本文主要是介绍【已解决】RuntimeError: Trying to backward through the graph a second time (or directly access saved tens,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
问题描述
Traceback (most recent call last):
File "/home/sysu/qfy/project/GCL/GCL/Main.py", line 281, in <module>
main(args)
File "/home/sysu/qfy/project/GCL/GCL/Main.py", line 200, in main
loss, Matrix = train(encoder_model, args, data, optimizer, epoch)
File "/home/sysu/qfy/project/GCL/GCL/Main.py", line 153, in train
loss.backward()
File "/home/sysu/qfy/anaconda3/envs/gclv1/lib/python3.8/site-packages/torch/_tensor.py", line 487, in backward
torch.autograd.backward(
File "/home/sysu/qfy/anaconda3/envs/gclv1/lib/python3.8/site-packages/torch/autograd/__init__.py", line 200, in backward
Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
RuntimeError: Trying to backward through the graph a second time (or directly access saved tensors after they have already been freed). Saved intermediate values of the graph are freed when you call .backward() or autograd.grad(). Specify retain_graph=True if you need to backward through the graph a second time or if you need to access saved tensors after calling backward.
解决办法
1、解决方法直出
为什么会报这个错,这个错翻译成白话文就是说:当我们第二次backward的时候,计算图的结构已经被破坏了(buffer的梯度被释放了),这也是pytorch动态图的机制,可以节省内存。
在pytorch的计算图中,其实只有两种元素:tensor和function,function就是加减乘除、开方、幂指对、三角函数等可求导运算,而tensor可细分为两类:叶子节点(leaf node)和非叶子节点。使用backward()函数反向传播计算tensor的梯度时,并不计算所有tensor的梯度,而是只计算满足这几个条件的tensor的梯度:1.类型为叶子节点、2.requires_grad=True、3.依赖该tensor的所有tensor的requires_grad=True。
而报这个错的原因很简单,就是在进行训练的时候,由于是在下一次循环的时候前一次的计算图已经被释放了,所以下次计算就会出现问题,那怎么办呢?就把计算图保留下来就可以了
.backward()
改为
.backward(retain_graph=True)
这个时候就不会再出错了
2、示例程序:在占用较少缓存情况下进行更新 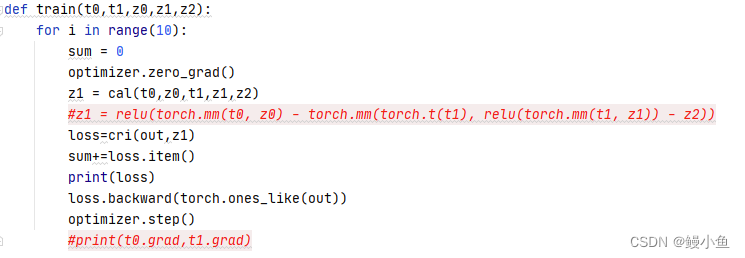
def train(t0,t1,z0,z1,z2):for i in range(10): #迭代10次sum = 0optimizer.zero_grad() #梯度清零z1 = cal(t0,z0,t1,z1.data,z2) #调用函数计算z1#z1 = relu(torch.mm(t0, z0) - torch.mm(torch.t(t1), relu(torch.mm(t1, z1.data)) - z2))loss=cri(out,z1) #计算反向传播的losssum+=loss.item() #loss值计算print(loss) loss.backward(torch.ones_like(out)) #反向传播,里面参数设置可以自行查阅optimizer.step() #梯度更新print(t0.grad,t1.grad) #打印需要更新的参数的梯度————————————————
版权声明:本文为CSDN博主「toroxy」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/toro12306/article/details/121094110很明显可以看出来,再循环中是要对z1进行更新的
z1是通过 z1 = cal(t0,z0,t1,z1,z2) 得到的,这里z1是已经定义了的变量,但是经过这个公式又把z1更新覆盖了,虽然说这个错误可以在最后loss.backward()函数里加上retain_graph=Ture,即loss.backward(retain_graph=Ture)解决,但是这会增加显存的使用,明显当任务需要较大的计算量时,这是不合理的,所以这种方案并不是最优的。
而我的解决方案是对 z1 = cal(t0,z0,t1,z1,z2) 进行了简单的修改,只需要在我们需要更新的参数,这里是z1,后面加上 .data 即可,此时这句变为了 z1 = cal(t0,z0,t1,z1.data,z2),这样不会报错,并且显存占用也很少,这样做的原因我觉得和with torch.no_grad()类似,这里进行计算的z1.data数据是不存在梯度的,在整个计算过程中也是不存在梯度的,而这里的z1本身又是中间变量,没有梯度,也不需要求梯度,所以此方法可行。
发现可以收敛,参数正常更新,也不会报错。
其他建议
这个错误表明在你的代码中尝试对计算图进行第二次反向传播,或者在计算图中的某些保存的中间值已经被释放后,再次尝试访问它们。这通常是由于没有正确处理计算图的释放或者多次反向传播导致的。
以下是一些建议来解决这个问题:
1、确保只调用一次 backward:
在你的代码中,确保只调用了一次 loss.backward()。如果你在训练循环中多次调用了 backward,这可能导致问题。
2、检查是否需要 retain_graph:
如果你在训练循环中有多个优化步骤,确保你在每个步骤中都使用了新的输入,或者使用了 retain_graph=True 参数来保留计算图,以便多次反向传播。loss.backward(retain_graph=True)
请注意,使用 retain_graph=True 可能会导致 GPU 内存占用增加,因此要小心使用。
3、释放不再需要的变量:
在训练循环结束时,确保释放不再需要的中间变量,可以使用 del 关键字或者将其设置为 None。
# 释放不再需要的变量 intermediate_result = None
4、检查模型和优化器的状态:
在训练循环结束时,确保你的模型和优化器都处于正确的状态。你可能需要在每个训练步骤之前调用 optimizer.zero_grad() 来清除梯度。optimizer.zero_grad()
5、使用 PyTorch 内置调试工具:
使用 torch.autograd.detect_anomaly() 来捕捉异常的计算图操作。这有助于定位导致问题的操作。原理可参考下图
完结撒花
如果总和一个经常闹矛盾的人打交道,两个人中至少有一个不正常!
这篇关于【已解决】RuntimeError: Trying to backward through the graph a second time (or directly access saved tens的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






