本文主要是介绍基于pytorch的视觉变换器-Vision Transformer(ViT)的介绍与应用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
近年来,计算机视觉领域因变换器模型的出现而发生了革命性变化。最初为自然语言处理任务设计的变换器,在捕捉视觉数据的空间依赖性方面也显示出了惊人的能力。视觉变换器(Vision Transformer,简称ViT)就是这种变革的一个典型例子,它提出了一种新颖的架构,在各种图像分类任务上实现了最先进的性能。
在这篇文章中,我们将一起构建我们自己的视觉变换器模型,使用PyTorch进行实现。通过逐步分解实现过程,我们旨在提供对ViT架构的全面理解,并使您能够清晰地掌握其内部工作原理。当然,我们可以直接使用PyTorch内置的视觉变换器模型,但那样就没有乐趣了。
我们将从设置必要的依赖和库开始,确保整个项目的顺利进行。接下来,我们将进入数据获取阶段,获取适合训练我们的视觉变换器模型的数据集。
为了准备训练数据,我们将定义必要的转换操作,用于增强和标准化输入图像。随着数据转换的到位,我们将创建自定义数据集和数据加载器,为训练模型搭建舞台。
要理解视觉变换器架构,从零开始构建它至关重要。在后续部分,我们将逐一解析ViT模型的每个组件,并解释其作用。我们将从负责将输入图像划分为更小块并将其嵌入向量格式的Patch嵌入层开始。紧接着,我们将探索多头自注意力模块,它允许模型捕捉图像块之间的全局和局部关系。
此外,我们还将深入了解机器学习感知器模块,这是一个关键组件,使模型能够捕捉输入数据的层次性表示。通过组合这些组件,我们将构建变换器块,它构成了视觉变换器的核心构建块。
最后,我们将通过使用我们精心打造的组件来创建ViT模型。随着模型的完成,我们可以对其进行实验,微调,并在各种计算机视觉任务上发挥其潜力。
到本文结束时,您将获得对视觉变换器架构及其在PyTorch中的实现的扎实理解。有了这些知识,您将能够根据自己的具体需求修改和扩展模型,甚至在此基础上构建更高级的计算机视觉应用。让我们开始吧。
快速部署
第一步:安装并导入依赖项
!pip install -q torchinfo
import torch
from torch import nn
from torchinfo import summary
第二步:获取数据集
import requests
from pathlib import Path
import os
from zipfile import ZipFile# 定义zip文件的URL
url = "https://github.com/mrdbourke/pytorch-deep-learning/raw/main/data/pizza_steak_sushi.zip"# 发送GET请求以下载文件
response = requests.get(url)# 定义数据目录的路径
data_path = Path("data")# 定义图像目录的路径
image_path = data_path / "pizza_steak_sushi"# 检查图像目录是否已经存在
if image_path.is_dir():print(f"{image_path} 目录已存在。")
else:print(f"未找到 {image_path} 目录,正在创建...")image_path.mkdir(parents=True, exist_ok=True)# 将下载的内容写入一个zip文件
with open(data_path / "pizza_steak_sushi.zip", "wb") as f:f.write(response.content)# 解压zip文件到图像目录
with ZipFile(data_path / "pizza_steak_sushi.zip", "r") as zipref:zipref.extractall(image_path)# 删除下载的zip文件
os.remove(data_path / 'pizza_steak_sushi.zip')
第三步:定义转化器
1.调正图像大小
2.运用ToTensor()函数转化格式
from torchvision.transforms import Resize, Compose, ToTensor# 使用Compose定义train_transform
