充足专题

亚马逊云注册就送小礼品,数量充足,耳机键盘等你来拿!
专属注册链接 必须通过专属注册链接注册,否则无效 https://aws.amazon.com/cn/campaigns/nc202408/?trk=cea4eff1-c9d0-4ed8-924b-c48b2dd6b6d3&sc_channel=psm
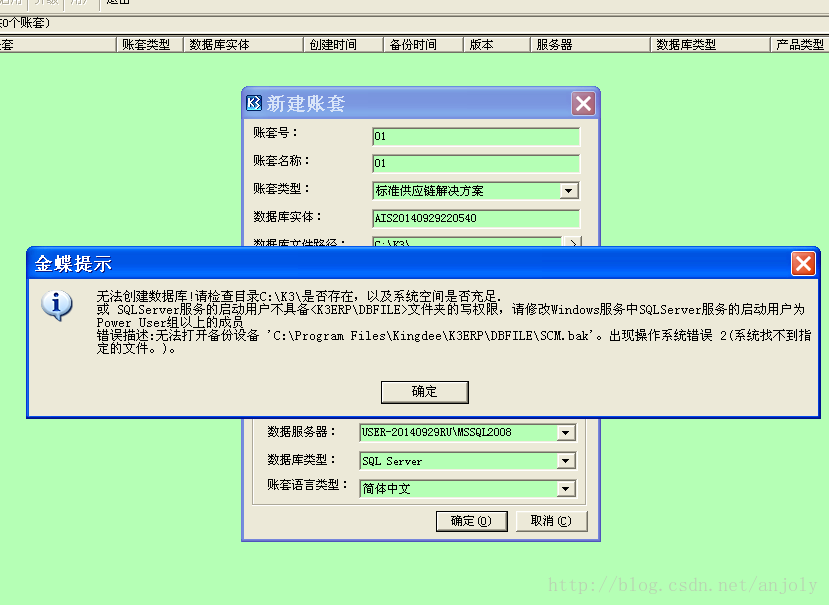
新建帐套提示“无法创建数据库!请检查目录…是否存在,以及系统空间是否充足.
1、在K/3安装路径下K3ERP文件夹下,找到DBFILE文件夹;2、右击单击“DBFILE”文件夹,选择“属性”→【安全】→【添加】,选择【高级】→【立即查找】→找到everyone用户;3、把该用户添加到【用户和组】中,并赋予“完全控制权限”。

保证充足的高质量睡眠
如何睡的充足呢?可以选择一个凉快、光线较暗的房间,如果觉得难以入睡,睡前放松一下,看看书或看电视,使自己平静下来,也可以喝杯脱脂牛奶或吃一根香蕉或其他含褪黒激素(燕麦、甜玉米、米饭、大麦、番茄)或血清素(全麦面食、蔬菜等富含复合碳水化合物的食品)的食物,帮助你入睡。 如果第二天要早起,睡前不要做运动,有规律的、与自然节奏同步的时间表是最佳的作息安排。如果有需要,可以在周末补充睡眠
苹果Find My产品需求增长迅速,伦茨科技ST17H6x芯片供货充足
苹果的Find My功能使得用户可以轻松查找iPhone、Mac、AirPods以及Apple Watch等设备。如今Find My还进入了耳机、充电宝、箱包、电动车、保温杯等多个行业。苹果发布AirTag发布以来,大家都更加注重物品的防丢,苹果的 Find My 就可以查找 iPhone、Mac、AirPods、Apple Watch。 如今的Find My已经不单单可以查找苹果的设备,随着
![找不到GPU资源——[显存充足,但是却出现CUDA error:out of memory错误]](https://img-blog.csdnimg.cn/20200203232820491.png)
找不到GPU资源——[显存充足,但是却出现CUDA error:out of memory错误]
说明: 系统:Centos(Redhat)环境:python3.6+pytorch1.4.0(gpu)+tensorflow2.0.0(cpu)Cuda:9.2Cudnn:7.0.6?模型 YOLOv3 描述 图找不到了,就去隔壁偷了一张(传送)在运行git上的yolov3目标检测项目的时候尝试使用GPU加速,结果爆出CUDA error:out of memory 隔壁说是找不到GPU资源

