本文主要是介绍Swin Transformer简记-220112版,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Swin Transformer简记
文章目录
- Swin Transformer简记
- 参考
- 问题与方案
- Window Attention
- Patch Merging
- Shifted Window based Self-Attention
- 总结
参考
-
源码
-
本次回顾这篇用的时间不长,主要是大致浏览了一遍,记录一下,如有错误,踢我一下
问题与方案
-
CV中input的scale存在不定性,变化可能很大(就像YOLO v3的输入可以是416也可以是608之类的),这与NLP问题是不同的,并且比较棘手。
-
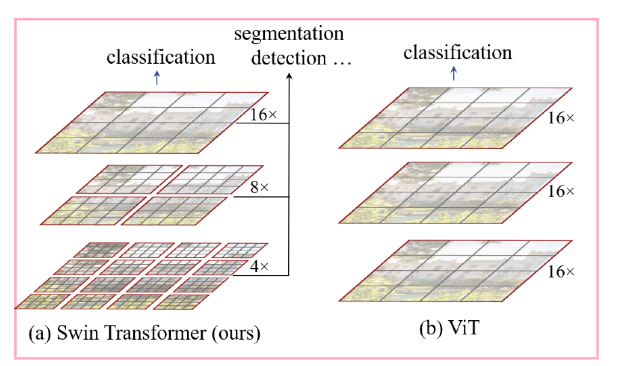
VIT中的结构是下面右侧的这样,将一张图分成16份,即16个patch,直接对patch们做attention然后做后续任务,这样的话当input的scale的数量变大的时候,其计算量会以二次方的量级增加(因为embedding用的是FC。。。)
-
因此呢swin- transformer的一个创新点就是将原本的分成16格再一次划分,分成更小的window,每次以更小的window计算,最后合起来,这样就可以实现减少计算量的目的,这点思想参考了CNN中的层次结构,就很像pooling将图片的hw维度变小一样。这是第一个window partition思想
-
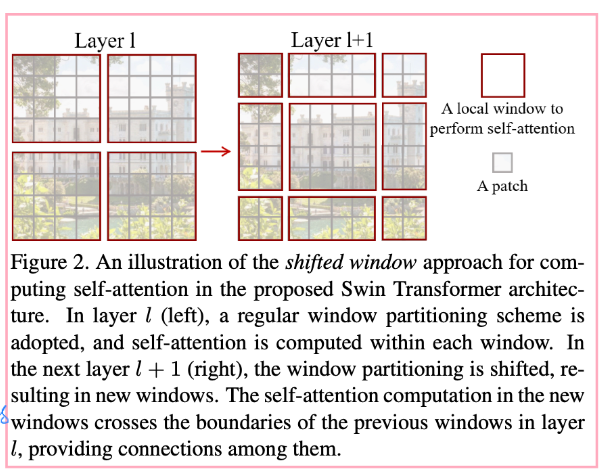
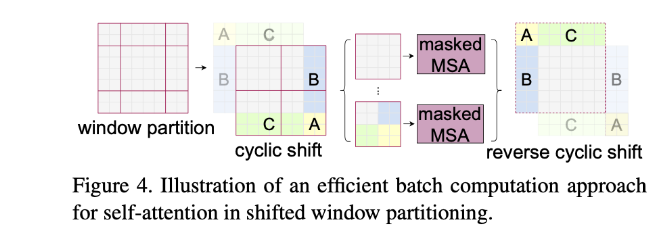
第二个为了提升每个patch的感受野,同时为了更好地提取window边缘的特征信息,作者在一个Swin Transformer block中设计了一个shifted window attention
Window Attention
-
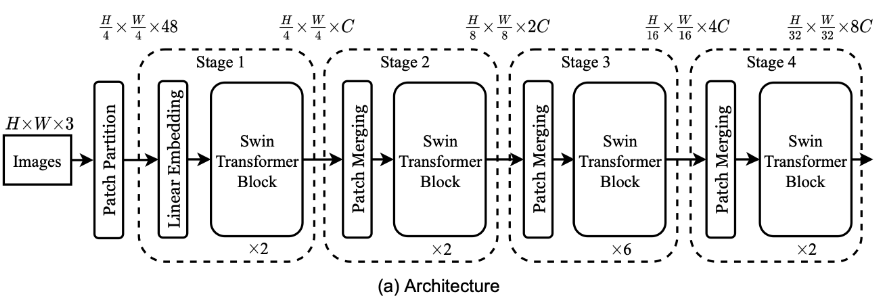
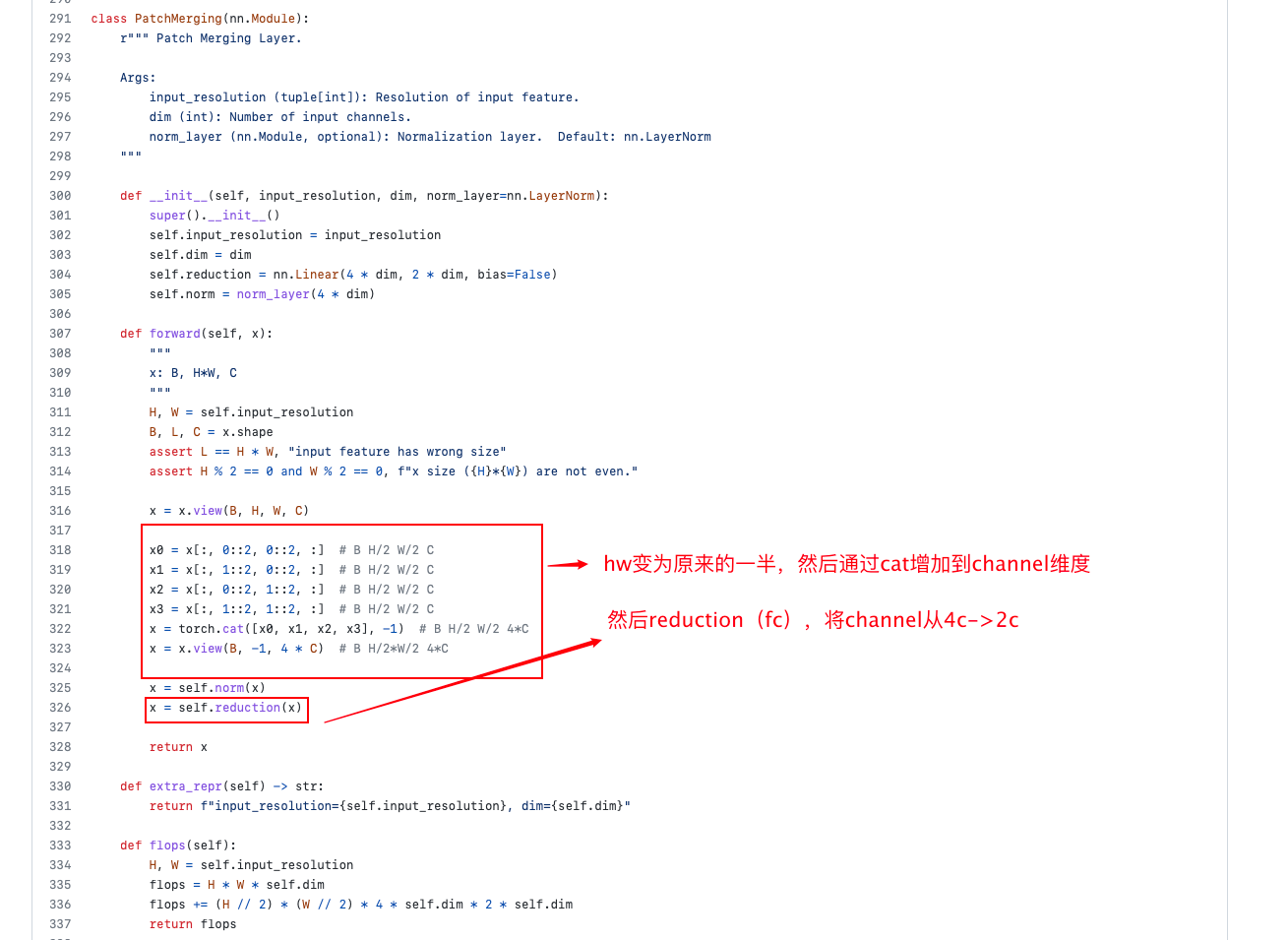
