本文主要是介绍【RAG】Chain-of-Verification Reduces Hallucination in LLM,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
note
- 百川智能还参考Meta的CoVe(Chain-of-Verification Reduces Hallucination in Large Language Models)技术,将真实场景的用户复杂问题拆分成多个独立可并行检索的子结构问题,从而让大模型可以针对每个子问题进行定向的知识库搜索,提供更加准确和详尽的答案。
文章目录
- note
- Chain-of-Verification Reduces Hallucination in Large Language Models
- 背景
- 相关工作
- 验证链 CoVe
- (1)生成基准回复
- (2)设计验证
- (3)执行验证
- (4)生成最终验证响应
- 实验
- (1)实验数据集
- (2)对比模型
- 实验结论
- 1、CoVe提高了基于列表的答案任务的精确度
- 2、CoVe提高了闭卷质检的性能
- 3、指令微调和CoT并未减少幻觉
- 4、因子式CoVe和两步式CoVe可提高性能
- 5、进一步明确推理有助于消除幻觉
- 6、基于CoVe的Llama优于InstructGPT、ChatGPT和PerplexityAI
- 7、短式验证问题比长式查询回答得更准确
- Reference
Chain-of-Verification Reduces Hallucination in Large Language Models
缓解LLM幻觉 :Chain-of-Verification 一种基于链式验证思想的自我修正工作解读
论文链接:https://arxiv.org/pdf/2309.11495

背景
CoVe生成的各代推理都带有验证,如果用户查看这些验证,就能为其决策增加更多可解释性,但这是以增加计算量为代价的,因为要在输出中生成更多token,这与Chain-of-Thought等其他推理方法类似。

相关工作
大多数减少幻觉的方法大致可分为三类:训练时校正、生成时校正和使用工具。
