本文主要是介绍2m高分辨率土地利用分类矢量数据/植被类型分布数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
土地利用数据是在根据影像光谱特征,结合野外实测资料,同时参照有关地理图件,对地物的几何形状,颜色特征、纹理特征和空间分布情况进行分析,建立统一解译标志的基础之上,依据多源卫星遥感信息,结合实地调查和其他辅助数据,采用全数字化人机交互作业方法,主要根据对图像光谱、纹理、色调等的认识结合地形图目视解译而成;在内业建立解译标示与实现数据获取的基础上,结合外业实地考察验证,提高土地利用数据精度。
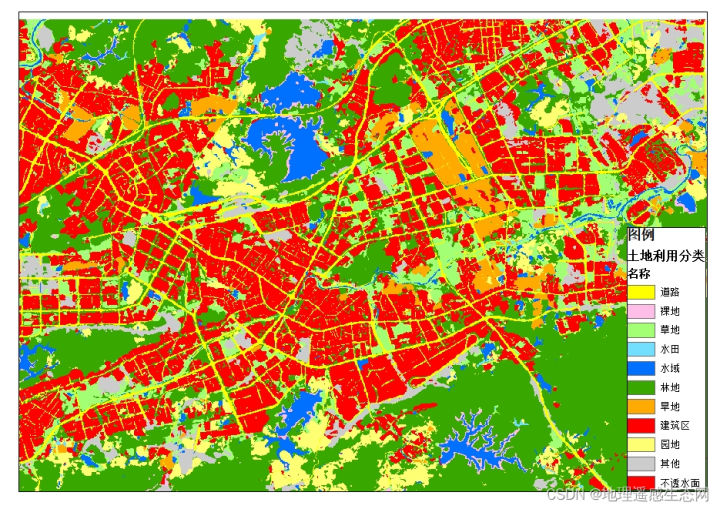
地理遥感生态网在对植被生长较好时间的GF1号等多源卫星影像下载、拼接、校正、配准等预处理以及高程等辅助信息的搜集整理的基础上,通过目视解译得到2米高精度土地利用数据。该数据主要包括以下类别(1)水田、(2)旱地、(3)园地、(4)林地、(5)草地、(6)建筑区、(7)道路、(8)不透水层、(9)农业大棚、(10)裸地、(11)水域。通过抽样人工检查,土地利用总体精度在90%以上。
原文链接:https://bbs.csdn.net/forums/gisrs?spm=1001.2014.3001.6682
这篇关于2m高分辨率土地利用分类矢量数据/植被类型分布数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