无充足准备下的秋招、笔试面试简历,踩得坑等
在这里给大家说一下我本次21届秋招踩过的各种坑。0+0 前提、本来是准备考研的,但因为疫情的原因,在家的复习状态特别差,所以准备了大半年又放弃了,所以说如果要考研的话就必须要提前准备好,不然会像我这样马上要回校进行秋招,或者两个月左右后考研,这样的进退两难。最终我还是选择了找工作。所以接下来就给大家说一下我在秋招前几天才开始的准备和踩过的各种坑。 首先说一下,我学的是计科专业,然后我们学校主要是走

在两三年前,选择数据库是一件非常容易的事。资金充足的企业会选择甲骨文数据库,使用微软产品的企业通常SQL Server,而预算不足企业则会选择MySQL。不过,如今的情况已经大不相同了。 最近两三年
http://cloud.csdn.net/a/20110808/302768.html 在两三年前,选择数据库是一件非常容易的事。资金充足的企业会选择甲骨文数据库,使用微软产品的企业通常SQL Server,而预算不足企业则会选择MySQL。不过,如今的情况已经大不相同了。 最近两三年,许多企业都推出了他们自己的开源项目以用于存储信息。在许多案例中,这些项目抛弃了传统的关系型

显卡显存充足,但是报错:CUDA error: out of memory
1. 问题描述 显卡未显存充足,且无进程占用,使用 nvidia-smi 和 sudo fuser -v /dev/nvidia* 均找不到占用进程。 报错: RuntimeError: CUDA error: out of memory CUDA kernel errors might be asynchronously reported at some 2. 解决方案 2.1

运行pytorch 显存充足却显示OOM(out of memory)
有时候训练网络,bach_size调大一点就报OOM,但是查看GPU使用情况,发现并不高,无奈只能调小。 最近用onnx,又报CUDA out of memory。仔细研究了一下,有一些发现,记录一下。 如果只有一块GPU,主要是因为pytorch会在第0块gpu上初始化,并且会占用一定空间的显存。这种情况下,经常会出现指定的gpu明明是空闲的,但是因为第0块gpu被占满而无法运行,一

显存充足,但提示CUDA out of memory
详细错误如下: RuntimeError: CUDA out of memory. Tried to allocate 32.00 MiB (GPU 1; 23.70 GiB total capacity; 21.69 GiB already allocated; 26.81 MiB free; 22.00 GiB reserved in total by PyTorch) 认真阅读这个错误

记一次显存充足报CUDA out of memory 的错误
如图,总显存12G,目前只使用了665M, 需要再申用 98M的显存空间却报 RuntimeError:CUDA out of memory 解决方案 重启电脑后恢复正常

