本文主要是介绍【算法与数据结构】深入解析二叉树(二)之堆结构实现,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

文章目录
- 📝二叉树的顺序结构及实现
- 🌠 二叉树的顺序结构
- 🌠 堆的实现
- 🌠 堆的实现
- 🌉堆向下调整算法
- 🌉堆的创建
- 🌉建堆时间复杂度
- 🌉堆的插入
- 🌉堆的删除
- 🌠堆向上调整算法
- 🌉堆的接口
- 🌠堆的实现
- 🌠堆的实现代码测试
- 🚩总结
📝二叉树的顺序结构及实现
🌠 二叉树的顺序结构
普通的二叉树是不适合用数组来存储的,因为可能会存在大量的空间浪费。而完全二叉树更适合使用顺序结构存储。现实中我们通常把堆(一种二叉树)使用顺序结构的数组来存储,需要注意的是这里的堆和操作系统虚拟进程地址空间中的堆是两回事,一个是数据结构,一个是操作系统中管理内存的一块区域分段。
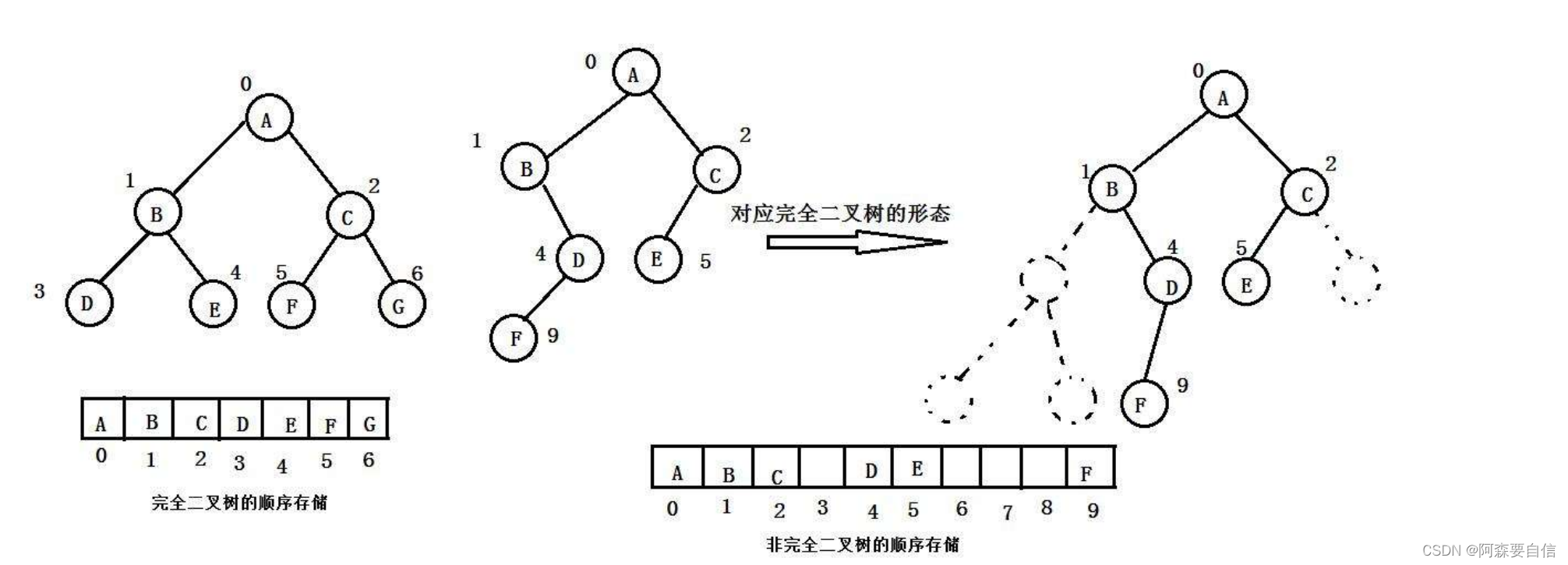
🌠 堆的实现
堆(heap)是计算机科学中一类特殊的数据结构的统称。堆通常是一个可以被看做一棵树的数组对象。堆总是满足下列性质:
堆的物理结构本质上是顺序存储的,是线性的。但在逻辑上不是线性的,是完全二叉树的这种逻辑储存结构。 堆的这个数据结构,里面的成员包括一维数组,数组的容量,数组元素的个数,有两个直接后继。
堆的定义如下:n个元素的序列{k1,k2,ki,…,kn}当且仅当满足下关系时,称之为堆。
(且)或者(), ()
若将和此次序列对应的一维数组(即以一维数组作此序列的存储结构)看成是一个完全二叉树,则堆的含义表明,完全二叉树中所有非终端结点的值均不大于(或不小于)其左、右孩子结点的值。由此,若序列{k1,k2,…,kn}是堆,则堆顶元素(或完全二叉树的根)必为序列中n个元素的最小值(或最大值)。
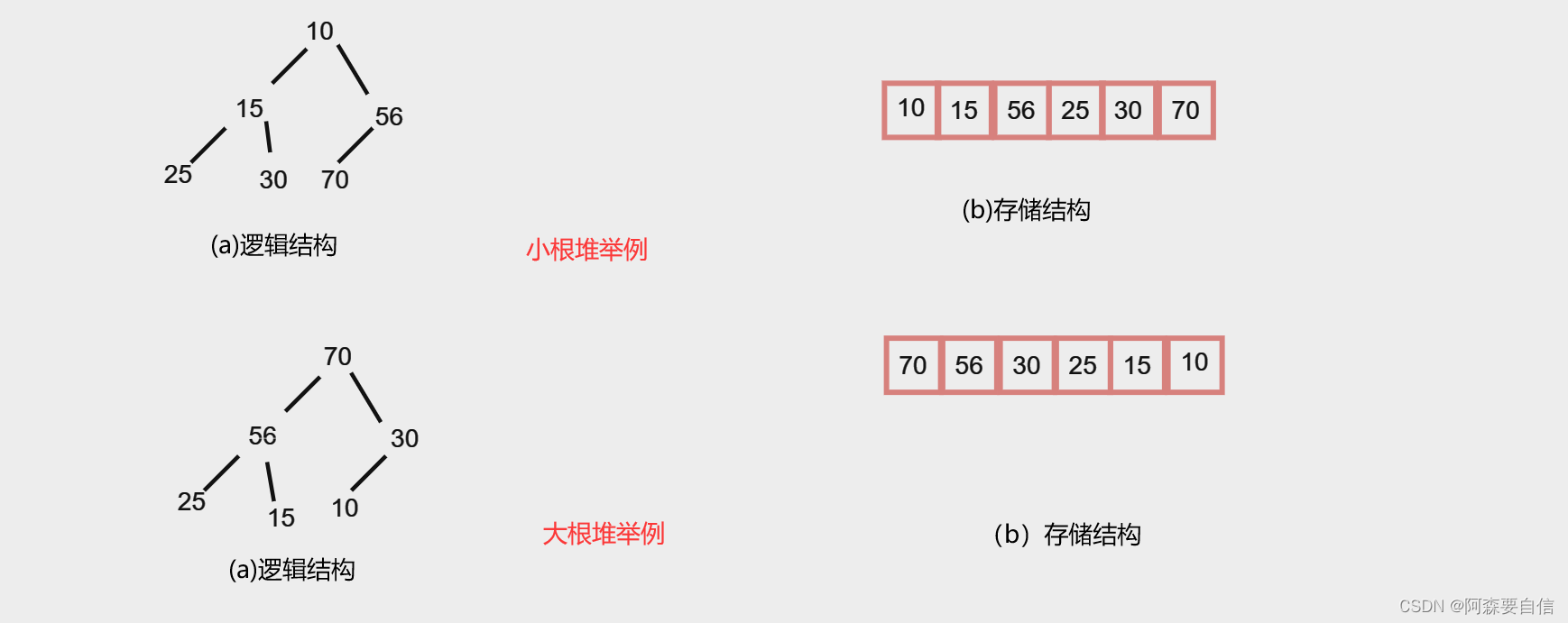