train_transform = Compose([Resize((224, 224)), # 将图像调整为224x224像素ToTensor() # 将图像转换为Tensor格式
])# 使用Compose定义test_transform
test_transform = Compose([Resize((224, 224)), # 将图像调整为224x224像素ToTensor() # 将图像转换为Tensor格式
])
第四步:创建数据集和数据加载器
我们可以使用PyTorch的ImageFolder数据集库来创建我们的数据集。
为了使ImageFolder工作,您的数据文件夹需要按照这种方式进行结构化。
data
└── pizza_steak_sushi├── test│ ├── pizza│ ├── steak│ └── sushi└── train├── pizza├── steak└── sushi
所有的比萨图片将位于train和test子文件夹下的pizza文件夹中,其他类别的图片也是如此。
在创建的training_dataset和test_dataset上,有两个有用的方法可以调用:
training_dataset.classes,它会返回['pizza', 'steak', 'sushi']training_dataset.class_to_idx,它会返回{'pizza': 0, 'steak': 1, 'sushi': 2}
from torchvision.datasets import ImageFolder
from torch.utils.data import DataLoaderBATCH_SIZE = 32# 定义数据目录
data_dir = Path("data/pizza_steak_sushi")# 使用ImageFolder创建训练数据集
training_dataset = ImageFolder(root=data_dir / "train", transform=train_transform)# 使用ImageFolder创建测试数据集
test_dataset = ImageFolder(root=data_dir / "test", transform=test_transform)# 使用DataLoader创建训练数据加载器
training_dataloader = DataLoader(dataset=training_dataset,shuffle=True, # 开启随机打乱batch_size=BATCH_SIZE, # 批量大小设置为32num_workers=2 # 使用2个工作进程
)# 使用DataLoader创建测试数据加载器
test_dataloader = DataLoader(dataset=test_dataset,shuffle=False, # 关闭随机打乱batch_size=BATCH_SIZE, # 批量大小设置为32num_workers=2 # 使用2个工作进程
)
我们可以可视化一些训练数据集图像,并查看它们的标签
import matplotlib.pyplot as plt
import randomnum_rows = 5
num_cols = num_rows# 创建一个包含多个子图的图形
fig, axs = plt.subplots(num_rows, num_cols, figsize=(10, 10))# 遍历子图并展示训练数据集中的随机图片
for i in range(num_rows):for j in range(num_cols):# 从训练数据集中随机选择一个索引image_index = random.randrange(len(training_dataset))# 在子图中显示图片axs[i, j].imshow(training_dataset[image_index][0].permute((1, 2, 0)))# 设置子图的标题为对应的类名axs[i, j].set_title(training_dataset.classes[training_dataset[image_index][1]], color="white")# 禁用坐标轴以获得更好的视觉效果axs[i, j].axis(False)# 设置图形的超标题
fig.suptitle(f"训练数据集中随机{num_rows * num_cols}张图片", fontsize=16, color="white")# 将图形的背景色设置为黑色
