本文主要是介绍Python 导入Excel三维坐标数据 生成三维曲面地形图(面) 3、线条平滑曲面但有条纹,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
环境和包:
环境
python:python-3.12.0-amd64包:
matplotlib 3.8.2
pandas 2.1.4
openpyxl 3.1.2
scipy 1.12.0
代码:
import pandas as pd
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from scipy.interpolate import griddata
import numpy as np# 读取Excel文件
df = pd.read_excel('煤仓模拟参数.xlsx')# 提取x、y、z坐标数据
x = df['X轴'].values
y = df['Y轴'].values
z = df['Z轴'].values# 设置网格大小和插值方法
grid_size = 100# 创建3D图形对象并绘制平滑曲面
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')# 生成网格坐标
grid_x, grid_y = np.mgrid[min(x):max(x):grid_size, min(y):max(y):grid_size]# 计算平滑曲面高度
grid_z = griddata((x, y), z, (grid_x, grid_y), method='cubic')#ax.scatter(x, y, z) # 也可以绘制原始的点云
ax.plot_surface(grid_x, grid_y, grid_z, cmap='viridis') # 绘制平滑曲面
# 设置x轴的刻度间隔
ax.set_xticks(np.arange(-7500, 7500, 2500)) # 从-7500到7500,步长为2500# 设置y轴的刻度间隔
ax.set_yticks(np.arange(-7500, 7500, 2500)) # 从-7500到7500,步长为2500# 设置z轴的刻度间隔
ax.set_zticks(np.arange(10000, 31000, 2500)) # 从10000到31000,步长为2500
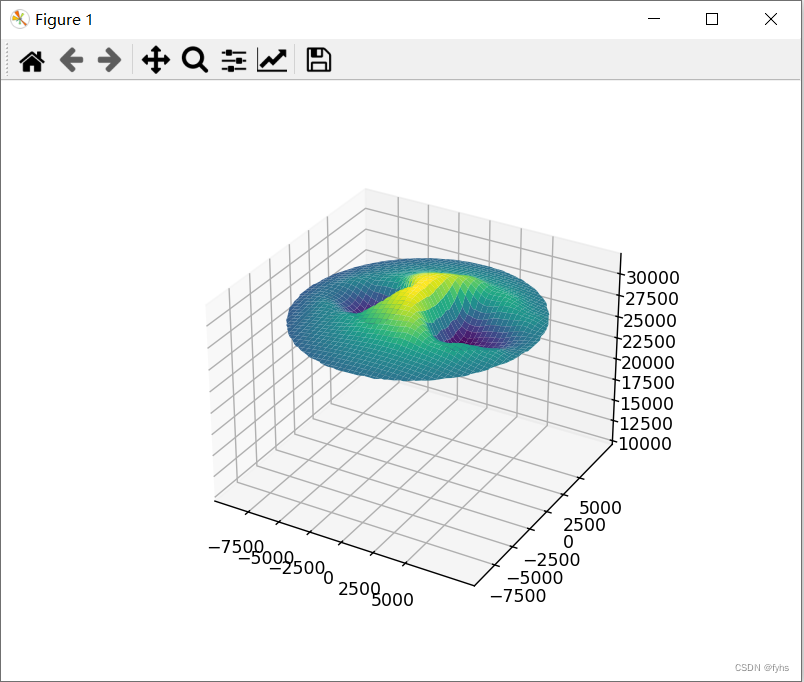
plt.show()效果图:
资源下载(分享-->资源分享):
链接:https://pan.baidu.com/s/1UlP0lsma8OWchfV5kstEFQ
提取码:kdgr
这篇关于Python 导入Excel三维坐标数据 生成三维曲面地形图(面) 3、线条平滑曲面但有条纹的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





