本文主要是介绍深度之眼Paper带读笔记NLP.17:GNMT,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 前言
- 第一课 论文导读
- 神经机器翻译简介
- 神经机器翻译相关方法(之前有,看带读15课)
- 多层LSTM模型
- Attention
- 处理OOV词
- 前期知识储备
- 第二课 论文精读
- 论文整体框架
- 模型
- 残差连接
- 双向LSTM
- 束搜索
- 实验和结果
- 数据集
- 实验结果
- 讨论和总结
前言
Google’s Neural Machine Translation System:Bridging the Gap between Human and Machine Translation
谷歌的神经机器翻译系统
作者:Yonghui Wu et al.
单位:Google
发表会议及时间:2016
在线LaTeX公式编辑器
a. 神经机器翻译的概念
神经机器翻译就是通过端对端的神经网络使得机器能够自动将一种语言的句子翻译成另外一种语言的句子。
b. 三种神经机器翻译模型
了解基于多层LSTM、attention、处理OOV词的三种神经机器翻译模型。
c. 了解Seq2Seq模型
当前的神经机器翻译模型都是基于端对端的Seq2Seq结果,包含一个Encoder和一个Decoder,Encoder将源语言压缩成一个向量,而Decoder利用源语言压缩得到的向量生成目标句子。
d. 谷歌的神经机器翻译系统
理解谷歌神经机器翻译系统的细节,包括模型的总体结构,attention,残差连接,底层的双向LSTM以及改进的Beam Search等。
e. 谷歌神经机器翻译系统实验结果
深入理解论文突出的谷歌神经机器系统的实验结果。
第一课 论文导读
神经机器翻译简介
神经机器翻译:通过端对端的神经网络模型将一种语言的句子翻译成另外一种语言。
意义:解决人与人之前的交流问题。

神经机器翻译相关方法(之前有,看带读15课)
多层LSTM模型
输入逆序。

Attention
来自之前读过的:Neural Machine Translation by Jointly Learning to Align and Translate
Encoder:单层双向LSTM。(就是下图中下面两层方框)
Decoder:
对于输出:
p ( y i ) = g ( y i − 1 , s i , c i ) p(y_i)=g(y_{i-1},s_i,c_i) p(yi)=g(yi−1,si,ci)
对于 c i c_i ci:
c i = ∑ j = 1 T x a i j h j , a i j = e x p ( e i j ) ∑ k = 1 T x e x p ( e i k ) c_i=\sum_{j=1}^{T_x}a_{ij}h_j,a_{ij}=\frac{exp(e_{ij})}{\sum_{k=1}^{T_x}exp(e_{ik})} ci=j=1∑Txaijhj,aij=∑k=1Txexp(eik)exp(eij)
w h e r e e i j = a ( s j − 1 , h j ) where \space e_{ij}=a(s_{j-1},h_j) where eij=a(sj−1,hj)
处理OOV词
OOV词就是out-of-vocabulary词,文中提出在翻译之后,对于翻译结果中的unk词找到源语言句子中的对应词,然后直接将源语言中对应unk词的词用词典翻译。

REF:Addressing the Rare Word Problem in Neural Machine Translation
前期知识储备
了解Seq2Seq模型
·本文讲的谷歌机器翻译模型就是基于Seq2Seq模型,Seq2Seq模型有一个Encoder和一个Decoder,可以参考:
https://zhuanlan.zhihu.com/p/57155059
第二课 论文精读
论文整体框架
这个论文非常长长长长的(23 pages)
摘要
1.介绍
2.相关工作
3.模型
4.词分割方法(如何处理OOV)
5.目标函数
6&7.加速推理&解码器
8&9.实验结果&结论
模型
模型分别由8层encoder和8层decoder组成

先看左边的encoder,最下面两层是双向LSTM(就是GPU1和GPU2对应的那里),后面每层都是单向的LSTM。最后的结果用于最后的Attention。Attention是单隐层的感知机(中间蓝色部分),就是一个隐层一个输出层。然后接上decoder中的y1到y3得到的结果用于后面的每一层。
s t = A t t e n t i o n F u n c t i o n ( y t − 1 , x t ) , ∀ t , 1 ≤ t ≤ M s_t=AttentionFunction(y_{t-1},x_t),\forall t,1≤t≤M st=AttentionFunction(yt−1,xt),∀t,1≤t≤M
p t = e x p ( s t ) ∑ t = 1 M e x p ( s t ) , ∀ t , 1 ≤ t ≤ M p_t=\frac{exp(s_t)}{\sum_{t=1}^Mexp(s_t)},\forall t,1≤t≤M pt=∑t=1Mexp(st)exp(st),∀t,1≤t≤M
a i = ∑ t = 1 M p t ⋅ x t a_i=\sum_{t=1}^Mp_t\cdot x_t ai=t=1∑Mpt⋅xt
残差连接
由于层比较多,为了防止梯度消失,加入了残差连接模块