fig.set_facecolor(color='black')# 展示绘图
plt.show()

理解视觉变换器架构
让我们现在花些时间来理解视觉变换器架构。这是原始视觉变换器论文的链接:https://arxiv.org/abs/2010.11929。
下面,您可以看到论文中提出的架构图。
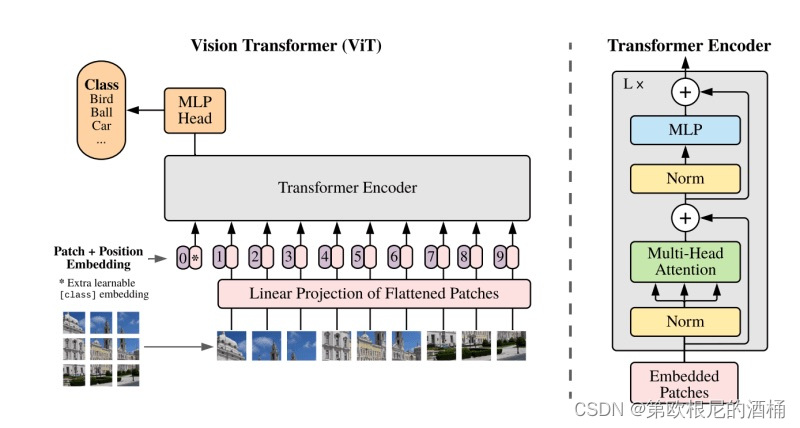
视觉变换器(ViT)是一种为图像处理任务设计的变换器架构类型。与传统的变换器不同,后者主要处理词嵌入序列,ViT处理的是图像嵌入序列。换句话说,它将输入图像分割成多个小块,并将这些小块视为一系列可学习的嵌入。
ViT的基本操作步骤包括:
- 创建补丁嵌入:它将图像分割成补丁,并将每个补丁转换成嵌入向量。
- 通过变换器块传递嵌入:
- 补丁嵌入连同一个分类令牌一起,被送入多个变换器块。
- 每个变换器块由一个多头自注意力模块(MultiHead Self-Attention Block,简称MSA块)和一个多层感知器块(Multi-Layer Perceptron Block,简称MLP块)组成。
- 在变换器块的输入和MSA块的输入之间,以及MLP块的输入和MLP块的输出之间建立跳过连接,以缓解梯度消失问题。
- 执行分类:
- 变换器块的最终输出通过一个MLP块进行处理。
- 使用其中的分类令牌,该令牌包含有关输入图像类别的信息,来进行预测。
接下来,我们将详细探讨每个步骤,首先从创建补丁嵌入的关键过程开始。
第五步:创建补丁嵌入层
根据ViT论文,我们需要对图像执行以下操作,然后才能传递给多头自注意力变换器层:
- 将图像转换为16x16像素大小的补丁。
- 将每个补丁嵌入768维空间。因此,每个补丁变成一个[1 x 768]向量。每张图像将有KaTeX parse error: Can't use function '\(' in math mode at position 1: \̲(̲N = H \times W …个这样的补丁。这样会得到形状为[14 x 14 x 768]的图像。
- 将图像沿着一个向量展平,得到一个[196 x 768]矩阵,即我们的图像嵌入序列。
- 在上述输出前加上类别令牌嵌入。
- 将位置嵌入添加到类别令牌和图像嵌入中。
PATCH_SIZE = 16
IMAGE_WIDTH = 224
IMAGE_HEIGHT = IMAGE_WIDTH
IMAGE_CHANNELS = 3
EMBEDDING_DIMS = IMAGE_CHANNELS * PATCH_SIZE**2
NUM_OF_PATCHES = int((IMAGE_WIDTH * IMAGE_HEIGHT) / PATCH_SIZE**2)# 图像宽度和高度应该能被补丁大小整除。这是一个检查以确保这一点。
assert IMAGE_WIDTH % PATCH_SIZE == 0 and IMAGE_HEIGHT % PATCH_SIZE == 0, print("图像宽度不是补丁大小的整数倍")
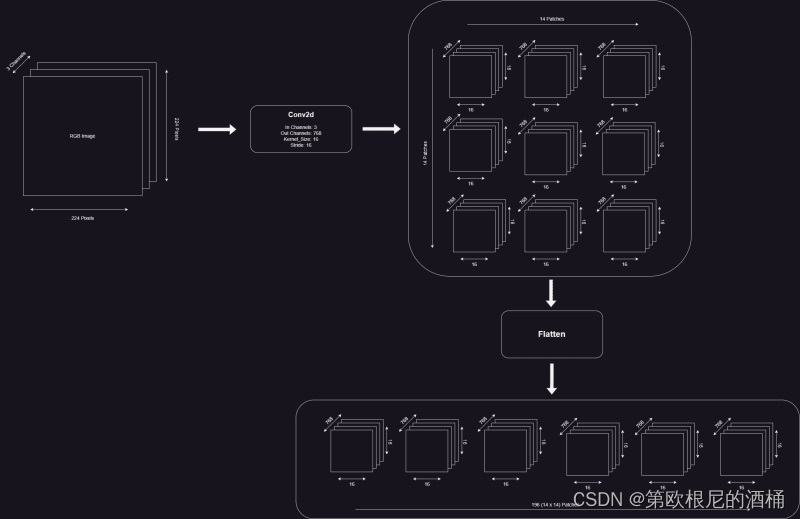
4.1 将图像转换为16x16大小的补丁,并为每个大小为768的补丁创建一个嵌入向量。
这可以通过使用一个Conv2D层来实现,其kernel_size(核大小)等于patch_size(补丁大小),stride(步长)也等于patch_size。
conv_layer = nn.Conv2d(in_channels = IMAGE_CHANNELS, out_channels = EMBEDDING_DIMS, kernel_size = PATCH_SIZE, stride = PATCH_SIZE)
我们可以将随机图像传递到卷积层中,看看会发生什么
random_images, random_labels = next(iter(training_dataloader))
random_image = random_images[0]# 创建一个新的图形
fig = plt.figure(1)# 展示随机选取的图像
plt.imshow(random_image.permute((1, 2, 0)))# 禁用坐标轴以获得更好的视觉效果
plt.axis(False)# 设置图像的标题
plt.title(training_dataset.classes[random_labels[0]], color="white")# 将图形的背景色设置为黑色
