本文主要是介绍0基础使用LLAMA大模型搞科研,自动阅读论文、代码修改、论文润色、稿件生成等等,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
0基础使用LLAMA大模型搞科研,自动阅读论文、代码修改、论文润色、稿件生成等等。

使用 LLAMA大模型 辅助科研可以带来多方面的好处和优势,主要包括:
-
提高文献调研效率: LLAMA大模型 可以帮助研究人员快速获取特定研究领域的概述,提供相关文献的摘要和关键点,从而加速文献调研过程。
-
语言处理能力:对于非英语母语的科研人员, LLAMA大模型 可以提供论文润色、翻译和写作支持,帮助提高论文的语言质量,减少语言障碍。
-
创意和灵感激发: LLAMA大模型 的生成能力可以帮助研究人员思考新的研究问题、实验设计或研究方法,激发创新思维。
-
数据分析支持: LLAMA大模型 可以提供数据分析方法的建议,帮助研究人员理解和解释数据,甚至生成数据可视化图表。
-
写作和编辑辅助:在撰写科研论文、报告或摘要时, LLAMA大模型 可以提供思路、段落结构和编辑建议,提高写作效率。
-
学术交流增强: LLAMA大模型 可以帮助科研人员准备学术交流材料,如会议演讲稿、学术报告等,提高交流效果。
-
时间管理: LLAMA大模型 可以协助创建研究计划和提醒,帮助科研人员更好地管理时间和项目进度。
-
编程和代码理解:对于涉及编程的科研工作, LLAMA大模型 可以提供代码编写建议,帮助理解开源代码,提高编程效率。
-
学术诚信: LLAMA大模型 可以帮助科研人员避免抄袭和不当引用,确保研究工作的原创性和学术诚信。
-
跨学科协作: LLAMA大模型 可以作为不同学科背景的科研人员之间的沟通桥梁,帮助他们理解彼此的研究内容,促进跨学科合作。
-
快速响应: LLAMA大模型 能够即时响应问题,为科研人员提供快速的信息反馈,节省查找资料的时间。
-
降低门槛: LLAMA大模型 的使用不需要深厚的技术背景,使得更多科研人员能够利用这一工具,降低了科研工作的门槛。
-
个性化支持: LLAMA大模型 可以根据用户的具体需求提供个性化的帮助,如模拟特定期刊的编辑风格进行论文改写。
-
减轻工作负担:通过自动化一些重复性的工作,如文献搜索、数据整理等, LLAMA大模型 可以减轻科研人员的日常工作负担。
-
教育和培训: LLAMA大模型 可以作为教育工具,帮助学生和新入科研领域的人员快速掌握研究技能和知识。
使用openAI公司开发的 LLAMA大模型 ,后来又使用了NewBing,一开始只是比较新奇这个人工智能的技术,平时也喜欢研究各种软件的使用,就用它当做一个维基百科使用,有一些概念性的和生活常识的问题就会向他提问。
后面因为我是一直在自学生物信息学,有一个师兄带我,但是我也不可能什么问题都去问他,于是开始尝试使用 LLAMA大模型 询问一些研究领域相关的专业知识问题,发现它的回答比自己辛辛苦苦去谷歌的答案更准确和快速,不过是在正确的提示词(prompt)的基础上。
于是每天我打开电脑的第一件事就是打开浏览器,然后点击chathub插件,然后开始一天的科研工作。
关于使用 LLAMA大模型 方面是 0基础的,我会从最基础的如何巴拉拉小魔仙上网教学,包括远程帮你部署,让你不需要经历任何困难就能直接上手使用 LLAMA大模型 。
提供的服务包括:
一个 LLAMA大模型 帐号
NewBing帐号,可以教你如何申请或者帮你申请
一个月的巴拉拉小魔仙工具
远程部署和教学使用巴拉拉小魔仙工具和 LLAMA大模型 的使用
提供 LLAMA大模型 的一些小工具的软甲包和插件,比如实现联网
提供一些 LLAMA大模型 的平替网址和工具
关于 LLAMA大模型 、ai绘画midjourney 如何使用说明,中文prompt调教指南可以参考发布的众多专栏文章。
以及平时一些关于 LLAMA大模型 使用的问题可以私信我
研究生如何利用 LLAMA大模型 帮助开展日常科研工作?
