本文主要是介绍零售场景梳理和运筹优化工作经验总结,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 亡羊补牢不为迟
- 零售行业规模大
- 卷出零售新高度
- 运筹优化实践经验
亡羊补牢不为迟
由于工作岗位变动的缘故,暂时要告别零售场景了。当初自己没想太多就一头扎进了“新”零售这个场景,迄今为止都没有针对零售场景做一个通盘的梳理,现在补回来,以期给后入者一个参考。
但其实,也没必要苛责自己。当初作为一个刚出校门的小白,没有贵人指点,本就很难做出全面的判断。大多数人都是边走边看边思考,唯一不同的是,我还希望把思考的结果梳理出来,然后传递给每一个可能需要的人。观点可能不全面甚至不对,但也是一个过来人的心得体会,最差也能作为大家做判断时的一个输入,哈哈。
好了,进入正题。
零售行业规模大
根据2021年10月开始实施的国家标准《零售业态分类(GB/T 18106-2021)》,零售主要指的是面向最终消费者(如居民等)的消费活动。按照有无固定营业场所,可以分为有店铺零售和无店铺零售两大类。其中,有店铺零售可以细分为便利店、超市、折扣店、仓储会员店、百货店、购物中心、专业店、品牌专卖店、集合店和无人值守商店等10种零售业态;无店铺零售包含网络零售、电视/广播零售、邮寄零售、无人售货设备零售、直销、电话零售、流动货摊零售等7种零售业态。

接下来通过一组数据直观感受一下零售行业的规模。此处,我们姑且假设网上零售等同于网络零售,并且社会消费品零售等同于零售大盘(因为没有查到网络零售和零售大盘的直接数据)。
| 年份 | 网上零售额(万亿) | 社会消费品零售总额(万亿) | 网上零售占比 | GDP(万亿) | 零售/GDP |
|---|---|---|---|---|---|
| 2017 | 7.2 | 35 | 0.21 | 83 | 0.42 |
| 2018 | 9.0 | 38 | 0.24 | 92 | 0.41 |
| 2019 | 10.6 | 41 | 0.26 | 99 | 0.41 |
| 2020 | 11.8 | 39 | 0.30 | 102 | 0.38 |
| 2021 | 13.1 | 44 | 0.30 | 114 | 0.39 |
| 2022 | 13.8 | 44 | 0.31 | 121 | 0.36 |
从上表中,至少可以得到三个结论:
(1)零售在GDP中占比约40%。这是一个非常大的比重了。所以这件事情本身,确实是非常重要的,直接关系着国计民生。
