本文主要是介绍如何用BI工具对数据进行预处理?数据分析的这项技巧你必须掌握。,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在当今数字化时代,数据不仅是企业决策的基础,也是创新和发展的关键推动力。在面对庞大而复杂的数据集时,如何进行高效的预处理成为了数据分析领域中至关重要的一步。

在进行数据处理和分析的日常工作中,业务普遍使用Excel和SQL这两个经典的工具。然而,使用这两个工具进行数据处理,在实际的过程中可能遇到的一些问题:
Excel:
- 限制于数据规模: Excel在处理大规模数据时可能会变得缓慢且占用大量内存,导致性能下降。这对于处理数百万行的数据集可能是一个挑战。
- 手动操作误差: Excel通常需要手动进行数据清理和转换,这增加了人为出错的可能性。公式和数据操作的复制粘贴可能导致错误的结果,特别是在复杂的数据处理任务中。
- 版本控制问题: 在团队协作中,如果多个人同时编辑Excel文件,容易导致版本冲突,使得数据处理流程难以管理和跟踪。
- 有限的自动化能力: Excel的自动化功能相对有限,特别是在处理大型、复杂的数据集时,自动化处理和重复利用的能力相对较弱。
SQL:
- 复杂的语法: SQL语法相对复杂,对于初学者来说,学习和理解SQL可能需要一些时间。写复杂的查询语句可能容易出现错误,而调试这些错误可能会耗费时间。