- 上午读文献
1)遇到不懂得句子和专业名词直接甩给它,让它翻译和通俗解释一下,实在不行画一个markdown图来帮助理解。
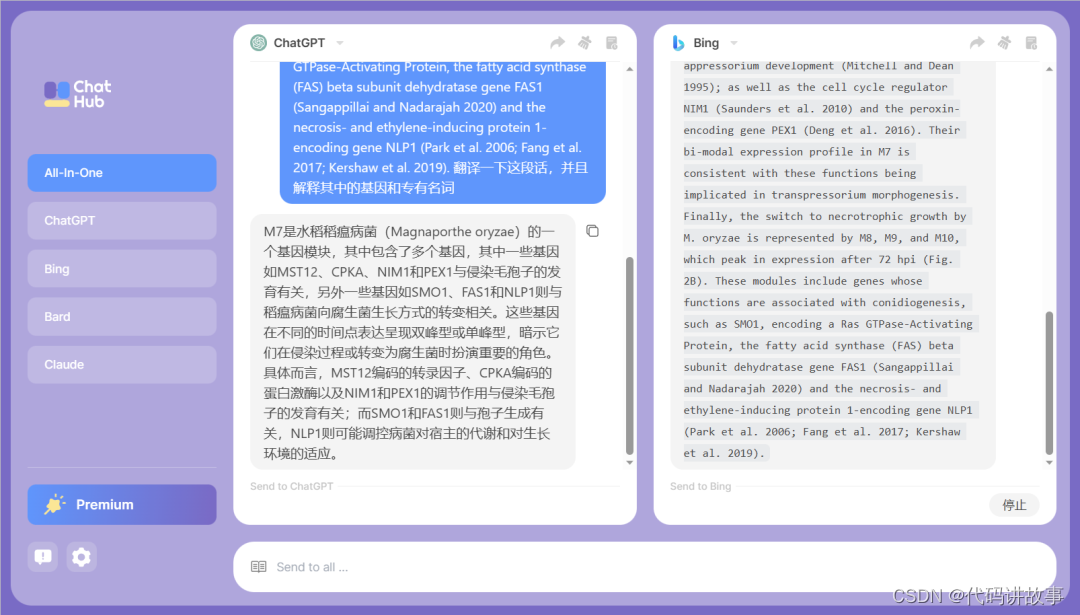
问题:M7 contains genes such as MST12, which encodes a transcription factor required for appressoriummediated penetration (Park et al. 2002); CPKA, encoding the catalytic subunit of cAMP-dependent protein kinase A, another key regulator of appressorium development (Mitchell and Dean 1995); as well as the cell cycle regulator NIM1 (Saunders et al. 2010) and the peroxin-encoding gene PEX1 (Deng et al. 2016). Their bi-modal expression profile in M7 is consistent with these functions being implicated in transpressorium morphogenesis. Finally, the switch to necrotrophic growth by M. oryzae is represented by M8, M9, and M10, which peak in expression after 72 hpi (Fig. 2B). These modules include genes whose functions are associated with conidiogenesis, such as SMO1, encoding a Ras GTPase-Activating Protein, the fatty