本文主要是介绍MaPLe: Multi-modal Prompt Learning,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
代码:https://github.com/muzairkhattak/multimodalprompt-learning
目录
摘要
1.简介
2.相关工作
3.方法
3.1回顾CLIP
3.2MaPLe:Multi-modal Prompt Learning
3.2.1 Deep Language Promptin
3.2.2 Deep Vision Prompting
3.2.3 Vision Language Prompt Coupling
4.实验
4.1基准设置
4.2 通过V-L prompts prompting CLIP
4.3 基类到新类的泛化
4.4 跨数据集评估
4.5 域泛化
4.6 消融实验
5.总结
动机:
以前做prompt都是在图片或者文本一个模态做prompt,本文觉得只在其中一个模态(分支)做prompt只能达到次优的性能,所以他们提出应该在每一个模态都应该做prompt。另外,为了建立两个分支prompt的联系,作者提出了一个 coupling function,简单来说,visual branch 的 prompt embedding 是由 language prompt embedding映射来的。
摘要
预训练的视觉语言(V-L)模型,如CLIP,在下游任务中显示出出色的泛化能力。但是,它们对输入文本提示的选择很敏感,需要仔细选择提示模板才能运行良好。受自然语言处理(NLP)文献的启发,最近的CLIP适应方法学习提示作为文本输入,以微调下游任务的CLIP。我们注意到,使用提示来适应CLIP(语言或视觉)的单个分支中的表示是次优的,因为它不允许在下游任务上灵活地动态调整两个表示空间。在这项工作中,我们提出了针对视觉和语言分支的多模态提示学习(MaPLe),以改善视觉和语言表征之间的一致性。我们的设计促进了视觉语言提示之间的强耦合,以确保相互协同,并阻止学习独立的单模态解决方案。此外,我们在不同的早期阶段学习单独的提示,逐步对阶段特征关系建模,以允许丰富的上下文学习。我们评估了我们的方法在三个代表性任务上的有效性:对新类别的泛化、新的目标数据集和未见过的域转移。与最先进的CoCoOp方法相比,MaPLe在11个不同的图像识别数据集上取得了平均值,在新类别上取得了3.45%的绝对增益,在总谐波平均值上取得了2.72%的绝对增益。
1.简介
基本的视觉语言(V-L)模型,如CLIP(对比语言-图像预训练)对下游任务表现出出色的泛化能力。这些模型经过训练,可以在网络规模的数据上对齐语言和视觉模式,例如CLIP中的4亿文本图像对。由于自然语言提供了丰富的监督,这些模型可以对open-vocabulary的视觉概念进行推理。在推理过程中,使用手工设计的文本提示,例如,“a photo of a <category>”作为文本编码器的查询。输出文本嵌入与来自图像编码器的视觉嵌入相匹配,以预测输出类。设计高质量的上下文提示已被证明可以提高CLIP和其他V-L模型的性能。
