runtimeerror专题

解决RuntimeError: Numpy is not available
运行项目时,遇到RuntimeError: Numpy is not available 这是因为Numpy 版本太高,将现有Numpy卸载 pip uninstall numpy 安装numpy=1.26.4,解决此问题 pip install numpy=1.26.4 -i https://pypi.tuna.tsinghua.edu.cn/simple

解决报错“RuntimeError: CUDA error: device-side assert triggered ”
这是一个比较通用的错误,通常发生在以下几种情况下: 索引超出范围:在某些情况下,操作涉及的张量索引超出了允许的范围。例如,使用 index_select 或 gather 时,索引可能超出张量的范围。非法操作:例如对负数取对数、零除法,或对概率分布应用 log 函数时存在无效值(例如 0)。数据类型或维度不匹配:操作的输入张量可能在维度或数据类型上不匹配,这会触发设备端的断言。类别标签非法:如果
RuntimeError: invalid argument 4: out of range at pytorch/torch/lib/TH/generic/THTensor.c:439
使用from torchvision.utils import save_image保存图像时,出现错误: File “/usr/local/lib/python2.7/dist-packages/torchvision/utils.py”, line 51, in save_image grid = make_grid(tensor, nrow=nrow, padding=padding)
解决:RuntimeError: “slow_conv2d_cpu“ not implemented for ‘Half‘的方法之一
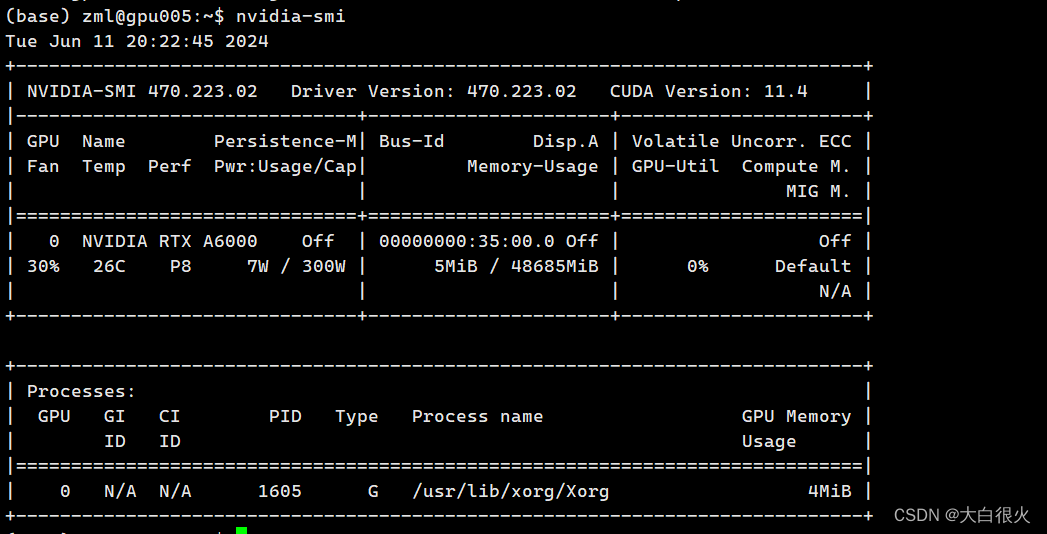
1. 问题描述 今天跑实验的时候,代码报错: RuntimeError: "slow_conv2d_cpu" not implemented for 'Half' 感觉有点莫名奇妙,经检索,发现将fp16改为fp32可以解决我的问题,但是运行速度太慢了。后来发现,是系统内核自动升级,导致显卡驱动与内核驱动不匹配。验证是否是该问题,可在命令行输入nvidia-smi来验证,若出现: NVI
![已解决Error || RuntimeError: size mismatch, m1: [32 x 100], m2: [500 x 10]](https://img-blog.csdnimg.cn/direct/aa86eef0d81e4f279688a772e92ea3bc.webp#pic_center)
已解决Error || RuntimeError: size mismatch, m1: [32 x 100], m2: [500 x 10]
已解决Error || RuntimeError: size mismatch, m1: [32 x 100], m2: [500 x 10] 原创作者: 猫头虎 作者微信号: Libin9iOak 作者公众号: 猫头虎技术团队 更新日期: 2024年6月6日 博主猫头虎的技术世界 🌟 欢迎来到猫头虎的博客 — 探索技术的无限可能! 专栏链接: 🔗 精选专栏:
Pytorch中“RuntimeError: Input, output and indices must be on the current device“问题解决
问题描述 昨天跟着一篇博客BERT 的 PyTorch 实现从头写了一下BERT的代码,因为原代码是在CPU上运行的,于是就想将模型和数据放到GPU上来跑,会快一点。结果,在将输入数据和模型都放到cuda上之后,仍然提示报错: "RuntimeError: Input, output and indices must be on the current device" 原因与解决方法 通