acid synthase (FAS) beta subunit dehydratase gene FAS1 (Sangappillai and Nadarajah 2020) and the necrosis- and ethylene-inducing protein 1-encoding gene NLP1 (Park et al. 2006; Fang et al. 2017; Kershaw et al. 2019). 请先将上面的英文翻译为中文,然后解释其中的基因和专有名词
回答:M7包含一些基因,例如编码转录因子MST12的基因,该因子在侵染介导的穿透过程中必需 (Park et al. 2002);编码cAMP依赖性蛋白激酶A的催化亚基CPKA,这是侵染孢子发育的另一个关键调节因子 (Mitchell and Dean 1995);以及细胞周期调节因子NIM1 (Saunders et al. 2010)和过氧化物酶Peroxin编码基因PEX1 (Deng et al. 2016)。它们在M7中的双峰表达模式与这些功能与穿透菌丝体形成相关。最后,M. oryzae转向向缘生长的转换由M8、M9和M10表示,它们在感染后72小时达到峰值表达 (图2B)。这些模块包括功能与分生孢子有关的基因,例如编码Ras GTP酶激活蛋白的SMO1、脂肪酸合成酶(FAS)β亚单位脱水酶基因FAS1 (Sangappillai和Nadarajah 2020) 和编码死亡和乙烯诱导蛋白1的基因NLP1 (Park et al. 2006; Fang et al. 2017; Kershaw等,2019)。解释:1. MST12:一种转录因子,参与侵染孢子形成的调节。2. CPKA:cAMP依赖性蛋白激酶A的催化亚基,参与侵染孢子发育的调节。3. NIM1:细胞周期调节因子,参与穿透菌丝体形成的调节。4. PEX1:过氧化物酶Peroxin编码基因,参与穿透菌丝体形成的调节。5. SMO1:编码Ras GTP酶激活蛋白的基因,与分生孢子形成有关。6. FAS1:编码脂肪酸合成酶(FAS)β亚单位脱水酶的基因,与分生孢子形成有关。7. NLP1:编码死亡和乙烯诱导蛋白1的基因,与分生孢子形成有关。
