本文主要是介绍【backward解决方案与原理】网络模型在梯度更新时出现变量版本号机制错误,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
【backward解决方案与原理】网络模型在梯度更新时出现变量版本号机制错误
- 报错详情
- 错误产生背景
- 原理
- 解决方案
RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation
报错详情
模型在backward时,发现如下报错:

即RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation。
其大概意思是说,当在计算梯度时,某个变量已经被操作修改了,这会导致随后的计算梯度的过程中该变量的值发生变化,从而导致计算梯度出现问题。
错误产生背景
起因是我要复现一种层级多标签分类的网络结构:
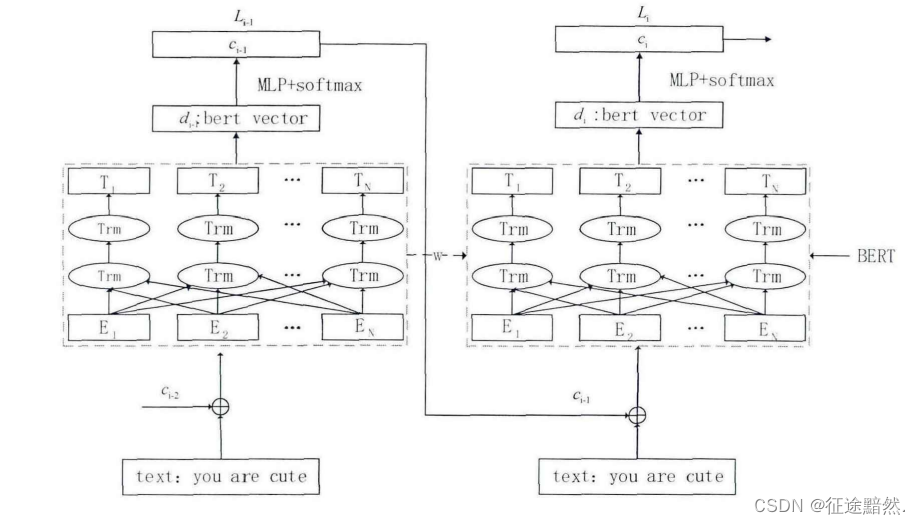
当输入序列 x x x经过一次BERT模型之后,得到当前预测的一级标签,然后拼接到输入序列 x x x上,再次输入到BERT模型里以预测二级标签。
出错版本的模型结构如下:
def forward(self, x, label_A_emb):context = x[0] # 输入的句子mask = x[2] d1 = self.bert(context, attention_mask=mask)logit1 = self.fc1(d1[1]) # [batch_size, label_A_num] = [128, 34]idx = torch.max(logit1.data, 1)[1] # [batch_size] = [128]extra = label_A_emb[idx]context[:, -3:] = extramask[:, -3:] = 1d2 = self.bert(context, attention_mask=mask)logit2 = self.fc2(d2[1]) # [batch_size, label_B_num] = [128, 34]return logit1, logit2
在计算梯度时,由于context和mask的值被中间修改过一次,所以会报错。
原理
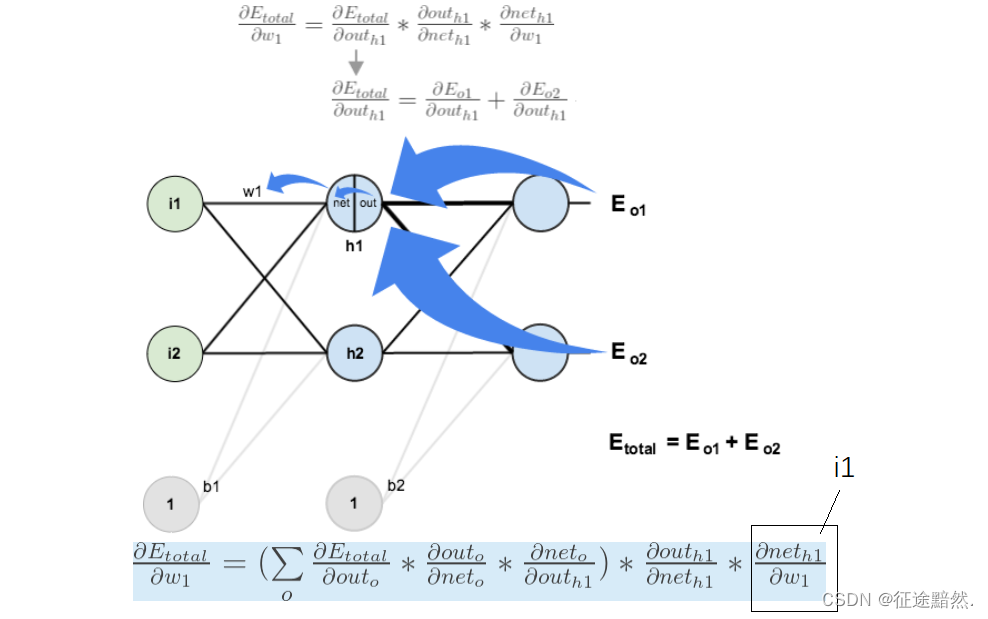
图中 w 1 w_1 w1的梯度计算如上图,损失函数为 E t o t a l E_{total} Etotal,最终 w 1 w_1 w1的梯度里是需要用到原始输入 i 1 i_1 i1的。
所以在上面贴的模型结构代码中,输入在经过神经网络之后,又作了一次改动,然后再经过神经网络。但是梯度计算会计算两次的梯度,可是发现输入只有改动后的值了,改动前的值已经被覆盖。
计算梯度时的版本号机制是PyTorch中用于跟踪张量操作历史的一种机制。它允许PyTorch在需要计算梯度时有效地管理和跟踪相关的操作,以便进行自动微分。每个张量都有一个版本号,记录了该张量的操作历史。当对一个张量执行就地操作(inplace operation)时,例如修改张量的值或重新排列元素的顺序,版本号会增加。这种就地操作可能导致计算梯度时出现问题,因为梯度计算依赖于操作历史。
解决方案
把即将改动的变量深拷贝一份,最终优化的代码如下:
def forward(self, x, label_A_emb):context = x[0] # 输入的句子mask = x[2] d1 = self.bert(context, attention_mask=mask)logit1 = self.fc1(d1[1]) # [batch_size, label_A_num] = [128, 34]idx = torch.max(logit1.data, 1)[1] # [batch_size] = [128]extra = label_A_emb[idx]context_B = copy.deepcopy(context)mask_B = copy.deepcopy(mask)context_B[:, -3:] = extramask_B[:, -3:] = 1d2 = self.bert_A(context_B, attention_mask=mask_B)logit2 = self.fc2(d2[1]) # [batch_size, label_B_num] = [128, 34]return logit1, logit2
这篇关于【backward解决方案与原理】网络模型在梯度更新时出现变量版本号机制错误的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




