本文主要是介绍【单目3D检测】:SMOKE论文,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 1 网络结构
- 1.1 Backbone
- 1.2 检测模块
- key-point(heatmap)分支
- 3D box 回归分支
- 2. 损失函数loss
- 2.1 keypoint分类损失
- 2.2 3D box回归损失
- 3. 数据增广
- 实验结果
- 参考

论文: SMOKE: Single-Stage Monocular 3D Object Detection via Keypoint Estimation
github: https://github.com/lzccccc/SMOKE
- SMOKE 延续了
centernet的key-point做法,认为2D 检测模块是多余的,只保留了 3D 检测模块。其预测投影下来的 3D 框中心点和其他属性变量,从而得到 3D 框,参考Disentangling Monocular 3D Object Detection对预测属性进行了loss 解耦。这个简单的结构收敛较快且推理耗时较小。- 提出一种
端到端的单目 3D 目标检测的方法,该方法具有较为简洁的网络结构- 在 2019.11.12 提交的时候,SMOKE 在 KITTI 数据集上优于所有当时的最先进的单目 3D 目标检测算法
解决的问题:
-
在SMOKE算法之前,一般基于region_based的RCNN或者RPN结构,基于得到的
2d proposals,结合后序结构推理出3dbox。一般是多阶段的算法。 -
SMOKE仅
3d模块,基于key-point直接回归3d属性,基于解耦loss来训练
1 网络结构

- SMOKE 的网络结构非常简洁,主要由 backbone 、关键点分类分支和 3D 框回归分支组成
- SMOKE 利用
DLA-34作为backbone提取特征,将特征图下采样到原图的1/4。输出的Featue map 通过两个独立的分支分别预测keypoint的类别以及回归3D box坐标。 - keypoint分支输出的分辨率为
(H/4,W/4,C),表示数据集中前景目标的类别个数 - 3D box回归分支输出的分辨率为
(H/4,W/4,8),表示描述3D边界框的8个参数:h,w,l,x,y,z,yaw。
1.1 Backbone
使用与 centernet 相同的 DLA-34 backbone来提取特征,唯一的改变就是将BN替换为GN(group norm),因为GN对batch size不那么敏感, 且对于训练噪声更加鲁棒,因此 SMOKE 将所有的 BN 操作全部换为 GN 操作, 图像经过Backbone输出特征尺寸为[H/4, w/4,C]。 DLA-34结构中包含多个cross path、下采样与上采样。如下图(Objects as Points):

1.2 检测模块
3d检测模块(head)分为两部分:(1)key-point分支,即heatmap分类分支;(2)3D box回归分支。结构图如下:
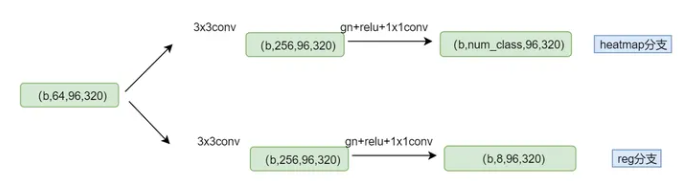
key-point(heatmap)分支
与centernet不同的是这里预测3d box中心点投影到2d图像上的点,而不是2d box的中心点,因为论文中直接抛弃了2d检测分支,而3d box中心点在2d图像上的投影点,可通过相机内参 K K K, 可完全恢复3d box中心点的三维坐标,所以这里用3d box投影下来的点更合适,

如图3,红色点为 2D 框中心点,而橙色点为 3D 点投影后的点。假设 [ x , y , z ] T [x,y,z]^T [x,y,z]T为物体在相机坐标系下的3D中心点, [ x c , y c ] T [x_c,y_c]^T [xc,yc]T为3D中心点投影到图像上的点。利用相机内参矩阵 K K K, 则这两个点的投影关系如下:

3D box 回归分支
回归分支主要任务是对heatmap上的keypoint 预测一组参数来构建3D box, 预测的参数为 ( x , y , z , l , w , h , θ ) (x,y,z,l,w,h,\theta) (x,y,z,l,w,h,θ), 其中, ( x , y , z ) ( x , y , z ) (x,y,z) 为 3D 框的中心点, ( l , w , h ) ( l , w , h ) (l,w,h) 为 3D 框的长宽高, θ \theta θ 为 3D 框的偏航角。论文中与ROI-10D和disentangling中类似,用8维的变量来表示: [ δ z , δ x c , δ y c , δ w , δ h , δ l , s i n a , c o s a ] [\delta_z, \delta_{x_c}, \delta_{y_c},\delta_w,\delta_h,\delta_l,sina,cosa] [δz,δxc,δyc,δw,δh,δl,sina,cosa], 都做成的预测偏移量形式来预测,来降低学习的难度
- δ z \delta_z δz:表示相机坐标系下深度depth偏移量offset, 根据从数据集中统计出平移平均值 μ z \mu_z μz, 度方差 σ z \sigma_z σz, 基于预测的深度偏移量 δ z \delta_z δz, 利用公式 z = μ z + σ z δ z z= \mu_z +\sigma_z\delta_z z=μz+σzδz, 得到最终的深度 z z z
- δ x c , δ y c \delta_{x_c}, \delta_{y_c} δxc,δyc 为 heatmap 中由于下采样引起的量化误差, 目标在中心点相机坐标系的位置 ( x , y , z ) (x,y,z) (x,y,z), 可以利用2D图像上投影点 [ x c , y c ] T [x_c,y_c]^T [xc,yc]T 结合下采样产生的量化偏差 δ x c , δ y c \delta_{x_c}, \delta_{y_c} δxc,δyc, 并利用相机内参矩阵 K K K 来计算。

- δ w , δ h , δ l \delta_w,\delta_h,\delta_l δw,δh,δl : 为长宽高的偏移量,结合预先计算的逐类别统计的尺度平均值 [ h ‾ , w ‾ , l ‾ ] [\overline h,\overline w,\overline l] [h,w,l], 根据如下公式计算目标的长宽高尺寸:

这里使用e的幂次是为了保证正数乘到均值上,结果一定为正。实际在网络输出加了sigmoid来映射: - s i n α sinα sinα 和 c o s α cosα cosα : 基于以往的论文,作者选择回归观测角度 α \alpha α,而不是偏航角 θ \theta θ, 并且将 α \alpha α用 [ s i n a , c o s a ] [sina,cosa] [sina,cosa]来编码, 从而映射为连续值,是角度估计中的常见做法。通过以下公式可以计算角度 θ \theta θ, 关于角度的详细说明,参考:https://zhuanlan.zhihu.com/p/452676265

kitti中的alpha
这里有必要解释下kitti数据集中的 α \alpha α角,在下图中将小车沿着y轴顺时针旋转,待小车和camera连线与相机坐标系的z轴重合时停止,那么紫色的角是没有发生变化的,可以有: r _ y + p i / 2 − t h e t a = a l p h a + p i / 2 r\_y + pi/2 -theta =alpha + pi/2 r_y+pi/2−theta=alpha+pi/2, 整理后得: r _ y = a l p h a + t h e t a = a l p h a + a r c t a n ( x / z ) r\_y = alpha + theta = alpha +arctan(x/z) r_y=alpha+theta=alpha+arctan(x/z)
论文中作者给出yaw角 θ \theta θ的计算公式: θ = a z + a r c t a n ( x / z ) \theta =a_z +arctan(x/z) θ=az+arctan(x/z) ,这里的 θ \theta θ就是公式中的 r _ y r\_y r_y, a z a_z az就是kitti中的alpha。而smoke中定义的角度是 a x a_x ax,而smoke中定义的角度是 a z a_z az,现在来解释它俩的关系。参考1,参考2

来看下代码:smoke/smoke/modeling/smoke_coder.py:200
def decode_orientation(self, vector_ori, locations, flip_mask=None):locations = locations.view(-1, 3)rays = torch.atan(locations[:, 0] / (locations[:, 2] + 1e-7)) # 计算theta,用的gtalphas = torch.atan(vector_ori[:, 0] / (vector_ori[:, 1] + 1e-7)) # arctan(sin/cos)# get cosine value positive and negtive index.cos_pos_idx = torch.nonzero(vector_ori[:, 1] >= 0) # 比较cos值是否大于0,判断属于哪个区间cos_neg_idx = torch.nonzero(vector_ori[:, 1] < 0)alphas[cos_pos_idx] -= PI / 2 # 通过这步转换为kitti中的alpha角度定义alphas[cos_neg_idx] += PI / 2# retrieve object rotation y angle.rotys = alphas + rays # ry = alpha + theta
- rotys 就是 θ \theta θ:
- θ = r o t y s = r _ y \theta =rotys=r\_y θ=rotys=r_y =alphas + a z a_z az = alphas + rays = alphas+ a r c t a n ( x / z ) arctan(x/z) arctan(x/z)
- 其中: rays = a r c t a n ( x / z ) arctan(x/z) arctan(x/z) = torch.atan(locations[:, 0] / (locations[:, 2] + 1e-7))
- alphas = alphas =torch.atan(vector_ori[:, 0] / (vector_ori[:, 1] + 1e-7)), 其中
vector_ori= [ s i n a , c o s a ] [ sina,cosa] [sina,cosa] vector_ori= [ s i n a , c o s a ] [ sina,cosa] [sina,cosa] 中的 s i n a sina sina 和 c o s a cosa cosa 是在网络输出的 o s i n a o_{sina} osina和 o c o s a o_{cosa} ocosa做归一化后得到的。