将根结点最大的堆叫做最大堆或大根堆,根结点最小的堆叫做最小堆或小根堆。常见的堆有二叉堆、斐波那契堆等
堆的性质:
- 堆中某个节点的值总是不大于或不小于其父节点的值;
- 堆总是一棵完全二叉树。
🌠 堆的实现
🌉堆向下调整算法
现在我们给出一个数组,逻辑上看做一颗完全二叉树。我们通过从根节点开始的向下调整算法可以把它调整成一个小堆。向下调整算法有一个前提:左右子树必须是一个堆,才能调整。
int array[] = {27,15,19,18,28,34,65,49,25,37};
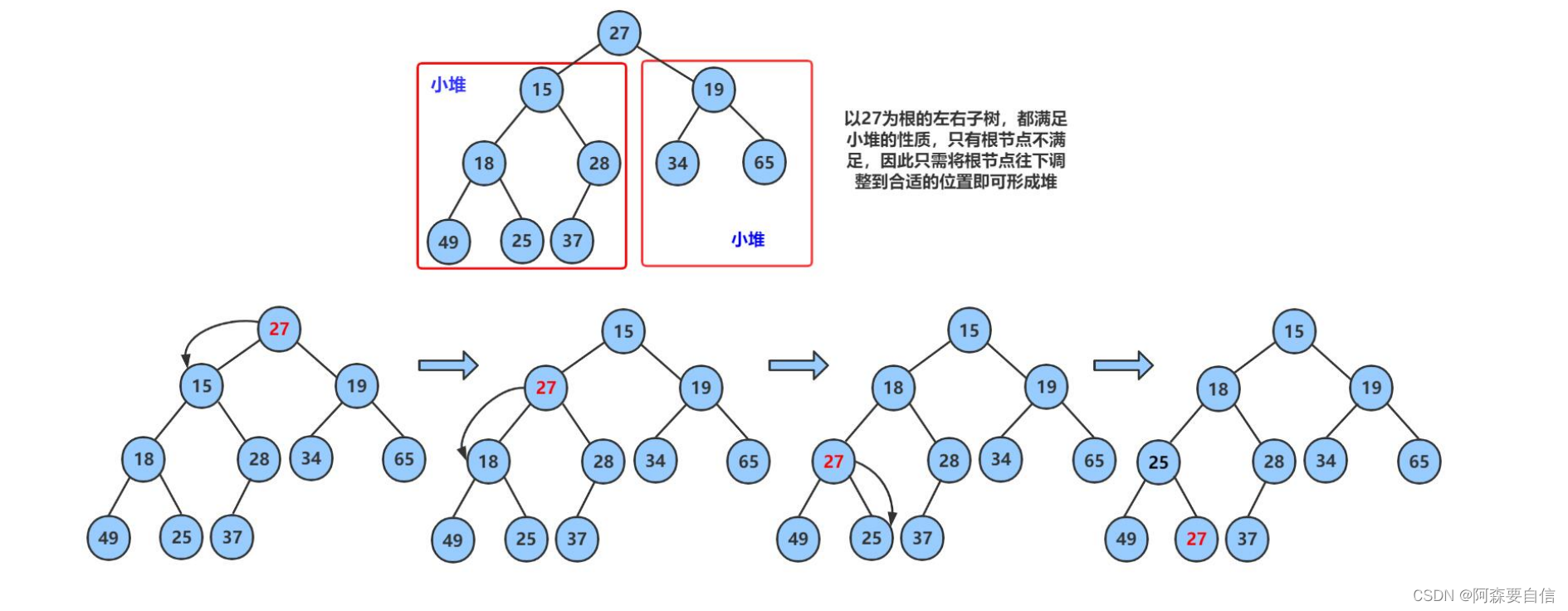
void AdjustDown(HPDataType* a, int n, int parent)
{int child = parent * 2 + 1;while (child < n){if (child+1<n && a[child + 1]>a[child]){child++;}if (a[child] > a[parent]){Swap(&a[child], &a[parent]);parent = child;child = parent * 2 + 1;}else{break;}}
}
🌉堆的创建
下面我们给出一个数组,这个数组逻辑上可以看做一颗完全二叉树,但是还不是一个堆,现在我们通过算法,把它构建成一个堆。根节点左右子树不是堆,我们怎么调整呢?这里我们从倒数的第一个非叶子节点的子树开始调整,一直调整到根节点的树,就可以调整成堆。
int a[] = {1,5,3,8,7,6};
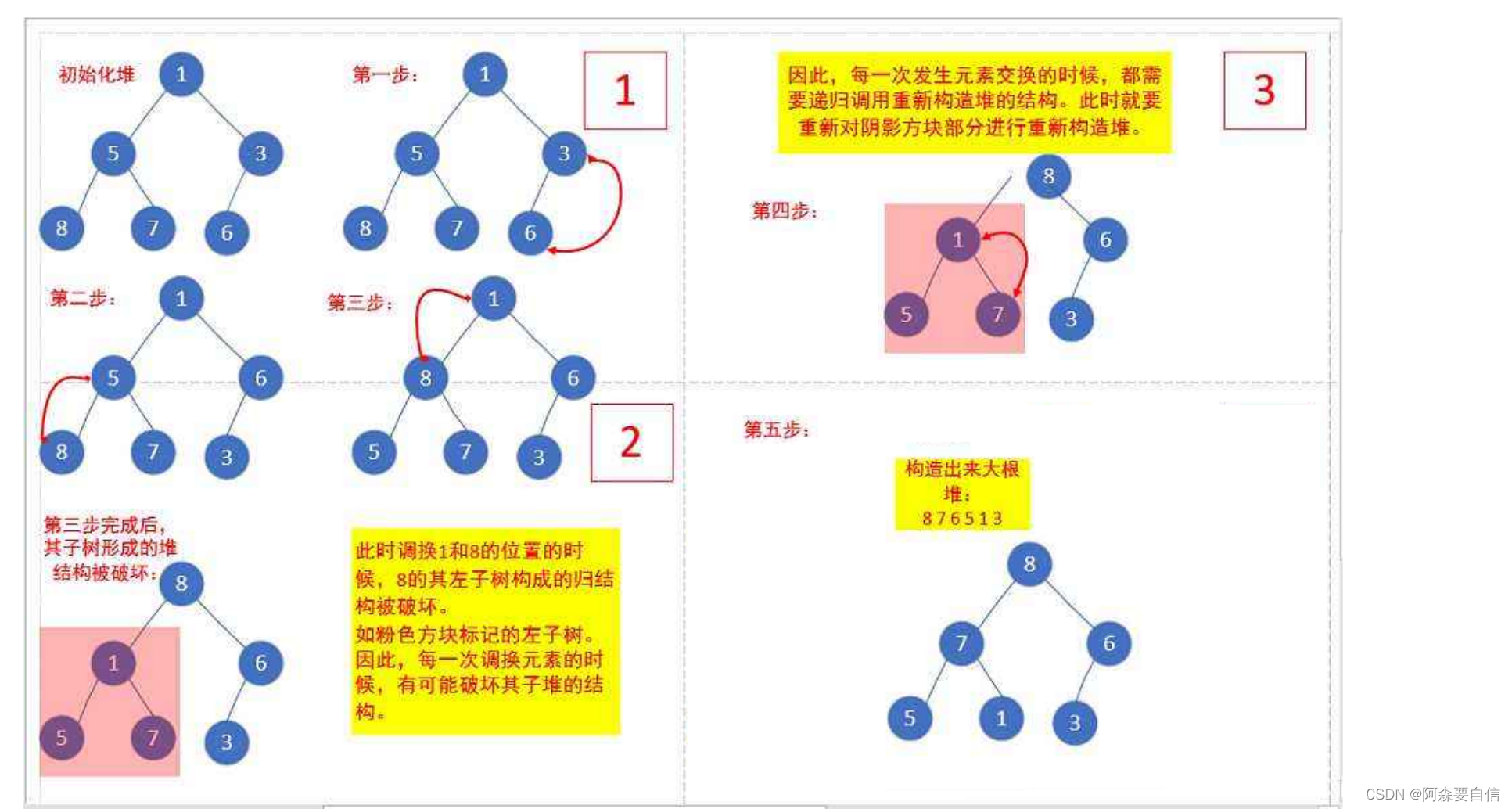
代码:
int size=sizeof(array)/sizeof(int);
//向下建堆,复杂度为O(N)
for (int i = (size - 1 - 1) / 2; i >= 0; i--)
{AdjustDown(array, size,i);
}