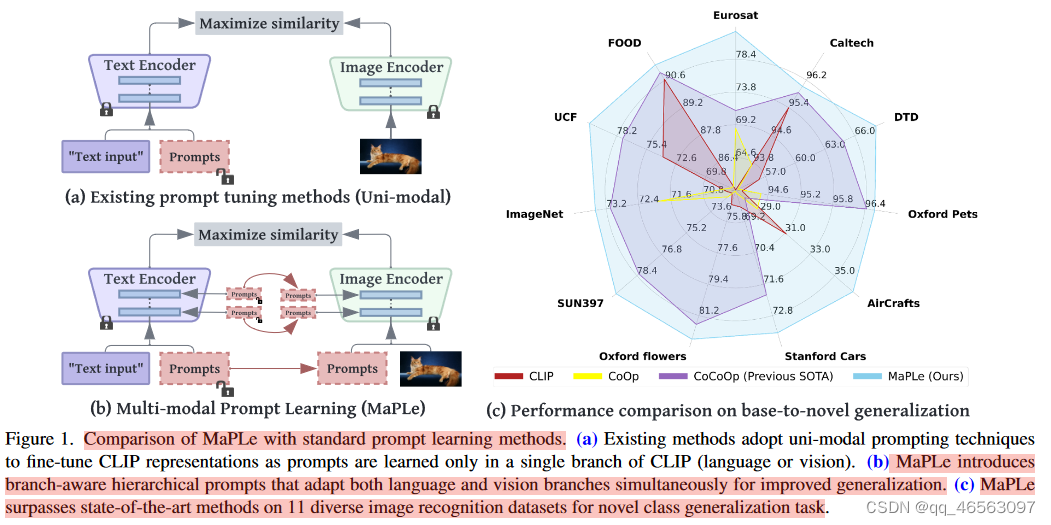
尽管CLIP对新概念的泛化是有效的,但它的大规模和训练数据的稀缺性(例如,few-shot设置)使得对下游任务的完整模型进行微调是不可行的。这种微调也可能忘记在大规模预训练阶段获得的有用知识,并可能对下游任务造成过拟合的风险。为了应对上述挑战,已有的研究提出了语言提示学习,以避免手动调整提示模板,并提供了一种机制来适应模型,同时保持原始权值不变。受自然语言处理(NLP)的启发,这些方法仅探索CLIP中文本编码器的提示学习(图1:a),而与CLIP中同等重要的图像编码器一起进行适应选择仍然是文献中未探索的主题。
我们的动机源于CLIP的多模态特性,其中文本和图像编码器共存,并且都有助于正确对齐V-L模态。我们认为任何提示技术都应该完全适应模型,因此,仅为CLIP中的文本编码器学习提示不足以模拟图像编码器所需的适应。为此,我们着手实现提示方法的完整性,并提出了多模态提示学习(MaPLe),以充分微调文本和图像编码器表示,以便在下游任务中实现最佳对齐(图1:b)。我们在三个关键的代表性设置上进行了广泛的实验,包括基础到新类的泛化,跨数据集评估和域泛化,证明了MaPLe的强度。在base-to-novel泛化方面,我们提出的MaPLe在11个不同的图像识别数据集上优于现有的提示学习方法(图1:c),并且在novel类上实现了3.45%的绝对平均增益,在harmono -mean上超过了最先进的Co-CoOp方法,实现了2.72%的绝对平均增益。此外,MaPLe在跨数据集传输和领域泛化设置中表现出了良好的泛化能力和鲁棒性,与现有方法相比有了一致的改进。由于其流线型的架构设计,与Co-CoOp相比,MaPLe在训练和推理过程中表现出了更高的效率,而Co-CoOp由于其图像实例条件设计而缺乏效率。
本文的主要贡献:
1.我们提出了CLIP中的多模态提示学习,以更好地对齐视觉-语言表示。据我们所知,这是第一个用于微调CLIP的多模态提示方法。
2.为了将文本和图像编码器中学习到的提示联系起来,我们提出了一个耦合函数,以显式地将视觉提示与它们的语言对应物联系起来。它充当两种模式之间的桥梁,并允许梯度的相互传播以促进协同作用。
3.我们的多模态提示是通过视觉和语言分支的多个transformer blocks来学习的,以逐步学习两种模式的协同行为。这种深度prompt策略允许独立地对上下文关系建模,从而提供更大的灵活性来对齐视觉语言表示。
2.相关工作
Vision Language Models:语言监督与自然图像的结合使用是计算机视觉领域非常感兴趣的问题。与仅在图像监督下学习的模型相比,这些视觉语言(V-L)模型编码了丰富的多模态表示。最近,像CLIP , ALIGN , LiT, FILIP和Florence这样的V-L模型在广泛的任务中表现出了卓越的性能,包括few-shot和zero-shot视觉识别。这些模型使用来自网络的大量可用数据,以自监督的方式学习联合图像语言表示。例如,CLIP和ALIGN分别使用~ 400M和~ 1B图像-文本对来训练多模态网络。尽管这些预训练的V-L模型学习了广义表示,但有效地将它们适应下游任务仍然是一个具有挑战性的问题。通过使用定制的方法来适应V-L模型进行少量图像识别,目标检测和分割,许多工作已经证明了在下游任务上有更好的性能。在这项工作中,我们提出了一种新的多模态提示学习技术,以有效地适应CLIP用于few-shot和zero-shot视觉识别任务。