- 处理字符串操作相对繁琐: 在SQL中,对字符串的处理相对繁琐,尤其是涉及到文本分割、合并和模糊匹配等操作时,可能需要编写复杂的代码。
- 性能问题: 对于大规模数据集,一些查询可能会导致性能问题,需要优化查询语句或者使用索引来提高效率。
- 难以处理非结构化数据: SQL更适用于关系型数据库,对于非结构化或半结构化数据的处理相对困难,需要在SQL外引入其他工具。
随着数据规模和复杂性的不断增加,以及对实时决策的需求日益迫切,业界逐渐转向更为高效、灵活的BI(商业智能)工具。对比于Excel和SQL在处理大规模、复杂数据时所面临的诸多挑战,BI工具以其强大的自动化和直观性,为用户提供了更为高效和便捷的数据处理解决方案。在这篇文章中,我们就将深入讲解使用BI工具进行数据预处理的关键技巧,希望能为已经引入BI工具的企业员工提供数据分析的帮助与思路!
示例中提到的数据分析模板分享给大家——
https://s.fanruan.com/427eu零基础快速上手,还能根据需求进行个性化修改哦
第一步:学会如何调整并简化数据结构
1、调整数据结构
在进行数据分析之前,往往需要对数据结构进行特定的处理,以便更有效地进行后续分析工作。原始数据通常并非直接符合我们分析的需求,因此必须进行一些行列转换的操作,以便调整数据的格式和结构,使其适应分析的要求。
在FineBI里,我们通过数据编辑内封装的功能“拆分行列”和“行列转换,迅速、灵活地实现对数据的调整和重组,从而达到快速获得所需分析结果的目的。通过“拆分行列”功能,我们能够将原始数据按照指定的规则进行拆分,从而分离出所需的信息。而“行列转换”则允许我们在数据集中对行与列进行灵活的转换,以满足不同的分析需求。
