本文主要是介绍FedDefender: Client-Side Attack-Tolerant Federated Learning,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
与现有的大部分方法不同,FedDefender是在客户端层面的防御机制。
方法叠的有点多

大部分方法都在④这一步防御,通过设计鲁邦的聚合策略等,但是本文通过修改本地训练策略,来更新模型,文章主要基于两个观点:
- 本地模型不容易过拟合噪声
- 知识蒸馏传递正确的全局信息
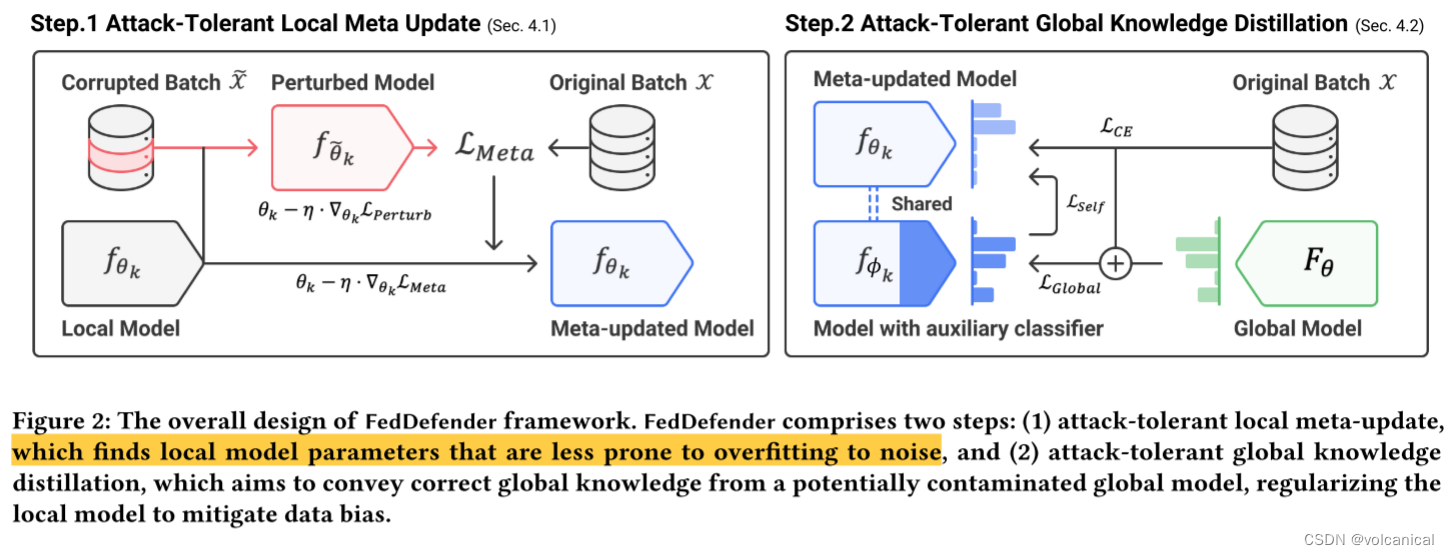
Step 1. 本地元更新
我们通过元学习以鲁棒的方式训练良性局部模型。目标是发现模型的参数,即使在被噪声信息干扰后也能产生准确的预测。为了实现这一点,首先生成一个有噪声的合成标签,然后应用一个梯度更新来扰动局部网络参数。然后,计算扰动网络预测正确输出的梯度,并利用梯度优化原始局部模型。
作者认为,用传统的损失函数训练得到的模型,很容易会对恶意用户产生的噪声过拟合,因此可以给局部模型“打疫苗”,先用生成的噪声去训练。
过多的扰动会使模型的决策边界过度变形,导致性能下降。为了减轻这种严重变形的风险,我们通过转移来自类似样本的标签来创建更逼真的噪声标签,这些标签类似于y的分布。
1. 得到 θ ~ k \tilde{\theta}_k θ~k
怎么做呢,就是用模型的特征提取层,就是中间随便找一层,得到特征分布,然后计算与他特征分布最接近top-k个,然后随机选择一个作为他的新标签。
因为是top-k个中随机选择一个,因此大部分选中的还是和他一样的标签,小概率选中其他的标签,就防止噪声过大了。
得到这个带有噪声的数据集之后,用这个数据集进行一次正常的梯度下降。
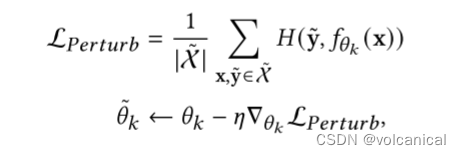
2. 用 θ ~ k \tilde{\theta}_k θ~k在原始数据集上训练,得到的梯度给 θ k \theta_k θk用
进行了一次正常的梯度下降,得到的模型我们称之为 θ ~ k \tilde{\theta}_k θ~k
