本文主要是介绍西瓜书机器学习AUC与ℓ-rank(loss)的联系理解以及证明(通俗易懂),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
在学习到这部分时,对 ℓ-rank 以及AUC的关系难以理解透彻,在网上看到其他博主也并未弄明白,大家大多写自己的理解,我希望您在看完这篇文章时能够深刻理解这二者的关系,如果我的理解有误,希望您在评论区指正,给出您的见解。
首先理解什么是AUC?
首先理解什么是ROC曲线,ROC曲线如何绘制?
ROC曲线,即接收者操作特征曲线(Receiver Operating Characteristic Curve),反映了在不同分类阈值下真正类率(TPR)和假正类率(FPR)的变化情况。
绘制ROC曲线的过程如下:
- 给定m+个正例和m-个反例,首先将分类的阈值设置到最大,此时所有的例子预测结果都是反例,此时真正例率和假正例率均为0,在坐标原点(0,0)处标记一个点。
- 然后,逐步降低阈值,每次降低都将导致更多的样例被划分为正例。对于每个降低的阈值,计算当前的真正例率和假正例率,并在ROC图上标记相应的点。
- 最后,用线段连接这些点,即得ROC曲线。
通俗地说,分类阈值就像一个“门槛”,数据样本需要通过这个“门槛”才能被归类到某个类别中。在二分类问题中,模型通常会为每个样本输出一个概率值,表示该样本属于正例(比如:某种疾病的患者)的概率。这时,我们就需要选择一个阈值,来决定当这个概率达到多少时,我们就认为这个样本是正例。
例如,如果我们设定阈值为0.5,那么当模型输出的概率(概率就是模型对一个例子的判断,比如说10%可能是正例,90%是反例)大于或等于0.5时,我们就认为这个样本是正例(那么刚才认为10%为正例就不被认为是正例);如果小于0.5,则认为是负例(比如:非疾病患者)。
我们所做的就是逐渐把开始设定的正例阈值从100%逐渐降低到0。然后看模型的结果被划分为真正例与假正例的结果。(比如,有个正例,机器给的判断是50%概率是正例,那么他就会在之后我们把阈值降到50%时被纳入正例,此时,这是一个正例,模型判断也为正例,那么就被纳入真正例,如果是这是一个反例,模型给出50%概率的正例,那么此时应该别纳入假正例)。
在绘制ROC曲线时,我们会使用多个不同的阈值来计算真正例率(True Positive Rate,TPR)和假正例率(False Positive Rate,FPR)。TPR表示实际为正例的样本中被预测为正例的比例,而FPR表示实际为负例的样本中被错误地预测为正例的比例。通过改变阈值,我们可以得到不同的TPR和FPR组合,从而绘制出ROC曲线。
具体来说,从(0,0)开始,对于给定的m1个正例和m2个反例,根据预测结果进行排序,依次将这些样例划分为正例。若为**真正例,则y值增加1/m1,否则x值增加1/m2。**最后,将这些点连线,所得到的面积就是AUC。

什么是AUC
AUC(Area Under the Curve)曲线则是基于ROC曲线计算得到的。AUC值表示ROC曲线下的面积,用于量化评估模型的性能。AUC值越接近1,表示模型的性能越好。
ℓ-rank
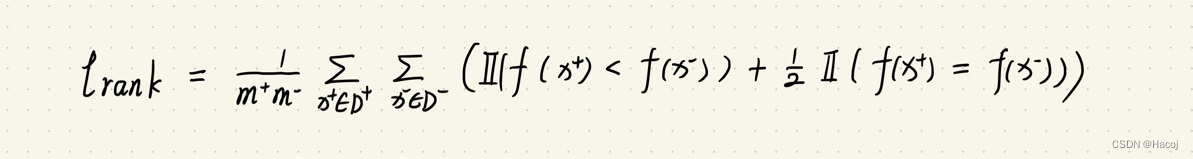
先看这个表达式,我们需要理解一些东西
m+与m -, D +与D-,II
m +与m -分别对应正例与反例的个数。
D+与D-分别对应正例集与反例集。
II(罗马数字2),如果在II后括号中的为正确表达式,那么返回1,否则返回0。
f函数
f函数可以认为是被判断出来的先后,如果例子被先判断出来,那么函数的值大,反之就小
ℓ-rank被称为排序损失,为什么要叫排序损失呢?