原数据结构:字段内容混杂,不利于开展分析
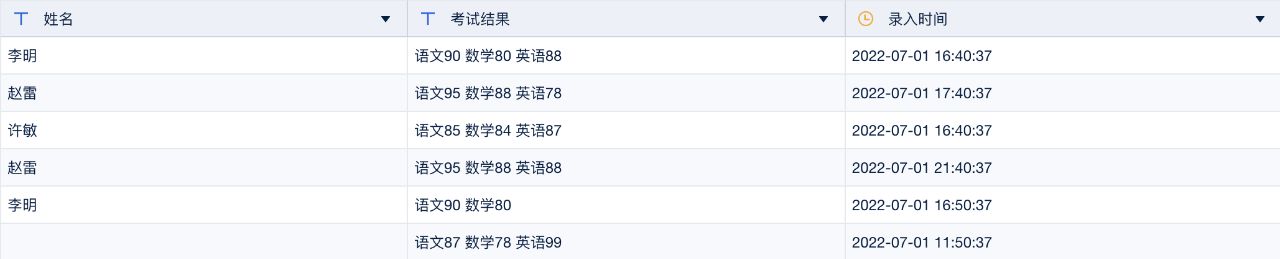
处理后数据结构:拆分行列并转换后,字段结构简单清晰
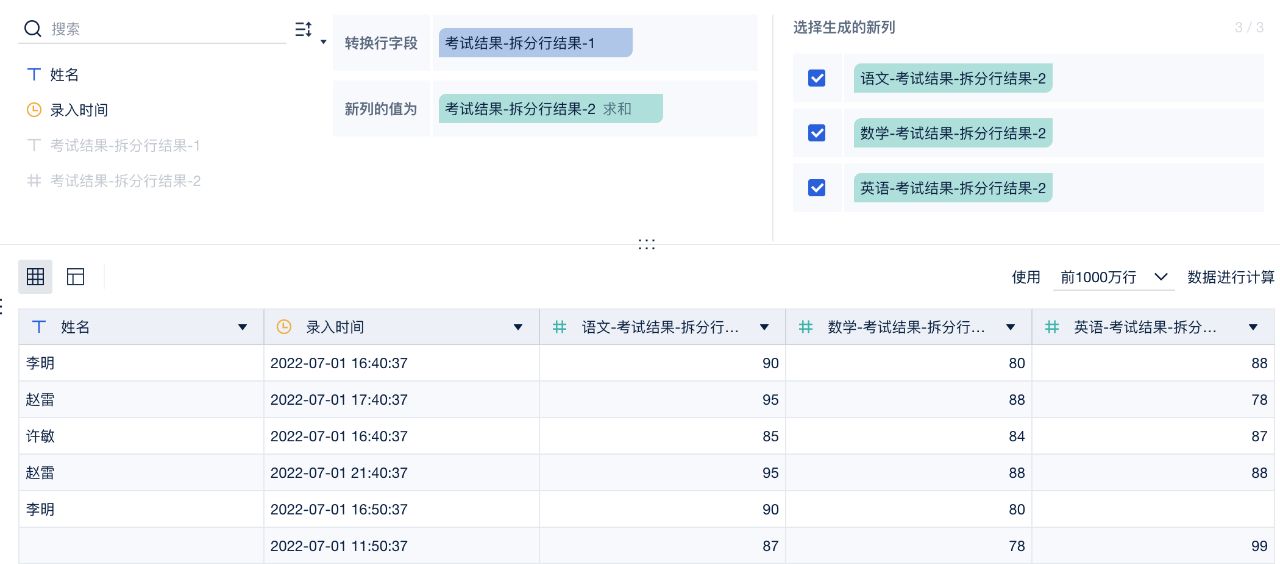
2、处理重复行数据
在实际的业务分析过程中,数据质量问题常常成为业务顺利进行分析的最主要障碍。其中,最为常见和棘手的问题之一就是重复行的存在。在处理这些重复行时,我们通常会面临两种主要情况,每一种都需要特定的处理方式。
首先,是那种删除任意一行都不会对分析结果产生实质性影响的情况,比如数据中存在类似“A、A、A”的重复行,而只需保留其中的一个“A”即可。针对这种情况,FineBI内封装了“删除重复行”功能,能够在业务分析中快速而便捷地实现这一操作。通过这个功能,我们能够轻松地剔除冗余的数据,以确保数据集的干净整洁,有利于后续准确的业务分析。
其次,还存在另一种情况,即需要有选择地保留特定的一行数据。例如,在系统中同一个客户可能有两行不同的数据记录,而在进行分析时,我们可能需要有针对性地选择保留最新录入的一条数据。在这种“A、B、C”中只需取A的场景下,我们首先通过对数据表进行排序,确保最新的数据位于数据表的顶部,再利用“删除重复行”的逻辑,只保留最上方的一行数据,从而达到筛选并保留特定行的目的。这一流程既简洁又有效,为业务分析提供了灵活而可控的数据清洗手段。而表头下拉菜单对字段内容进行统计的功能,也让检查重复行变得更加简单。