2)我想找一些文献有关于植物lncRNA综述的文献来阅读。
new bing回答:
你好,这是必应。我作为一个植物学领域的教授,给你推荐以下几篇植物lncRNA方面的综述文献阅读,希望能帮助你更快的了解这个领域:- 《植物中LncRNA的研究应用》1,介绍了植物lncRNA的研究背景、方法和进展,以及lncRNA在植物生长发育和抗逆反应中的作用。- 《LncPheDB 植物中全基因组lncRNAs调控表型数据库》2,介绍了一个收集和整理了植物中lncRNAs与表型相关信息的数据库,以及如何使用该数据库进行lncRNA功能预测和分析。- 《用于lncRNA-miRNA相互作用预测的计算方法和数据库的调查》3,介绍了一些用于预测和分析lncRNA与miRNA相互作用的计算方法和数据库,以及它们在植物中的应用和意义。- 《RNA普查——LncRNA在植物中的研究进展》4,介绍了植物中lncRNA的产生机制、分类、功能、调控网络和研究挑战,以及一些重要的lncRNA家族和例子。- 《非编码RNA在植物免疫过程中重要调控作用的综述》5,介绍了不同类型的非编码RNA(包括lncRNA)在植物免疫反应中的调控作用和分子机制,以及非编码RNA之间的协同调控关系。- 《LncRNA的定义、功能、挑战和建议》6,介绍了lncRNA的基本概念、命名规则、保守性、表达特征、表型可见性、功能分析和分子机制,以及lncRNA在核外的作用。
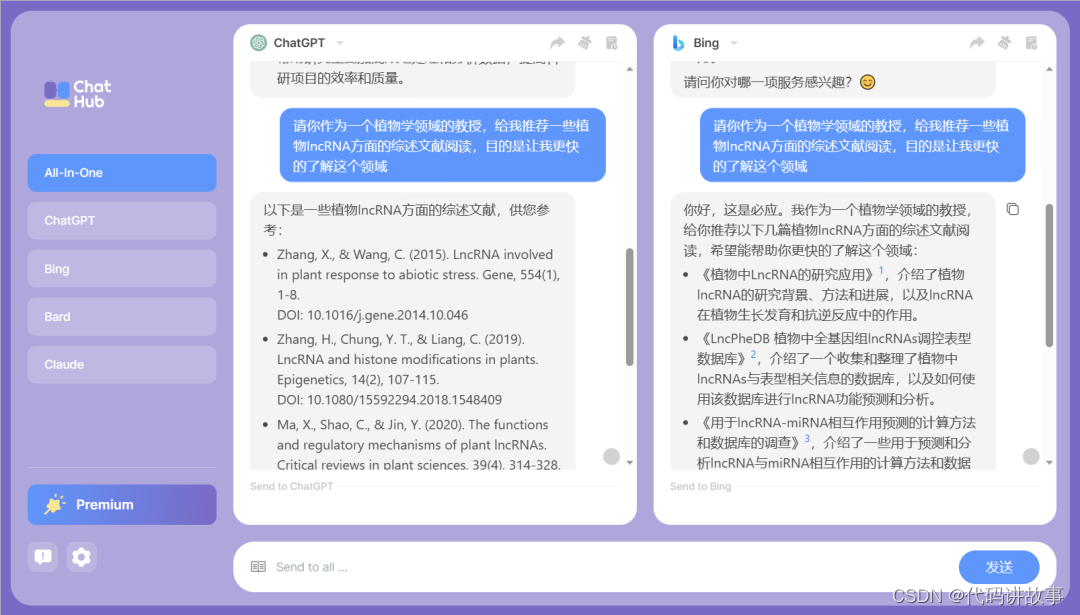
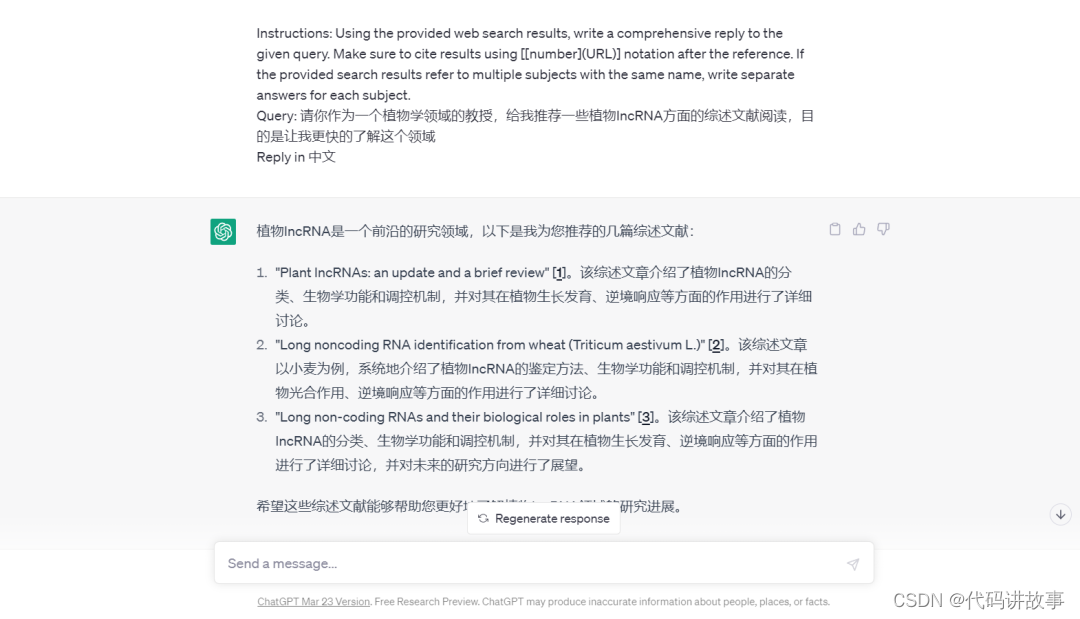
这是使用了联网插件web LLAMA大模型 以后的搜索结果,目前来看查文献还是NewBing更靠谱。
- 做生信免不了要读文档,了解每个软件的原理和使用方法。
1)甚至格式都给你整理的整整齐齐的,方便后面的查找。