fig.set_facecolor(color="black")

我们需要将形状更改为[1,14,14,768],并将输出扁平化为[1,196,768]
# 将图像通过卷积层
image_through_conv = conv_layer(random_image.unsqueeze(0))
print(f'通过卷积层的嵌入形状 -> {list(image_through_conv.shape)} <- [批大小, 补丁行数, 补丁列数, 嵌入维度]')# 调整image_through_conv的维度以匹配预期形状
image_through_conv = image_through_conv.permute((0, 2, 3, 1))# 使用nn.Flatten创建一个展平层
flatten_layer = nn.Flatten(start_dim=1, end_dim=2)# 将image_through_conv通过展平层
image_through_conv_and_flatten = flatten_layer(image_through_conv)# 打印嵌入图像的形状
print(f'通过展平层的嵌入形状 -> {list(image_through_conv_and_flatten.shape)} <- [批大小, 补丁数量, 嵌入维度]')# 将嵌入图像赋值给一个变量
embedded_image = image_through_conv_and_flatten
通过卷积层的嵌入形状 -> [1, 768, 14, 14] <- [批大小, 补丁行数, 补丁列数, 嵌入维度]
通过展平层的嵌入形状 -> [1, 196, 768] <- [批大小, 补丁数量, 嵌入维度]
4.2 添加类别标记嵌入和位置编码嵌入
class_token_embeddings = nn.Parameter(torch.rand((1, 1,EMBEDDING_DIMS), requires_grad = True))
print(f'类别令牌嵌入的形状 --> {list(class_token_embeddings.shape)} <-- [批大小, 1, 嵌入维度]')embedded_image_with_class_token_embeddings = torch.cat((class_token_embeddings, embedded_image), dim = 1)
print(f'\n带有类别令牌嵌入的图像嵌入形状 --> {list(embedded_image_with_class_token_embeddings.shape)} <-- [批大小, 补丁数量+1, 嵌入维度]')position_embeddings = nn.Parameter(torch.rand((1, NUM_OF_PATCHES+1, EMBEDDING_DIMS ), requires_grad = True ))
print(f'\n位置嵌入的形状 --> {list(position_embeddings.shape)} <-- [批大小, 补丁数量+1, 嵌入维度]')final_embeddings = embedded_image_with_class_token_embeddings + position_embeddings
print(f'\n最终嵌入的形状 --> {list(final_embeddings.shape)} <-- [批大小, 补丁数量+1, 嵌入维度]')
`class_token_embeddings` 的形状 --> `[1, 1, 768]` <-- `[批大小, 1, 嵌入维度]`带有 `class_token_embeddings` 的图像嵌入形状 --> `[1, 197, 768]` <-- `[批大小, 补丁数量+1, 嵌入维度]``position_embeddings` 的形状 --> `[1, 197, 768]` <-- `[批大小, 补丁数量+1, 嵌入维度]``final_embeddings` 的形状 --> `[1, 197, 768]` <-- `[批大小, 补丁数量+1, 嵌入维度]`
将补丁嵌入层整合起来
我们将继承PyTorch的nn.Module来创建我们的自定义层,该层接收一张图像,并输出补丁嵌入,包括图像嵌入、类别标记嵌入和位置嵌入。
