backward专题
【规律题】Backward Digit Sums
【POJ3187】【洛谷1118】Backward Digit Sums Time Limit : 2000/1000ms (Java/Other) Memory Limit : 131072/65536K (Java/Other) Problem Description FJ and his cows enjoy playing a mental game. They write do

uva 10623 - Thinking Backward(数学)
题目链接:uva 10623 - Thinking Backward 题目大意:就是给出N,表示要将平面分解成N份,问有哪些可选则的方案,m表示椭圆、n表示圆形、p表示三角形的个数,m、n、p分别给定范围。 解题思路:本来这题一点思路都没有,但是在论坛上看到一个公式N=2+2m(m−1)+n(n−1)+4mn+3p(p−1)+6mp+6np 这样只要枚举m和p,求解n,判断n是否满

理论学习:optimizer.zero_grad() loss.backward() optimizer.step()
optimizer.zero_grad(): 在开始一个新的迭代之前,需要清零累积的梯度。这是因为默认情况下,PyTorch在调用.backward()进行梯度计算时会累积梯度,而不是替换掉旧的梯度。如果不手动清零,那么梯度会从多个迭代中累积起来,导致错误的参数更新。optimizer.zero_grad()正是用来清除过往的梯度信息,确保每次迭代的梯度计算都是基于当前迭代的数据。 loss.b

RuntimeError: Trying to backward through the graph a second time but the buffers have already been f
RuntimeError: Trying to backward through the graph a second time, but the buffers have already been freed 遇到过几次这个报错了,这几天把backward和autograd给看了几遍,终于摸着点门道 首先要知道,为什么会报这个错,这个错翻译成白话文就是说:当我们第二次backward的时候,
【已解决】RuntimeError: Trying to backward through the graph a second time (or directly access saved tens
问题描述 Traceback (most recent call last): File "/home/sysu/qfy/project/GCL/GCL/Main.py", line 281, in <module> main(args) File "/home/sysu/qfy/project/GCL/GCL/Main.py", line 200, in main

Object detection with location-aware deformable convolution and backward attention filtering
CVPR19 动机:对multi-scale目标检测来说, context information和high-resolution的特征是很重要的。但是context information一般是不规则分布的,高分辨率特征也往往包含一些干扰的low-level信息。 为了解决这两个问题, 文章提出两个模块: location-aware deformable convolution 和 back
PyTorch中tensor.backward()函数的详细介绍
backward() 函数是PyTorch框架中自动求梯度功能的一部分,它负责执行反向传播算法以计算模型参数的梯度。由于PyTorch的源代码相当复杂且深度嵌入在C++底层实现中,这里将提供一个高层次的概念性解释,并说明其使用方式而非详细的源代码实现。 在PyTorch中,backward() 是自动梯度计算的核心方法之一。当调用一个张量的 .backward() 方法时,系
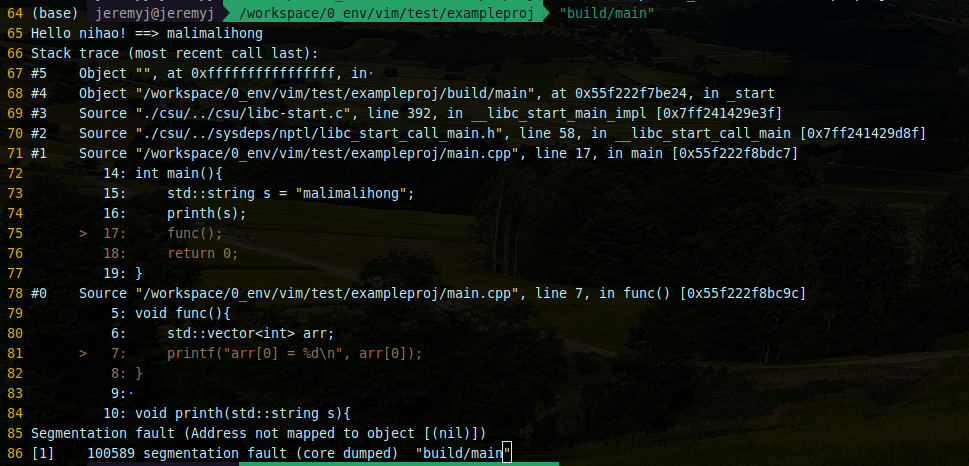
记录 | gdb使用backward-cpp来美化调试log
# 在当前工程目录下git clone https://github.com/bombela/backward-cpp.git 编辑CMakeList.txt cmake_minimum_required(VERSION 3.15)project(exampleproj LANGUAGES CXX)add_subdirectory(backward-cpp)add_executable(ma