void AdjustDown(HPDataType* a, int n, int parent)
{ //a是数组指针,n是数组长度,parent是当前需要下调的父结点索引int child = parent * 2 + 1;//child表示父结点parent的左孩子结点索引,因为是完全二叉堆,可以通过parent和2计算得到while (child < n){//如果左孩子存在if (child + 1 < n && a[child + 1] < a[child]){//如果右孩子也存在,并且右孩子值小于左孩子,则child指向右孩子child++;}if (a[child] < a[parent])//如果孩子结点值小于父结点值,则需要交换{Swap(&a[child], &a[parent]);//交换孩子和父结点parent = child;//父结点下移为当前孩子结点child = parent * 2 + 1;//重新计算新的左孩子结点索引}else{break;}}
}
这是向下调整,最终形成小根堆,如果你想修改大根堆只需改变两个代码方向即可:
if (child+1<n && a[child + 1]>a[child])
if (a[child] > a[parent])
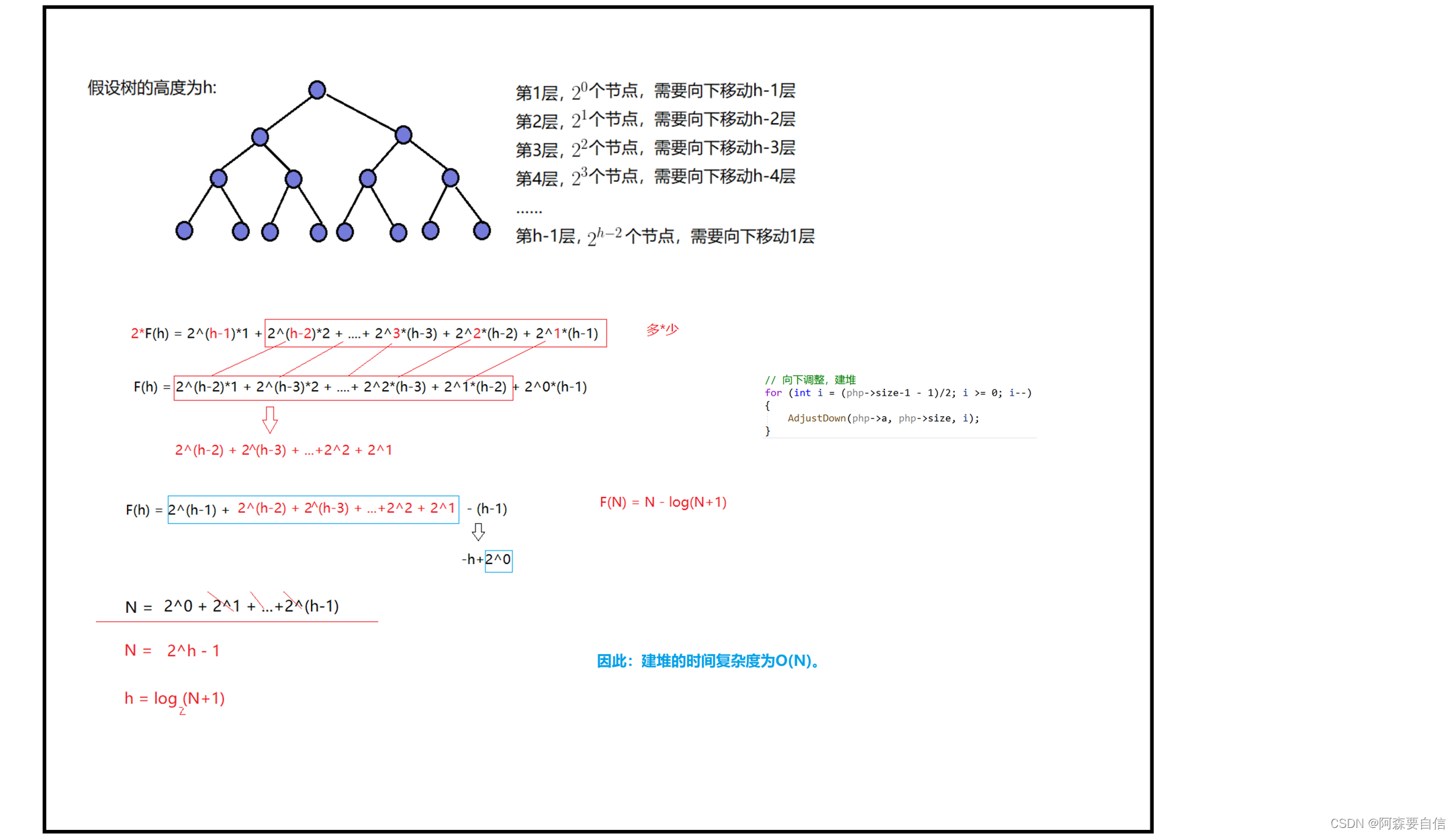
🌉建堆时间复杂度
因为堆是完全二叉树,而满二叉树也是完全二叉树,此处为了简化使用满二叉树来证明(时间复杂度本来看的就是近似值,多几个节点不影响最终结果):
复杂度:O(N)
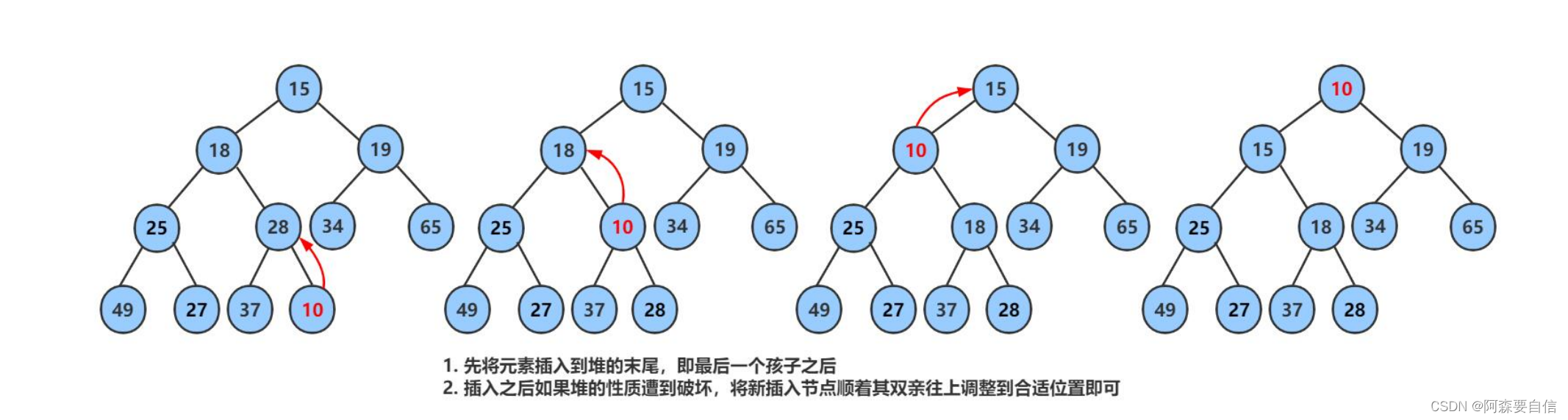
🌉堆的插入
先插入一个10到数组的尾上,再进行向上调整算法,直到满足堆。
void HPPush(HP* php, HPDataType x)