(2)2022年网上零售额的绝对值为13.8万亿。这个数值可能还是不太直观,我们再稍微对比一下。沃尔玛是薄利多销的代表,其在2022年的总销售额5727.54万亿美元,净利润为136.76亿美元,利润率为2.4%。即使我们降低利润率至1%,那么13.8万亿销售额也可以带来1千亿+的净利润。京东是“2022中国网络零售TOP100”中的第1名,其年销售额为8千亿+元,按照1%标准转化为利润的话,预计可达80亿+元。所以该场景对公司来说是非常有吸引力的。
(3)网上零售额在整个零售中占比约30%,增速逐渐趋0。这个和我们的直觉是不太一致的,如火如荼的互联网+,经过国内互联网大厂对零售行业十余年的改造,才将网络占比变为30%。根据中国互联网络信息中心发布的《第51次中国互联网络发展状况统计报告》,截至2022年12月,中国网民数量为10.67亿,网络购物用户为8.45亿。所以人口基数已经非常庞大,再想提升网上购物的占比,困难重重。市场没有了增量,公司为了各自发展,就只能“互卷”了。
卷出零售新高度
既然要卷,首先就得知道零售可以朝哪些方向卷,那就必须理清楚零售的发展历史。这里比较推荐刘润的《新零售:低价高效的数据赋能之路》,本节主要基于该书的内容,进行梳理。
零售被定义为连接“人”与“货”的“场”。最早的场是集市;然后增加了百货商场和连锁超市等;现在又增加了电商平台。随着场的演变,能够被连接的“货”的种类变多了,“人”的规模也变多了。
接下来分别从“人”、“货”和“场”来理解一下零售。
人:流量 × 转化率 × 客单价 × 复购率 人:流量\times转化率\times客单价\times复购率 人:流量×转化率×客单价×复购率
这个比较容易理解,就不多赘述了。
货: D − M − S − B − b − C 货:D-M-S-B-b-C 货:D−M−S−B−b−C
D=Design,设计;M=Manufacture,制造商;S=Supply Chain,供应链;B=Business,大商场;b=business,小商店;C=consumer,消费者。
以上是一件商品从设计、生产到消费市场的完整链条。
场:信息流 + 资金流 + 物流 场:信息流+资金流+物流 场:信息流+资金流+物流
这是个新定义,举个例子说明一下,我们去超市买某件商品,会摸一摸手感品质,看一看是否过期等,这是“信息流”;觉得不错,把它放进购物车,推到收银台付钱,这是“资金流”;购买后,自己开车或者坐超市班车回家,这是“物流”。
有了以上的基本认知后,我们看一下,到目前为止零售都有了哪些新玩法。
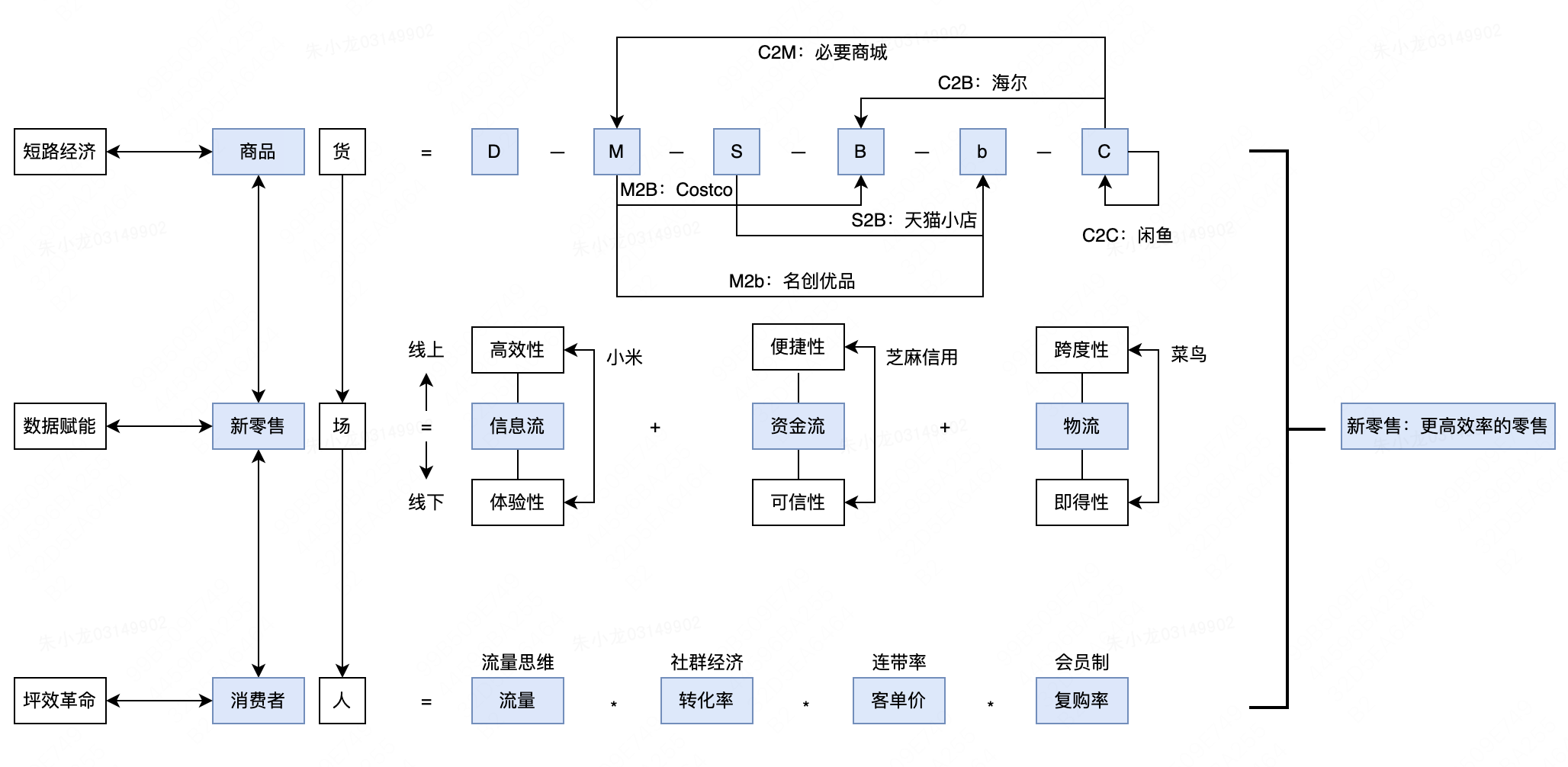
