本文主要是介绍【大厂AI课学习笔记NO.60】(13)模型泛化性的评价,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
我们学习了过拟合和欠拟合,具体见我的文章:https://giszz.blog.csdn.net/article/details/136440338
那么今天,我们来学习模型泛化性的评价。
泛化性的问题,我们也讨论过了,那么如何评价模型的泛化性呢?

我们知道,过拟合(over-fitting),就是在训练数据上表现良好,在未知数据上表现差。
欠拟合(under-fitting),就是在训练数据和未知数据上表现都很差。
这里要记住!
过和欠都不好,训练结合略微低于测试结果是组好的。
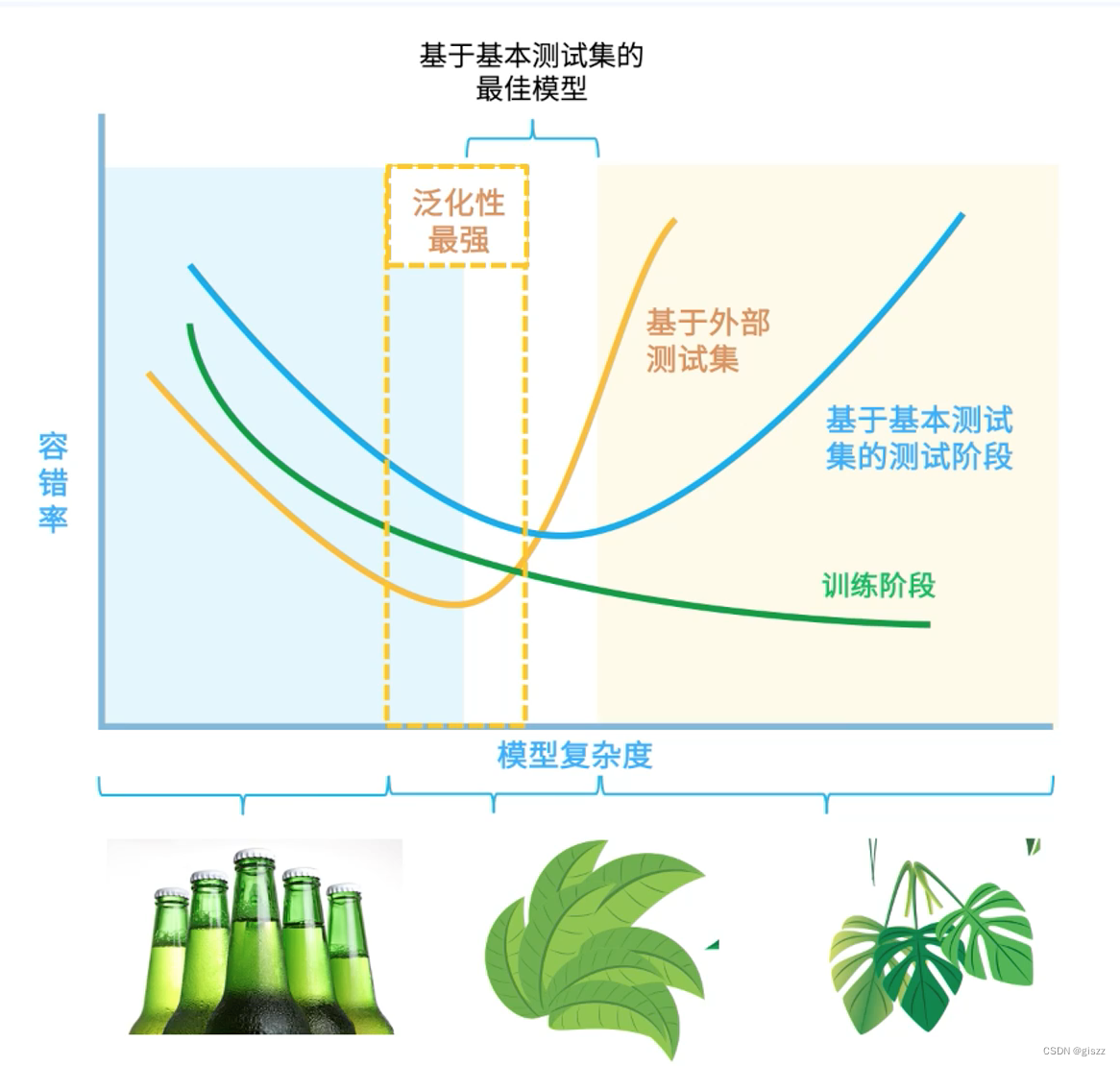
这个图特别有助于我们的理解。
延伸学习:
模型泛化性的评价方法主要包括留出验证、交叉验证、自助法等,下面详细阐述留出验证和交叉验证这两种常用的方法,以及它们的步骤和重要的工具,并给出具体的例子来说明。
一、留出验证
留出验证是将数据集划分为训练集、验证集和测试集三个部分。训练集用于训练模型,验证集用于调整模型参数和选择最佳模型,测试集用于评估模型的泛化性能。
步骤:
- 将数据集按比例划分为训练集、验证集和测试集,通常的比例是70%:15%:15%或60%:20%:20%等。
- 使用训练集训练模型,并使用验证集进行模型选择和参数调整。
- 选择在验证集上表现最好的模型,使用测试集评估其泛化性能。
工具:
Python中的scikit-learn库提供了留出验证的相关功能,如train_test_split函数可用于划分数据集。
例子:
假设我们有一个包含1000个样本的数据集,我们可以使用train_test_split函数将其划分为训练集、验证集和测试集。例如,将70%的数据作为训练集,剩余的30%再平均分为验证集和测试集。
from sklearn.model_selection import train_test_split X, y = # 数据集的特征和标签 X_train, X_temp, y_train, y_temp = train_test_split(X, y, test_size=0.3, random_state=42)
X_val, X_test, y_val, y_test = train_test_split(X_temp, y_temp, test_size=0.5, random_state=42)二、交叉验证
交叉验证是一种将数据集分成多份,每次使用其中的一份作为验证集,其余的作为训练集的验证方法。常见的交叉验证方法有k折交叉验证和留一交叉验证。
步骤(以k折交叉验证为例):
- 将数据集平均分成k份,每份称为一个折(fold)。
- 每次使用其中的一个折作为验证集,其余的k-1个折作为训练集。
- 重复k次,每次选择不同的折作为验证集,确保每个折都被用作验证集一次。
- 计算k次验证结果的平均值作为模型的性能评估指标。
工具:
Python中的scikit-learn库提供了交叉验证的相关功能,如KFold和cross_val_score等。
例子:
假设我们有一个包含100个样本的数据集,我们可以使用5折交叉验证来评估模型的性能。这意味着我们将数据集分成5份,每份包含20个样本。
from sklearn.model_selection import KFold, cross_val_score
from sklearn.linear_model import LogisticRegression X, y = # 数据集的特征和标签
model = LogisticRegression() # 以逻辑回归模型为例 kfold = KFold(n_splits=5, shuffle=True, random_state=42) # 创建5折交叉验证对象
scores = cross_val_score(model, X, y, cv=kfold) # 使用交叉验证评估模型性能 print("交叉验证结果:", scores) # 输出每次验证的结果
print("平均性能:", scores.mean()) # 输出平均性能评估指标需要注意的是,在实际应用中,我们通常会结合多种评估方法和工具来全面评估模型的泛化性能。此外,还需要注意数据集的划分比例、随机性等因素对评估结果的影响。
这篇关于【大厂AI课学习笔记NO.60】(13)模型泛化性的评价的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