以上是gffcompare命令的参数说明和使用方法的简要介绍,下面对各参数进行解释:-v:显示gffcompare的版本号。-i:提供一个包含需要处理的GTF文件列表的文本文件,代替在命令行参数中指定文件名。对于需要处理大量GTF文件的情况比较有用。-r:指定参考注释文件(GTF/GFF)。–strict-match:严格匹配模式,即只有当参考transcript的所有外显子边界均匹配时才会给予匹配符号’=‘,否则如果存在内含子匹配或单外显子匹配,则会给予匹配符号’~'。-R:限制参考transcript与输入transfrags之间的匹配。只对与输入transfrags有重叠的参考transcript进行准确率计算。-Q:限制输入transfrags与参考transcript之间的匹配。只考虑与参考transcript有重叠的输入transfrags进行精确度计算。需要注意的是,使用此选项会丢弃所有“新颖”位点。-M:忽略单外显子transfrags和参考transcript。-N:丢弃单外显子参考transcript。-D:在单个样本中禁用“注释”模式,忽略重复的查询transfrags(即具有相同内含子链的transfrags)。-S:与-D类似,但复制检查更严格,只有当匹配的查询或参考transcript(具有相同的内含子链)边界完全包含在更大或相同的transfrag中时才会丢弃。如果–strict-match选项也被指定,则需要对所有外显子边界进行精确匹配。–no-merge:禁用靠近的外显子合并(默认情况下,合并相互间隔小于5个碱基的外显子的位置)。-s:指定基因组序列的路径(可选),可以是多个序列的multi-FASTA文件或一个包含每个contig的单个fasta文件的目录。需要进行自动掩蔽(以小写字母表示)以将transfrags分类为重复元素。-T:不生成每个输入文件的.tmap和.refmap文件。-e:用于评估外显子精度时允许的参考transcript端部自由端的最大距离范围(100)。-d:用于分组transcript起始位点的最大距离范围(100)。-V:详细模式,显示GFF解析器警告。–chr-stats:分别对每个参考染色体/contig生成摘要和准确性数据的.stats文件。