本文主要是介绍电机参数辨识算法(2)——基于高频注入的磁链辨识策略,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
电机参数辨识算法(1)——基于高频注入的电感辨识策略-CSDN博客![]() https://blog.csdn.net/m0_46903653/article/details/136722750?spm=1001.2014.3001.5501上一期已经讲过了电感辨识方法。
https://blog.csdn.net/m0_46903653/article/details/136722750?spm=1001.2014.3001.5501上一期已经讲过了电感辨识方法。
今天这是参数辨识的第二期,今天来简单看看磁链的辨识。
Tpwm = 1e-4;%开关周期
Tspeed = 1e-4;%转速采样周期
Pn = 4;%电机极对数
Ld = 4.5e-3;
Lq = 6.2e-3;
Rs = 0.7;%定子电阻
flux = 0.137;%永磁体磁链
J = 0.00126;%转动惯量
Vdc = 150;%直流母线电压
iqmax = 5;%额定电流
Tdead = 5e-7;%死区时间
TEnable = 0.3;
相对于上一期而已,我把电感参数改的比较小了,这样的话,可以看看在这种电感相对较小的电机的辨识效果。
1.滤波的方式
上一期我有说到,如果用低通滤波器的话,还是会有一部分交流量无法滤除,所以我自己用了平均值滤波,而论文里面用的是低通滤波。
然后我在想,是不是我仿真里的低通滤波的截止频率还是太大了?(上一期内容我取了10Hz的截止频率)我现在试着把低通滤波截止频率改一改,看看滤波效果如何。
仿真中,还是选择在0.3s开启参数辨识。
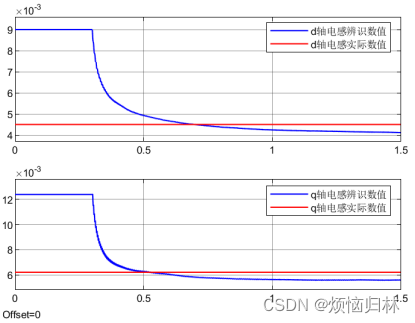
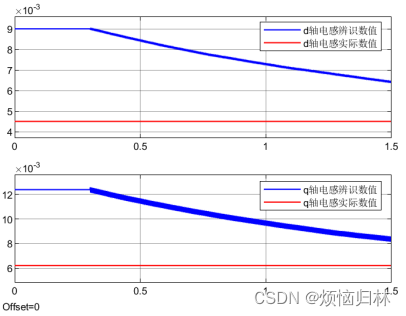
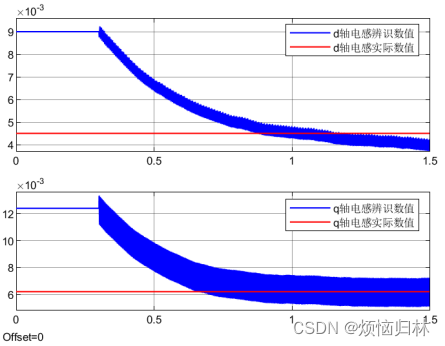
可以看到,如果低通滤波截止频率取0.1Hz,辨识的电感脉动很小,但是收敛非常慢!如果低通滤波截止频率取0.5Hz,辨识的电感收敛比较快,但是电感脉动大的离谱!