显存充足但是CUDA out of Memory报错解决_查看僵尸进程
首先排除了是batchsize太大的原因,我从16改到了1,还是一直在OOM,而且更重要的是,前一天还是能跑的,今天就跑不了了55。 然后突然想到是不是僵尸进程的原因,僵尸进程是不会显示在nvidia-smi里的 去网上搜了搜怎么看僵尸进程的方法:fuser -v /dev/nvidia* 这条命令用不用sudo都行。 我看了两次,真让我找到两个叛徒。nvidia-smi里面根本没有它们。k
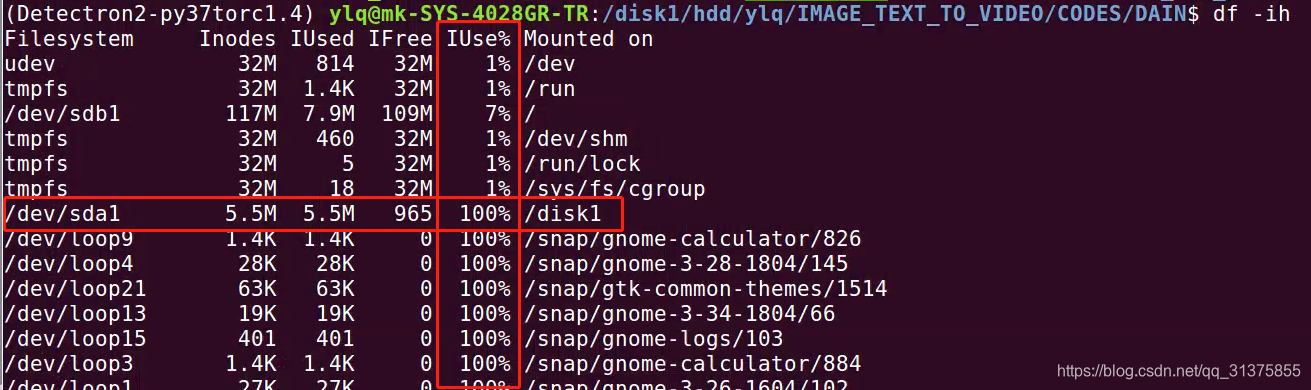
No space left on device 但是 df -h 发现空间充足
No space left on device 但是 df -h 发现空间还很充足 可能是 inodes 不足所致。 用“df -ih”命令查看 inodes 使用情况: df -ih 若 Iuse 一项显示 100%,就是 inodes 不足: 解决方法:用“rm -rf”清理掉那些小而多的垃圾文件(如一些 log 日志文件等) 【解释】 inode 是 Linux 用来

Pytorch:测试保存训练模型时,显存充足,却提示cuda out of memory的问题
在训练网络结束后,测试训练模型,明明显存还很充足,却提示我cuda out of memory 出现这种问题,有可能是指定GPU时出错(注意指定空闲的GPU),在排除这种情况以后,通过网上查找,说有可能是测试时的环境与训练时的环境不一样所导致,例如在网络训练时所使用的pytorch版本和测试时所使用的版本不同。由于我训练和测试用的同一虚拟环境,故排除这种情况。 还有一种说法,是因为pyto
Pytorch显存充足出现CUDA error:out of memory错误
Pytorch显存充足出现CUDA error:out of memory错误 Ref: https://www.cnblogs.com/jisongxie/p/10276742.html 报错内容 Bug描述 显存充足,并且已经通过 torch.nn.DataParallel 指定GPU编号CUDA与CUDNN均无错误,NVIDIA驱动无错误 解决方案 以上情况很可

显存充足,但是却出现CUDA error:out of memory错误
之前一开始以为是cuda和cudnn安装错误导致的,所以重装了,但是后来发现重装也出错了。 后来重装后的用了一会也出现了问题。确定其实是Tensorflow和pytorch冲突导致的,因为我发现当我同学在0号GPU上运行程序我就会出问题。 详见pytorch官方论坛: https://discuss.pytorch.org/t/gpu-is-not-utilized-while-occur-
找不到GPU资源——[显存充足,但是却出现CUDA error:out of memory错误]
说明: 系统:Centos(Redhat)环境:python3.6+pytorch1.4.0(gpu)+tensorflow2.0.0(cpu)Cuda:9.2Cudnn:7.0.6?模型 YOLOv3 描述 图找不到了,就去隔壁偷了一张(传送)在运行git上的yolov3目标检测项目的时候尝试使用GPU加速,结果爆出CUDA error:out of memory 隔壁说是找不到GPU资源

内存充足时,malloc内存分配失败问题
如题,为什么内存充足时,malloc内存分配失败? 首先,在32位平台下,系统最多可管理4G内存,其中2G系统自用,剩下2G可供用户使用,然而在实际分配时,用户可用空间始终小于2G(若有童鞋在如上条件下分配空间 等于或大于2G可以联系我哦,以让我纠正自己的错误)。64位则可以管理好多,有兴趣的童鞋可以自己算下哦! 那么,这些跟malloc内存分配失败有什么关系呢有什么关系呢?哈哈,

