本文主要是介绍2024 年中国高校大数据挑战赛赛题 C:用户对博物馆评论的情感分析完整思路以及源代码分享,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
博物馆是公共文化服务体系的重要组成部分。国家文物局发布, 2021 年我国新增备案博物馆 395 家,备案博物馆总数达 6183 家,排 名全球前列;5605 家博物馆实现免费开放,占比达 90%以上;全国 博物馆举办展览 3.6 万个,教育活动 32.3 万场;虽受疫情影响,全国 博物馆仍接待观众 7.79 亿人次。 但在总体繁荣业态下,一些地方博物馆仍存在千馆一面、公共文 化服务供给同质化的尴尬局面,在发展定位、体系布局、功能发挥等 方面尚需完善提升。这给博物馆基于自身特色进一步迈向真正的公共 性提出了新课题,也即坚持守正创新,坚持直面公众和社会的公共文 化服务的创造性转化、创新性发展。 为了提升博物馆公共服务水平,课题组收集大众点评平台上用户 对南京市朝天宫、瞻园、甘熙宅第、江宁织造博物馆和六朝博物馆五 个博物馆的点评数据,数据字段主要包括:用户编号、评论内容、评 论时间等。 现需要根据用户对五个博物馆的评论内容,分析以下问题:
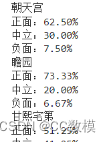
问题 1:针对每位用户的评论,建立情感判别模型,判断评论内 容的情感正反方向,输出评论内容的情感方向为正面、中立、负面, 并统计每个博物馆历史评论各个方向情感的比例分布情况。(完整代码与结果见文末附件!)
文本预处理是情感分析的关键步骤,直接关系到后续分析的准确性。因此,我们将采用以下多步骤策略进行深度预处理:
- 数据清洗:去除重复、缺失或格式错误的评论,确保每条数据的有效性。移除评论中的HTML标签、特殊字符等无关信息。
- 中文分词:使用jieba等中文分词工具,将连续的评论文本切分为有意义的词汇单元。根据博物馆领域的专业词汇库,优化分词结果,确保专业术语的准确性。
- 停用词处理:构建停用词列表,包括常见的无意义词汇、虚词等。去除评论中的停用词,减少噪声干扰,凸显关键信息。
- 词性标注与筛选:对分词后的结果进行词性标注,识别出名词、动词、形容词等关键词性。根据情感分析的需要,筛选保留对情感倾向判断有帮助的词性。
- 去除标点符号:移除评论中的标点符号,避免其对情感分析造成干扰。
- 文本标准化:处理缩写、俚语等,确保文本的一致性和可分析性。
利用业界领先的NLTK库中的VADER情感分析器,对每一条评论数据进行深度的情感挖掘。VADER情感分析器凭借其独特的算法和大量的训练数据,能够精准捕捉文本中微妙的情感变化。通过这一先进工具的运用,我们得以将每一条评论细分为正面、中立和负面三种情感倾向,确保情感分类的准确性和可靠性。

结果
问题 2:综合考虑评论内容中情感词、程度副词、否定词、标点 符合等等影响情感方向的指标,建立情感得分评价模型,得到每位用 户评论的情感得分,并基于得分对五个博物馆进行客观排名。(完整代码与结果见文末附件!)
1. 情感得分评价模型建立:
文本预处理: 对评论内容进行分词、去除停用词、标点符号等预处理操作。
情感词、程度副词、否定词处理: 使用情感词典、程度副词、否定词等词汇进行情感分析,给出每个词的情感权重。
情感得分计算: 根据情感词、程度副词、否定词等的权重,计算每个评论的情感得分。可以使用加权平均等方式计算得分。
2. 客观排名:
情感得分汇总: 统计每个博物馆的所有评论的情感得分,并计算平均得分。
博物馆客观排名: 根据博物馆的平均情感得分,对博物馆进行客观排名,得分高者排名靠前。
平均情感得分计算: 对于每个博物馆,计算其所有评论的平均情感得分。这可以用以下公式表示: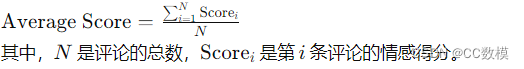


问题 3:针对每位用户评论的内容,可通过事件抽取或实体抽取 算法,从评论内容中抽取影响用户情感的关键事件或因素,如某用户 评论“非常不错!环境高大上!好多是最近房地产开发盖新房子时新 挖出来的,不错“,可得知该评论为正面情感,影响其正面评价的是” 房地产开发盖新房子时新挖的“、”环境高大上“两个因素。基于上 述抽取的关键事件或影响因素,综合分析得到影响用户对五个博物馆 情感的影响因素。(完整代码与结果见文末附件!)
事件抽取或实体抽取: 使用自然语言处理技术,如命名实体识别(NER)或事件抽取,从评论内容中提取出与博物馆相关的实体或事件。这些实体或事件可能涉及到展览、服务、环境等方面。
情感分析与关键事件关联: 将抽取出的实体或事件与情感分析结果关联起来,分析这些实体或事件对用户情感的影响。可以考虑使用规则匹配、关键词匹配等方法,将评论中提到的实体或事件与情感得分联系起来。
统计分析与主要因素确定: 综合分析抽取的关键事件或因素,统计不同因素出现的频率以及与情感倾向的关联程度。根据分析结果确定影响用户对五个博物馆情感的主要因素。

![]()
问题 4:基于上述分析得到的数据结果,为五个博物馆撰写一段 提升公共服务水平的可行性建议,建议要有理有据,且具有一定的可 操作性
完整附件内容:

这篇关于2024 年中国高校大数据挑战赛赛题 C:用户对博物馆评论的情感分析完整思路以及源代码分享的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