{assert(php);if (php->size == php->capacity){size_t newCapacity = php->capacity == 0 ? 4 : php->capacity * 2;HPDataType * tmp = realloc(php->a, sizeof(HPDataType) * newCapacity);if (tmp == NULL){perror("realloc fail");return;}php->a = tmp;php->capacity = newCapacity;}php->a[php->size] = x;php->size++;AdjustUp(php->a, php->size - 1);
}
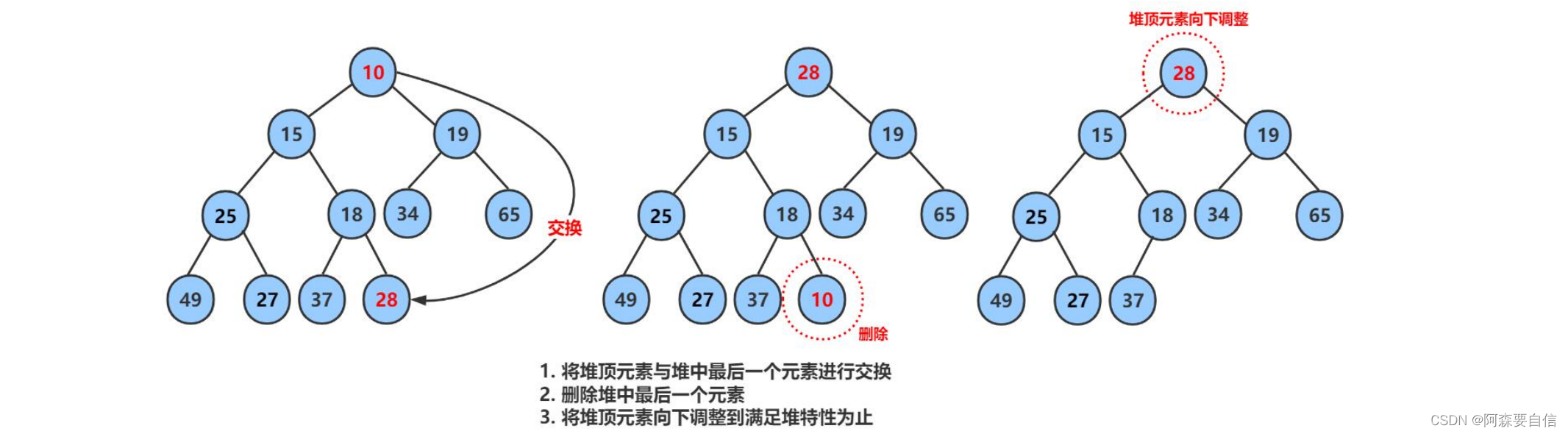
🌉堆的删除
删除堆是删除堆顶的数据,将堆顶的数据根最后一个数据一换,然后删除数组最后一个数据,再进行向下调整算法。
//时间复杂度是:logN
void HPPop(HP* php)
{assert(php);assert(php->size > 0);Swap(&php->a[0], &php->a[php->size - 1]);php->size--;AdjustDown(php->a, php->size, 0);
}
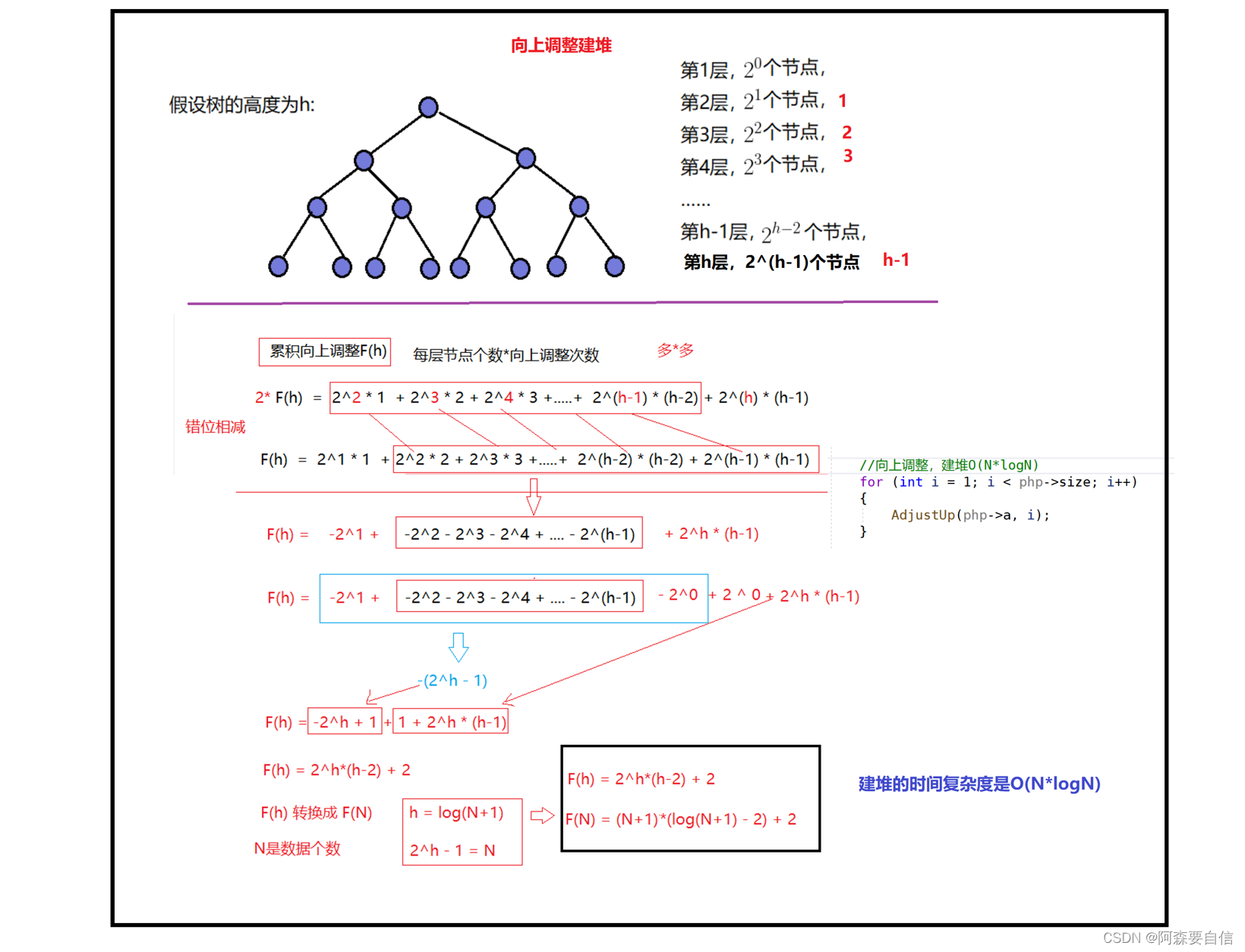
🌠堆向上调整算法
堆向上调整算法主要用于堆排序中,删除堆顶元素后,将最后一个元素补至堆顶,然后需要向上调整。
//向上调整,建堆O(N*logN)
for (int i = 1; i < size; i++)
{ //for循环从索引1开始,到size结束,即从第二个元素开始。AdjustUp(array, i);
}
void AdjustUp(HPDataType* a, int child)