class PatchEmbeddingLayer(nn.Module):def __init__(self, in_channels, patch_size, embedding_dim,):super().__init__()self.patch_size = patch_sizeself.embedding_dim = embedding_dimself.in_channels = in_channelsself.conv_layer = nn.Conv2d(in_channels=in_channels, out_channels=embedding_dim, kernel_size=patch_size, stride=patch_size)self.flatten_layer = nn.Flatten(start_dim=1, end_dim=2)self.class_token_embeddings = nn.Parameter(torch.rand((BATCH_SIZE, 1, EMBEDDING_DIMS), requires_grad=True))self.position_embeddings = nn.Parameter(torch.rand((1, NUM_OF_PATCHES + 1, EMBEDDING_DIMS), requires_grad=True))def forward(self, x):output = torch.cat((self.class_token_embeddings, self.flatten_layer(self.conv_layer(x).permute((0, 2, 3, 1)))), dim=1) + self.position_embeddingsreturn output
让我们从我们的补丁嵌入层传递一批随机图像。
patch_embedding_layer = PatchEmbeddingLayer(in_channels=IMAGE_CHANNELS, patch_size=PATCH_SIZE, embedding_dim=IMAGE_CHANNELS * PATCH_SIZE ** 2)patch_embeddings = patch_embedding_layer(random_images)
patch_embeddings.shape
torch.Size([32, 197, 768])
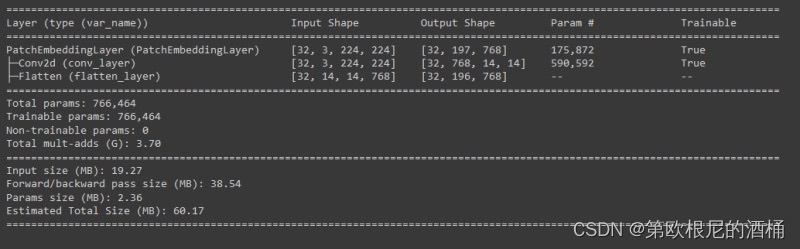
summary(model=patch_embedding_layer,input_size=(BATCH_SIZE, 3, 224, 224), # (batch_size, input_channels, img_width, img_height)col_names=["input_size", "output_size", "num_params", "trainable"],col_width=20,row_settings=["var_names"])
第六步 创建多头自注意力(Multi-Head Self Attention,MSA)块。
理解MSA块
作为将变换器块整合进视觉变换器模型的第一步,我们将创建一个多头自注意力块。
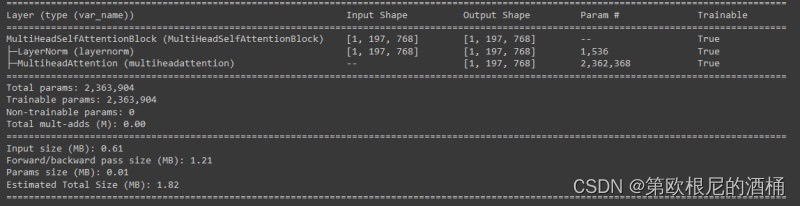
让我们花一点时间来理解MSA块。MSA块本身包含一个层归一化(LayerNorm)层和多头注意力层。层归一化层基本上是在嵌入维度上对我们的补丁嵌入数据进行规范化。多头注意力层接受输入数据作为三种形式的可学习向量,即查询(query)、键(key)和值(value),统称为qkv向量。这些向量共同构建了输入序列中每个补丁与同一序列中其他所有补丁之间的关系(因此得名自注意力)。
因此,我们输入MSA块的形状将是我们使用补丁嵌入层制作的补丁嵌入的形状 -> [批大小, 序列长度, 嵌入维度]。而从MSA层的输出形状将与输入形状相同。
MSA块代码
现在让我们开始编写我们MSA块的代码。这将是简短的,因为PyTorch已经有了LayerNorm和MultiHeadAttention层的预构建实现。我们只需要传递正确的参数以适应我们的架构。我们可以在原始ViT论文中的这张表格中找到我们MSA块所需的各种参数。
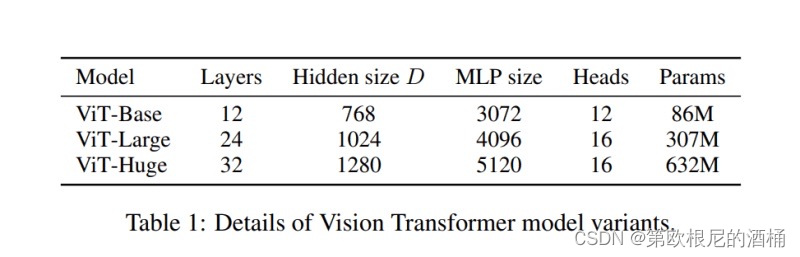