所以这么看来,还是用平均值滤波比较好。
2.电阻辨识
文章中给了提取电阻信息的公式。

但是,文章中实际上并没有进行电阻的辨识。只辨识了d-q电感以及磁链。
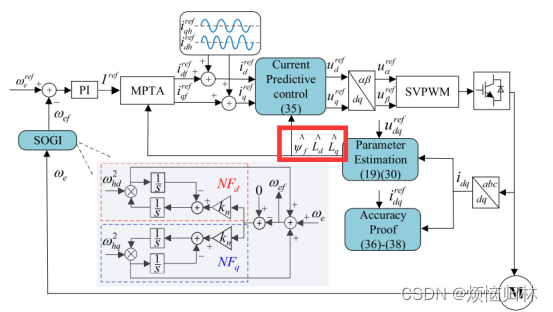
在无差拍预测电流控制中,电阻这一相其实往往被忽略的。从下面这个式子的红色方框中可以看到,假如你电阻是1Ω,控制周期100us,电感1mH,那么Ts*R/L=0.1,所以这一项常是被忽略的。

3.磁链辨识
那我们接下来看看这篇文章的磁链辨识。文章上通过一个低通滤波器,提取电压参考值的直流分量以及电流的直流分量。


从上文的滤波器分析来看,我觉得这里还是不应该用低通滤波器,因为低通滤波始终没有办法提取出来有效的直流分量。所以,我直接采用了平均值滤波!
(1)平均值滤波模块的验证
从这个式子(30)来看,我们需要平均滤波的物理量为:(1)d-q轴的电压参考给定值;(2)d-q电流的测量值。
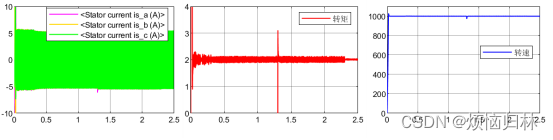
我这里已经搭建好了平均滤波的模块,我们直接来看看滤波效果。仿真工况就是,电机带2Nm负载,额定转速是1000r/min,0.3s时开始注入高频电流(即启用辨识程序)。
可以看到,在平均值滤波之后,所有的变量都变成了直流。(不要问我为什么d-q电流滤波之后还有大纹波,那是因为自己把电流放大了,自己注意看幅值)
(2)小磁链辨识效果的验证
滤波模块搭建好了之后,那就可以直接用式子(30)来计算磁链数值了。
这里要注意一点,式子(30)是利用平均值滤波之后的电流以及电压参数,那你肯定得等平均值滤波稳定之后再开始进行磁链的计算对吧。
从上面的波形看来,平均值滤波之后的d轴电流,大概在1.25s才稳定,所以我们开始磁链辨识时间设置应大于1.25s之后。我这里设置为1.5s开始磁链辨识。
我把磁链初值设置为0.137,也就是标准值。然后发现1.5s开始磁链辨识之后,辨识得到的误差非常非常大!!!!!!!
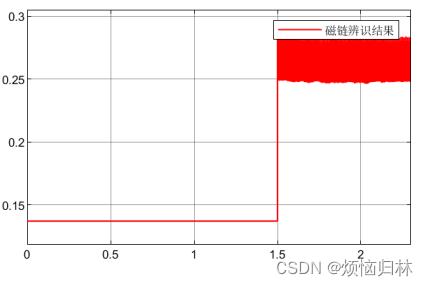
(3)大磁链辨识效果的验证
然后我再看看了文献中的磁链,文献中的磁链非常巨大!磁链数值为0.8Wb,是我电机磁链数值的五倍之多。
文章中也说了,逆变器非线性对磁链辨识有一定的影响。我这个辨识效果不好的原因估计就是,逆变器非线性的占比相对较大了(我仿真中的死区设置为0.5us)。
那我接下来把磁链放大为原来的五倍,注意,此时直流母线电压也要相应提高!
修改的电机参数如下:
flux = 0.137*5;%永磁体磁链
J = 0.00126*5;%转动惯量
Vdc = 150*5;%直流母线电压
可以看到当前磁链数值是0.685Wb,辨识结果大致为0.85Wb左右。说明误差不小,但是误差的占比以及小了很多。
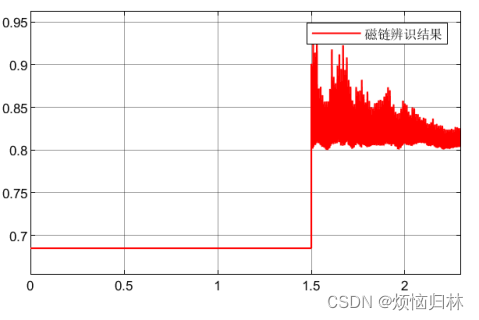
(4)辨识效果差的原因分析
注意一下,发现上文辨识的磁链数值波动非常大!
