本文主要是介绍找不到GPU资源——[显存充足,但是却出现CUDA error:out of memory错误],希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
说明:
- 系统:Centos(Redhat)
- 环境:python3.6+pytorch1.4.0(gpu)+tensorflow2.0.0(cpu)
- Cuda:9.2
- Cudnn:7.0.6?
- 模型 YOLOv3
描述
- 图找不到了,就去隔壁偷了一张(传送)
- 在运行git上的yolov3目标检测项目的时候尝试使用GPU加速,结果爆出CUDA error:out of memory

- 隔壁说是找不到GPU资源:解决方法如下(抄的):
'''
1.使用python的os模块import osos.environ['CUDA_VISIBLE_DEVICES']='2, 3'
# 表示2,3可见,用哪块需设置,默认是用第一个2.直接设置环境变量(linux系统)export CUDA_VISIBLE_DEVICES=2,3
'''
- 简单来说就是找到GPU就完事了,我照做,问题解决了。
问题探究
- 我特地查看了一下服务器的显卡配置
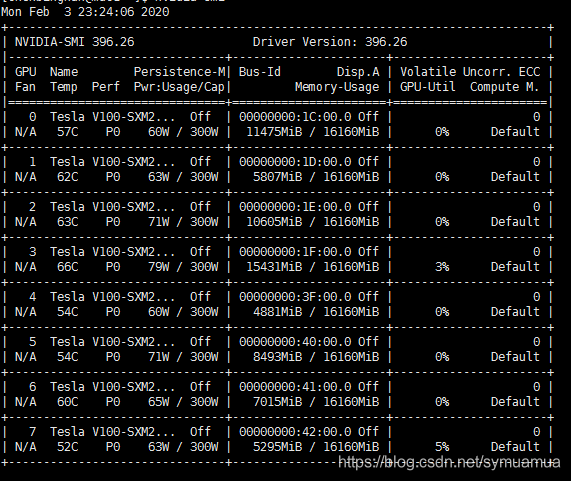
- 8张,除去第0张不能用(不知道为什么,测试出来的),剩余7张都是可以用的
- 说明一下 Bus-Id Disp.A这一栏下面是显存使用情况,每一张16GIB左右大小,目前被我占用的有2,3两块,也就是他们

- 换句话说,之所以会出现CUDA error:out of memory这个错误,因为当没有指定用哪块GPU的时候,就默认第一块,那么大家都用第一块,当第一块不够了,自然就会抛出显存溢出这个错误。
- 另外分享一个实时查看显卡信息的命令;
watch -n 10 nvidia-smi
- 10=10秒,每隔10秒
- nvidia-smi表示查看显卡
- 其实这是两个命令的结合,watch命令后面也可以不是nvidia-smi
这篇关于找不到GPU资源——[显存充足,但是却出现CUDA error:out of memory错误]的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