class MultiHeadSelfAttentionBlock(nn.Module):def __init__(self,embedding_dims = 768, # 隐藏尺寸D,来自ViT论文表1num_heads = 12, # 头的数量,来自ViT论文表1attn_dropout = 0.0 # 默认为零,因为根据ViT论文,MSA块没有dropout):super().__init__()self.embedding_dims = embedding_dimsself.num_head = num_headsself.attn_dropout = attn_dropoutself.layernorm = nn.LayerNorm(normalized_shape = embedding_dims)self.multiheadattention = nn.MultiheadAttention(num_heads = num_heads,embed_dim = embedding_dims,dropout = attn_dropout,batch_first = True,)def forward(self, x):x = self.layernorm(x)output,_ = self.multiheadattention(query=x, key=x, value=x,need_weights=False)return output
测试
multihead_self_attention_block = MultiHeadSelfAttentionBlock(embedding_dims = EMBEDDING_DIMS,num_heads = 12)
print(f'Shape of the input Patch Embeddings => {list(patch_embeddings.shape)} <= [batch_size, num_patches+1, embedding_dims ]')
print(f'Shape of the output from MSA Block => {list(multihead_self_attention_block(patch_embeddings).shape)} <= [batch_size, num_patches+1, embedding_dims ]')Shape of the input Patch Embeddings => [32, 197, 768] <= [batch_size, num_patches+1, embedding_dims ]
Shape of the output from MSA Block => [32, 197, 768] <= [batch_size, num_patches+1, embedding_dims ]
很好,看起来我们的MSA块正在工作。我们可以使用 torchinfo 获取有关 MSA 块的更多信息
summary(model=multihead_self_attention_block,input_size=(1, 197, 768), # (batch_size, num_patches, embedding_dimension)col_names=["input_size", "output_size", "num_params", "trainable"],col_width=20,row_settings=["var_names"])
第七步 创建机器学习感知器(Machine Learning Perceptron,MLP)块
理解MLP块
变换器中的机器学习感知器(MLP)块是一个全连接层(也称为线性层或密集层)和非线性层的组合。在ViT中,非线性层是一个GeLU层。
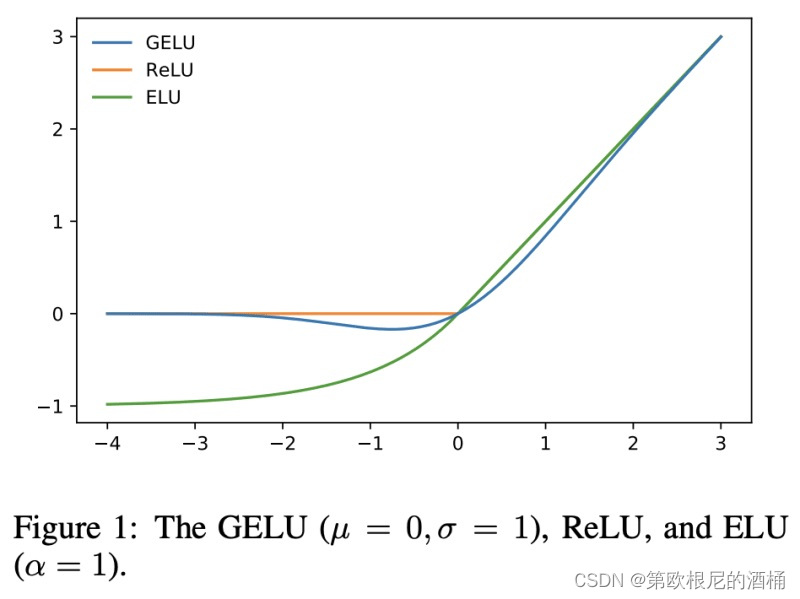

变换器还实现了一个Dropout层以减少过拟合。因此,MLP块将如下所示:
输入 → 线性 → GeLU → Dropout → 线性 → Dropout
根据论文,第一个线性层将嵌入维度扩展到3072维(对于ViT-16/Base)。Dropout设置为0.1,第二个线性层将维度缩减回嵌入维度。
MLP块代码
现在让我们组装我们的MLP块。根据ViT论文,从MSA块输出的内容加上输入到MSA块的内容(由模型架构图中的跳过/残差连接表示)作为输入传递给MLP块。所有层都由PyTorch库提供。我们只需要将它们组装起来。
