本文主要是介绍第一个深度学习模型 Bitmoji Faces Gender Recognition,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
简介:
本文根据利用深度学习模型,根据人脸的表情信息对人的性别进行分类,数据集来自kaggle。是一个二分类问题,比较简单,可以当做自己的第一个深度学习模型。动手深刻感受深度学习。
数据集:
原始数据集如下所示:

其中所给的训练集图像有3000张,测试集图像有1084张,同时还提供了训练集的CSV文件如下所示:
| image_id | is_male | left_eye_x | left_eye_y | right_eye_x | right_eye_y | nose_x | nose_y | mouth_left_x | mouth_left_y | mouth_right_x | mouth_right_y |
| 0000.jpg | 1 | 152 | 186 | 236 | 183 | 196 | 234 | 158 | 262 | 231 | 260 |
| 0001.jpg | -1 | 146 | 191 | 232 | 192 | 190 | 229 | 155 | 263 | 228 | 264 |
| 0002.jpg | 1 | 157 | 188 | 229 | 188 | 194 | 235 | 164 | 258 | 224 | 257 |
| 0003.jpg | -1 | 152 | 210 | 232 | 210 | 191 | 248 | 159 | 280 | 222 | 281 |
| 0004.jpg | -1 | 151 | 189 | 237 | 189 | 192 | 227 | 155 | 254 | 232 | 254 |
其中表格中中1代表男性,-1代表女性,同时还提供了左眼,右眼,鼻子,左嘴巴端点,右嘴巴端点的坐标。以像素值表示。这些数据本文并没有用到。只用了图片作为卷积输入。
1.相关工作
1.1. 预处理:
所谓的预处理,是将计算特征之前,排除掉跟脸无关的一切干扰,因此,就有了数据增强,图片大小的重置、图片的剪裁、向量化和归一化等。
数据增强,包含在线和离线两种[1]:主流的离线数据增强,包含随机扰动,变换(旋转,平移,翻转,缩放,对齐),噪声添加如椒盐噪声,斑点噪声,以及亮度,饱和度变化,以及在眼睛之间添加2维高斯随机分布的噪声。同时,还有其他的如GAN生成脸[2],3DCNN辅助AUs生成表情。
除此之外为了方便数据输入模型,我们需要将图片存储的位置和图片的标签放到一个文本文件中,如下所示:

其中1代表男性,0代表女性。这个处理需要使用make_data_txt.py 这个文件,主要是制作训练集,测试集。里面文件路径需要替换成自己的。
1.2. 深度特征学习
主要是基于CNN的网络模型,具有非常高性能的特征表达能力[3]。特别适合基于图像的分类问题,另外一个基于DBN网络的特征提取,以及DAE转门用作特征提取。最后,还有一部分是基于序列建模的RNNs,如LSTM等。因为我们的这个作业复杂度不高,所以主要采用CNN的网络模型。
1.3.面部表示分类
主要是说,可以基于深度学习,直接学习特征,预测概率(softmax),也可以把学习的深度特征,用SVM等浅层分类器进行分类[3]。
2 本文工作
本文的核心框架为pytorch,接下来将从图片的处理方法,模型的结构和模型的结果展示三个部分进行模型说明。
2.1模型的图片处理
这里我使用pytorch的transform进行数据的预处理,主要用到了图片大小的重置、图片的剪裁、向量化和归一化。
图片大小的重置:考虑到使用两层卷积层和池化层,这里决定设置一个普通的数据256像素。原图片大小为384*384。然后进行中心剪裁,这里剪裁后的大小为224*224.
图片归一化:使得预处理的数据被限定在一定的范围内,从而消除奇异样本数据导致的不良影响。

2.2 网络结构
本模型使用的网络结构较为简单,首先是一层卷积层,然后跟着一个池化层,然后又是一层卷积跟着一个池化。接下来就是全连接层。一共有三层全连接层。经过全连接层之后将结果进行输出。这里不同的是没有使用激活函数,也是只用了两层的卷积。
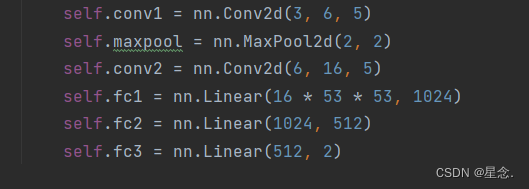
对于网络参数的设置如下:
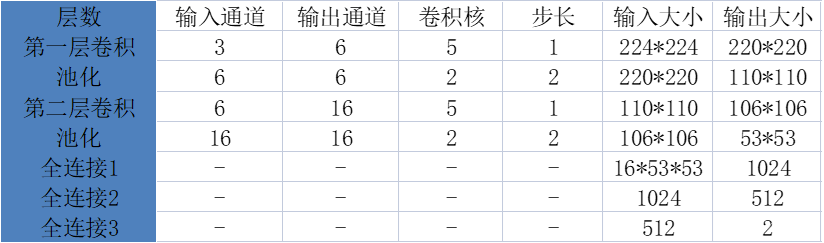
这里所有的填充都是0,所以没有添加到上述表格中。最终的输出是是一个1*2的张量,里面是预测的概率。
2.3 结果展示和分析
本模型训练的参数是总共训练10 epochs,训练的batch_size是4。使用的是CPU进行训练的。
10个epochs的准确度如下所示:

模型大概训练了40分钟,最终训练集的正确率达到99.875,测试集的正确率达到99.333。然后将此模型的识别结果提交到kaggle上时,得到的评分是99.472.
3 代码
训练模型的代码如下所示:
# coding=utf-8
import os
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.autograd import Variable
from torch.utils.data import Dataset
from torchvision import transforms, datasets, models
from PIL import Imageepochs = 10 # 训练次数
batch_size = 4 # 批处理大小
num_workers = 0 # 多线程的数目
use_gpu = torch.cuda.is_available()
PATH='./mymodel.pt'
# 对加载的图像作归一化处理, 并裁剪为[224x224x3]大小的图像
data_transform = transforms.Compose([transforms.Resize(256),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])class MyDataset(Dataset):def __init__(self, txt_path, transform = None):fh = open(txt_path, 'r')imgs = []for line in fh:line = line.rstrip()words = line.split()imgs.append((words[0], int(words[1])))self.imgs = imgsself.transform = transformdef __getitem__(self, index):fn, label = self.imgs[index]img = Image.open(fn).convert('RGB')if self.transform is not None:img = self.transform(img)return img, labeldef __len__(self):return len(self.imgs)# 配置参数
random_state = 1
torch.manual_seed(random_state) # 设置随机数种子,确保结果可重复
torch.cuda.manual_seed(random_state)
torch.cuda.manual_seed_all(random_state)
np.random.seed(random_state)
# random.seed(random_state)train_dataset = MyDataset(txt_path='train_data.txt', transform=data_transform)
train_loader = torch.utils.data.DataLoader(train_dataset,batch_size=batch_size,shuffle=True,num_workers=num_workers)test_dataset = MyDataset(txt_path='test.txt', transform=data_transform)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=batch_size, shuffle=True, num_workers=num_workers)# 创建模型
class Net(nn.Module):def __init__(self):super(Net, self).__init__()self.conv1 = nn.Conv2d(3, 6, 5)self.maxpool = nn.MaxPool2d(2, 2)self.conv2 = nn.Conv2d(6, 16, 5)self.fc1 = nn.Linear(16 * 53 * 53, 1024)self.fc2 = nn.Linear(1024, 512)self.fc3 = nn.Linear(512, 2)def forward(self, x):x = self.maxpool(F.relu(self.conv1(x)))x = self.maxpool(F.relu(self.conv2(x)))x = x.view(-1, 16 * 53 * 53)x = F.relu(self.fc1(x))x = F.relu(self.fc2(x))x = self.fc3(x)return xnet = Net()
if(os.path.exists('mymodel.pt')):net=torch.load('mymodel.pt')if use_gpu:net = net.cuda()
print(net)# 定义loss和optimizer
cirterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.0001, momentum=0.9)def train():for epoch in range(epochs):running_loss = 0.0train_correct = 0train_total = 0for i, data in enumerate(train_loader, 0):inputs, train_labels = dataif use_gpu:inputs, labels = Variable(inputs.cuda()), Variable(train_labels.cuda())else:inputs, labels = Variable(inputs), Variable(train_labels)optimizer.zero_grad()outputs = net(inputs)_, train_predicted = torch.max(outputs.data, 1)train_correct += (train_predicted == labels.data).sum()loss = cirterion(outputs, labels)loss.backward()optimizer.step()running_loss += loss.item()train_total += train_labels.size(0)print('train %d/%d epoch loss: %.3f acc: %.3f ' % (epoch + 1, epochs,running_loss / train_total, 100 * train_correct / train_total))# 模型测试correct = 0test_loss = 0.0test_total = 0test_total = 0net.eval()for data in test_loader:images, labels = dataif use_gpu:images, labels = Variable(images.cuda()), Variable(labels.cuda())else:images, labels = Variable(images), Variable(labels)outputs = net(images)_, predicted = torch.max(outputs.data, 1)loss = cirterion(outputs, labels)test_loss += loss.item()test_total += labels.size(0)correct += (predicted == labels.data).sum()print('test %d/%d epoch loss: %.3f acc: %.3f ' % (epoch + 1,epochs, test_loss / test_total, 100 * correct / test_total))torch.save(net, 'mymodel.pt')print('mymodels save!')train()
4 总结
这个模型是个比较简单的二分类问题,因此模型也比较简单,可以帮助我们更好地理解深度学习的数据处理和输入,数据的处理流程,作为我们的第一个深度学习模型是比较好的。顺便提一下,模型没有用到特征增强,我同学有用到这一方面,准确率可以达到100%。感兴趣的小伙伴可以尝试改进模型。
完整项目以及介绍见 GitHub
引用
[1] 宋雨,王帮海,曹钢钢.结合数据增强与特征融合的跨模态行人重识别[J/OL].计算机工程与应用:1-10[2022-12-26].http://kns.cnki.net/kcms/detail/11.2127.TP.20221213.1638.017.html
[2]范丽丽. 基于深度学习的视觉特征学习关键技术研究[D].吉林大学,2022.DOI:10.27162/d.cnki.gjlin.2022.002224.
[3]杨兆龙. 面部表情识别方法研究实现[D].福州大学,2017.
这篇关于第一个深度学习模型 Bitmoji Faces Gender Recognition的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