few-shot:对于新的类别,只需少量样本就能快速学习
zero-shot:在可见类上进行训练,完成对unseen classes的识别
Prompt Learning:句子形式的指令,称为文本提示,通常是提供给V-L模型的语言分支,使其更好地理解任务。可以为下游任务手工制作,也可以fine-tuning(微调)阶段自动学习。后者被称为“prompt learning”,首先被用于NLP领域,随后用于V-L和仅视觉模型。与Visual prompt tuning类似,我们也使用了深度“vision”提示,但是我们是多模态的。
Prompt Learning in Vision Language models:Full fine-tuning和Linear probing是使V-L模型(即CLIP)适应下游任务的两种典型方法。完整的微调导致先前学习的联合V-L表示降低,而线性探测限制了CLIP的zero-shot能力。为此,受NLP中的提示学习的启发,许多工作提出通过在端到端训练中学习prompt token来适应V-L模型。CoOp通过优化其语言分支的连续提示向量集来微调CLIP,以进行几次传输。Co-CoOp突出了CoOp在新类上的较差性能,并通过显式地对图像实例进行条件反射来解决泛化问题。[25]提出通过学习提示的分布来优化多组提示。b[18]通过学习提示来适应视频理解任务。[1]通过在视觉分支上提示,在CLIP上执行视觉提示调优。我们注意到,现有的方法遵循独立的单模态解决方案,并在CLIP的语言或视觉分支中学习提示,从而部分适应CLIP。在本文中,我们探讨了一个重要的问题:鉴于CLIP的多模态性质,完整提示(即在语言和视觉分支中)是否更适合适应CLIP?我们的工作是第一个通过调查多模态提示学习的有效性来回答这个问题,以改善视觉和语言表征之间的一致性。
Full fine-tuning: 用已知的网络结构和网络参数,修改output层为自己的层,微调最后一层前的若干层的参数,这样就有效利用了深度神经网络强大的泛化能力
linear-probe: 将最后一层替换为线性层,只训练线性层。常用来测试预训练模型性能
3.方法
我们的方法涉及fine-tuning预训练的多模态CLIP,以便通过提示进行上下文优化,更好地泛化到下游任务。图2显示了我们提出的MaPLe(多模式提示学习)框架的整体架构。与之前的方法[48,49]不同,MaPLe提出了一种联合提示方法,其中上下文提示在视觉和语言分支中都被学习。具体而言,我们在语言分支中附加可学习的上下文标记,并通过耦合函数显式地在语言prompt上设置视觉prompt,以建立它们之间的交互。为了学习分层上下文表示,我们在两个分支中通过跨不同traansformer blocks的单独可学习上下文提示引入深度提示。在微调期间,只学习上下文提示及其耦合函数,而模型的其余部分被冻结。下面,我们首先概述预训练的CLIP架构,然后介绍我们提出的微调方法。