RuntimeError: leaf variable has been moved into the graph interior(Pytorch报错)
有时候想在pytorch中修改训练过程中网络模型的参数。比如做网络稀疏化训练,对于某一层卷基层的参数,如果值小于一定阈值就想赋值为0,这时就需要实时修改网络模型的参数,如果直接修改会报错: RuntimeError: leaf variable has been moved into the graph interior 这是因为pytorch中会有叶子张量和非叶子张量之分,这

RuntimeError: CUDA out of memory. Tried to allocate 1.77 GiB?如何解决
🏆本文收录于「Bug调优」专栏,主要记录项目实战过程中的Bug之前因后果及提供真实有效的解决方案,希望能够助你一臂之力,帮你早日登顶实现财富自由🚀;同时,欢迎大家关注&&收藏&&订阅!持续更新中,up!up!up!! 问题描述 mmdetection运行mask rcnn,训练模型时运行train.py出现RuntimeError: CUDA out of memory. T
Pycharm debug 运行报错 (RuntimeError: cannot release un-acquired lock)
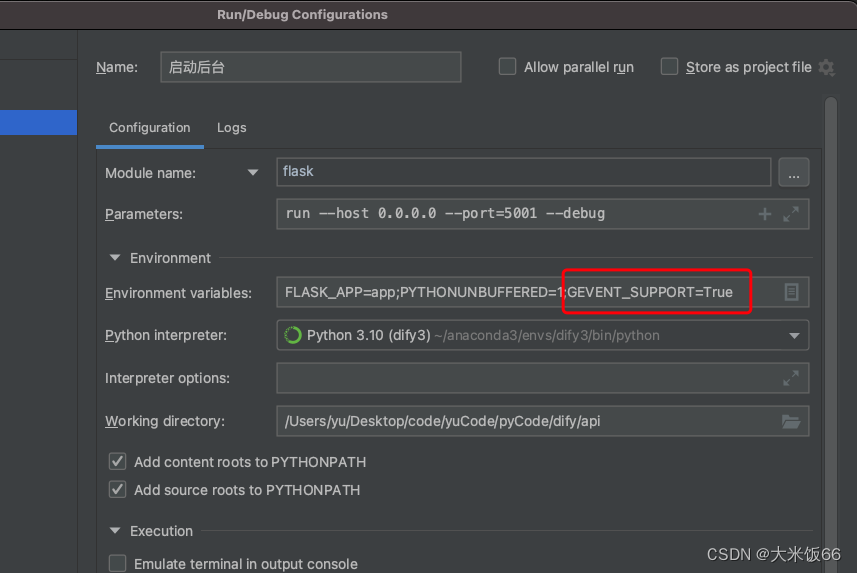
问题描述: 最近再跑一个 flask应用,Pycharm 运行没问题,debug断点启动时报错 如下: 解决方案: 在环境变量中增加 GEVENT_SUPPORT=True 启动成功!

