本文主要是介绍【论文解读】伪装物体检测 Camouflaged Object Detection,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 伪装物体检测 Camouflaged Object Detection
- SINet v1
- RF模块:
- PDC模块:
- SINet v2
- 特征提取
- Texture Enhanced Module 纹理增强模块
- Neighbor Connection Decoder 邻居连接解码器
- Group-Reversal Attention 组反转注意力
- 总结
伪装物体检测 Camouflaged Object Detection
SINet 有两个版本
SINet-v1发表在CVPR2020
论文地址:Camouflaged_Object_Detection_CVPR_2020
代码地址:SINet-v1代码
SINet-v2发表在2021年 IEEE TPAMI上
论文地址:Concealed Object Detection
代码地址:SINet-V2
v1版本相较于v2版本,对网络结构有些变化
论文翻译:https://zpf1900.blog.csdn.net/article/details/127429430
v1网络结构:
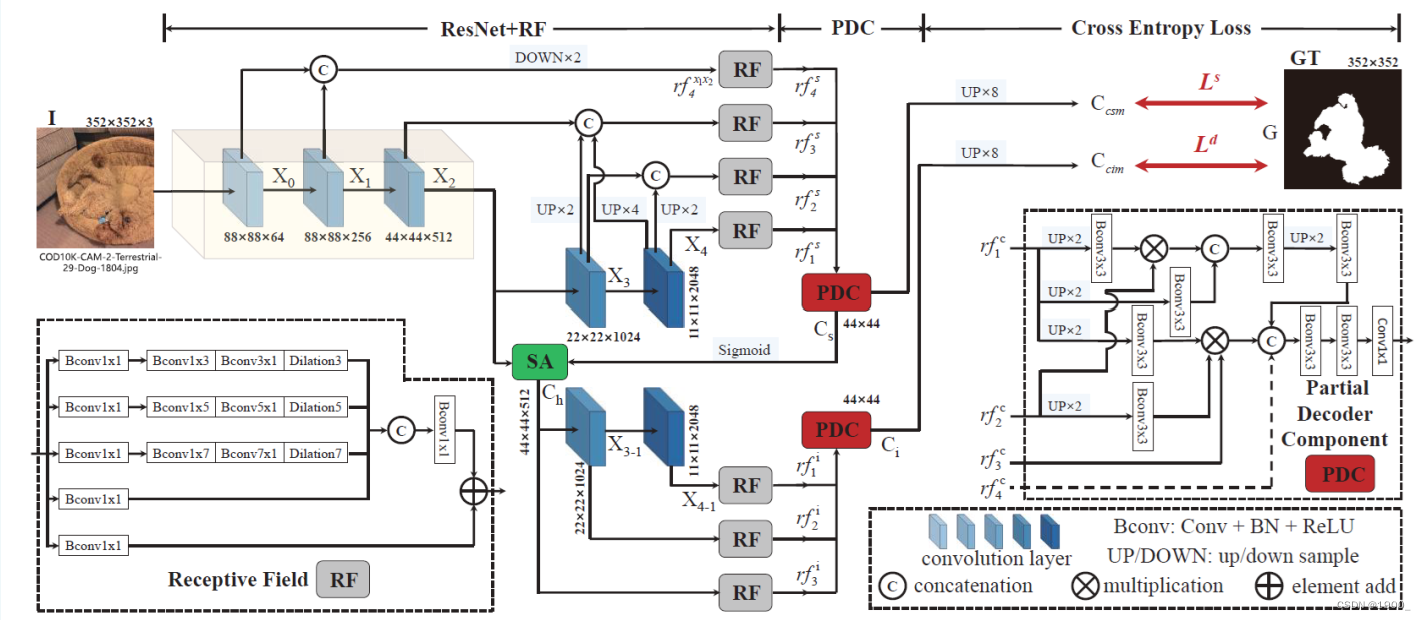
v2网络结构:
SINet v1
SINet主要的贡献是制作了COD10K这个数据集,另外算是挖了伪装物体识别这个坑。
SINet v1在网络结构上并无太大的创新,结构主要是仿照CPD框架
建议看v1结构之前先去看这篇文章:
- Cascaded Partial Decoder for Fast and Accurate Salient Object Detection