3.1回顾CLIP
我们在预先训练的视觉语言(V-L)模型CLIP上构建我们的方法,CLIP由文本和视觉编码器组成。与现有提示方法一致[48,49],我们使用vision transformer( ViT)的CLIP模型。CLIP对图像I和相应的文本描述进行编码,如下所述。
Encoding Image:图像编码器V有K个transformer layers。先将图像I分割成M个固定大小的patches,这些patches投影到patch embeddings E0,patch embeddings Ei与一个可学习类(CLS)token ci一起作为第(i+1)个transformer blocks(V(i+1))的输入,并通过K个transformer blocks顺序处理。
![]()
为了获得最终的图像表示x,最后的transformer层(Vk)的class token Ck通过ImageProj被投影到公共的V-L潜在embedding空间(将单模态特征转为多模态特征),
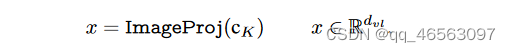
Encoding Text:CLIP文本编码器通过对单词进行标记并将其投影到词embeddings 来生成用于文本描述的特征表示。在每一阶段,Wi输入到文本编码分支(Li+1)的(i +1)个transformer块,
![]()
通过TextProj将最后一个变块的最后一个标记对应的文本embeddings投影到一个公共V-L潜在embedding space,得到最终的文本表示z,
![]()
Zero-shot Classification:对于zero-shot分类,文本提示是手工制作的,类标签y∈{1,2,…C}(如。, ' a photo of a <category>')具有C类。使用温度参数τ计算具有最高余弦相似分数(sim(·))的图像I对应的预测y,
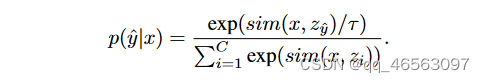
3.2MaPLe:Multi-modal Prompt Learning
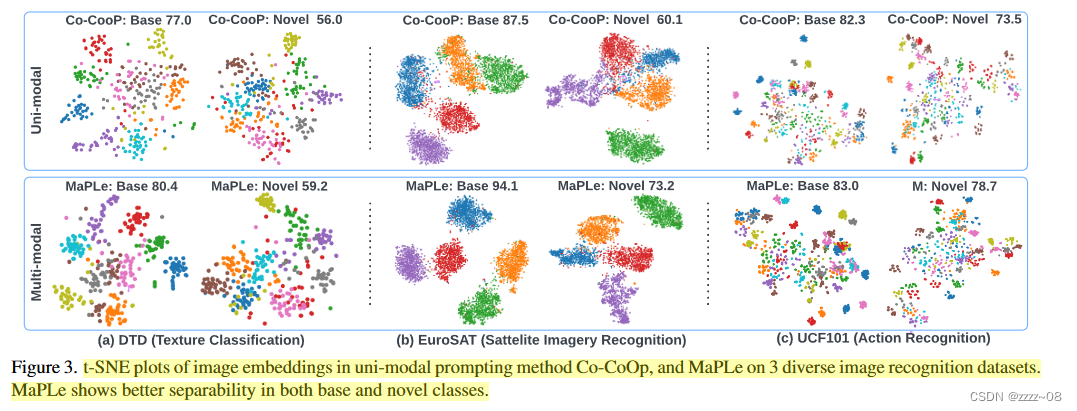
为了有效地微调CLIP下游图像识别任务,我们探索了多模态提示微调的潜力。我们认为,先前主要探索单模态方法的工作不太合适,因为它们不提供动态适应语言和视觉表示空间的灵活性。因此,为了实现提示的完整性,我们强调了多模态提示方法的重要性。在图3中,我们将MaPLe的图像embedding与最近最先进的工作Co-CoOp进行了可视化和比较。注意CLIP, CoOp和Co-CoOp的图像embedding将是相同的,因为它们不学习视觉分支中的提示。可视化结果表明,MaPLe的图像embedding具有更强的可分离性,这表明除了学习语言提示外,学习视觉提示可以更好地适应CLIP。
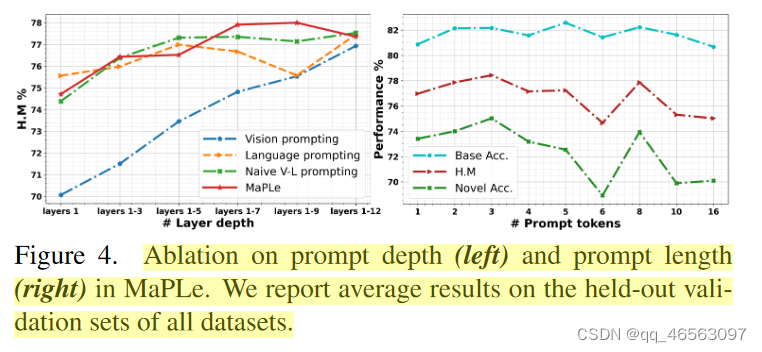
提示使得CLIP更好的适应。除了多模态提示外,我们发现在更深的transformer层中学习提示以逐步建模阶段特征表示是必不可少的。为此,我们建议在视觉和语言分支的前J层(其中J < K)引入learnable token。这些多模态分层提示利用CLIP模型中嵌入的知识来有效地学习任务相关的上下文表示(见图4)。