找了找原因。主要是平均滤波之后的d轴电流很小。因为我采用id=0控制,所以滤波之后的id都是在0上下波动的。
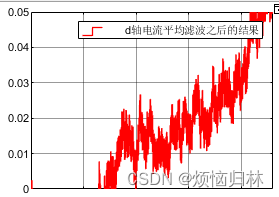
再看看式子(30),磁链数值的分母为id,所以相当于一个接近于0的数做为分母,那这个id轻微变化,肯定就会造成磁链的巨大波动。
而论文中采用的是IPMSM,其id不等于0,所以论文中的磁链估计效果很好。那我现在采用id=-5,把id的基波参考值给大一些,这样有利于计算磁链。
(5)采用id≠0控制后的磁链辨识效果
采用id=-5之后,平均滤波的结果以及磁链辨识结果如下。可以看到,磁链的辨识结果大致为0.6825左右,与真实值的误差非常非常之小!
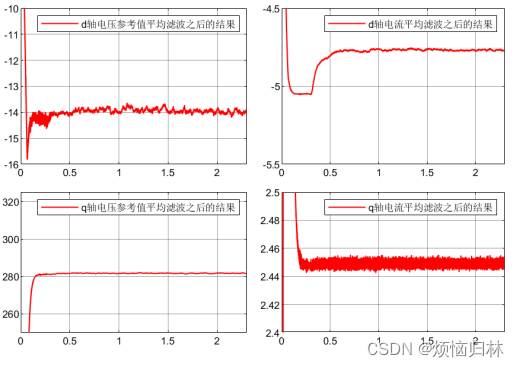
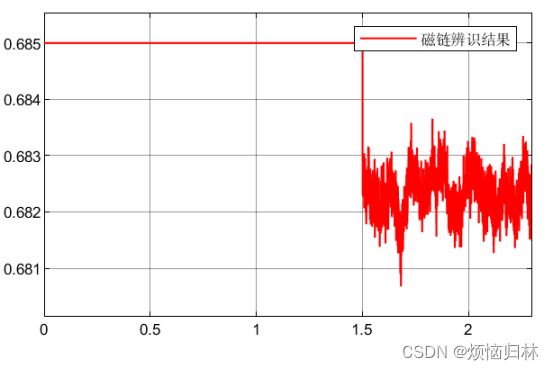
那我再转过头来想想,刚才在磁链比较低的时候,辨识效果不行,是不是也是因为id=0的原因呢?
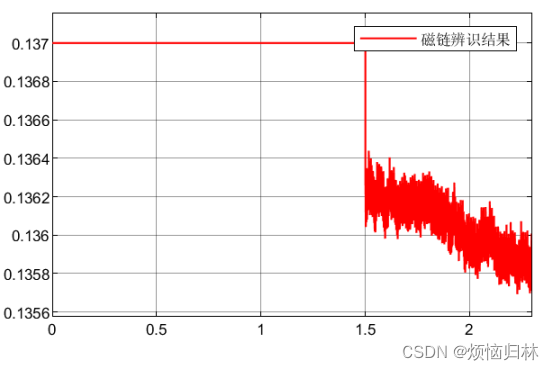
那好,我现在同样实行id=-5,对磁链为0.137的电机进行磁链辨识。辨识结果如下,辨识的磁链数值为0.136左右。误差占比(0.001/0.137)*100%=0.73%,这个误差太完美了,这么低的误差,不得不佩服。
4.仿真连接
和参数辨识的上一讲内容一样,上面的模块验证,只是在离线的方式下进行的,磁链辨识模块还没有接入到系统当中。那么,我们已经验证了磁链辨识模块的可行性,我们现在把搭建好的磁链辨识模块与整个控制回路相链接,看看在控制器运行时,磁链模块的辨识效果吧。
辨识模块以及整个控制器的simulink模型如下:
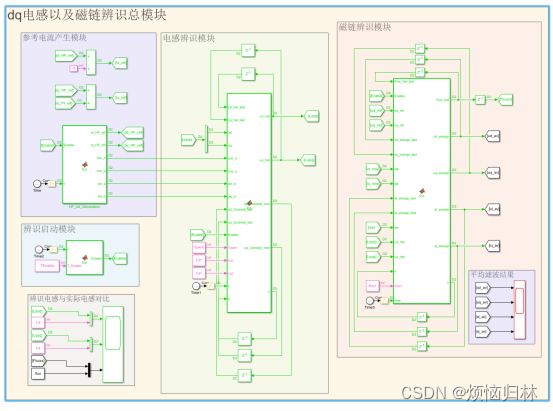
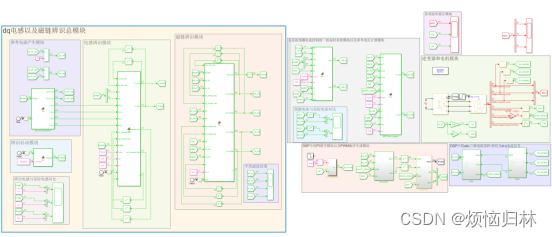
(1)控制器电感参数设置为实际电感的两倍,控制器磁链参数设置为实际磁链的四倍下的仿真结果
仿真参数如下:
Tpwm = 1e-4;%开关周期
Tspeed = 1e-4;%转速采样周期
Pn = 4;%电机极对数
Ld = 4.5e-3;
Lq = 6.2e-3;
Rs = 0.7;%定子电阻
flux = 0.137*1;%永磁体磁链
J = 0.00126*1;%转动惯量
Vdc = 150*1;%直流母线电压
iqmax = 8;%额定电流
Tdead = 5e-7;%死区时间
TEnable = 0.3;
%这是控制器使用的电机参数
Ld1 = 2*Ld;%电感参数设置为实际电感的两倍
Lq1 = 2*Lq;
Rs1 = Rs;%电阻参数设置为实际电阻
flux1 = 4*flux;%磁链参数设置为实际磁链的四倍
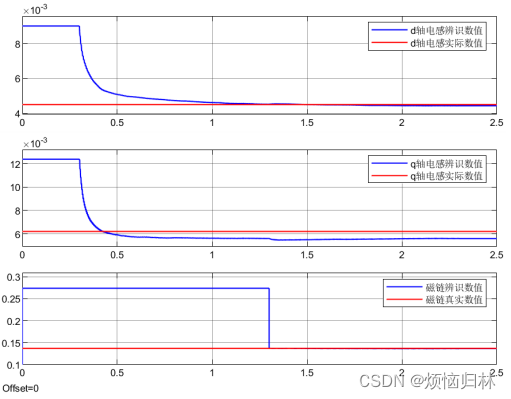
这里我采用与论文中一致的失配方式,即控制器电感参数设置为实际电感的两倍,控制器磁链参数设置为实际磁链的四倍。
仿真工况:负载2Nm,id参考值为-5A(为了更好的辨识磁链数值),转速保持1000r/min。0.3s开始注入高频电流进行电感辨识,同时对高频电流进行平均值滤波,当平均值滤波结果稳定后,也就是1.3s开始进行磁链辨识。2.3s结束高频电流注入,即停止电感辨识,同时也停止磁链辨识。
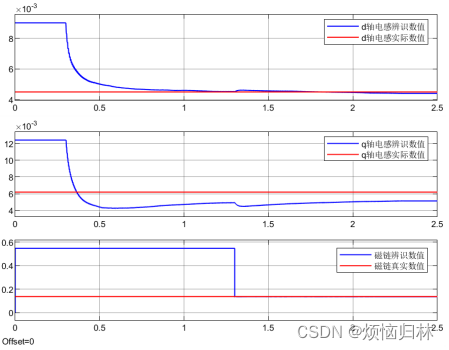
首先呢,先看辨识的结果。由于我们把控制器磁链设置为真实磁链的4倍,这个偏差属于非常大了的。实际中不会出现那么大的偏差(偏差个50%就很夸张了),除非永磁体在高温长时间运行发生了退磁。这个较大的偏差就导致了q轴电感估计结果有一定偏差了,但是也还好,偏差也不大。其次,在1.3s开始辨识磁链的时候,磁链立马就达到了真实数值,辨识效果非常好!这是因为我刚才在前面搭建模型的时候也说了,我搭建的模型里,是等待电压以及电流的平均滤波数值稳定之后,才开始计算磁链。用已经稳定的数值,计算出磁链,这就使得磁链立马达到了真实值。
总的来说,在电感和磁链分别发生2倍/4倍失配的情况下,最终辨识的精度还是很高的!