【已解决】backward() got an unexpected keyword argument 'retain_variables'
出现这个报错的原因是,在新版本的Python下,原来的变量retain_variables被替换成了retain_graph。因此,在调用位置将其替换就可以了。 注:retain_graph的作用是为了避免内存在反向传播之后被释放,从而导致的无法第二次反向传播。因此需要将backward(retain_graph=True)。 更多内容,欢迎加入星球讨论。
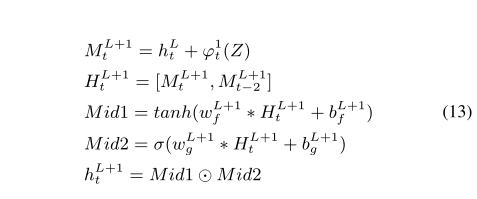
Multi-modal Circulant Fusion for Video-to-Language and Backward(MCF)同时使用vector和matrix
1.多模态循环融合(MCF) MCF的详细过程如图,x,y为不同模态特征向量,首先利用两个投影矩阵W1,W2将将特征投影到VC两个低维空间。 然后利用V、C构造循环矩阵A和B 为了使投影向量和循环矩阵中的元素充分作用,我们探索了两种不同的乘法运算 1)在循环矩阵和投影向量之间使用矩阵乘法 2)是让循环矩阵的投影向量和每行进行元素积 最后通过一个投影矩阵W3,将F

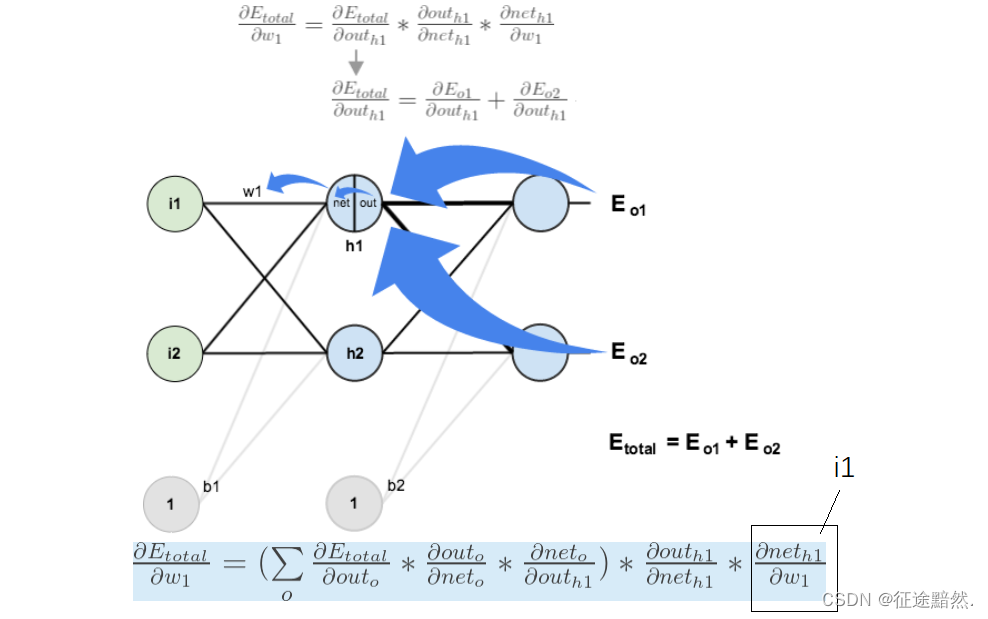
三幅图简易说明神经网络的后向传播(Backward propagation)
神经网络的后向传播是在神经网络进行训练时,神经网络各层更新数值的方法。后向传播大致可以分为以下三种情况: 在节点处相加的情况:节点会将传入的梯度值直接向后传播。 在节点处相乘的情况:将输入端的值对调,并和传入的梯度值相乘。 在节点处进行函数变换:对函数求导,并和传入的梯度值相乘。特别的,如果 g = m a x ( ) g=max() g=max(),那么只有达到了max的x的分量会传出梯度值
【backward解决方案与原理】网络模型在梯度更新时出现变量版本号机制错误
【backward解决方案与原理】网络模型在梯度更新时出现变量版本号机制错误 报错详情 错误产生背景 原理 解决方案 RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation 报错详情 模型在backw