3.2.1 Deep Language Prompting
为了学习语言上下文提示,我们在CLIP的语言分支中引入可学习标记{}
。输入embeddings现在遵循[
]的形式,其中
对应于固定的输入tokens。在语言编码器(Li)的每个transformer block中进一步引入新的learnable tokens,直到特定深度J,
![]()
后续的层处理前层的prompt,计算最后的文本表示z,
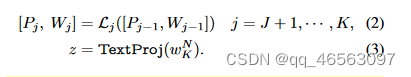
当J = 1时,可学习标记P仅应用于第一层transformer的输入,这种深度语言提示技术退化为CoOp。
3.2.2 Deep Vision Prompting
类似于深度语言提示,我们在CLIP的视觉分支中,在输入图像标记旁边引入b个learnable tokens{}
。在图像编码器(V)更深的transformer层中进一步引入新的可学习tokens,直到深度J。
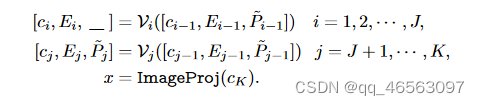
我们的深度提示提供了跨ViT架构中不同特征层次学习提示的灵活性。我们发现,与独立提示相比,跨阶段共享提示更好,因为由于连续的transformer blocks处理,特征更加相关。因此,与早期阶段相比,后期阶段不提供独立学习的补充提示。
3.2.3 Vision Language Prompt Coupling
我们认为,在提示调优中,必须采用多模态方法,同时适应CLIP的视觉和语言分支,以实现上下文优化的完整性。一个简单的方法是将深度视觉和语言提示结合起来,在同一个训练计划中学习语言提示P和视觉提示。我们将这种设计命名为“独立V-L提示”。虽然该方法满足了提示的完整性要求,但由于视觉和语言分支在学习任务相关上下文提示时没有相互作用,因此该设计缺乏视觉和语言分支之间的协同作用。
为此,我们提出了一种分支感知的多模态提示,通过在视觉和语言两种模态之间共享提示来协调CLIP的视觉和语言分支。语言提示符被引入到语言分支直到第J个变压器块,类似于公式1-3所示的深度语言提示。为了保证V-L提示符之间的相互协同作用,通过视觉到语言的投影,将语言提示符P投影出来,得到视觉提示符,我们称之为V-L耦合函数F(·),使得。耦合函数是作为一个线性层实现的,它将d
维输入映射到d
。这作为两种模式之间的桥梁,从而鼓励梯度的相互传播。
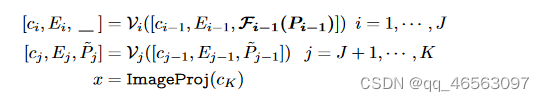
与独立的V-L提示不同,对P的显式地调节有助于在两个分支之间的共享embedding空间中学习提示,从而促进相互协同。
4.实验
4.1基准设置
从基类到新类的泛化:我们评估MaPLe的泛化性,并遵循zero-shot设置,将数据集分为基本类和新类。该模型仅在few-shot设置下的基类上进行训练,并在基本类别和新类别上进行评估。
跨数据集评估:为了验证我们的方法在跨数据集传输中的潜力,我们直接在其他数据集上评估我们的ImageNet训练模型。与Co-CoOp一致,我们的模型以few-shot的方式在所有1000个ImageNet类上训练。