这里结合它整体的结构讲,如下两张图所示,每一组Swin Transformer block后都会将hw维度缩为一半,然后再看下面的示意图,就是说,一开始是window_size=7,然后一组block之后经过类似pooling的做法(当然应该不是pooling,应该是Patch Emerging,重新构造patch的形状,把hw各缩小一半,值压缩到对应的channel中去,此时channe=channelx4,然后经过fc使得channel减半变成没有merging之前的两倍),这样就实现了hw变小,此时再用相同的window做local attention感受野就是原来的四倍。
-
-
-
具体的话实现在这里:https://github.com/microsoft/Swin-Transformer/blob/5d2aede42b4b12cb0e7a2448b58820aeda604426/models/swin_transformer.py#L163 的第249行
-

-
Patch Merging
Shifted Window based Self-Attention
-
-
它的一个shifted window attention 机制就是这样的,将window分为9个区域,然后将区域调换之后再做local self-attention
-
在代码中是这样实现的,有一个类叫SwinTransformerBlock,在构造的时候没如果传入shift_size,则该类是Shifted Window Attention的类
-
也正因此,作者才会给出W-MSA和SW-MSA是一组的图
-
然后在狗仔Swin Transformer Block的forward的时候会根据shift_size构造SW-MSA(Shifted Window Multi-Head Self-Attention)

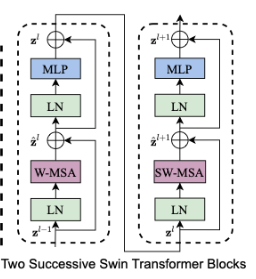

总结
- 距离第一次看过了半年,以上便是我再看的新理解,也许过段时间再看会有新发现~
这篇关于Swin Transformer简记-220112版的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