接下来看看无差拍控制器中,电流的预测值和真实值的对比。注意看,在1.3s之前,由于磁链失配,给q轴电流的预测值和真实值之间,带来了一个巨大的静差。在1.3s之后,由于磁链达到了真实值,所以静差就立马被消除了。
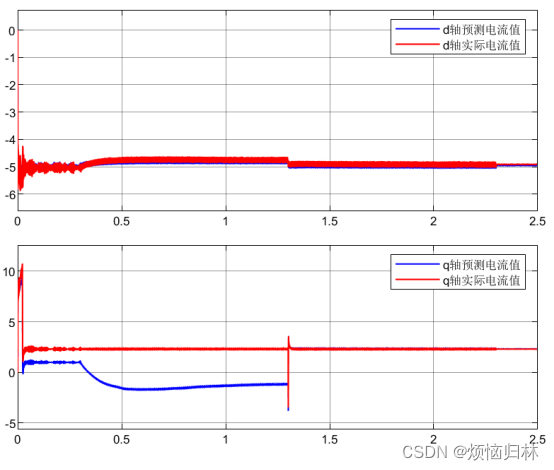
为什么磁链失配会产生静差?可以看看我之前的这篇文章。
永磁同步电机高性能控制算法(7)——基于PI调节器控制、无差拍预测电流控制、扩张状态观测器-无差拍预测电流控制、扩张状态观测器-无模型预测控制的仿真对比 - 知乎在之前的文章中就已经做过PI、DPCC(无差拍预测电流控制)、基于ESO(扩张状态观测器)的DPCC,以及基于ESO的MFPC(无模型预测控制),但是当时还没有进行一个详细的对比。 烦恼归林:永磁同步电机高性能控制算法…![]() https://zhuanlan.zhihu.com/p/680117350
https://zhuanlan.zhihu.com/p/680117350
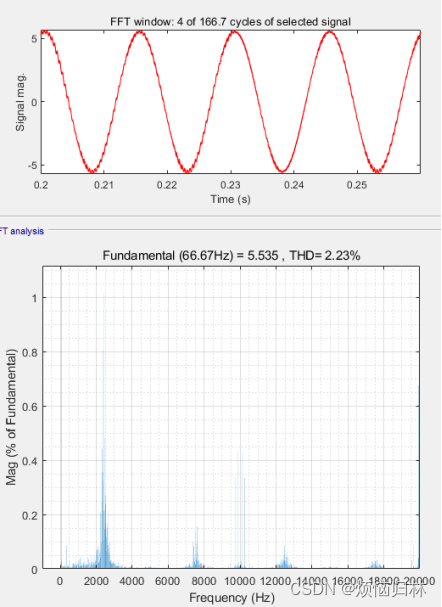
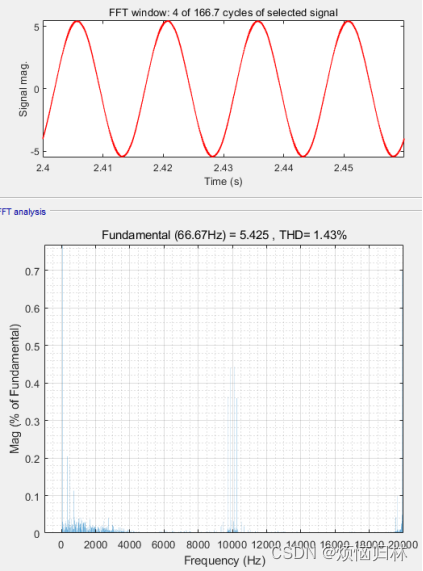
辨识前后,相电流THD由2.23%降低至1.43%了。
(2)控制器电感参数设置为实际电感的两倍,控制器磁链参数设置为实际磁链的两倍下的仿真结果