域泛化:我们评估了我们的方法在分布外数据集上的鲁棒性。与跨数据集评估类似,我们直接在另外四个图像上测试我们的ImageNet训练模型。
数据集:为了从基本类到新类的泛化和跨数据集评估,在11个图像分类数据集上评估了我们的方法的性能,这些数据集涵盖了广泛的识别任务。这包括两个通用对象数据集,ImageNet和Caltech101 ;5个细粒度数据集,OxfordPets、StanfordCars、Flowers102、Food101和FGVCAircraft ;场景识别数据集SUN397 ;动作识别数据集UCF101 ;纹理数据集DTD和卫星图像数据集EuroSAT。为了进行域泛化,我们使用ImageNet作为源数据集,并使用ImageNetV2、Image等四个变体作为目标数据集。
实现细节:我们在所有的实验中都使用了few-shot训练策略,每个类随机抽取16张图片。我们在预训练的ViT-B/16 CLIP模型上应用提示微调,其中dl = 512, dv = 768和dvl = 512。对于MaPLe,我们将提示深度J设置为9,语言和视觉提示长度设置为2。所有模型在单个NVIDIA A100 GPU上通过SGD优化器训练5个epoch,批大小为4,学习率为0.0035。我们报告了基础类和新类的精度及其谐波平均值(HM)在3次运行中的平均值。初始化第一层P0的语言提示使用模板“a photo of a <category>”的预训练CLIP词embedding,而对于后续层,它们是从正态分布随机初始化的。对于ImageNet所有1000个类作为源模型训练MaPLe,提示深度J设置为3,模型训练了2个epoch,学习率为0.0026。深度语言提示、深度视觉提示和独立V-L提示的超参数详见附录a。所有数据集的超参数都是固定的。
4.2 通过V-L prompts prompting CLIP
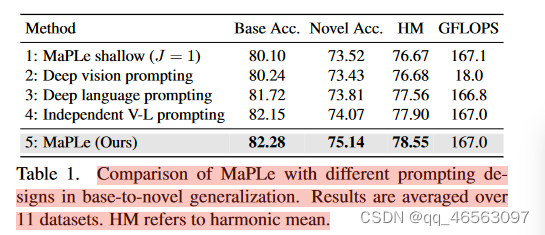
提示变体:评估了不同可能的提示设计选择的性能,作为我们提出的分支感知多模态提示MaPLe的消耗。这些变体包括shallow MaPLe、深度语言提示、深度视觉提示和独立的V-L提示。在表1中,我们给出了11个图像识别数据集的平均结果。shallow MaPLe(第1行)在泛化方面提供了对CoOp和Co-CoOp的持续改进。深度语言提示(第3行)比深度视觉提示(第2行)有所改善,表明在语言分支学习的提示能更好地适应CLIP。虽然单独结合上述两种方法(第4行)进一步提高了性能,但它很难从语言和视觉分支中获得综合效益。我们假设这是由于学习视觉和语言提示之间缺乏协同作用,因为它们在训练期间彼此不互动。同时,MaPLe与深度提示(第4行)结合了提示在两个分支中的好处,通过在语言提示上执行视觉提示的显式条件反射来强制交互。它提供了新类和基类准确度的改进,导致最佳HM为78.55%。我们探索了其他可能的设计选择,并在附录B中给出了消融。
4.3 基类到新类的泛化