这篇文章是2019年CVPR的关于显著目标检测的文章
这篇文章主要是提出了一种新的级联部分解码器(CPD)框架,用于快速准确地检测显著目标。
SINet中使用的RF模块、SA模块、PDC模块都是抄的CPD框架中的模块
以及SINetv1使用的的双分支结构也是抄的CPD的双分支结构
基本结构都一样 只不过没有舍弃低级特征而已
关于CPD框架可以看另一篇博客:PDC模块、F模块、SA模块这里面都有讲解
https://zpf1900.blog.csdn.net/article/details/127429430
整个网络大结构也是仿照CPD的结构,双分支
虽然作者将其分为两块,并且起名字叫搜索模块(SM)和识别模块(IM),但是其实就是CPD的那个双分支结构
所以,起名字是一种艺术
主干网络用ResNet50,五个卷积块的特征都不舍去
第一个分支将五个卷积块的特征经过RF模块后,使用PDC融合一下
第二个分支将第三模块的特征图送入SA,然后与第四、第五卷积块的特征图一起经过RF模块再送入PDC得到增强的图
两个分支使用交叉熵损失函数联合训练
具体的网络细节,我在CPD那篇博客里面都有写,这里就不解释了。CPD讲解
另外,CPD那篇文章里面作者没有为自己使用的模块画具体的网络图
SINet倒是画了两个图
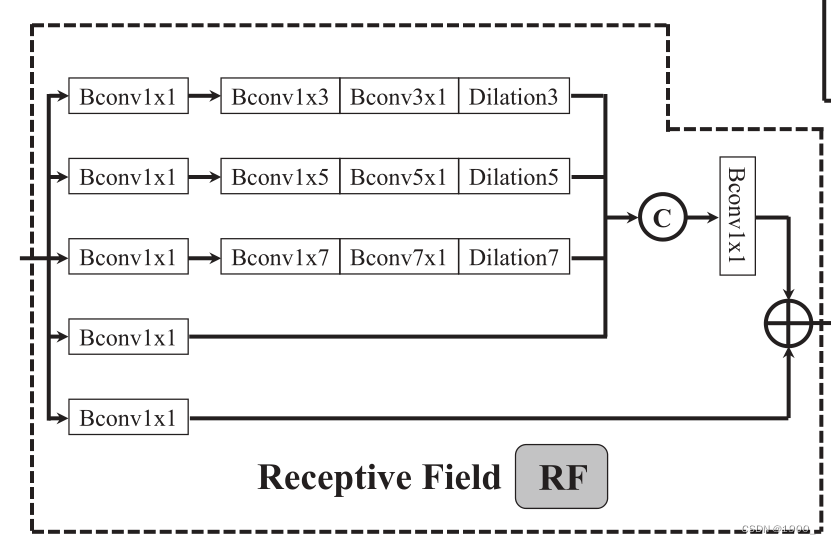
RF模块:
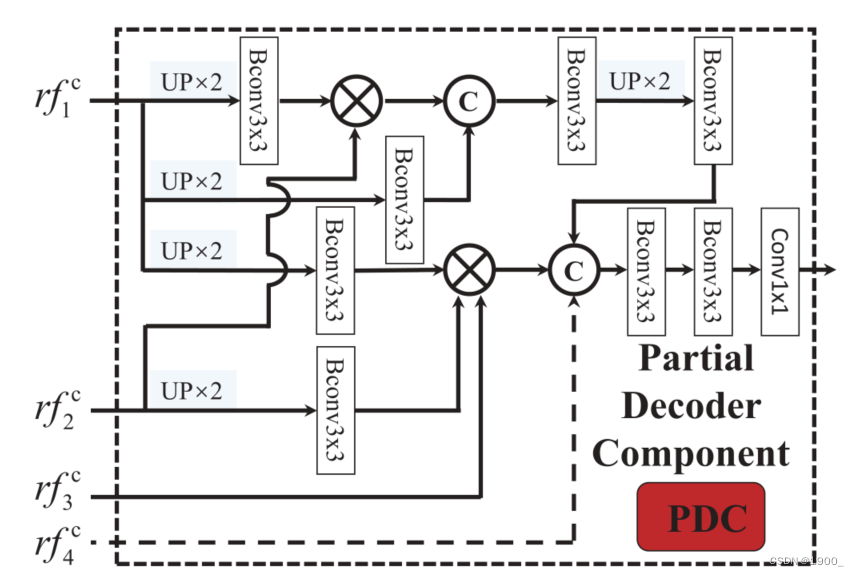
PDC模块:
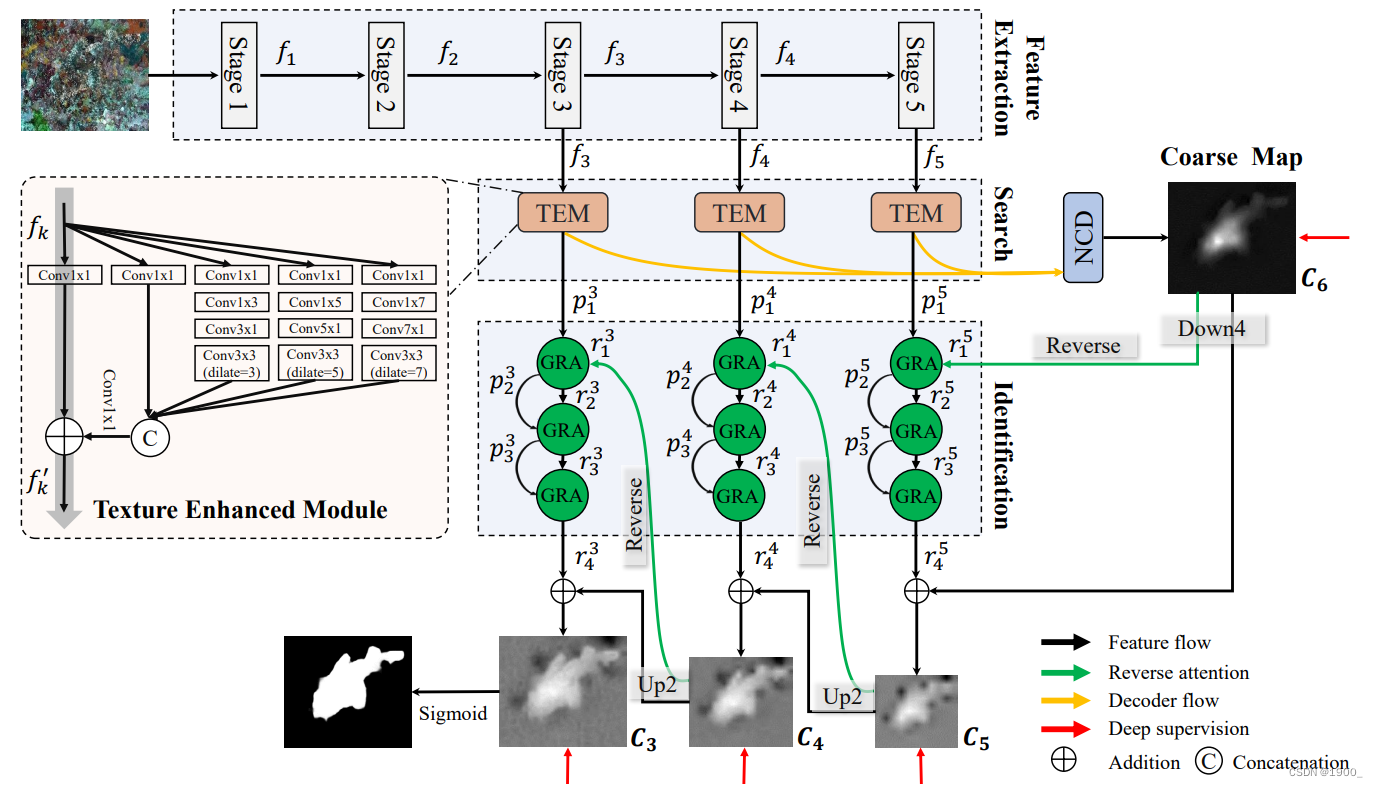
SINet v2
v2与v1最大的差别是注意力那块,v2使用了组反转注意力。
特征提取
还是使用ResNet50,但是与v1不同的是,这里只要后三个阶段的特征,低级特征舍去(还是借鉴的CPD框架的处理)
Texture Enhanced Module 纹理增强模块