解决RuntimeError: cuDNN error: CUDNN_STATUS_EXECUTION_FAILED
下图说明在一瞬间我的GPU就被占满了 我的模型在训练过程中遇到了 CUDA 相关的错误,这是由于 GPU资源问题或内存不足导致的。这类错误有时候也可能是由于某些硬件兼容性问题或驱动程序问题引起的。 为了解决这个问题,可以尝试以下几个解决方案: 降低批次大小:减小批次大小可以减少每次迭代对 GPU 内存的需求,有助于避免内存不足的问题。确保足够的 GPU 内存:确保在训练开始前没
pytorch 训练/测试模型时错误:RuntimeError: CUDA error: out of memory
方法1:batch-size设置多小 方法2: with torch.no_grad():net = Net()out = net(imgs) 积累的梯度应该是会一直放在显存里的...用了这一行就会停止自动反向计算梯度 方法3: 设置cpu来加载模型: model_path = 'path/to/model.pt' model = UNet(n_channels = 1, n_c
【Pytorch报错】RuntimeError: cuDNN error: CUDNN_STATUS_INTERNAL_ERROR
报错信息: File "/root/miniconda3/lib/python3.8/site-packages/torch/nn/modules/conv.py", line 297, in _conv_forwardreturn F.conv1d(input, weight, bias, self.stride,RuntimeError: CUDA error: CUBLAS_STATUS
pytorch训练模型遇到RuntimeError: inconsistent tensor错误
问题描述: 训练resnet模型,使用torchvision的ImageFolder来创建训练和测试集的DataLoader,然后训练模型的时候,出现RuntimeError: inconsistent tensor错误. 解决措施: 在transforms.Compose()中,transforms.Resize(224)后面跟一个transforms.CenterCrop(224)操作

RuntimeError: cuda runtime error (30)解决
程序出错如上,而且总是伴随着黑屏,一开始以为是cuda跑出问题,而且该问题必须重启才能解决,但是一直很好奇我的电脑Ubuntu18.04设置了黑白屏从不,还是出现该错误,最后为了复现该错误就强制锁屏,果然错误复现。找到原因之后就可以比较好解决,该死的Ubuntu18.04锁屏是在挂起里面设置,不是空白屏幕这里设置。重新设置了从不挂起解决问题。主要是锁屏之后显卡也进入休眠模式,导致出错!!!!!

RuntimeError: “addmm_impl_cpu_“ not implemented for ‘Half‘解决方案
大家好,我是爱编程的喵喵。双985硕士毕业,现担任全栈工程师一职,热衷于将数据思维应用到工作与生活中。从事机器学习以及相关的前后端开发工作。曾在阿里云、科大讯飞、CCF等比赛获得多次Top名次。现为CSDN博客专家、人工智能领域优质创作者。喜欢通过博客创作的方式对所学的知识进行总结与归纳,不仅形成深入且独到的理解,而且能够帮助新手快速入门。 本文主要介绍了RuntimeError: “a
RuntimeError: Attempted to send CUDA tensor received from another process
训练模型时报错: RuntimeError: Attempted to send CUDA tensor received from another process; this is not currently supported. Consider cloning before sending. 翻译:RuntimeError:尝试发送从其他进程接收的 CUDA 张量;目前不支持此
RuntimeError: Library cublas64_12.dll is not found or cannot be loaded
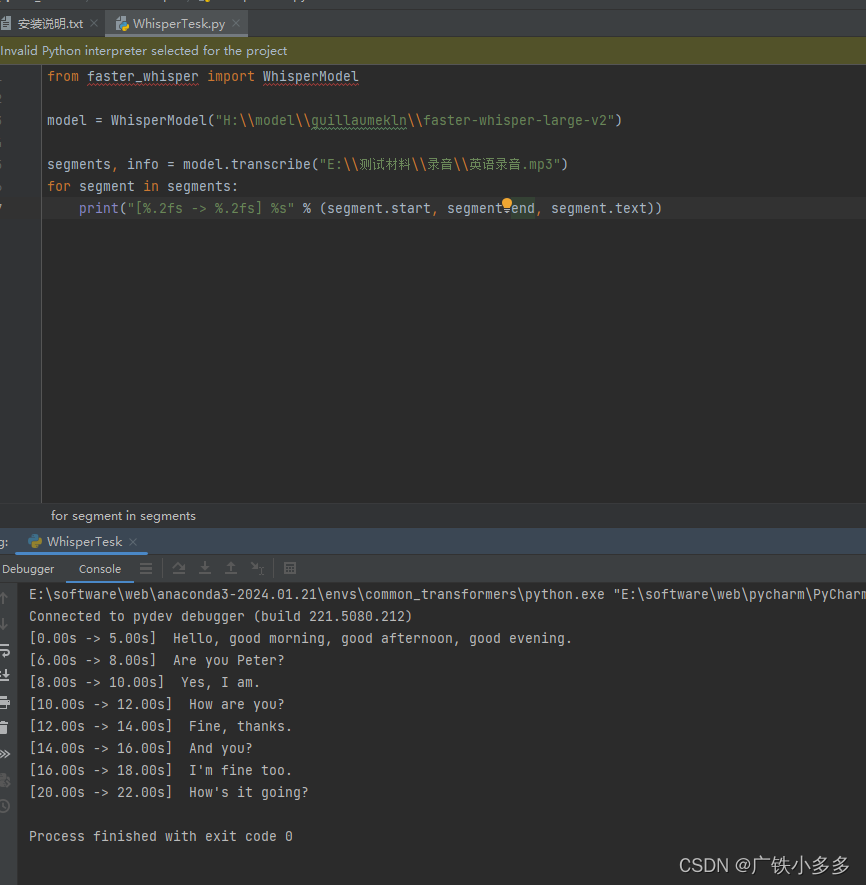
运行guillaumekln/faster-whisper-large-v2模型进行语音识别的时候报错了 RuntimeError: Library cublas64_12.dll is not found or cannot be loaded 代码: from faster_whisper import WhisperModelmodel = WhisperModel("H:\\mode

