本文主要是介绍三天学会MySQL(七)聚合函数 数据分组,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
一.聚合函数介绍
二.AVG 和 SUM 函数
三.MIN 和 MAX 函数
四.COUNT 函数
五.创建数据分组
六.在多列上使用分组
七.约束分组结果(HAVING)
八.聚合函数和分组练习
一.聚合函数介绍
聚合函数即多行函数,单行函数是对每一行数据进行处理,而多行函数是作用在数据分组的基础之上的。

聚合函数
聚合函数也称之为多行函数,组函数或分组函数。聚合函数不象单行函数,聚合函数对行的分组进行操作,对每组给出一个结果。如 果在查询中没有指定分组,那么聚合函数则将查询到的结果集视为 一组。
聚合函数类型
- AVG平均值
- COUNT计数
- MAX最大值
- MIN最小值
- SUM合计
聚合函数说明:

聚合函数使用方式

distinct(如果加的话)放在聚合函数的参数之前!
二.AVG 和 SUM 函数
AVG(arg) 函数
对分组数据做平均值运算。
arg: 参数类型只能是数字类型。
SUM(arg) 函数
对分组数据求和。
arg: 参数类型只能是数字类型。
示例:
计算员工表中工作编号含有 REP 的工作岗位的平均薪水与薪水总 和。
SELECT AVG ( salary ) , SUM ( salary )
FROM employees
WHERE job_id LIKE '%REP%' ;
三.MIN 和 MAX 函数
MIN(arg) 函数
求分组中最小数据。
arg: 参数类型可以是字符、数字、 日期。
MAX(arg) 函数
求分组中最大数据。
arg: 参数类型可以是字符、数字、 日期。
示例:
查询员工表中入职时间最短与最长的员工,并显示他们的入职时间。
SELECT MIN ( hire_date ) , MAX ( hire_date ) FROM employees;
四.COUNT 函数
返回分组中的总行数。
COUNT 函数有三种格式:
- COUNT(*):返回表中满足 SELECT 语句的所有列的行数,包括重复行,包括有空值列的行。
- COUNT(expr):返回在列中的由 expr 指定的非空值的数。 (即指定属性非空的行数)
- COUNT(DISTINCT expr):返回在列中的由 expr 指定的唯一的非空值的数。
使用 DISTINCT 关键字
COUNT(DISTINCT expr) 返回对于表达式 expr 非空并且值不相同的行数
显示 EMPLOYEES 表中不同部门数的值
示例一:
显示员工表中部门编号是 80 中有佣金的雇员人数。
SELECT COUNT ( commission_pct ) FROM employees WHERE department_id = 80 ;
示例二:
显示员工表中的部门数。
SELECT COUNT ( DISTINCT department_id ) FROM employees;
组函数和 Null 值
在组函数中使用 IFNULL 函数
SELECT AVG ( IFNULL ( commission_pct, 0 )) FROM employees;
IFNULL是第一个参数不为空就取第一个参数,否则取第二个参数。
五.创建数据分组
SQL语句不能嵌套使用!比如count里不能再存放其他函数!
创建数据组

创建数据组
在没有进行数据分组之前,所有聚合函数是将结果集作为一个大的信息组进行处理。但是,有时,则需要将表的信息划分为较小的 组,可以用 GROUP BY 子句实现。
GROUP BY 子句语法