为了便于理解,此处举个实例:Costco。Costco是世界第二大零售商,在2017年《财富》美国500强排行榜中,Costco名列第16位。在短路经济方面,Costco直接从制造商(M)采购,陈列在自己的卖场(B)里,短路了中间的供应链(S),提升了链条的效率,属于M2B;在数据赋能方面,Costco会通过大数据选择它认为有“爆款”潜质的商品上架,且包装大,量也足,能给消费者带来极好的体验;在坪效方面,通过会员制,提升了转化率和客单价,低价格高品质又能促进复购率,使得其坪效可以达到沃尔玛的2倍。
Costco代表的是一种以会员制为基础的零售方式。其核心盈利模式不在于商品本身带来的利润,而是会员费的收入。该模式目前已经基本跑通,类似的公司还有沃尔玛的山姆。
国内比较火的另外两种零售模式是:即时零售和社区团购。即时零售主打的是半小时/一小时达,目前做的有模有样的公司有盒马鲜生、叮咚买菜、美团买菜和朴朴超市等。该模式目前还没有完全跑通,各个公司都有不同程度的亏损,之前凉凉的每日优鲜就是一个例子。
社区团购的灵魂是价格实惠。在2020年前后,有大批玩家入局社区团购,比如兴盛优选、十荟团、京喜拼拼、淘菜菜、美团优选和多多买菜等。不过该模式烧钱太快,到现在为止也没找到盈利的门道,目前在市面上还占比较大份额的就只剩美团优选和多多买菜了。
运筹优化实践经验
鉴于零售行业的大规模,以及持续探索的“新”零售,运筹优化的相关算法是有一定发挥空间的。如果看零售的那张大图,其实很容易发现,运筹优化算法能够发挥的地方,主要是短路经济中的S模块,即供应链优化。
从问题场景来看,运筹优化可以应用于门店选址/规划,提升营业收入;可以应用于人员排班/定编,提升人效;可以应用于人力/资源的实时/定时调度,提升自动化效率和最优性。
从技术栈使用频率来看,最广泛被用到的的两大类算法是整数规划和启发式算法,梯度类算法较少涉及。
从关联技术来看,结合度最高的是机器学习算法,很多地方都需要预测的结果作为运筹优化算法模型的输入之一。
从实践难度来看,相比最佳的建模设计,落地后的算法采纳率往往是个更大的挑战。
造成这个现象的主要原因,目前的理解是:问题本身可能确实是个比较复杂的,但是在添加了比较多的现实约束后,问题被退化为了规模比较小的问题,业务侧基于自身经验设计的算法效果已经很好,算法能够带来的额外收益较小,甚至会降低业务侧的灵活性。
从价值体现来看,对业务有提升,但其上限大概率受限于具体的运营模式和流程;提升点主要表现在两个方面:流程自动化和结果指标更优。
这篇关于零售场景梳理和运筹优化工作经验总结的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