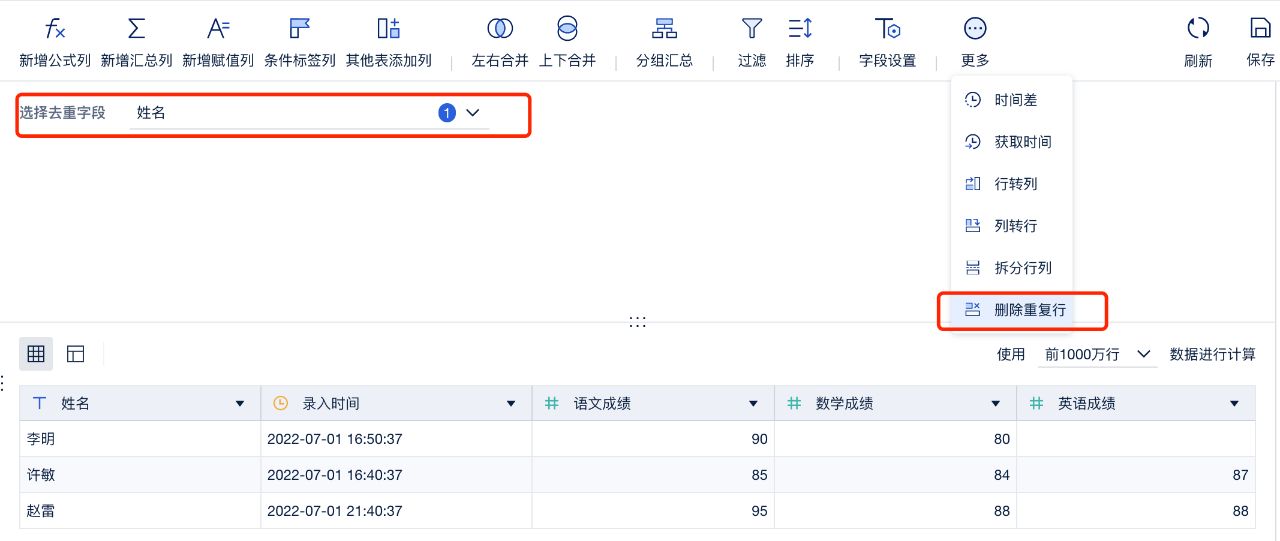
功能封装,选择去重字段快速去重
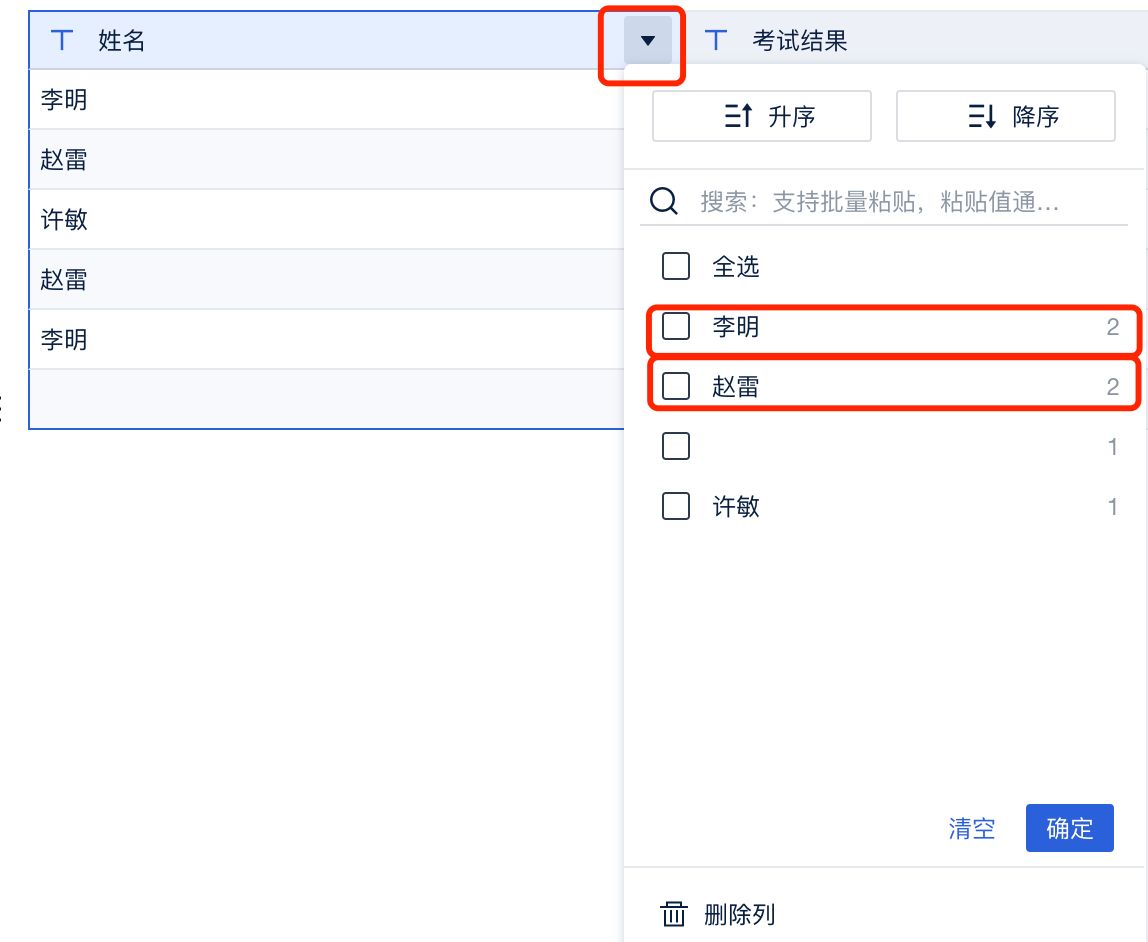
3、对null值的处理
在各种业务场景中,处理null值是一种不可避免的挑战,而不同的业务场景往往需要采用截然不同的处理策略。
当面临大规模数据集时,如果null值的出现相对较少,而这些空值并不会对总和或平均值等计算产生显著波动,那么我们通常可以直接忽略这些null值。这种处理方式在数据量庞大的情况下能够有效减少对计算结果的影响。
另一方面,对于那些在处理中希望将null值视为脏数据,从而整行剔除的情况,我们可以借助表头的快捷过滤功能迅速排除这些空值。这种方法通过使用表头的筛选工具,能够方便地将包含null值的整行数据剔除,从而确保数据的整洁性和准确性。
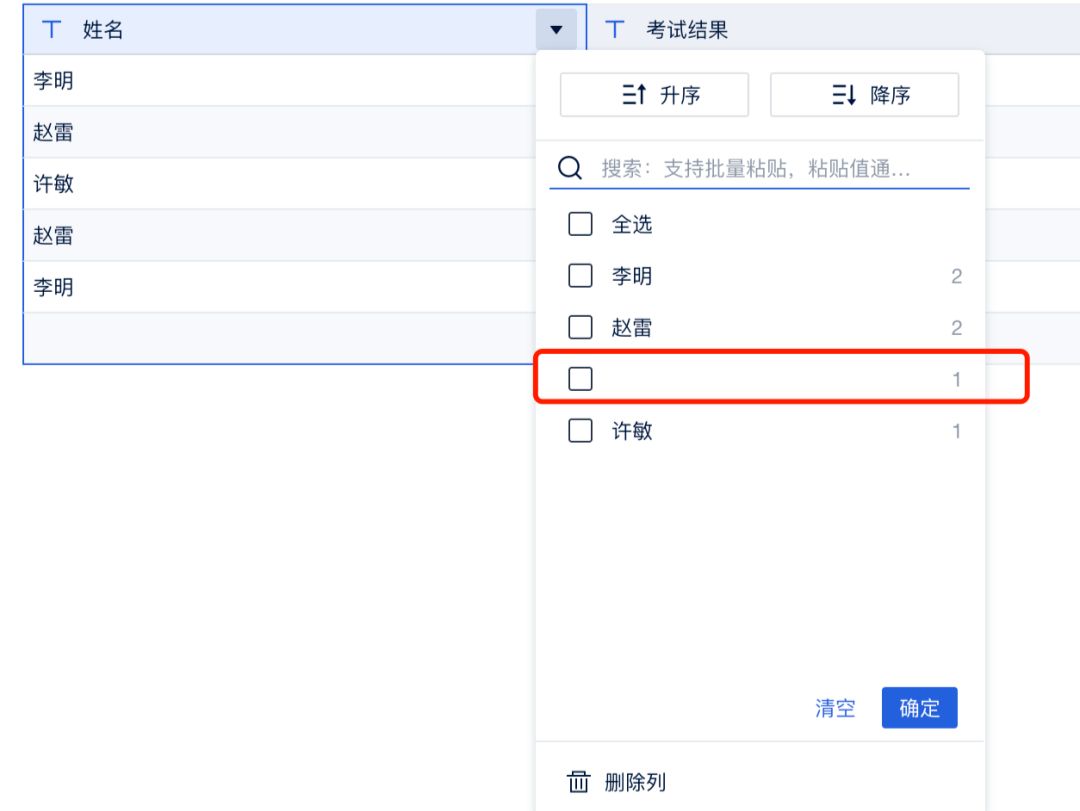
以上都是简单的场景处理,而在实际业务中,可能会遇到null值存在业务含义的情况。
例如示例中的数据,这位同学英语成绩为空的原因可能是他本身就因病没参加考试,此时既不能放着不管,也不能直接删去他的这一行数据。
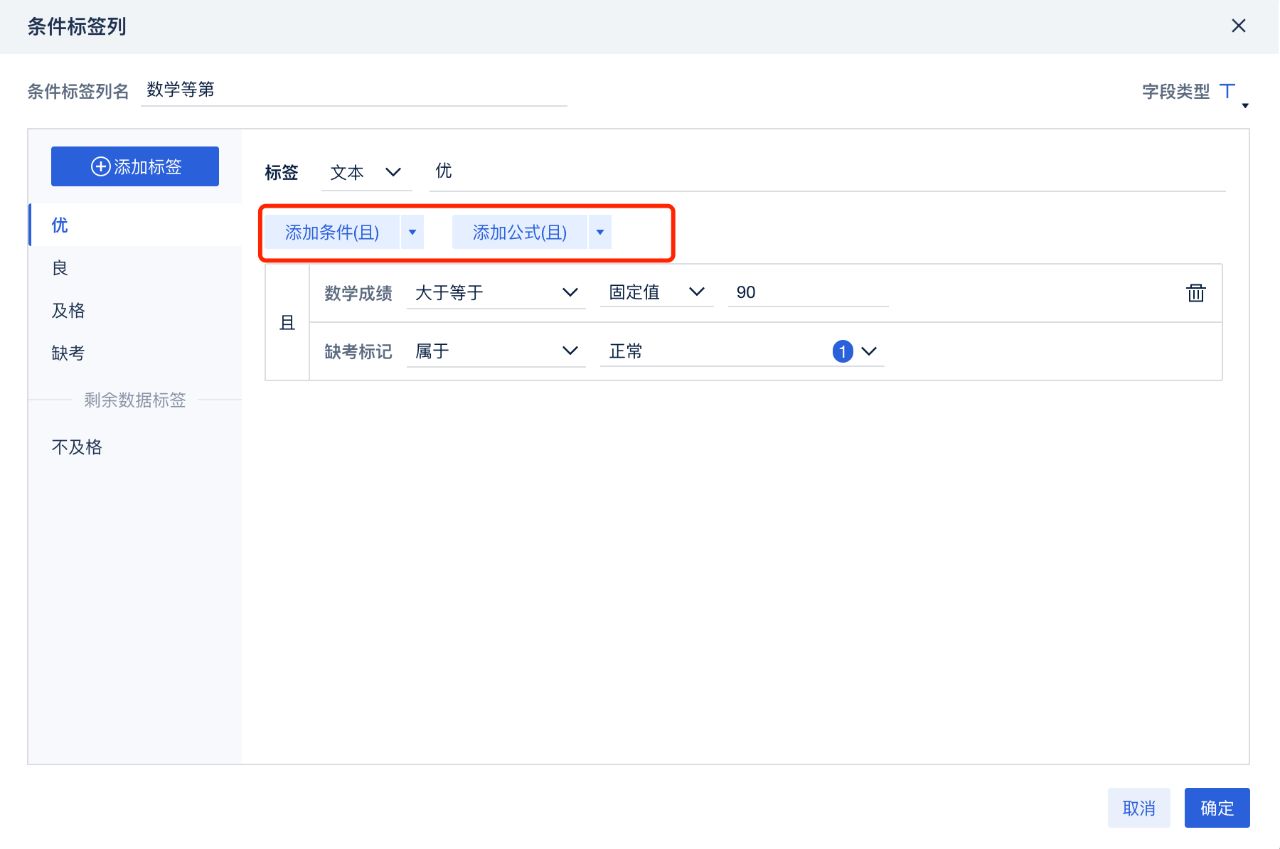