然后就是,用这个使用噪声数据集训练一步的模型 θ ~ k \tilde{\theta}_k θ~k,去原始数据集 X \mathcal{X} X上算一个分类的损失,然后用这个损失,去更新原来的模型 θ k {\theta}_k θk。反正 θ ~ k \tilde{\theta}_k θ~k就只是个工具人,只是为了训练出来,然后计算他在原始数据集上的梯度,将它的梯度给本来的模型用。具体为什么论文也没说。就说这样可以防止局部模型在训练过程中受到合成噪声的污染。
因为 θ ~ k \tilde{\theta}_k θ~k可以将噪声正确的区分?所以 θ ~ k \tilde{\theta}_k θ~k的梯度比较好用吗。
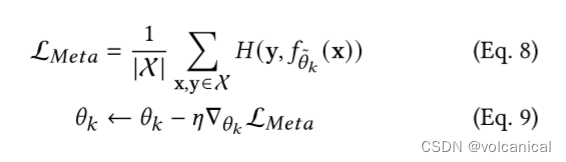
Step 2. 全局知识蒸馏
1. 辅助网络知识蒸馏
考虑到上一步的元更新局部模型,我们使用中间特征映射将全局知识蒸馏应用于辅助分类器,以抵消对污染全局模型的不利影响。在辅助分类器和原始分类器之间进行自知识蒸馏,进一步将全局知识整合到局部模型的更深层中。
深层神经网络中的深层更容易过度拟合噪声(即记忆),这是由于基于梯度下降的优化的固有性质。在这种情况下,FedDefender将全局知识转移到局部模型的浅层中间部分,以减少虚假信息的不利影响。
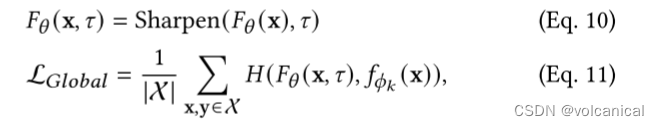
将一个模型分成两部分,全部模型和中间部分,用全部模型的输出当教师网络去训练中间层,这一部分设计知识蒸馏,不太懂。
然后又生成一个新的数据集 X ^ \hat{\mathcal{X}} X^, X ^ \hat{\mathcal{X}} X^里的 y ^ \hat{y} y^是如下公式替换的:
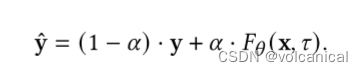
就是计算全局模型的输出和真实的标签的余弦相似度,修正一下标签。
然后上面的公式11就变成了
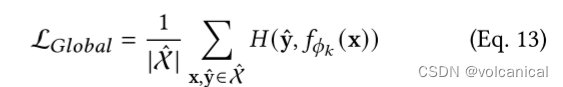
2. 辅助自蒸馏

看不下去了,这部分先放着
这一套组合拳,光损失就有五个,我都不敢想时间复杂度有多高。
这篇关于FedDefender: Client-Side Attack-Tolerant Federated Learning的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