三个阶段提取的特征都经过一个TEM,这个就是v1里面的RF模块,只不过换了个名字,代码都没变
Neighbor Connection Decoder 邻居连接解码器
这个就是v1里面的PDC模块,换了个名字而已。不做解释了
得到 C 6 C_6 C6
Group-Reversal Attention 组反转注意力
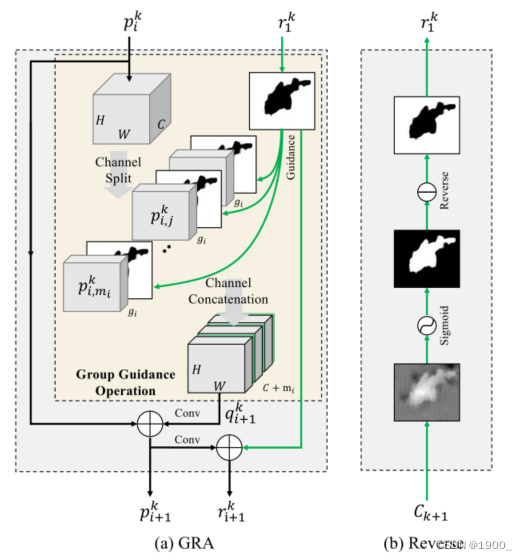
这个组反转注意力,目的是为了擦除已经识别到的物体来让网络后续去关注其他区域的信息。
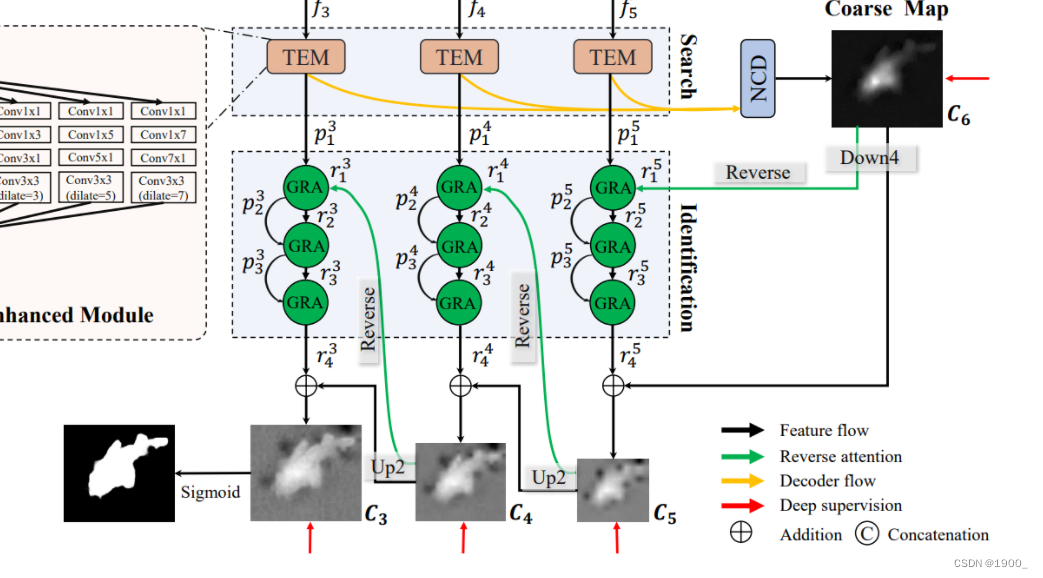
就是拿得到的这个粗略图 C 6 C_6 C6 ,先取反,把这个记作 y y y
然后将主干网络提取到的特征 p 1 5 p^5_1 p15,记作 x x x。
整个过程就是,将x按通道划分为几个组,然后将y插入进去,再卷积融合。
例如: p 1 5 p^5_1 p15就是 x x x,输入是32通道,一共进行三次GRA,第一次就分为一组,也就是直接等于x,32通道,加上一个取反后的 C 6 C_6 C6,也就是 y y y,得到33通道,经过一个3x3的卷积,变回32通道,再ReLU一下,就得到了新的 x x x,而y呢,把这个新的 x x x,卷积一下,通道压缩到1维,就是我们新的 y y y,我们也叫注意力分数。
然后那我们新的x和y,进行第二次GRA,这次输入x是32通道,分为4组,也就是每组8通道,我们在每一组后面都插入一个y,也就是每组都变成了9通道,然后再一起送入卷积,变回32通道,记作新的x,同样的,压缩通道后得到注意力分数,记作新的y。
然后第三次GRA,我们分为32组,也就是一个通道一组,然后每个通道都加一个y,也就是64通道,同样的,卷积变回32通道,压缩通道得到注意力分数。最后得到的这个y就是图中的 r 4 5 r^5_4 r45。再把 C 6 C_6 C6加上,再经过一个上采样恢复大小,就得到了我们的 C 5 C_5 C5。
