本文主要是介绍MATLAB算法实战应用案例精讲-【智能优化算法】野马优化算法(WHO)(附MATLAB和Python源码),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
野马优化算法(Wild Horse Optimizer,WHO)是Iraj Naruei等人于2021年提出的一种新颖的智能优化算法。它的灵感来自于野马的社会生活行为。马通常成群生活,包括一匹种马和几匹母马和小马驹。野马表现出多种行为,例如放牧、追逐、支配、领导和交配行为。该算法在CEC2017和CEC2019等多组测试函数上进行了测试,并与流行的和新的优化方法进行了比较。结果表明,与其他算法相比,该算法具有很强的竞争力,可应用于工程优化问题。
野马优化算法的主要步骤如下:
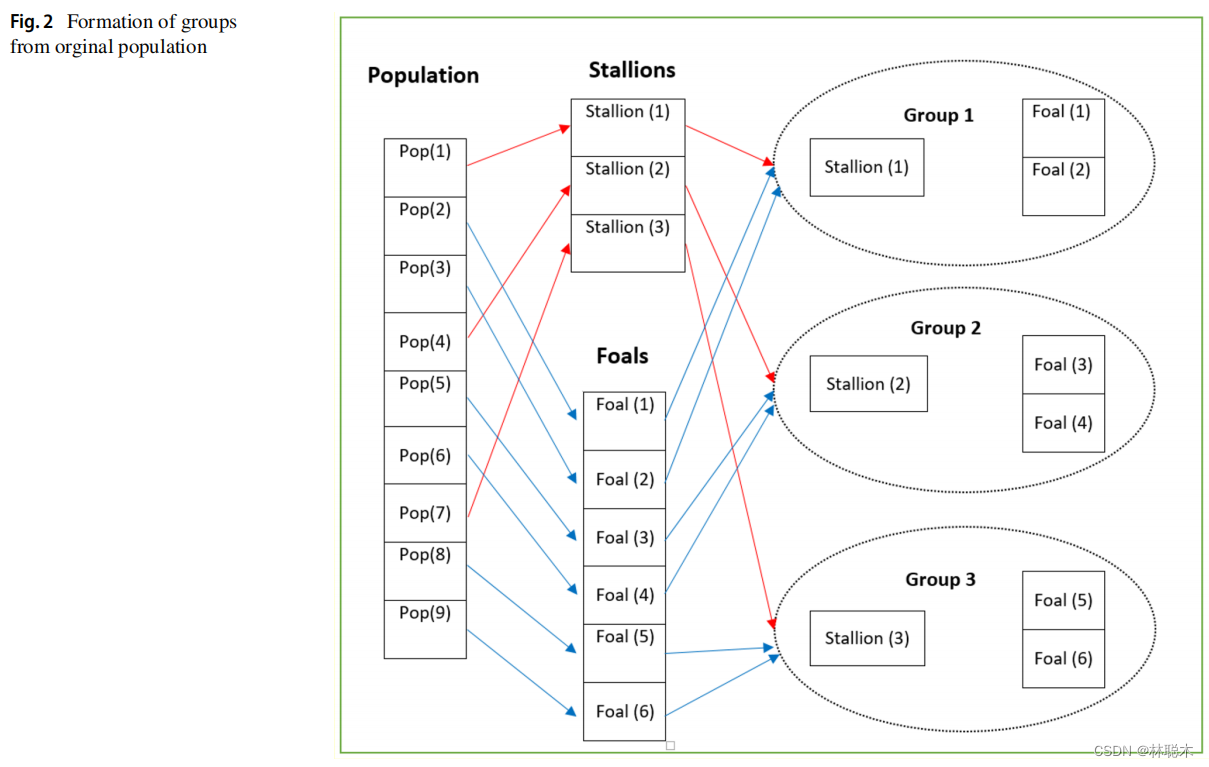
1.创建初始野马种群,形成马群和选择领导者;
2.马的放牧和交配;
3.领导和领导团队;
4.领导者的交流和选择;
5.保存最好的解决方案。
算法原理
算法思想


这篇关于MATLAB算法实战应用案例精讲-【智能优化算法】野马优化算法(WHO)(附MATLAB和Python源码)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