现在把磁链失配由四倍改为两倍,把负载转矩降低为原来的一半。
从下图可以看到,磁链失配由四倍变为两倍的时候,q轴电感的误差得到了一定的减小。
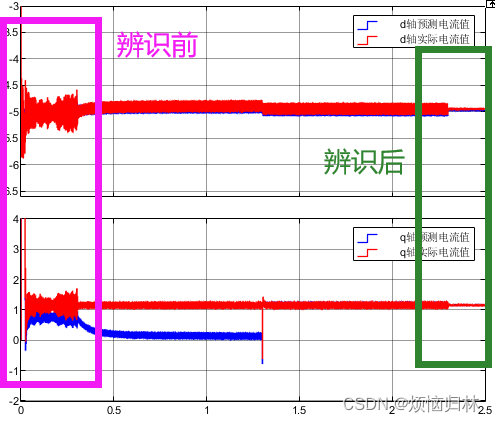
从这个图可以看到,辨识前后,dq电流中由电感失配产生的高频电流脉动以及由磁链产生的预测误差都被消除了。
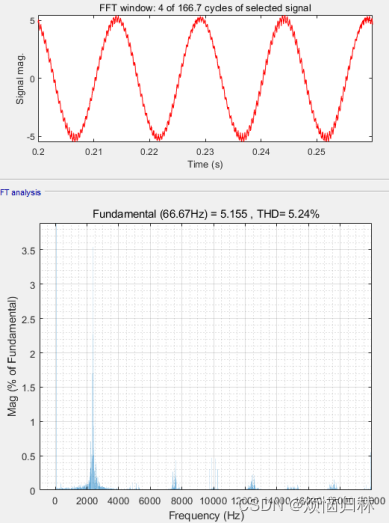
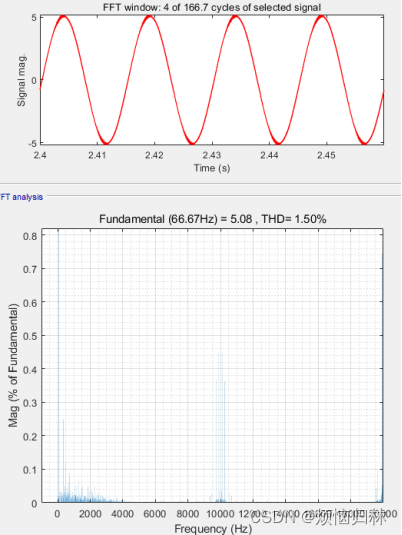
辨识前后的相电流THD由5.24%降低至1.50%,可见,本文的方法非常好。
5.总结
在参数辨识的这两篇分享中,我们完成了电感以及磁链的辨识,而且辨识的效果是非常好的。
在文章中你们也可以看到,如果采用文章中的低通滤波器,是没办法实现那么好的辨识效果。所以呢,自己在复现文章模型的时候,应该仔细思考如何解决文章中的问题,而不是照搬文章的内容。(这也是一个产生创新点的好途径)
当文章复现效果不好的时候,可以看看是不是自己的模型搭建错了,或者说看看论文的电机参数,是不是由于电机参数不一致导致的问题。就比如上文,我刚刚搭建磁链辨识模块的时候,效果并不好,最后发现是自己采用id=0控制的问题。
这篇关于电机参数辨识算法(2)——基于高频注入的磁链辨识策略的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