C 4 C_4 C4, C 3 C_3 C3也是同理。
整个过程其实就是, C 6 C_6 C6是我们已经发现的目标,然后先在图中把 C 6 C_6 C6消除了,然后经让网络再去搜寻目标,经过三轮搜寻之后,再把 C 6 C_6 C6补上。相当于完善了除 C 6 C_6 C6以外的细节。
然后把此过程在主干网络的三个阶段得到的特征图上都来一遍,相当于在各个阶段补充细节。
最终得到输出图,整个网络结构就是这样。
GRA模块作者画了个图,如下:
总结
本文的主要贡献是提出了伪装目标检测这个系统性的研究任务。
制作了COD10K数据集。
提出了SINet用于检测伪装目标。
SINetv1创新性不多,基本上是借鉴下面这篇文章的网络设计做的
- Cascaded Partial Decoder for Fast and Accurate Salient Object Detection
SINetv2将v1的结构改了,将注意力模块换做组反转注意力模块。作者说受下面这几个论文启发
- Pranet: Parallel reverse attention network for polyp segmentation,2020
- Object region mining with adversarial erasing: A simple classification to semantic segmentation approach,2017
- Reverse attention for salient object detection,2018
这篇关于【论文解读】伪装物体检测 Camouflaged Object Detection的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








