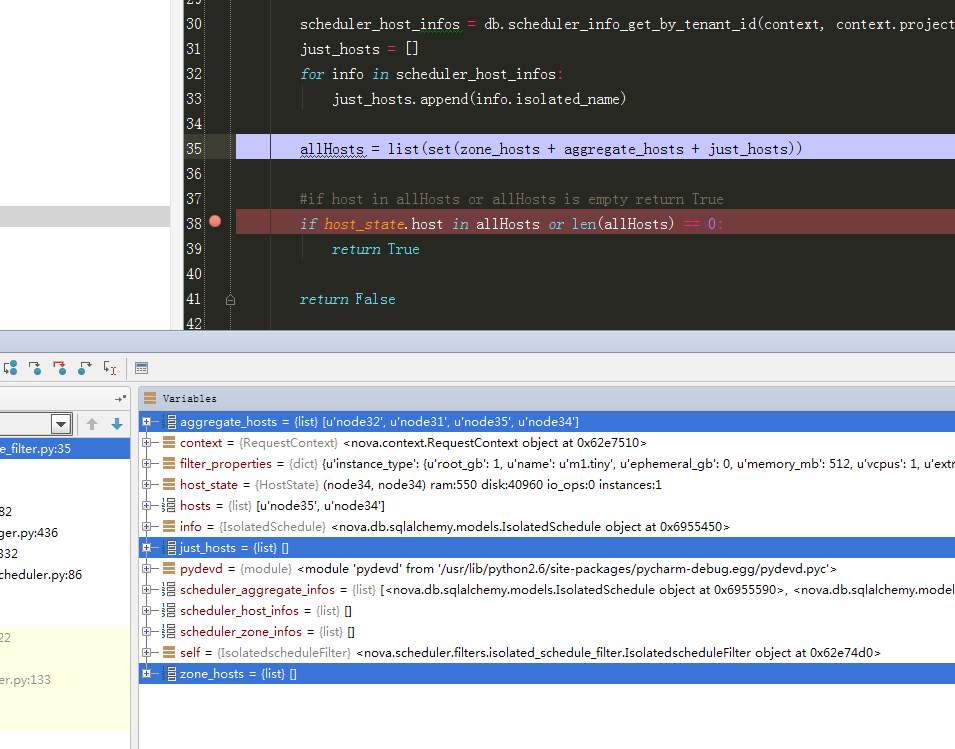
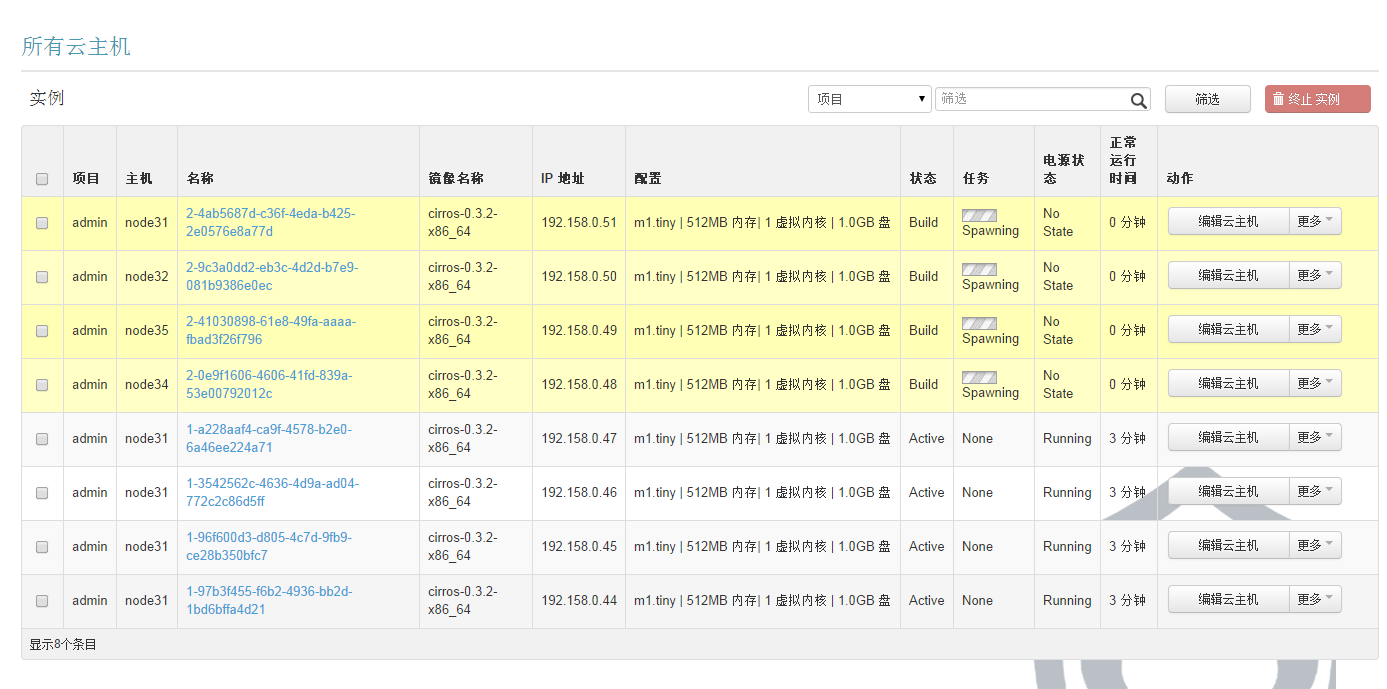
有上述结果可以知道,生成的8个虚拟机能够生成到指定的ag1、ag3上。