我们不妨看看刚才的ROC曲线
如果是正例,那点就在上边,如果是反例,就在上一个点的右边,所以咱们最好的情况就是上来把所有的正例全部找出来,就是ROC曲线一直向上,最后才开始向右走。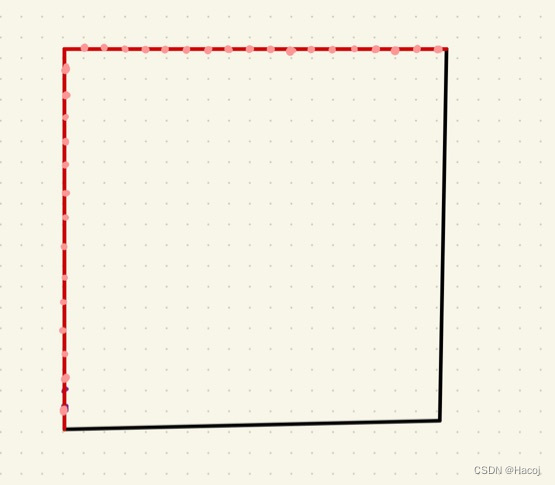
AUC表明的其实是一种顺序关系,即是在增大分类阈值(也就是让模型判断出来多少正例)时,正例会比反例被早判断出来的概率,也就是对正例的辨别能力,那这是如何在ROC曲线上体现出来的呢?我们以这个图的第二个点 为例子(假设它的坐标为(0.1)),我们可以发现在这个点的右侧,每一格(m,1)在ROC图线上都有对应的点,每个对应的点都是反例,这些反例就是在之后被发现的,因为从左下到右上,是分类阈值逐渐变大的过程,也就是相对偏后,那么,以我们这张图为例,在点(0,1)的右边的(20 - 0)* 1的矩阵(总共有20格)就是在指定阈值下正例比反例早被发现的概率(概率 需要归一化)。欸,那把所有的点的右侧部分的面积加起来归一化,不就是AOC,不就是正例比反例早发现的概率?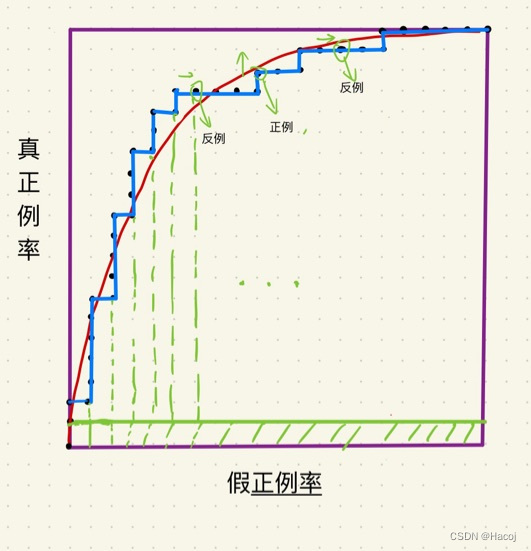
同理可得,在上边我们可以知道,一个点垂直向上形成的单位宽度的矩阵就是对于一个反例来说,它比部分正例早发现的概率(需要归一化)。
于是,AUC曲线的另一种表示形式应为
AUC = 1 - ℓ-rank
那么我们可以很轻易发现AUC与ℓ-rank的关系了,对于我们画的图AUC是右下侧,ℓ-rank是左上侧。
但是书上的还写了一个1/2 的等于项,这是为什么呢?
1/2项的来历
我们说到,ROC图线是不断增加阈值画点连线做成的图,那么他不一定是一个个例子来的,有可能阈值从1% -> 2%增加了两个例子,这两个例子得到的结果是,一个真正例,一个假正例,这导致真正例,假正例都增加了,这就形成了一个斜着的线,在左上,右下就形成了一个三角形,这就是1/2项的来历,此时,AUC也要加一个1/2的等于项。
证明
这篇关于西瓜书机器学习AUC与ℓ-rank(loss)的联系理解以及证明(通俗易懂)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