对于这种情况,我们要做的是针对某一类特殊情况打上对应的标签,以便在后续的分析中,有选择地过滤。在FineBI中,可以用“新增公式列”或者更方便的“条件标签列”来实现。
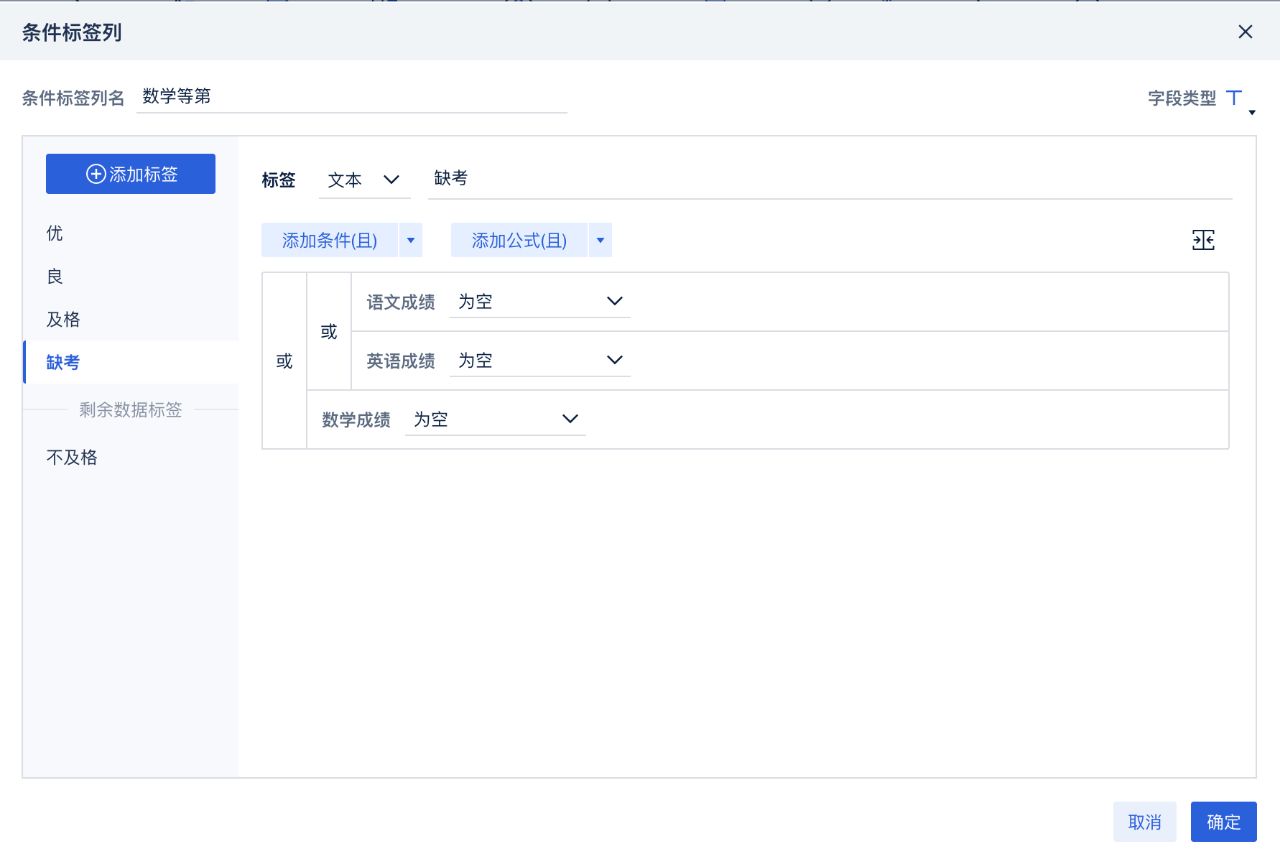
对存在空值成绩的同学打上缺考标签
第二步:学会如何对多张表进行合并分析
多表合并分析是指在数据分析过程中,将来自多个不同数据表的信息合并在一起进行综合分析的方法。在实际业务或研究中,数据通常分布在多个表格中,而多表合并分析的目的是为了获取更全面、更综合的信息,从而得出更深刻的结论。
这个过程通常包括以下几个步骤:
- 数据连接(Joining): 多表合并分析的第一步是通过某种关联关系将多个表格中的数据连接起来。这通常需要通过共享的关键字段(例如,客户ID、产品编号等)来建立连接,以确保正确关联相关数据。
- 数据合并(Merging): 一旦连接建立,接下来的步骤是将相关表格的数据合并成一个更大的数据集。这可以通过不同的合并方法实现,例如内连接、左连接、右连接或外连接,取决于分析者对数据的需求。
- 数据分析(Analysis): 合并后的数据集可以用于更深入的分析,例如生成统计指标、建立模型、进行趋势分析等。由于数据来自多个源头,多表合并分析有助于获得更全局的视角,使得分析结果更加全面和有说服力。
实际业务中,我们所需要的数据往往来自于多张表。在分析前,另外一个大难题就是,如何合并这些表。我们为刚上手BI的业务人员,归纳了以下两种合并的场景。