原则
- 使用 WHERE 子句,可以在划分行成组以前过滤行。
- 如果有WHERE子句,那么GROUP BY 子句必须在WHERE的子句后面。
- 在 GROUP BY 子句中必须包含列。
使用 GROUP BY 子句
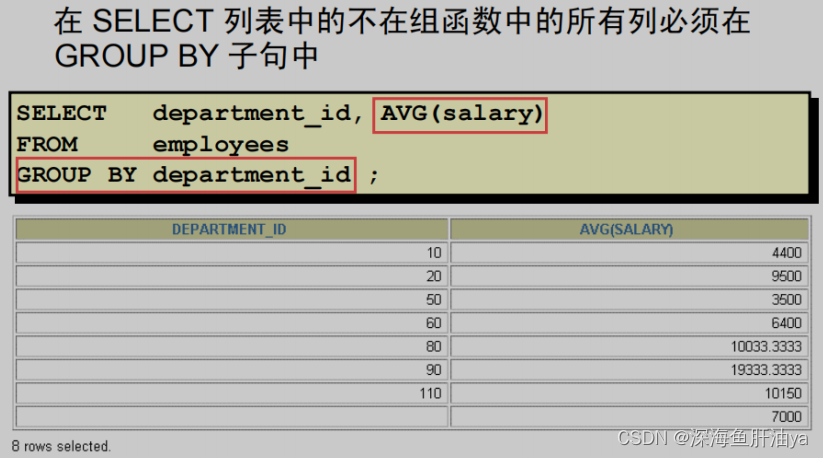
GROUP BY 子句
下面是包含一个 GROUP BY 子句 SELECT 语句的求值过程:
- SELECT 子句指定要返回的列:
- 在 EMPLOYEES 表中的部门号 − GROUP BY 子句中指定分组的所有薪水的平均值 − FROM 子句指定数据库必须访问的表:EMPLOYEES 表。
- WHERE 子句指定被返回的行。因为无 WHERE 子句默认情况下所有行被返回。
- GROUP BY 子句指定行怎样被分组。行用部门号分组,所以 AVG 函数被应用于薪水列,以计算每个部门的平均薪水。
示例:
计算每个部门的员工总数。
SELECT DEPARTMENT_ID, COUNT ( * ) FROM employees
GROUP BY DEPARTMENT_ID;
六.在多列上使用分组
相当于对组又细化了!
在多列上使用GROUPBY子句
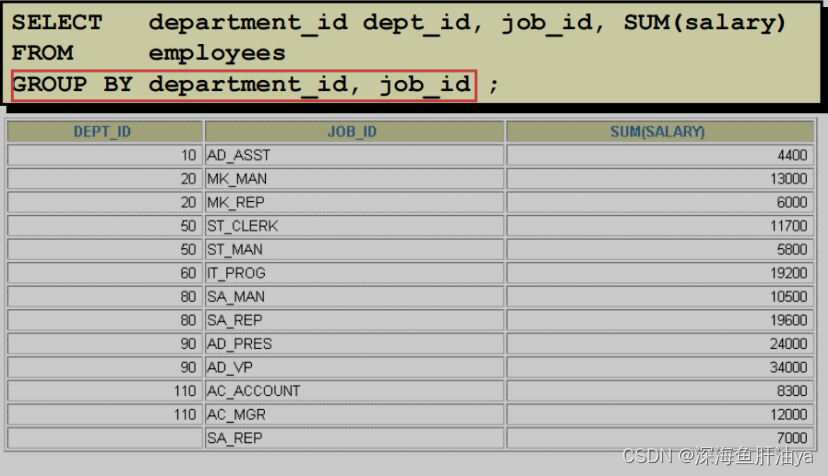
在组中分组
可以列出多个 GROUP BY 列返回组和子组的摘要结果。可以用GROUP BY 子句中的列的顺序确定结果的默认排序顺序。下面是图片中的 SELECT 语句中包含一个 GROUP BY 子句时的求值过程:
SELECT 子句指定被返回的列:
− 部门号在 EMPLOYEES 表中
− Job ID 在 EMPLOYEES 表中
− 在 GROUP BY 子句中指定的组中所有薪水的合计
FROM 子句指定数据库必须访问的表:EMPLOYEES 表。
GROUP BY 子句指定你怎样分组行:
− 首先,用部门号分组行。
− 第二,在部门号的分组中再用 job ID 分组行。
如此 SUM 函数被用于每个部门号分组中的所有 job ID 的 salary列。
示例:
计算每个部门的不同工作岗位的员工总数。
SELECT e .DEPARTMENT_ID , e .JOB_ID , COUNT ( * )
FROM employees e
GROUP BY e .DEPARTMENT_ID ,e .JOB_ID ;
七.约束分组结果(HAVING)
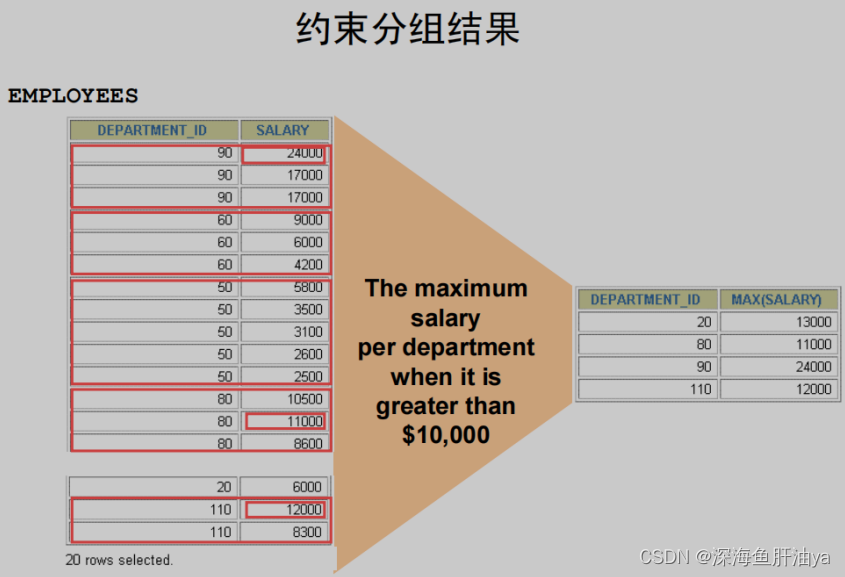
HAVING 子句
HAVING 子句是对查询出结果集分组后的结果进行过滤。
约束分组结果
用 WHERE 子句约束选择的行,用 HAVING 子句约束组。 为了找到每个部门中的最高薪水,而且只显示最高薪水大于 $10,000 的那些 部门,可以象下面这样做:
- 1 用部门号分组,在每个部门中找最大薪水。
- 2 返回那些有最高薪水大于 $10,000 的雇员的部门
SELECT department_id, MAX ( salary )
FROM employees
GROUP BY department_id
HAVING MAX ( salary ) > 10000 ;
HAVING子句语法