{int parent = (child - 1) / 2;//计算父节点的位置:父节点位置 = (当前节点位置-1)/2while (child > 0)//如果当前节点位置大于0,并且当前节点值小于父节点值,需要向上调整:{if (a[parent] < a[child]){Swap(&a[parent], &a[child]);child = parent;parent = (parent - 1) / 2;}//将当前节点位置设为父节点的位置,重复执行步骤2和步骤3//直到当前节点位置为0,或者当前节点值不小于父节点值为止。else{break;}}
}
堆向上调整的主要步骤::确定需要调整的子节点,通常是补至堆顶的最后一个元素。
时间复杂度为O(N*logN)
🌉堆的接口
# define _CRT_SECURE_NO_WARNINGS 1
#include <stdio.h>
#include<stdlib.h>
#include<assert.h>
#include<stdbool.h>
#include<string.h>typedef int HPDataType;typedef struct Heap
{HPDataType* a;int size;int capacity;
}HP;void Swap(int* px, int* py);
void AdjustUp(HPDataType* a, int child);
void AdjustDown(HPDataType* a, int n, int parent);//堆的简单初始化
//void HPInit(HP* php);
//堆的初始化+建堆
void HPInitArray(HP* php, HPDataType* a, int n);
//堆的销毁
void HPDestroy(HP* php);
//堆插入数据然后保持数据是堆
void HPPush(HP* php, HPDataType x);
//取堆顶的数据
HPDataType HPTop(HP* php);
//删除堆数据
void HPPop(HP* php);