Generalization to Unseen Classes:表3给出了MaPLe在11个识别数据集上从基本到新类的泛化设置下的性能。我们将其性能与CLIP zero-shot,以及近期的提示学习工作CoOp和Co-CoOp进行了比较。在CLIP的情况下,我们使用专门为每个数据集设计的手工提示。
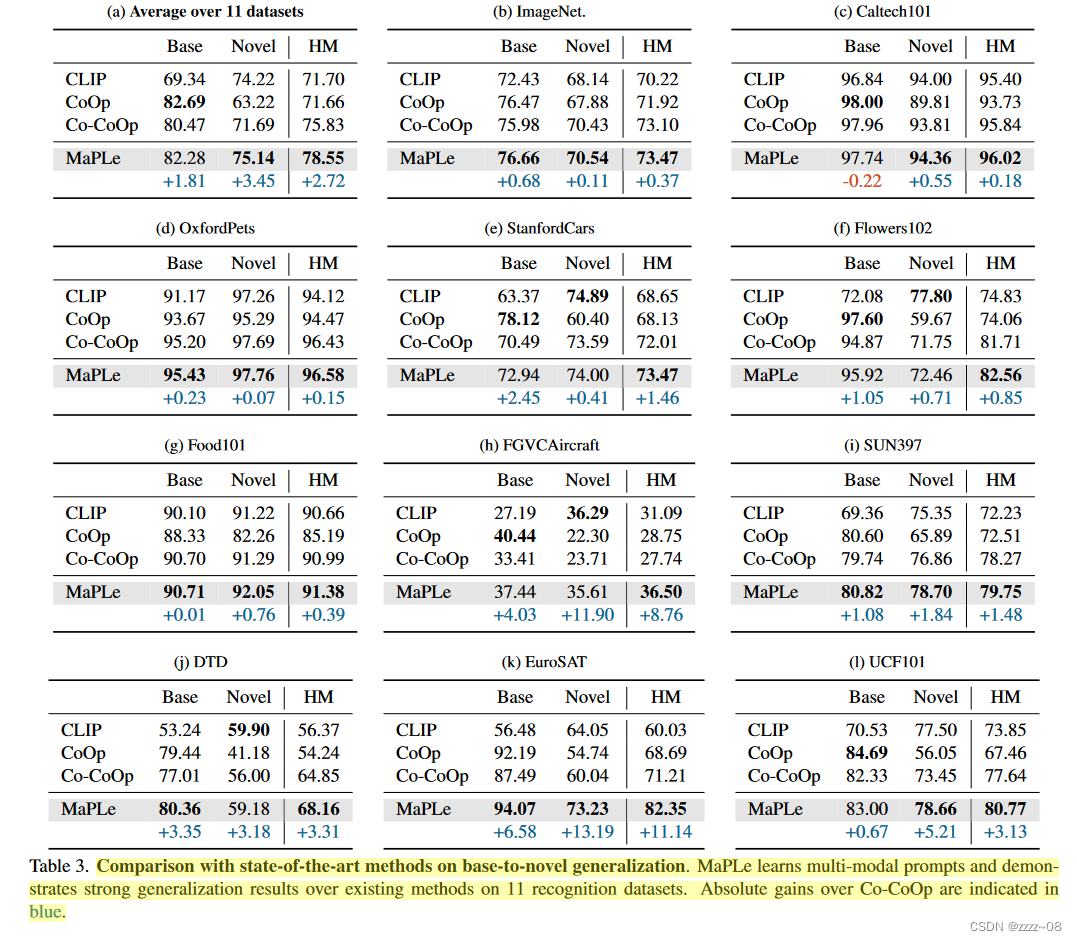
与最先进的Co-CoOp相比,MaPLe在所有11个数据集上的基本类和新类性能都有所提高,只有Caltech101的基本类性能略有下降。与Co-CoOp相比,在分支感知多模态提示的协同作用下,MaPLe在所有11个数据集上都能更好地泛化新类别,总体增益从71.69%提高到75.14%。当考虑到基础类和新类时,MaPLe的绝对平均增益比Co-CoOp高2.72%。
与CLIP相比,Co-CoOp仅在4/11数据集上有所提高,平均新分类准确率从74.22%降至71.69%。MaPLe是一个强大的竞争对手,它在6/11数据集上的新类别上提高了CLIP的准确性,平均增益从74.22%提高到75.14%。
基类上的泛化和性能:CoCoOp通过对图像实例进行条件反射来解决CoOp中的泛化问题,并在新类别上显示出显着的收益。然而,在基类上,它只在3/11数据集上比CoOp有所提高,平均性能从82.69%下降到80.47%。同时,提示的完整性帮助MaPLe在6/11数据集的基类上提高了CoOp,将平均基类准确率保持在82.28%左右,此外还提高了对新类的泛化。
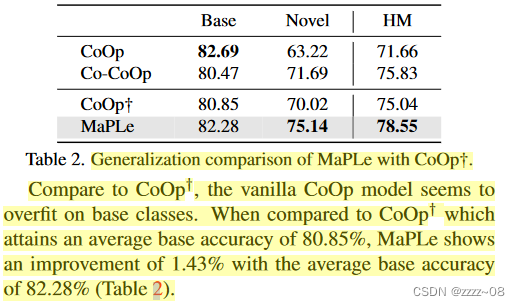
我们发现Co-CoOp的训练策略可以用于大幅提高CoCoOp的泛化性能(在新类中获得6.8%的增益)。因此,将我们的方法与CoOp†进行比较,CoOp†在CoCoOp设置下训练CoOp(更多细节请参阅附录A)。
与CoOp†相比,CoCoOp模型似乎在基类上过度拟合。与平均碱基精度为80.85%的CoOp†相比,MaPLe的平均碱基精度为82.28%,提高了1.43%(表2)。
4.4 跨数据集评估
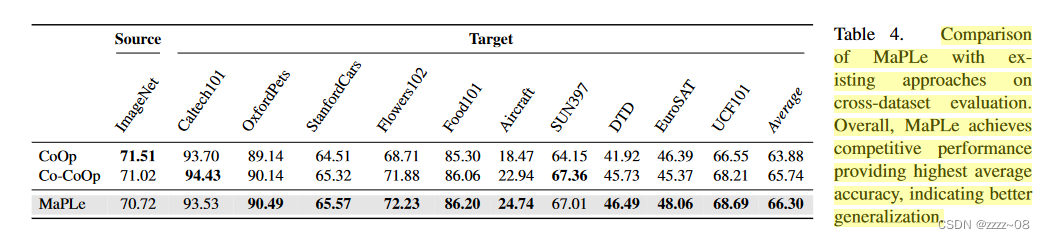
我们通过在所有1000个ImageNet类上学习多模态提示,然后直接将其转移到剩余的10个数据集上,来测试MaPLe的跨数据集泛化能力。表4显示了MaPLe、CoOp和Co-CoOp之间的性能比较。
在ImageNet源数据集上,MaPLe实现了与竞争方法相当的性能,但在9/10数据集中超过了CoOp,在8/10数据集中超越了Co-CoOp,表现出更强的泛化性能。总的来说,MaPLe表现出有竞争力的性能,平均准确率最高,为66.30%。这表明在MaPLe中使用分支感知的V-L提示有助于更好的泛化。
4.5 域泛化
与CoOp和Co-CoOp相比,MaPLe在分布外数据集上的泛化效果更好。我们评估了ImageNet训练模型对各种域外数据集的直接可移植性,并观察到,与表5所示的所有现有方法相比,它持续提升。这表明,利用多模态分支感知提示有助于MaPLe增强V-L模型(如CLIP)的泛化和鲁棒性。

4.6 消融实验