我们首先想象合并后表的状态,一种是表格上下扩展,分析的字段并没有增加,但是行数变多了。此时可以使用“上下合并”快速完成表的拼接。
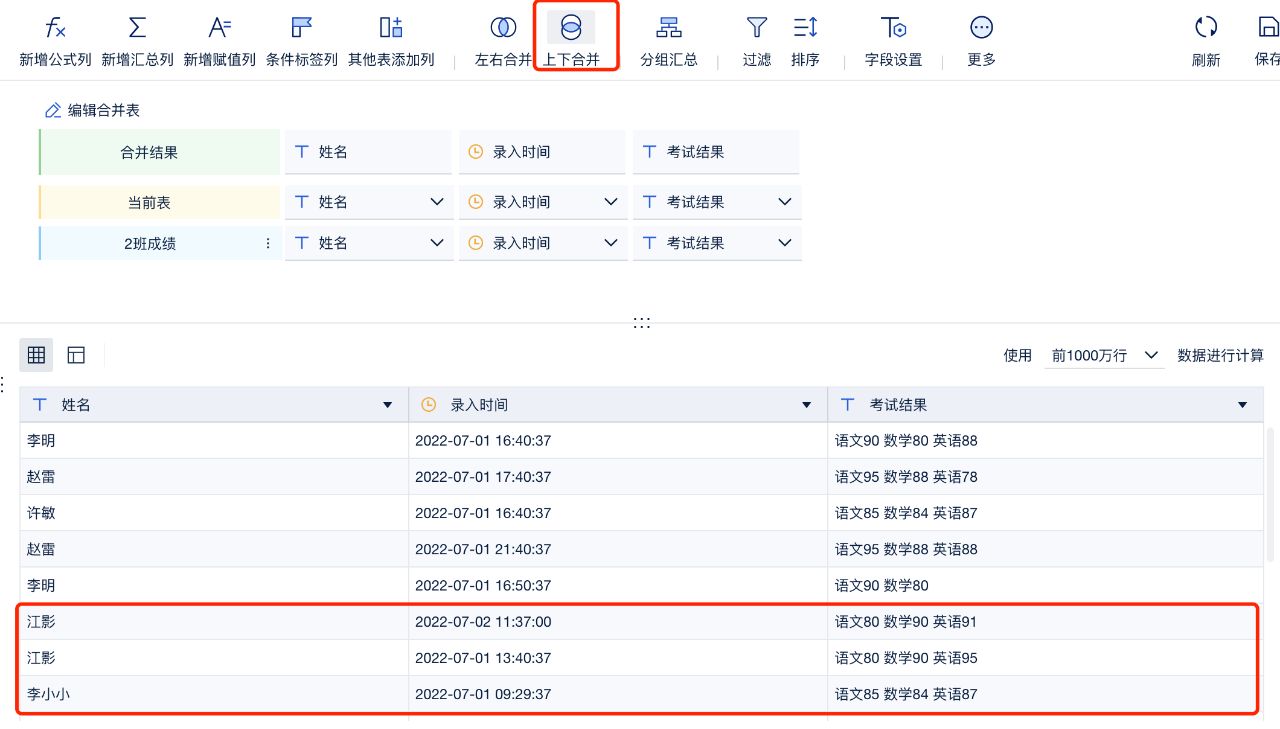
表格上下扩展,分析的字段并没有增加
另一种复杂的情况是合并后的表格是横向扩展的,即分析的字段变多了。
在讨论左右合并前,我们不妨先看看“其他表添加列”。
也许你对这个名字摸不着头脑,但是肯定不会对Excel的Vlookup、Sumif感到陌生。
没错,这个功能可以将其他表的指标字段进行聚合后合并(Sumif)或是查询对应的维度匹配到这张表中(Vlookup)。
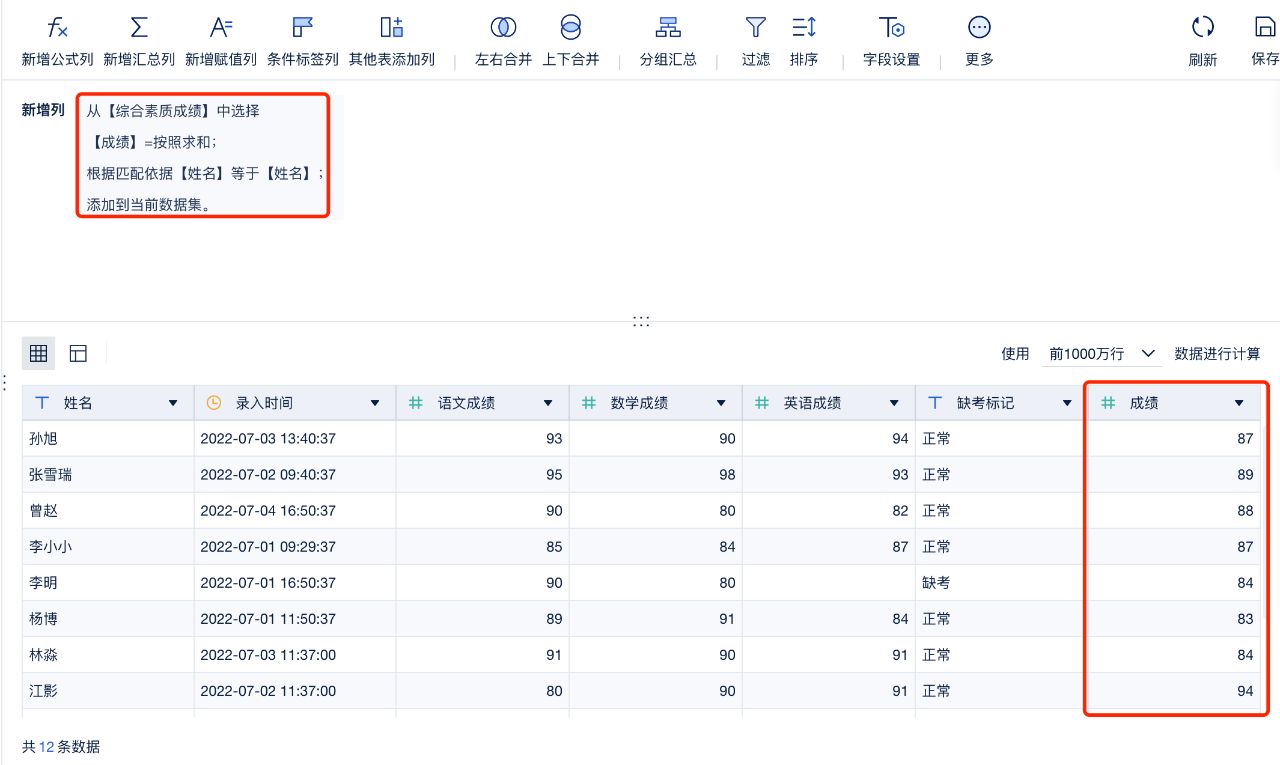
成绩根据要求求和后作为一个新的字段,依据“姓名”合并到本表中
而对SQL老练的玩家来说,left join、right join…..可能更加亲切,此时可以选择BI数据编辑中的“左右合并”功能,与SQL的逻辑一致,且比SQL的操作更加便捷,并不需要代码来实现,有基础的朋友可以很快上手。
第三步:学会新增计算及分析指标
在简化数据结构、并将多表进行合并处理后,我们需要停下来,审视一下自己所分析的问题,以及对应这个问题所需要的指标是否已经在表中了。
一般来说,事情可能没有这么顺利,当然这也在常理之中,比如在零售行业的分析中,往往需要我们自己计算毛利率、增长率等指标。
在开始分析前,我们可以将这些计算指标增添到数据表中。怎么做呢?