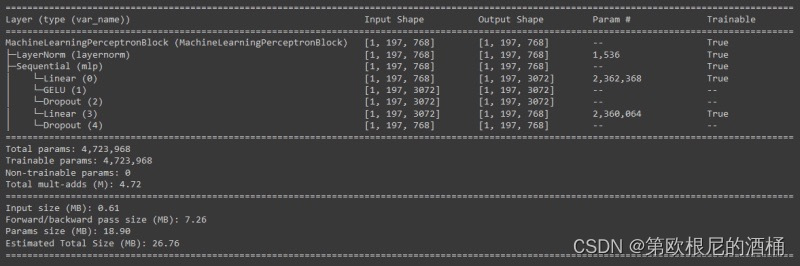
class MachineLearningPerceptronBlock(nn.Module):def __init__(self, embedding_dims, mlp_size, mlp_dropout):super().__init__()self.embedding_dims = embedding_dimsself.mlp_size = mlp_sizeself.dropout = mlp_dropoutself.layernorm = nn.LayerNorm(normalized_shape = embedding_dims)self.mlp = nn.Sequential(nn.Linear(in_features = embedding_dims, out_features = mlp_size),nn.GELU(),nn.Dropout(p = mlp_dropout),nn.Linear(in_features = mlp_size, out_features = embedding_dims),nn.Dropout(p = mlp_dropout))def forward(self, x):return self.mlp(self.layernorm(x))
测试
mlp_block = MachineLearningPerceptronBlock(embedding_dims = EMBEDDING_DIMS,mlp_size = 3072,mlp_dropout = 0.1)summary(model=mlp_block,input_size=(1, 197, 768), # (batch_size, num_patches, embedding_dimension)col_names=["input_size", "output_size", "num_params", "trainable"],col_width=20,row_settings=["var_names"])
第八步:集成组合
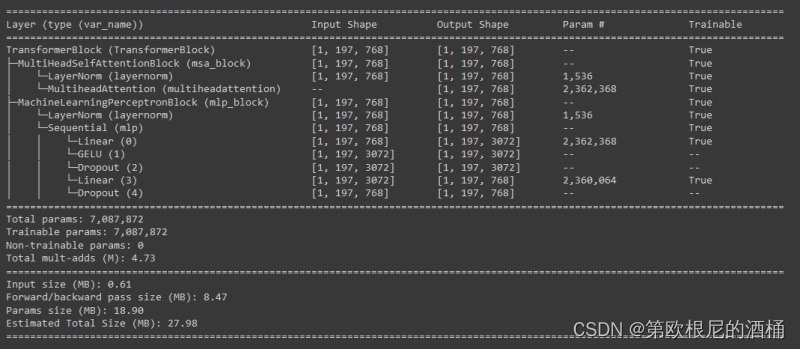
class TransformerBlock(nn.Module):def __init__(self, embedding_dims = 768,mlp_dropout=0.1,attn_dropout=0.0,mlp_size = 3072,num_heads = 12,):super().__init__()self.msa_block = MultiHeadSelfAttentionBlock(embedding_dims = embedding_dims,num_heads = num_heads,attn_dropout = attn_dropout)self.mlp_block = MachineLearningPerceptronBlock(embedding_dims = embedding_dims,mlp_size = mlp_size,mlp_dropout = mlp_dropout,)def forward(self,x):x = self.msa_block(x) + xx = self.mlp_block(x) + xreturn x测试
transformer_block = TransformerBlock(embedding_dims = EMBEDDING_DIMS,mlp_dropout = 0.1,attn_dropout=0.0,mlp_size = 3072,num_heads = 12)print(f'Shape of the input Patch Embeddings => {list(patch_embeddings.shape)} <= [batch_size, num_patches+1, embedding_dims ]')
print(f'Shape of the output from Transformer Block => {list(transformer_block(patch_embeddings).shape)} <= [batch_size, num_patches+1, embedding_dims ]')Shape of the input Patch Embeddings => [32, 197, 768] <= [batch_size, num_patches+1, embedding_dims ]