猫头虎博主分享运维技巧: 解决RuntimeError: Expected all tensors to be on the same device
博主猫头虎的技术世界 🌟 欢迎来到猫头虎的博客 — 探索技术的无限可能! 专栏链接: 🔗 精选专栏: 《面试题大全》 — 面试准备的宝典!《IDEA开发秘籍》 — 提升你的IDEA技能!《100天精通鸿蒙》 — 从Web/安卓到鸿蒙大师!《100天精通Golang(基础入门篇)》 — 踏入Go语言世界的第一步!《100天精通Go语言(精品VIP版)》 — 踏入Go语言世界的第二步!
运行pytorch作业出现错误 RuntimeError: unable to write to file
运行pytorch作业出现错误 RuntimeError: unable to write to file · Issue #26 · huaweicloud/dls-example · GitHub pytorch将共享内存的临时文件保存在了/torch_xxx文件中,即容器中的根目录下。容器磁盘空间不足导致该问题的发生。目前可以通过以下代码暂时关闭pytorch的shared memory功

(2019.10.10已解决)DolphinDB RuntimeError: Server Exception in run: table file does not exist:
如题所示,报错提醒确实文件,但实际上我文件夹内是有这个文件的。 原因是文件路径问题,将D:\DolphinDB改为D:/DolphinDB就可以了
RuntimeError:can not open CFlow file in line 338 of file 解决方法
问题 RuntimeError:can not open CFlow file in line 338 of file ..\..\source\userapi_se\ThostFtdcUserApiImplBase.cpp 原因 当前 .py 文件的执行目录下没有 flow 目录 解决方法 获取当前 .py 文件的执行目录,然后在该目录下创建 flow 文件夹 获取当前 .py 文件
成功解决RuntimeError: OpenSSL 3.0‘s legacy provider failed to load
报错 RuntimeError: OpenSSL 3.0's legacy provider failed to load. This is a fatal error by default, but cryptography supports running without legacy algorithms by setting the environment variable CRYPTO

RuntimeError: module compiled against API version 0xc but this version of numpy is 0xb
之前跑的好好的代码,今天一跑竟然报错了。最近总是这样,前一天跑的好好的,第二天就会出现奇奇怪怪的报错。 有一行提示 UserWarning: NumPy 1.14.5 or above is required for this version of SciPy (detected version 1.13.1)。 首先,通过以下代码查看numpy版本 conda activate pytor

BUG:RuntimeError: input.size(-1) must be equal to input_size. Expected 1, got 3
出现的bug为:RuntimeError: input.size(-1) must be equal to input_size. Expected 1, got 3 出现问题的截图: 问题产生原因:题主使用pytorch调用的nn.LSTM里面的input_size和外面的数据维度大小不对。问题代码如下: self.lstm = nn.LSTM(input_size, hidden_siz
【E20002】RuntimeError: call aclnnAddmm failed
报错如下: RuntimeError: call aclnnAddmm failed, detail:E20002: Value [/usr/local/Ascend/nnrt/7.0.0/opp/] for environment variable [ASCEND_OPP_PATH] is invalid when load buildin op store.Solution: Reset t
RuntimeError: expected scalar type Byte but found Float
部分代码如下 for data in train_loader:imgs, targets = data# print("标签为", targets.shape)imgs.byte()output = unet_l2(imgs)loss = criterion(output, targets)optimizer.zero_grad()loss.backward()optimizer.step()