首先是最令人熟悉的“新增公式列”,这个功能和Excel中写公式一样,只需要输入对应的公式就能产生对应的字段。接着是一些常用计算的封装功能,“新增汇总列”可以帮助我们进行简单的聚合计算。
选择对应的分组以及计算方式,对指标进行计算
而“条件标签列”这个功能则解决了众多分析师日常最头疼的IF嵌套问题,不需要写嵌套了七八层的IF公式,只需通过鼠标配置不同的条件,就可以对数据赋予不同的标签(值)。
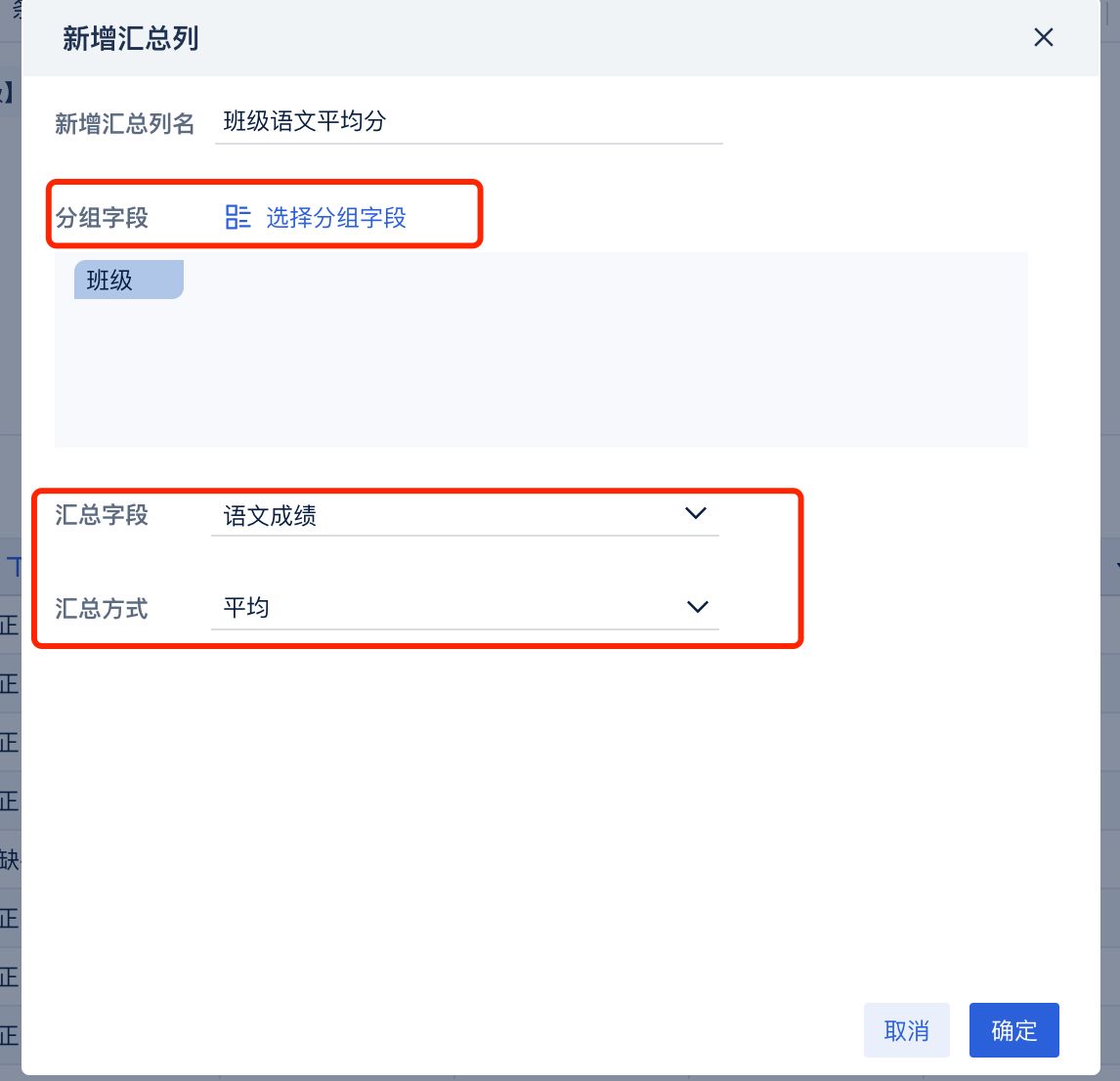
通过添加特定条件筛选数据并赋予对应的标签
第四步:学会对数据进行校验
刚接触BI的朋友遇到最大的问题不仅在于不理解BI许多功能的计算逻辑,更在于由此产生的对数据处理结果的不信任。“我这么做,出来的结果是对的吗?”是新手朋友最常问自己的一个问题。为了方便用户进行校验,数据编辑界面也内置了很多便利的功能。
1、表头数据校验
选中字段后,可以在左下角快速获得平均值、总和、记录数等数据,我们可以通过对熟悉的数据进行校验,结合经验来判断是否正确。
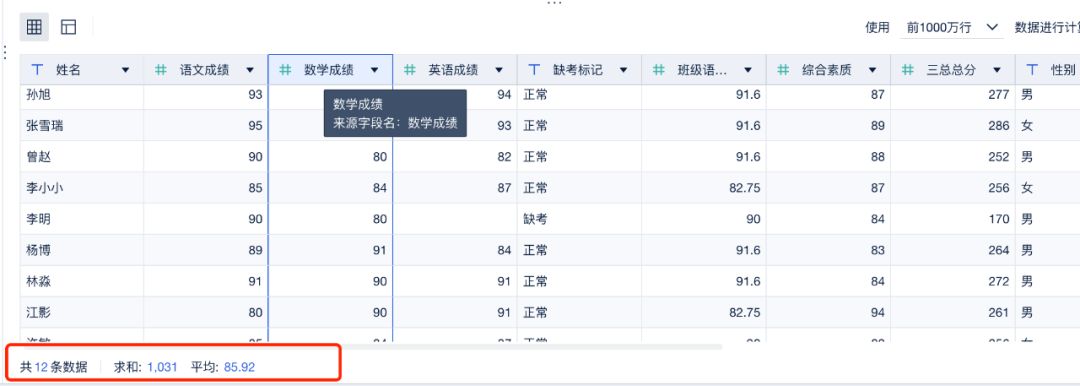
数学成绩字段校验得出平均分85.92,符合班级历史平均水平