c t i , m t i = L S T M i ( c t − 1 i , m t − 1 i , x t − 1 i ; W i ) c_t^i,m_t^i=LSTM_i(c^i_{t-1},m^i_{t-1},x^i_{t-1};W^i) cti,mti=LSTMi(ct−1i,mt−1i,xt−1i;Wi)
x t i = m t i x_t^i=m_t^i xti=mti
c t i + 1 , m t i + 1 = L S T M i + 1 ( c t − 1 i + 1 , m t − 1 i + 1 ; W i + 1 ) c_t^{i+1},m_t^{i+1}=LSTM_{i+1}(c_{t-1}^{i+1},m_{t-1}^{i+1};W^{i+1}) cti+1,mti+1=LSTMi+1(ct−1i+1,mt−1i+1;Wi+1)
其中i代表第几层, x t i x_t^i xti是t时刻 L S T M i LSTM_i LSTMi的输入, m t i m_t^i mti和 c t i c_t^i cti分别是t时刻 L S T M i LSTM_i LSTMi隐层状态和记忆单元状态,加入了残差连接后,上面的公式变成了:
c t i , m t i = L S T M i ( c t − 1 i , m t − 1 i , x t − 1 i ; W i ) c_t^i,m_t^i=LSTM_i(c^i_{t-1},m^i_{t-1},x^i_{t-1};W^i) cti,mti=LSTMi(ct−1i,mt−1i,xt−1i;Wi)
x t i = m t i + x t i − 1 x_t^i=m_t^i+x_t^{i-1} xti=mti+xti−1
c t i + 1 , m t i + 1 = L S T M i + 1 ( c t − 1 i + 1 , m t − 1 i + 1 ; W i + 1 ) c_t^{i+1},m_t^{i+1}=LSTM_{i+1}(c_{t-1}^{i+1},m_{t-1}^{i+1};W^{i+1}) cti+1,mti+1=LSTMi+1(ct−1i+1,mt−1i+1;Wi+1)
这样梯度就可以不通过LSTM直接从前一层传到后一层。
双向LSTM
一个LSTM是正向,一个LSTM是反向的,然后把他们的结果进行concat,双向LSTM计算量是比较大的,所以没有在所有后面的模型结构中使用,而是在第一层使用了。

束搜索
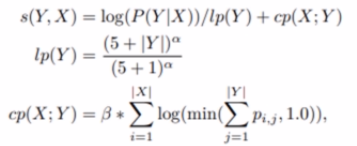
其中lp是让模型倾向于长句结果例如:

cp是在等长结果的情况下,倾向于每个结果与原文的每个词更加匹配的结果,例如:

两个超参数α和β变化与结果的关系
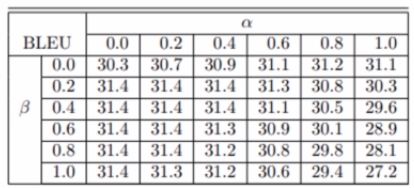
实验和结果
数据集
WMT English to French:包含36M英语到法语的双语语料,是机器翻译领域最常用的语料之一。
WMT English to German:包含5M英语到德语的双语语料,机器翻译领域最常用的
实验结果
结果解读老师的mic听得要吐血,自己看文章吧。




讨论和总结
本篇论文的主要贡献?
本文提出的GNMT使用多种技术大大超越了传统的基于短语的统计翻译模型。
GNMT的优点?
GNMT是使用当时神经机器翻译的集大成者,使用多种神经机器翻译技术大大超越了PBMT(传统基于统计的机器翻译模型)。
后来的改进模型?
后面的改进有改进LSTM,有改进Beam Search,还有词分割等等。
创新点:
A.提出了一种新的端对端神经翻译模型。
B.使用了多种技术使得其成为谷歌翻译的核心技术。
C.在多个数据集上达到了最好结果。
这篇关于深度之眼Paper带读笔记NLP.17:GNMT的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