register_backward_hook()和register_forward_hook()
结论: 一:register_forward_hook()在指定网络层执行完前向传播后调用钩子函数 二: 1:register_backward_hook()在指定网络层执行完backward()之后调用钩子函数 2:register_backward_hook()返回的grad_input是关于所有输入变量的梯度,也就是说grad_input是个元组,包含有对该层网络的权重weight的

pytorch中backward函数的参数gradient作用的数学过程
pytorch中backward函数的参数gradient作用的数学过程 问题描述实例分析 本机器学习小白最近在学习pytorch,在学习.backward()函数的过程中一直不能理解参数gradient的作用,感觉相关资料中对它的解释过于简单,几乎忽略了相关数学过程。这里分享一下我的理解,希望能对有需要的同学有些帮助。 .backward()函数是pytorch用来实现反向传
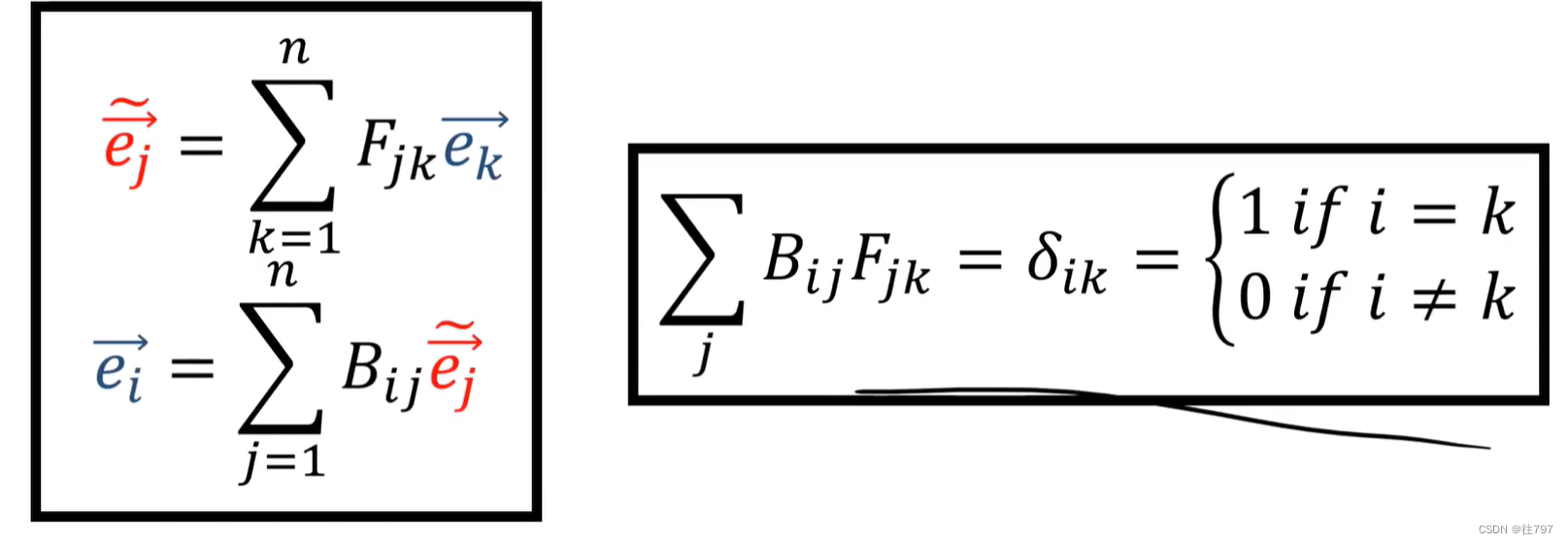
3.Tensors For Beginners- Forward and Backward Transformations
张量在不同坐标系之间来回移动的规则究竟如何。 之前说过,张量在坐标系变化下是不变的,故了解如何在坐标系之间来回移动对理解张量很重要。 Forward:旧基 到 新基 old basis:旧基 这是在二维坐标系下的两组基。 线性代数中的基: 向量空间V中的一组向量 若满足: 1)线性无光 2)向量中间V中的任何一个向量 都可由 该组向量 线性表出, 则称该组向量为 向量空间V的