银行资金来源管理+银行资本的构成与功能+银行的资本充足度+银行的资本计划与资本来源
MENU 银行资本管理银行资本的构成与功能定义银行资本的构成资本的功能 银行的资本充足度基本原则资本充足度衡量方法的早期演变资本充足度的国际标准-巴塞尔协议 银行的资本计划与资本来源资本计划资本来源 银行资本管理 银行资本的构成与功能 定义 银行资本的构成 资本的功能 银行的资本充足度 基本原则 数量充足 构成合理 银行需要在抵御风险与追求盈利之

解答篇:金蝶K3WISE 15.0 - 无法创建数据库!请检查目录是否存在,以及系统空间是否充足......
金蝶K3WISE15.0免费全套图文实例教程 +V信syfpindao进金蝶学习交流群、微信空位不多(备注:金蝶+城市+姓名) 目录 一、解答问题二、解答步骤 一、解答问题 二、解答步骤 1、检查系统安装空间是否充足 2、设置DBFILE文件夹权限 添加Everyone 用户权限即可
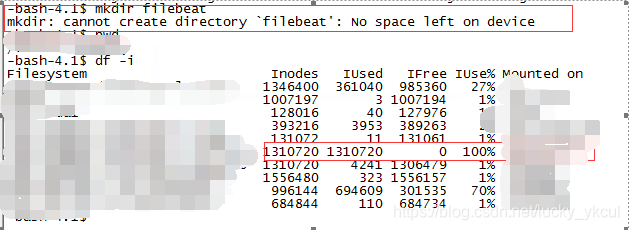
磁盘空间充足但无法创建文件no space left on device
问题现象 今天在创建目录时遇到了一个奇怪的问题,创建目录时报错can’t create directory ‘filebeat’:no space left on device。但我通过df -h发现磁盘空间还很充足,这是为什么呢? 问题原因 通过使用df -i命令发现该盘的inode使用率已经100%了,这就是为什么无法再创建目录和文件 硬盘格式化的时候,操作系统自动将硬盘分成两个区域。

显存充足 RuntimeError: CUDA error: out of memory
如果平时训练测试都没问题,忽然有一天测试的时候出现RuntimeError: CUDA error: out of memory,很有可能是因为当时训练时使用的卡号和现在使用的卡号不一致。 我今天用0卡的时候发现 RuntimeError: CUDA error: out of memory 首先nvidia-smi,发现0卡显存充足。 然后查看之前的日志,发现打印的变量在1卡上。 这说明
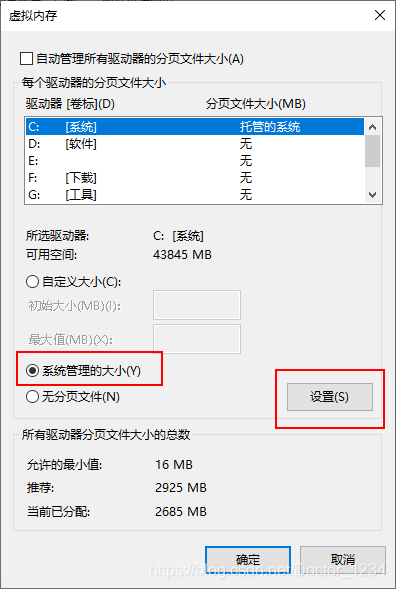
新版Edge浏览器在内存充足的条件下报错:内存不足,无法打开此页面
新版Edge浏览器在内存重组的条件下报错:内存不足,无法打开此页面 出现该问题可能的原因是虚拟内存设置过低造成的。 解决方案如下: 在Windows中直接搜索“环境变量” 在高级选项中卡中性能栏点击设置: 高级选项卡内虚拟内存栏点击更改…: 如图设置即可: 最后重启计算机,问题应该得到解决了。

显存充足却提示out of memory
1 问题描述 用Pytorch进行模型训练时出现以下OOM提示: RuntimeError: CUDA out of memory. Tried to allocate 98.00 MiB (GPU 0; 12.00 GiB total capacity; 3.19 GiB already allocated; 6.40 GiB free; 9.60 GiB allowed; 3.33 Gi