- 在训练时校正方法中:尝试通过训练或以其他方式调整模型权重以降低幻觉生成的概率来改进编码器-解码器或仅解码器语言模型的原始从左到右生成。这包括使用强化学习(Roit et al., 2023;Wu et al., 2023)、对比学习(Chern et al., 2023b;Sun et al., 2023b)和其他方法(Li et al., 2023)。
- 在生成时校正中:一个共同的主题是在基础 LLM 的“之上”做出推理决策,以使它们更加可靠。例如,通过考虑生成token的概率(Mielke et al., 2022;Kadavath et al., 2022)。(Manakul et al. 2023) 从模型中抽取多个样本来检测幻觉。在(Varshney et al. 2023) 使用低置信度分数来识别幻觉,并通过验证程序检查其正确性、减轻幻觉,然后继续生成。
- 使用外部工具:第三种方法是使用外部工具来帮助减轻幻觉,而不是仅仅依赖语言模型本身的能力。例如,检索增强生成可以通过使用事实文档作为基础(Shuster et al., 2021)或思维链验证(Zhao et al., 2023)来减少幻觉。其他方法包括使用事实核查工具(Chern et al., 2023a;Galitsky, 2023),或链接到带有归属的外部文档(Menick et al., 2022;Rashkin et al., 2023;Gao et al., 2023)。
验证链 CoVe
四个核心步骤:
- 生成基线回复:给定一个查询,使用 LLM 生成响应。
- 设计验证:给定查询和基线响应,生成验证问题列表,有助于自我分析原始响应中是否存在任何错误。
- 执行验证:依次回答每个验证问题,然后将答案与原始响应进行检查,以检查是否存在不一致或错误。
- 生成最终验证响应:鉴于发现的不一致(如果有),生成包含验证结果的修订响应。
(1)生成基准回复
使用few-shot的prompt声测会给你基准回复:

(2)设计验证
根据query和基准回复,生成一个验证问题列表。

(3)执行验证
依次回答验证列表,然后对基准回复,检查是否有不一致or错误。
验证执行的几种变体,分别称为联合、两步、因子和因子+修订:
- 在联合方法中,规划和执行(第2步和第3步)是通过使用单个LLM提示来完成的,其中的少量演示包括验证问题及其紧随问题之后的答案。这种方法不需要单独的提示。
- 缺点: 由于验证问题必须以LLM上下文中的基线反应为条件,而且该方法是联合的,因此验证答案也必须以初始反应为条件。这可能会增加重复的可能性,也意味着验证问题可能会产生与原始基线回复类似的幻觉,这就失去了意义。

- 两步:将计划和执行分为不同的步骤,这两个步骤都有各自的LLM提示。规划提示以第一步中的基准回答为条件。规划生成的验证问题在第二步中回答,关键是LLM提示的上下文只包含问题,而不包含基准回复,因此一般不会直接重复这些答案。

- 因子:将所有问题作为单独的提示独立回答,不过这可能会增加计算成本,在具体实现上,将计划验证阶段生成的问题集解析为单独的问题,以逗号分隔的列表形式生成,然后将它们拆分成单独的LLM提示。

- 因子+修订思想在于在回答了验证问题后,通过额外的LLM提示将其作为一个有意的步骤来执行,检查这些答案是否与原始答案不一致。
(4)生成最终验证响应
根据发现的不一致之处(如有),生成包含验证结果的修订回复,通过最后的few shot提示来执行。
实验
(1)实验数据集
- WIKIDATA数据集,首先使用WikidataAPI在一组自动生成的问题上对CoVe进行测试。
- 指标:精确度指标(微观平均值)
- QUEST数据集,维基分类列表问题
- 指标:精确度指标(微观平均值)
- 阅读理解基准MultiSpanQA数据集。 MultiSpanQA包含有多个独立答案的问题,从文本中一系列多个不连续的跨度中得出。使用了由418个问题组成的测试集,每个跨度的答案较短。
- 指标:精确度指标(微观平均值)
- 长篇传记的生成数据集,模型需根据提示生成所选实体的传记,例如:“告诉我<实体>的传记”。评估指标采用
FACTSCORE指标,该指标使用检索增强语言模型对回复进行事实检查(Instruct-Llama,“Llama+Retrieval+NP”)。- 指标:FACTSCORE指标,该指标使用检索增强语言模型对回复进行事实检查(Instruct-Llama,“Llama+Retrieval+NP”)
(2)对比模型
首先,使用Llama65B作为基础LLM,并对所有模型使用贪婪解码,由于Llama65B没有经过指令微调,采用针对每个任务的少量实例来衡量每个基准的性能。