//堆的数据个数
int HeapSize(HP* php);
//堆的判空
bool HPEmpty(HP* php);🌠堆的实现
#include"HeadSort.h"
//堆的简单初始化
void HPInit(HP* php)
{assert(php);php->a = NULL;php->size = 0;php->capacity = 0;
}void HPInitArray(HP* php, HPDataType* a, int n)
{assert(php);php->a = (HPDataType*)malloc(sizeof(HPDataType) * n);if (php->a == NULL){perror("malloc fail");return;}memcpy(php->a, a, sizeof(HPDataType) * n);php->capacity = php->size = n;//HPInitArray:/*初始化堆数组,并将数据拷贝过来有两种方式建堆:向上调整:每个节点都与父节点比较,时间复杂度O(NlogN)向下调整:从最后一个非叶子节点开 始,每个节点与子节点比较,时间复杂度O(N)这里采用向下建堆,复杂度更低*///向上调整,建堆O(N*logN)/*for (int i = 1; i < php->size; i++){AdjustUp(php->a, i);}*///向下建堆,复杂度为O(N)for (int i = (php->size - 1 - 1) / 2; i >= 0; i--){AdjustDown(php->a, php->size,i);}
}void HPDestroy(HP* php)
{assert(php);free(php->a);php->a = NULL;php->capacity = 0;php->size = 0;
}void Swap(int* px, int* py)
