本文主要是介绍UC伯克利:用大模型预测未来,准确率超越人类!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
近年来,语言模型在文本生成、翻译、情感分析等领域大放异彩,但利用语言模型做预测的任务还比较少。这里的预测任务指的是根据现有情况预测还未发生的结果,比如“明天会下雨吗?”、“4月1号前GPT-5会发布吗?”
其实文本生成本质上也是一种预测,根据输入的文本序列,预测下一个单词或字符。这样看来大语言模型天然就适合做预测任务。
事实真的如此吗?
今天介绍的这篇文章通过实验结果告诉我们没有任何模型天生擅长预测,且与人类预测水平还有一定的差距。
因此,本文沿着改善大模型的预测能力展开研究。简单来说,模型需要更加详细的背景信息和最新的信息才能做出准确的预测,因此作者增加了多阶段丰富的检索增强过程。另外作者还引导大模型同时给出预测结果与推理过程,增加了预测过程的可解释性。
同时发布了一个从5个真实世界的预测竞赛中编制的最大和最新的预测数据集,补充了背景信息的方法在该数据集上取得了与人类相当的水平。
论文标题:
Approaching Human-Level Forecasting with Language Models
论文链接:
https://arxiv.org/pdf/2402.18563.pdf
初步研究:数据、模型和基线
1. 数据
作者从Metaculus、Good Judgment Open、INFER、Polymarket和Manifold5个预测平台收集预测问题。下表展示了一个样本示例,每个问题包括一个背景描述、解决标准和3个时间戳:

本文专注于预测二元问题,并将收集到的多项选择问题拆分为二元问题。为防止语言模型预训练中的潜在信息泄漏,测试集中的每个问题都是选用2023年6月1日或之后,即基础语言模型的训练截止日期之后。而训练集和验证集中的所有问题都在2023年6月1日之前解决。这产生了一组5,516个二元问题,其中3,762个用于训练,840个用于验证和914个用于测试,如下表所示:

2. 评估
检索设置
为了模拟已解决问题的预测,设置模型查询历史新闻语料库,以检索问题开始日期和指定的检索日期之间的文章,检索日期可以被视为预测的“模拟日期”。
为每个问题设定检索日期,采取几何增长的方式,在问题开放与关闭日期间选择时间点。此安排基于两点考虑:问题初期活跃度较高,且部分问题关闭日期过于保守,远在问题解决后很久。为每个问题设定n=5个检索日期:
![]()
若问题在关闭前已解决,则排除其后的检索日期。此几何检索方案下,平均保留86%的检索日期。语料库中的平均问题窗口大约为70天,平均解决时间为42天。
评估指标
由于本文呢重点关注二元问题,因此采用Brier分数作为性能指标,定义为,其中代表概率预测,代表结果。Brier分数是一个严格的适当评分规则:假设的真实概率为,那么最理想的情况是。因此Brier分数越小,代表预测越准确。
为了计算最终的Brier分数,首先计算每个问题在不同检索日期上的Brier分数的平均值,然后计算所有问题的平均Brier分数。作者还报告了标准误差,以及均方根校准误差来测量校准情况。
基线测试
作者选用14个常用的大模型使用zero-shot提示和scratchpad提示,在没有额外的信息检索情况下报告了大模型的预测性能:

▲zero-shot提示
scratchpad提示要求模型在考虑是和否之后,对测试集中的给定问题做出预测:

结果如下表所示,可以发现没有一个模型天生擅长预测。大多数模型的得分都接近或低于随机猜测。GPT-4和Claude-2系列表现稍好,但仍然明显落后于人类预测能力(.149)。

本文方法
从上节的实验结果可以看出,所有模型在基准设置下表现不佳。模型需要详细的背景信息和最新的信息才能做出准确的预测。因此作者为系统增加了检索增强,并通过优化提示策略和微调来引出更好的推理。
1.检索
本文设置的检索系统包括4个步骤,如下图所示:语言模型接收问题并生成搜索查询,以从历史新闻API中检索文章。然后语言模型对文章进行相关性排名,并总结前k篇文章。

为了实现更广泛的覆盖范围,作者要求模型将预测问题分解为子问题,并使用每个子问题生成一个搜索查询;

接下来,系统使用LM生成的搜索查询从新闻API中检索文章。作者在评估了5个API的检索文章的相关性后选择了NewsCatcher1和Google News。
然后要求GPT-3.5-Turbo设置如下prompt,评估所有文章的相关性并过滤掉得分低的文章,为了节省开支,只向模型呈现文章的标题和前250个字。

由于语言模型受其上下文窗口的限制,要求GPT-3.5-Turbo从每篇文章中提炼出与预测问题相关的最重要细节。最后,向LM呈现按相关性排序的前k篇文章摘要。
2. 推理
在预测任务中从模型中获取预测结果及其理由非常重要。为了获取详细的预测解释,作者重新设计了提示,包括提出问题,提供描述,指定解决标准和关键日期,以及检索到的前k个相关摘要,并提示语言模型生成预测。

除此之外,还包括四个额外的组成部分:
-
为了确保模型理解问题,要求其重新表述问题。同时,指导模型利用自身知识扩展问题,以提供更多信息。
-
促使模型利用检索到的信息和其预训练知识,提出为何可能发生或不发生结果的论据。
-
该模型可能会生成较弱的论点。为了避免将所有考虑因素视为相等,建议根据重要性对其进行权衡,并相应地将它们聚合成初步预测。
-
最后,为了防止潜在的偏见和误校准,要求模型检查其是否过度自信或不够自信,促使其进行校准并相应修正预测。
整体的提示如下所示:

为了得到更好的推理效果,作者通过超参数扫描找到的最佳参数,来启动GPT-4-1106-Preview,因为它在测试的语言模型中始终给出最低的Brier分数。
另外,还使用训练数据微调GPT-4版本,可以在没有指示性指令的情况下进行推理,并生成具有准确预测的推理。
3. 优化系统
1. 微调推理模型
作者对语言模型进行微调,以生成准确预测的推理。为了生成微调数据,首先在训练集上收集大量的预测,然后选择模型胜过人类水平的子集。整体流程如下图所示:

生成的微调数据具有以下结构,如上图右边所示: • 模型的输入包括问题、描述和解决标准,然后是总结的文章。 • 目标输出包括推理和预测。
总共生成了73,632个推理,其中13,253个符合上述要求,作者使用GPT-4-0613在这些数据上微调。
2. 超参数扫描
本文涉及了多组超参数,作者将超参数分成1-2个组,并进行迭代优化。对于每个组,基于验证集上的平均Brier分数选择最佳配置。按顺序优化这些组,固定前一组的最佳配置,同时扫描当前组。尚未扫描的超参数会针对每个输入问题进行独立随机化。
结果与分析
首先评估了端到端系统在测试集上的Brier分数。所有超参数都是基于验证集选择的,并且所有测试集问题在时间上出现在验证问题之后,与现实设置相符。除了Brier分数,还将准确率作为指标之一。
本系统的整体得分达到(.179)明显优于最佳基准模型(使用 GPT-4-1106-Preview 的 0.208),但离人类基准还有一定的差距。
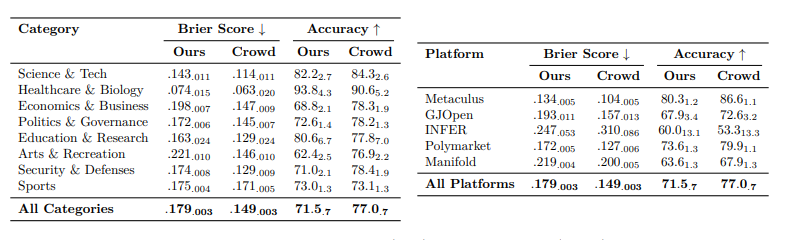
在各个类别中,该系统表现出明显的变化:在Sports上,系统几乎与人类表现持平,而在Environment & Energy,则落后很多。然而由于样本量较小,变化可能是由于噪音引起的,因此无法从子类别中的出强烈结论。
另外,我们的系统在验证集和测试集上具有良好的校准性,相比之下,在零-shot设置中,基础模型的校准性较差。
系统的优缺点分析
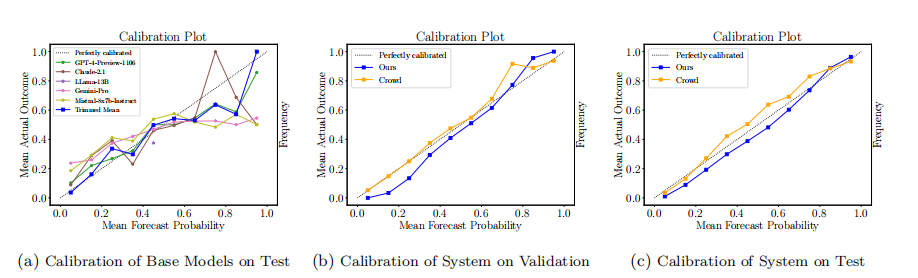
相较人类预测,本系统在验证集上表现优异,尤其在众人对答案信心不足、检索日期较早或文章数量较多时,此外系统校准更加精准。实现结果如下图所示:

对于人类不确定的问题(预测在0.3和0.7之间),本系统的表现优于他们(Brier分数为0.199 vs. 0.246),但在人类高度确信的问题(预测小于0.05)上,系统表现略逊,可能是由于模型保守预测策略所致。在较早的检索日期上,系统表现优于众人,但随问题明朗,提升速度放缓。系统依赖高质量检索,文章数量增加时性能更佳。
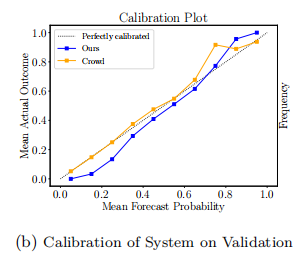
此外,如下图所示,尽管存在信心不足导致的校准误差,但整体校准效果良好。观察到接近0的预测值发生的频率低于预期,同样地,预测值接近1的事件发生的频率也高于模型所提示的。
消融实验
为了证明本系统的性能并不取决于基础模型(即 GPT-4)的能力,作者在所有微调数据(13,253个样本)上对 GPT-3.5 进行微调。结果发现,Brier分数仅略有下降:0.182,而之前的分数为 0.179。

为了展示微调带来的收益,只使用基础的 GPT-4-Preview-1106 作为推理模型。在这种设置下,被剔除微调的系统Brier分数为 0.186,比原始分数提高了0.007。 结果表明微调推理模型显著提升了系统的性能。
另外评测了检索系统的效果,在没有任何新闻检索,并使用基础的 GPT-4-1106-Preview 模型进行实验。被剔除检索功能的系统Brier分数为 0.206。而在前面的基线实验中最低Brier分数为0.208。因此缺少检索系统的系统恶化到了基准水平。
结论
本文提出了第一个可以接近人类水平进行预测的机器学习系统,开发了一种新颖的检索机制,利用语言模型确定要获取哪些信息以及如何评估其相关性,还提出了一种自监督微调方法,用于生成具有准确预测的推理。并发布了一个从5个真实世界的预测竞赛中编制的最大和最新的预测数据集。为自动化、可扩展的预测任务后续发展铺平了道路。
相信在不久的将来,基于语言模型的系统可以达到人类预测水平,从而为机构决策提供有利信息。


这篇关于UC伯克利:用大模型预测未来,准确率超越人类!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