其次,与Llama指令微调模型进行了比较,使用Llama2。
实验结论
1、CoVe提高了基于列表的答案任务的精确度
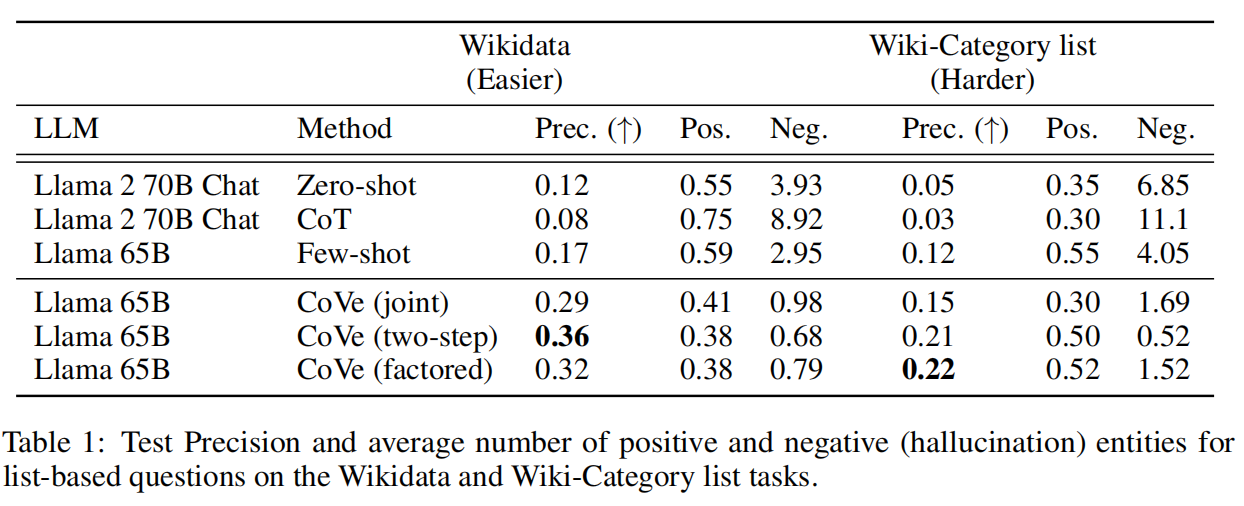
CoVe在基于列表的任务中提高了大量精确度,例如,在维基数据任务中,CoVe的精确度比Llama65B fewshot 基线提高了一倍多(从0.17提高到0.36)。从正负分类中发现,幻觉答案的数量大幅减少,而非幻觉答案的数量仅有相对较小的减少。
2、CoVe提高了闭卷质检的性能
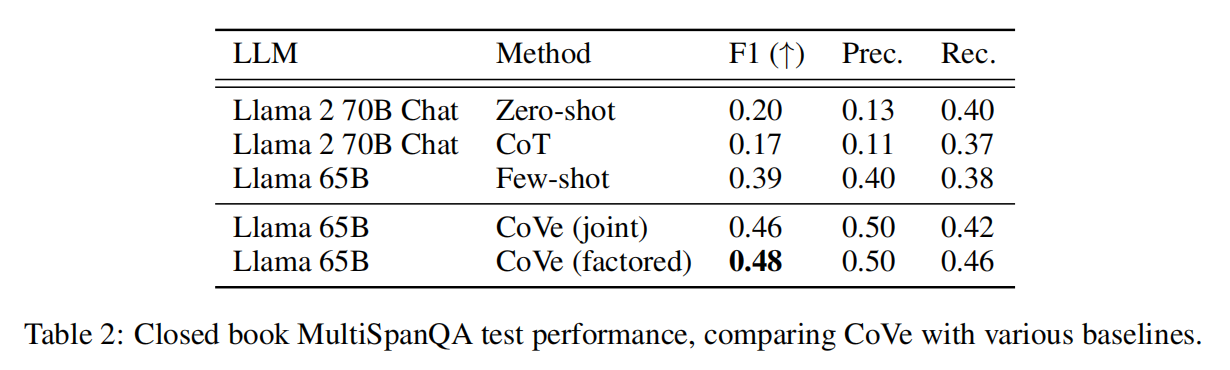
CoVe在一般质检问题上也有所改进,这是在MultiSpanQA上测得的结果。观察到,F1比很少的基线(0.39→0.48)提高了23%,提高的原因是精确度和CoVe提高了长式生成的精确度。
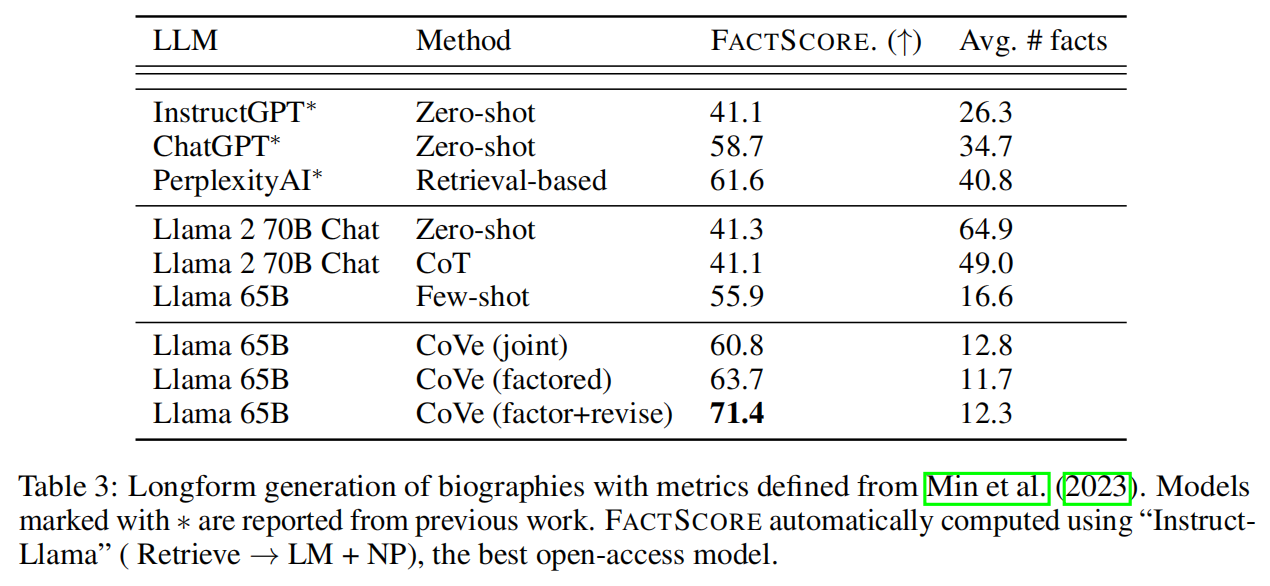
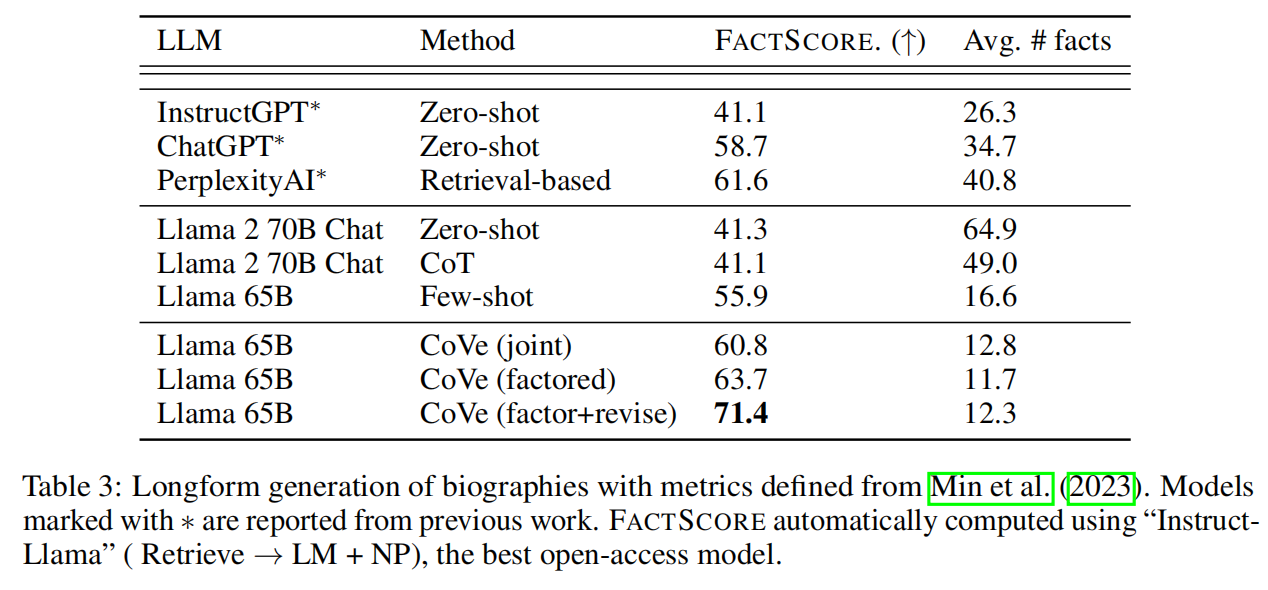
FACTSCORE比很少的基线提高了28%(55.9→71.4),而所提供事实的平均数量也只有相对较小的减少(16.6→12.3)。还在图2中显示了不同事实的改进情况,可以看出CoVe对罕见事实和更常见事实的结果都有改进。
3、指令微调和CoT并未减少幻觉
在所有任务中,采用预训练Llama模型的少量实例基线优于指令调整模型Llama2Chat。fewshot的示例会引导模型给出符合任务预期的输出结果,而一般的指令调整则会产生更多幻觉或错误输出。
标准的思维链(CoT)提示也未能改善这些任务的结果。虽然事实证明,CoT对推理任务有帮助,但它似乎不太适合在这项工作中测量的幻觉问题。
4、因子式CoVe和两步式CoVe可提高性能
与联合CoVe相比,采用因子式CoVe方法可在所有任务中持续提高性能。例如,在长表生成中,FACTSCORE的性能从60.8提升到63.7。
同样,在维基数据和维基分类列表任务的测试中,两步法也优于联合法,其中两步法在维基数据中的结果最好,而在维基分类中因子法的结果最好。
5、进一步明确推理有助于消除幻觉