最后,通过航角的旋转矩阵 R θ R_{\theta} Rθ, 物体的长宽高 [ h , w , l ] T [h,w,l]^T [h,w,l]T, 和中心点位置 [ x , y , x ] T [x,y,x]^T [x,y,x]T, 可构建 3D 边界框的 8 个角点(corners),公式如下:

2. 损失函数loss
损失函数由keypont分类损失和 3D box回归损失组成
2.1 keypoint分类损失
在heatmap上逐点应用focal loss,其中 s i , j s_{i,j} si,j 为heatmap上位置 ( i , j ) (i,j) (i,j)处的预测分数, y i , j y_{i,j} yi,j为真实的gt值由Gaussian Kernel分配。 β \beta β 和 γ \gamma γ是超参数, N N N 是每张图片中关键点的数量, 损失函数的定义如下:

总结:分类损失就是一个带focal loss的交叉熵损失
2.2 3D box回归损失
作者利用多步计算loss, 扩展了loss disentanglement思想。利用对3D box的尺寸 (h, w, l),中心点坐标(x, y, z) 和观测角度 α \alpha α, 产生了表征3D box 的8个角点。通过3个解耦L1 loss来计算损失。

其中 λ \lambda λ为权重的平衡系数,B为gt值, B ^ \hat{B} B^为预测值。
- 中心点(x,y,z)预测: 利用相机上的3D box中心点投影到图像平面上得到 [ x c , y c ] T [x_c,y_c]^T [xc,yc]T 和网络预测偏移量 δ x c , δ y c \delta_{x_c}, \delta_{y_c} δxc,δyc 以及已知的相机内参矩阵 K K K可以预测中心点。
- 观测角预测:使用 3D 框的 gt 中心点 ( x , y , z ) ( x , y , z ) (x,y,z) 和预测的观察角 a z ^ \hat{a_z} az^, 计算 θ \theta θ 角
- whl:长宽高使用预测值,其他值使用gt代入计算得到3d box的8个角点坐标。
其实就是,预测哪种类型的,那一类型的参数就使用预测值,其他使用真实值,从而计算得出 8 个预测角点的坐标
故最终损失为:

作者总结利用解耦的多步( multi-step)损失,可以显著提高检测精度
3. 数据增广
- heatmap分类分支: 包括水平翻转、多尺度、平移。
- 针对回归分支,只做了水平翻转。因为3d属性会随着缩放平移变化,需要对标签也做相应修改。
实验结果
- 仅用了60epoch就收敛,说明确实收敛更快了。
- test数据上比其他算法好,而val上不如其他算法,说明·smoke需要更多数据才能训好·,也说明kitti的val(当然这个val是人为划分的)和数据集划分不是很合理。

- 3.回归中
将不同属性的loss解耦后,性能提升明显。不同属性间会相互影响,这是单目检测或者多任务中经常面临的问题,而解耦loss是常用的解决方案。具体可以参考:Disentangling Monocular 3D Object Detection。

-
- 对比了GN和BN,GN效果更好,对batch-size不敏感,训练更快,BN对GN多消耗60%的时间

- 对比了GN和BN,GN效果更好,对batch-size不敏感,训练更快,BN对GN多消耗60%的时间
-
- 其他细节还有使用本文中sin/cos编码角度比四元数效果要好。本文无2d模块,将3d结果投影到图像作为2d检测结果,性能也不错

参考
https://zhuanlan.zhihu.com/p/452676265
https://blog.csdn.net/steven_ysh/article/details/124936613
这篇关于【单目3D检测】:SMOKE论文的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