Shape of the output from Transformer Block => [32, 197, 768] <= [batch_size, num_patches+1, embedding_dims ]
summary(model=transformer_block,input_size=(1, 197, 768), # (batch_size, num_patches, embedding_dimension)col_names=["input_size", "output_size", "num_params", "trainable"],col_width=20,row_settings=["var_names"])
第九步:创建ViT模型
最后,让我们来组装我们的ViT模型。这将是非常简单的,只需将我们到目前为止所做的所有工作结合起来。我们将稍微增加一个分类器层。在ViT中,分类器层是一个简单的线性层,配有层归一化。分类是在变换器输出的零索引处进行的。
class ViT(nn.Module):def __init__(self, img_size = 224,in_channels = 3,patch_size = 16,embedding_dims = 768,num_transformer_layers = 12, # from table 1 abovemlp_dropout = 0.1,attn_dropout = 0.0,mlp_size = 3072,num_heads = 12,num_classes = 1000):super().__init__()self.patch_embedding_layer = PatchEmbeddingLayer(in_channels = in_channels,patch_size=patch_size,embedding_dim = embedding_dims)self.transformer_encoder = nn.Sequential(*[TransformerBlock(embedding_dims = embedding_dims,mlp_dropout = mlp_dropout,attn_dropout = attn_dropout,mlp_size = mlp_size,num_heads = num_heads) for _ in range(num_transformer_layers)])self.classifier = nn.Sequential(nn.LayerNorm(normalized_shape = embedding_dims),nn.Linear(in_features = embedding_dims,out_features = num_classes))def forward(self, x):return self.classifier(self.transformer_encoder(self.patch_embedding_layer(x))[:, 0])
summary(model=vit,input_size=(BATCH_SIZE, 3, 224, 224), # (batch_size, num_patches, embedding_dimension)col_names=["input_size", "output_size", "num_params", "trainable"],col_width=20,row_settings=["var_names"])
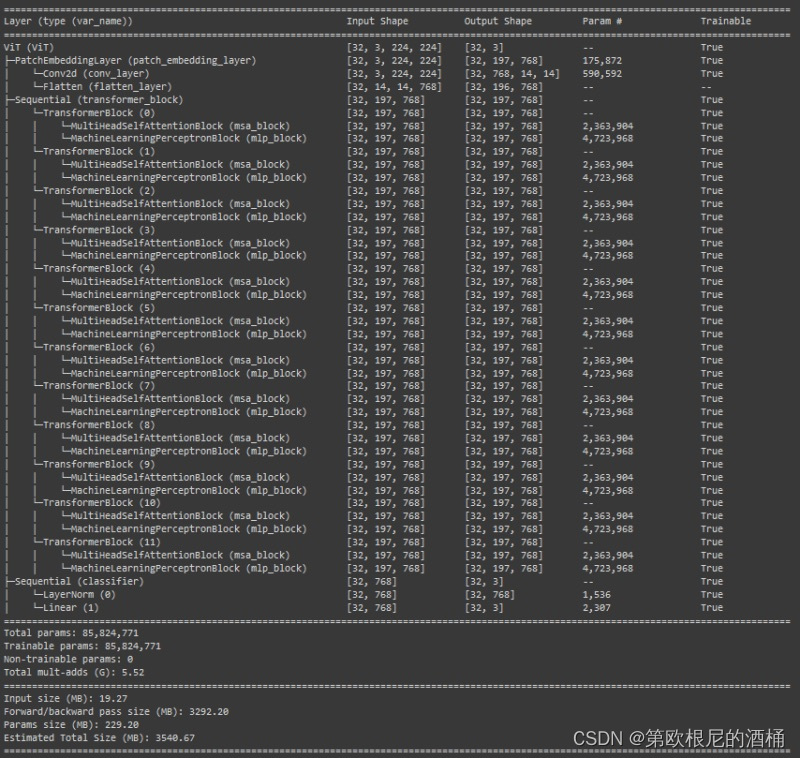
就是这样。现在,您可以像训练PyTorch中的任何其他模型一样训练这个模型。请告诉我这对您来说效果如何。我希望这个逐步指南帮助您理解了视觉变换器,并激发您更深入地探索计算机视觉和变换器模型的世界。借助获得的知识,您已经具备了推动计算机视觉发展和解锁这些开创性架构潜能的能力。
所以,继续前进,基于您所学到的知识,让您的想象力在利用视觉变换器应对激动人心的视觉挑战时自由发挥。编码愉快!
这篇关于基于pytorch的视觉变换器-Vision Transformer(ViT)的介绍与应用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