Prompt Depth:在图4(左)中,我们分别说明了MaPLe和提示深度J对语言和视觉分支深度的影响。一般来说,性能随着提示深度的增加而提高。我们注意到,当在模型特征空间已经成熟的冻结模型的更深层插入随机初始化提示时,性能灵敏度会增加。b[16]也报道了类似的趋势。由于早期的方法使用浅语言提示(J = 1),我们将我们的方法与深度语言提示进行比较。总体而言,MaPLe比深度语言提示实现了更好的性能,并且在深度为9时实现了最大性能。
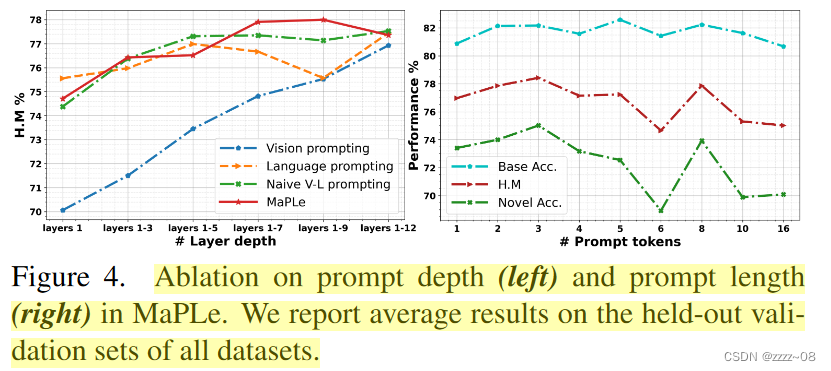
Prompt Length:图4(右)显示了提示符长度对MaPLe的影响。随着提示符长度的增加,基类上的性能一般保持不变,而新类的准确率则下降。这表明过拟合本质上损害了对新类别的泛化。
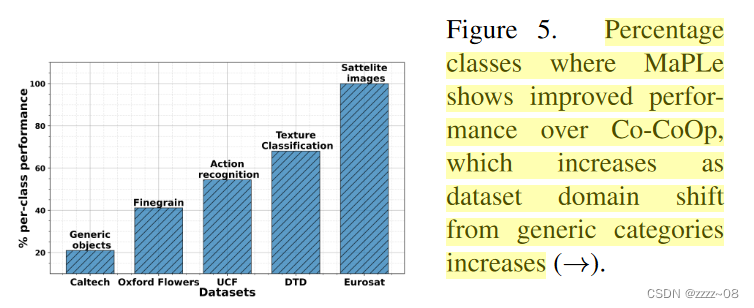
Effectiveness of Multi-modal Prompting:图5显示了对所选数据集按增加域移的顺序进行的每类精度分析。它表明,与Co-CoOp相比,MaPLe的性能增益在不同的数据集上有所不同。对于与CLIP预训练数据集有较大分布偏移的数据集,以及通常罕见且不太通用的视觉概念,MaPLe提供了比Co-CoOp显著的收益。附录C提供了进一步的详细分析。
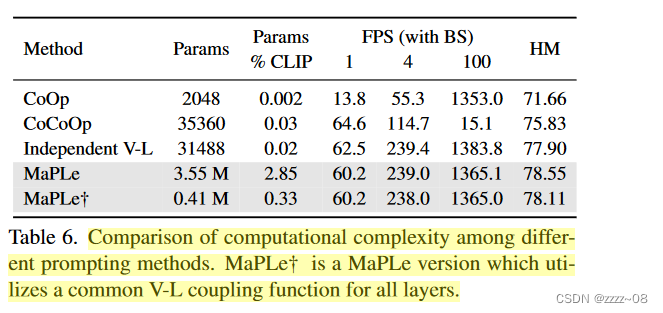
Prompting complexity:表6,显示与其他方法相比的MaPLe的计算复杂性。尽管MaPLe使用多模态提示,但其整体FLOPS(浮点运算)仅比CoOp和CoCoOp高0.1%。独立的V-L提示也提供了可比较的FLOP计数。就推理速度而言,Co-CoOp明显较慢,并且随着批大小的增加,FPS(每秒帧数)保持不变。相比之下,MaPLe没有这样的开销,并且提供了更好的推理和训练速度。此外,MaPLe提供了更好的收敛性,因为与Co-CoOp(5对10个时期)相比,它只需要一半的训练时期。MaPLe在CLIP的基础上增加了约2.85%的训练参数。为了研究性能增益是否主要归因于更多的参数,我们对MaPLe†进行了实验,它对所有层提示使用统一的V-L耦合函数。MaPLe†的参数比MaPLe小约9倍,也比现有方法有所改进。
MaPLe提供了更好的推理和训练速度。MaPLe†对所有层prompt使用统一的V-L耦合函数,比MaPLe少约9倍的参数,但性能差异不大。
5.总结
大规模V-L模型(例如CLIP)对下游任务的适应是一个具有挑战性的问题,因为大量的可调参数和有限的下游数据集大小。提示学习是一种高效且可扩展的技术,可以根据新的下游任务定制V-L模型。为此,目前的提示学习方法要么只考虑视觉方面的提示,要么只考虑语言方面的提示。我们的工作表明,对视觉和语言分支进行提示是至关重要的,以使V-L模型适当地适应下游任务。此外,我们提出了一种策略,通过在不同的transformer阶段将视觉提示明确地限制在文本提示上,来确保视觉语言模式之间的协同作用。我们的方法提高了对新类别、跨数据集迁移和具有域迁移的数据集的泛化能力。
这篇关于MaPLe: Multi-modal Prompt Learning的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