在长表生成任务中,CoVe"因子+修订"方法中更复杂的推理步骤,该方法明确交叉检查验证答案是否表明存在不一致。通过这种进一步的明确推理,FACTSCORE指标从63.7(因子)→71.4(因子+修正)有了大幅提高。
表明:在LLM中进行适当和明确的推理可在减少幻觉方面带来改进。
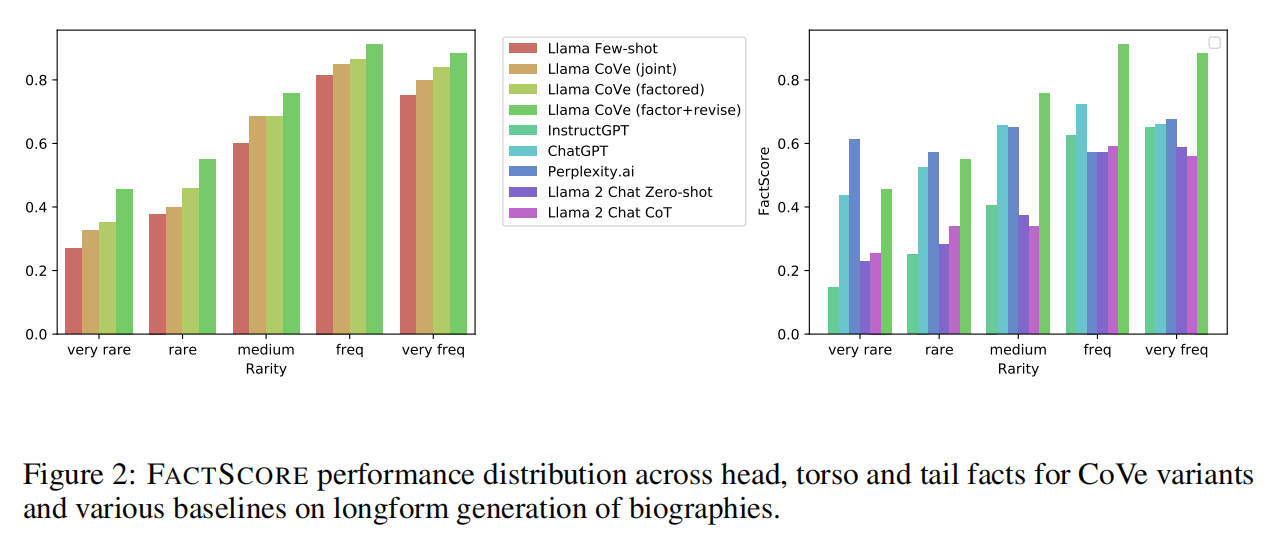
6、基于CoVe的Llama优于InstructGPT、ChatGPT和PerplexityAI
在长表单生成任务中,的基线Llama65B在FACTSCORE指标方面优于ChatGPT和PerplexityAI模型。
然而,将CoVe应用于基线Llama65B后,其性能不仅超过了ChatGPT和PerplexityAI,还超过了InstructGPT。
与PerplexityAI相比,这一点尤其明显,因为PerplexityAI是一个可以通过检索增强来支持其事实的模型,而CoVe仅使用基础语言模型本身,并通过验证来改进推理。
然而,可以从图2中看到,在检索非常重要的罕见事实方面,PerplexityAI的表现仍然优于CoVe,但在更高频的事实方面,CoVe的表现优于PerplexityAI。
7、短式验证问题比长式查询回答得更准确
在长式回答中,LLM很容易产生一些幻觉。然而,通常情况下,如果专门针对个别事实进行询问,LLM本身就会知道这些幻觉是错误的,与长表生成的其他部分无关。
这可以从维基数据任务中定量看出,在基于列表的问题中,只有∼17%的Llama少量基线答案实体是正确的。然而,当通过验证问题对每个实体进行查询时,发现有70%的实体得到了正确回答。
Reference
[1] Chain-of-Verification Reduces Hallucination in Large Language Models
[2] 百川智能发布Baichuan2—Turbo系列API,开启企业定制化新生态
这篇关于【RAG】Chain-of-Verification Reduces Hallucination in LLM的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!

![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)