2、步骤区关键步骤取消应用
BI可以在处理步骤间插入新的步骤,同时也可以设置某些步骤暂时取消生效。
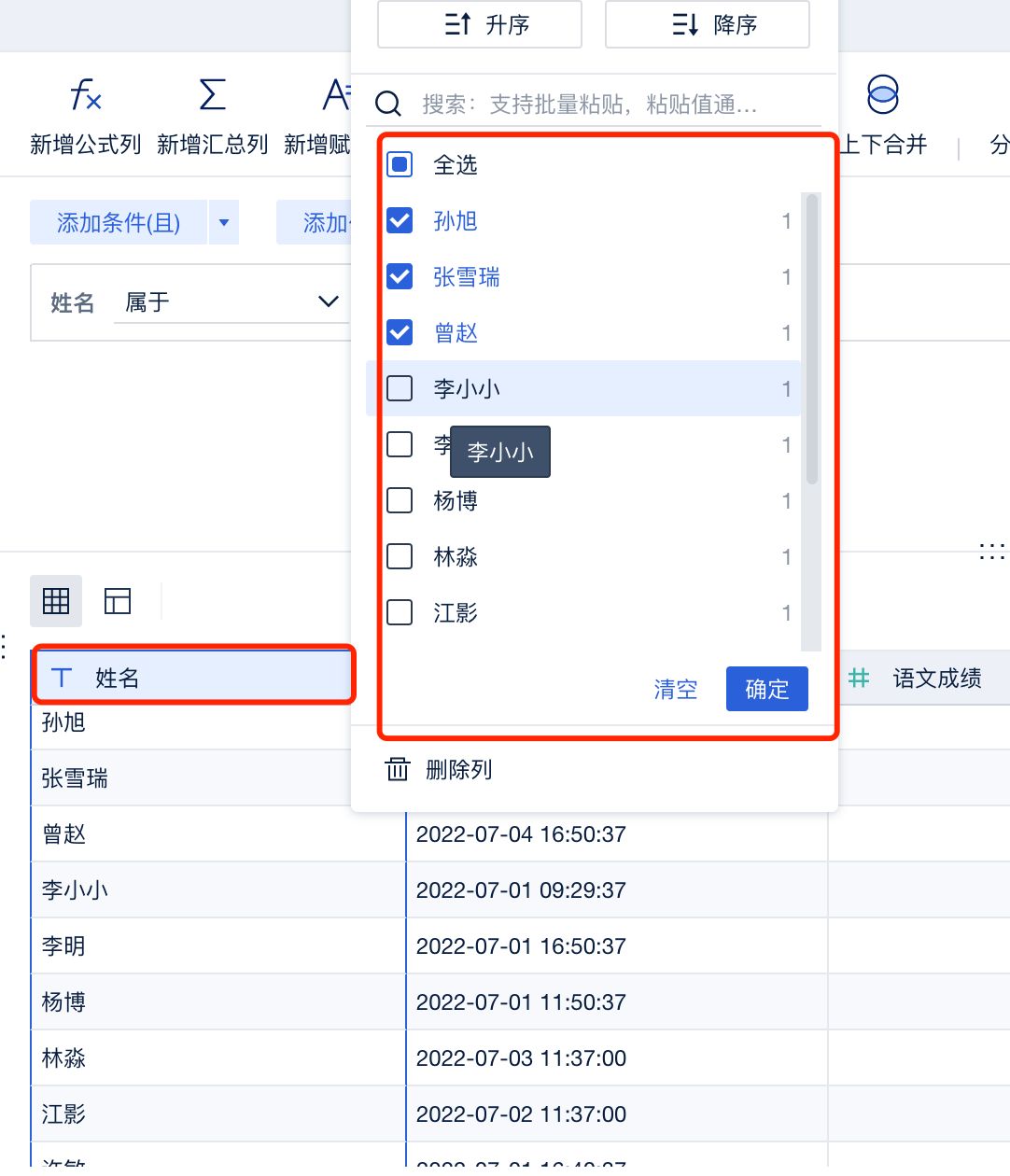
利用这一点,我们可以通过过滤出部分关键数据,并取消应用一些疑惑的关键步骤来进行试错。就如同刚学数学时习惯性的多次验算一样,虽然对老玩家略显繁琐,但的确是最令新手放心的定心丸。
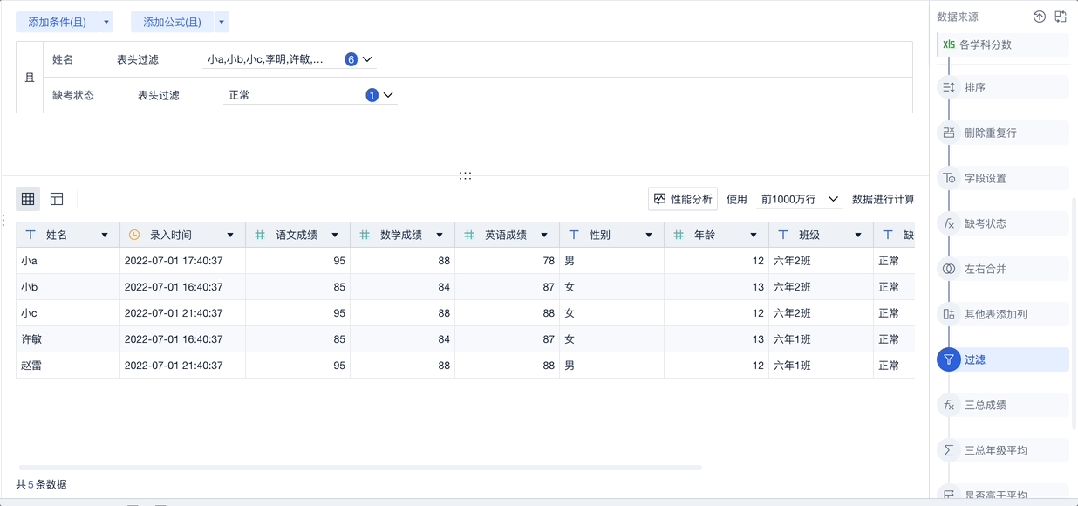
通过表头快速过滤出少部分数据进行“抽样检测”
灵活运用步骤区的小技巧帮助自己快速检查
结语
综上所述,BI工具为数据预处理提供了强大而灵活的平台,通过掌握其中的技巧,我们能够更加高效地应对复杂的数据情境,为业务决策提供更有力的支持。在这个数据驱动的时代,深谙数据预处理之道,将成为每位数据分析专业人士必须具备的重要技能。不仅能够提升分析效率,更能够确保我们从数据中挖掘出准确、深刻的见解,为业务的成功铺平道路。
这篇关于如何用BI工具对数据进行预处理?数据分析的这项技巧你必须掌握。的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