17、测试限制admin 租户只能将虚拟机生成到zone2上:
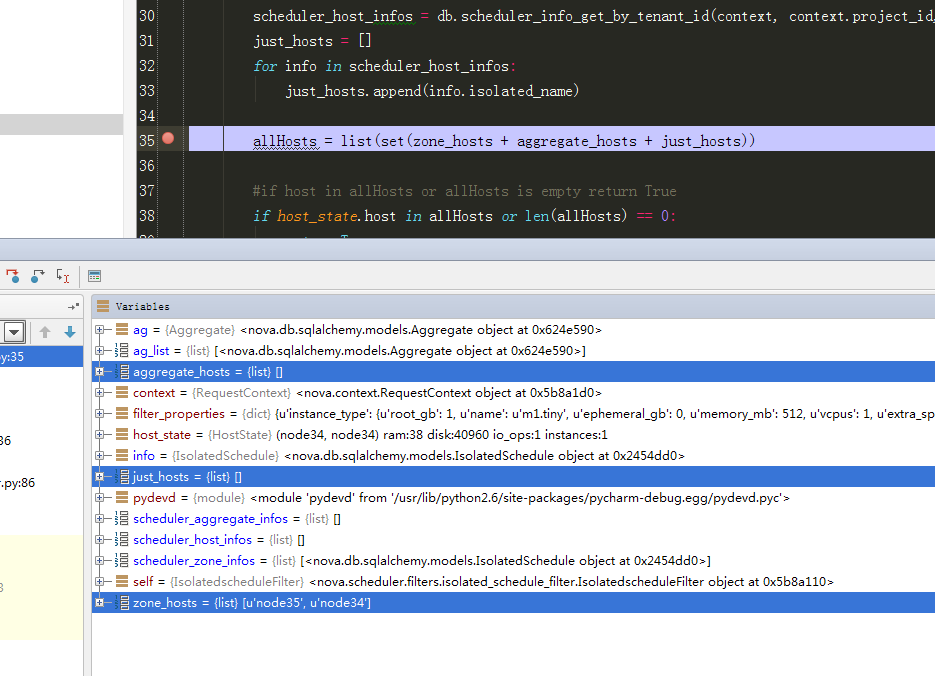
与预期一致:

有上述结果可以知道,生成的8个虚拟机能够生成到指定的zone2上。
18、测试限制admin 租户只能将虚拟机生成到ag2和node31及zone2上:
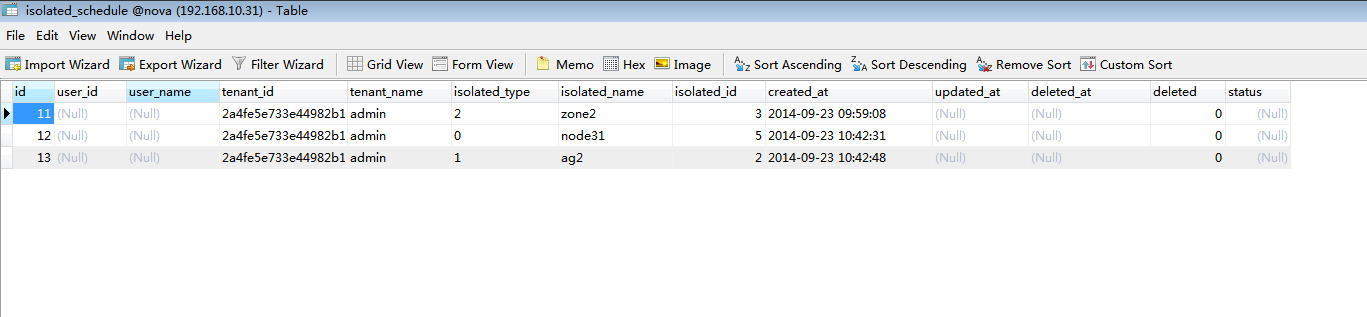
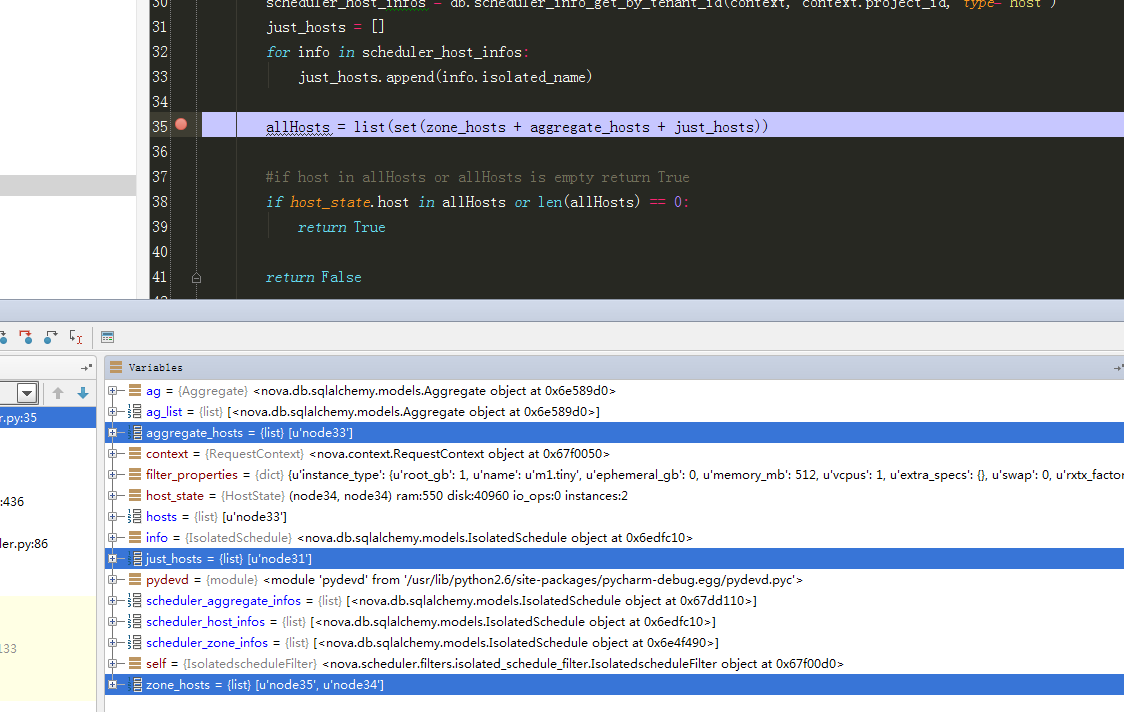
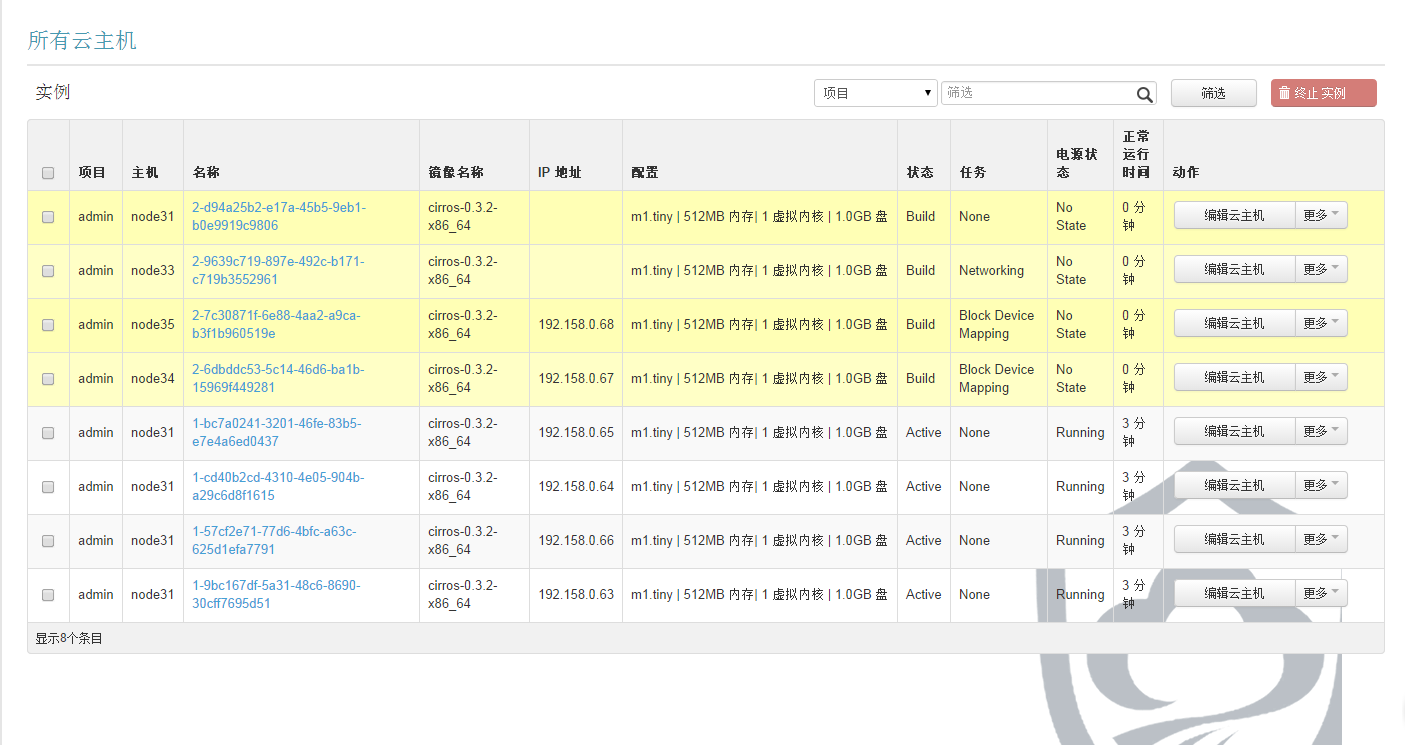
调度算法验证完毕。
这篇关于资源隔离调度算法测试(isolated_scheduler)及openstack集群开发环境搭建的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