{int temp = *px;*px = *py;*py = temp;
}void AdjustUp(HPDataType* a, int child)
{int parent = (child - 1) / 2;while (child > 0){if (a[parent] > a[child]){Swap(&a[parent], &a[child]);child = parent;parent = (parent - 1) / 2;}else{break;}}
}void HPPush(HP* php, HPDataType x)
{assert(php);if (php->size == php->capacity){size_t newCapacity = php->capacity == 0 ? 4 : php->capacity * 2;HPDataType * tmp = realloc(php->a, sizeof(HPDataType) * newCapacity);if (tmp == NULL){perror("realloc fail");return;}php->a = tmp;php->capacity = newCapacity;}php->a[php->size] = x;php->size++;AdjustUp(php->a, php->size - 1);
}HPDataType HPTop(HP* php)
{assert(php);return php->a[0];}void AdjustDown(HPDataType* a, int n, int parent)
{int child = parent * 2 + 1;while (child < n){if (child+1<n && a[child + 1]<a[child]){child++;}if (a[child] < a[parent]){Swap(&a[child], &a[parent]);parent = child;child = parent * 2 + 1;}else{break;}}
}//时间复杂度是:logN
void HPPop(HP* php)
{assert(php);assert(php->size > 0);Swap(&php->a[0], &php->a[php->size - 1]);php->size--;AdjustDown(php->a, php->size, 0);
}int HeapSize(HP* php)
{assert(php);return php->size;
}bool HPEmpty(HP* php)
{assert(php);return php->size == 0;
}
🌠堆的实现代码测试
int main()
{int a[] = { 60,70,65,50,32,100 };HP hp;HPInitArray(&hp, a, sizeof(a) / sizeof(int));/*HPInit(&hp);for (int i = 0; i < sizeof(a) / sizeof(int); i++){ HPPush(&hp, a[i]);}printf("%d\n", HPTop(&hp));HPPop(&hp);printf("%d\n", HPTop(&hp));*/while (!HPEmpty(&hp)){printf("%d\n", HPTop(&hp));HPPop(&hp);}HPDestroy(&hp);return 0;
}

🚩总结
感谢你的收看,如果文章有错误,可以指出,我不胜感激,让我们一起学习交流,如果文章可以给你一个小小帮助,可以给博主点一个小小的赞😘

这篇关于【算法与数据结构】深入解析二叉树(二)之堆结构实现的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