示例:
显示那些合计薪水超过 13,000 的每个工作岗位的合计薪水。排除那些 JOB_ID 中含有 REP 的工作岗位,并且用合计月薪排序列表。
SELECT job_id, SUM ( salary ) PAYROLL
FROM employees
WHERE job_id NOT LIKE '%REP%'
GROUP BY job_id HAVING SUM ( salary ) > 13000
ORDER BY SUM ( salary ) ;
八.聚合函数和分组练习
1. 显示所有雇员的最高、最低、合计和平均薪水,列标签分别为: Max 、 Min 、 Sum 和 Avg 。四舍五入结果为最近的整数。
SELECT
ROUND(MAX(e.SALARY)) max,ROUND(MIN(e.SALARY))
min,ROUND(SUM(e.SALARY)) sum ,
ROUND(AVG(e.SALARY)) avg
FROM employees e;2.写一个查询显示每一工作岗位的人数。
SELECT
e.JOB_ID,COUNT(*)
FROM employees e
GROUP BY e.JOB_ID; 3. 确定经理人数,不需要列出他们,列标签是 Number of Managers 。提示:用 MANAGER_ID 列决定经理号。
SELECT COUNT(DISTINCT e.MANAGER_ID) FROM employees e;4.写一个查询显示最高和最低薪水之间的差。
SELECT MAX(e.SALARY) - MIN(e.SALARY) FROM employees e; 5. 显示经理号和经理付给雇员的最低薪水。排除那些经理未知的人。排除最低薪水小于等于 $6,000 的组。按薪水降序排序输出。
SELECT e.MANAGER_ID,MIN(e.SALARY)
FROM employees e
WHERE e.MANAGER_ID is not null
GROUP BY e.MANAGER_ID
HAVING min(e.SALARY) > 6000
ORDER BY min(e.SALARY) desc; 6. 写一个查询显示每个部门的名字、地点、人数和部门中所有雇员的平均薪水。四舍五入薪水到两位小数。
SELECT
d.DEPARTMENT_NAME,d.LOCATION_ID,COUNT(*),ROUND(AVG(e.SALARY))
FROM employees e,departments d
where e.DEPARTMENT_ID = d.DEPARTMENT_ID
GROUP BY d.DEPARTMENT_NAME,d.LOCATION_ID先按名字分组,再按地点分组。
这篇关于三天学会MySQL(七)聚合函数 数据分组的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