–debug:启用详细模式(-V)并生成额外的文件: .Q_discarded.lst、.missed_introns.gff、.R_missed.lst。对于生成的合并GTF输出文件的选项:-p:用于一致性转录本的名称前缀。-C:在GTF输出中丢弃匹配和“包含”的transfrags(即在所有查询文件中聚合内含子冗余的transfrags)。-A:与-C类似,但如果具有不同5’外显子起始的内含子冗余transfrags,则不丢弃它们(保留备选启动子)。-X:与-C类似,但如果transfrag的端点超过了容器内部的内含子,则也丢弃包含的transfrags。-K:对于-C/-A/-X选项,不丢弃与参考完全匹配的冗余的transfrags。
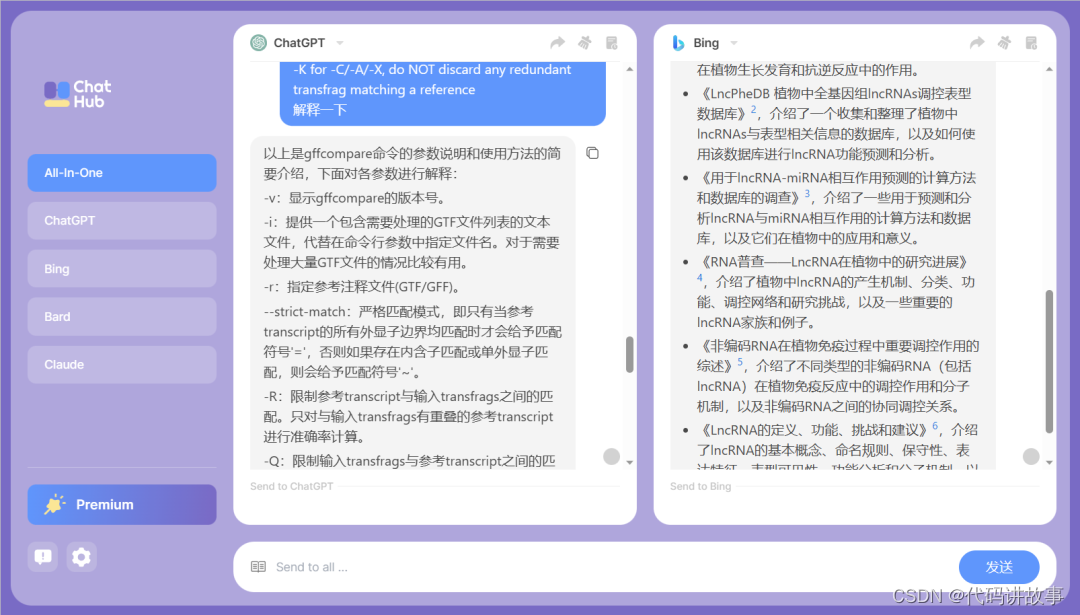
2)解释代码,再也不用担心看不懂其他人的代码
cat NONCODEv6_human.fa |seqkit rmdup -s -o clean.fa -d duplicated.fa -D duplicated.detail.txt 解释一下
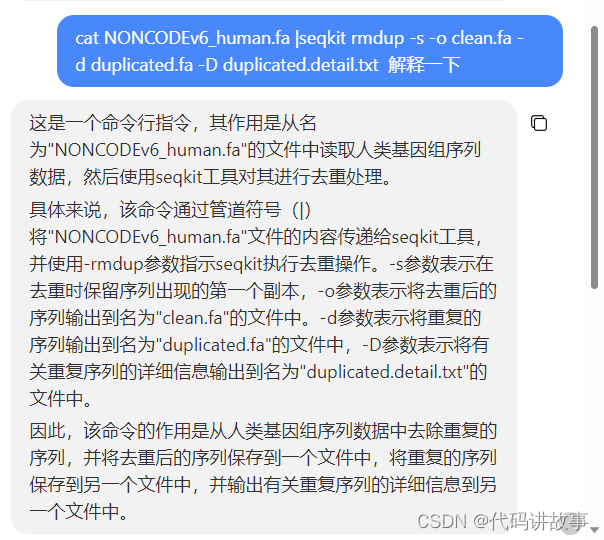
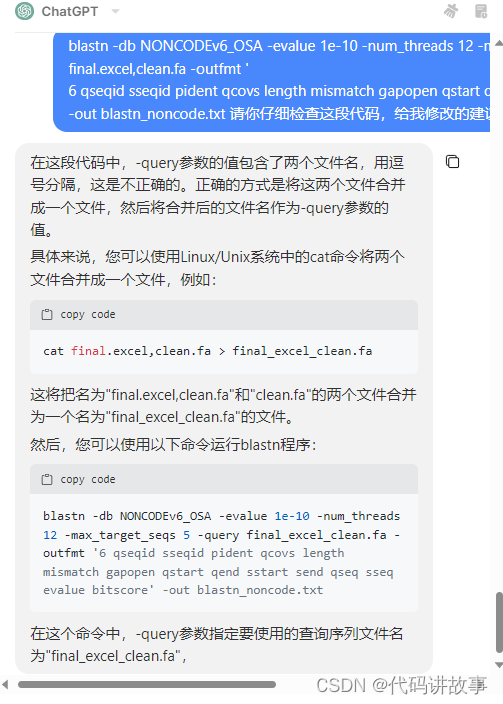
3)检查代码bug,给出建议
blastn -db NONCODEv6_OSA -evalue 1e-10 -num_threads 12 -max_target_seqs 5 -query final.excel,clean.fa -outfmt ’ 6 qseqid sseqid pident qcovs length mismatch gapopen qstart qend sstart send qseq sseq evalue bitscore’ -out blastn_noncode.txt 请你仔细检查这段代码,给出修改的建议。
4)编写python脚本,还可以将其转换成R脚本
这两个脚本就是用 LLAMA大模型 写的框架,自己又调试运行的。
一键计算荧光定量PCR(qRT-PCR)定量结果(Python脚本)
R脚本一键批量计算qRT-PCR和绘图
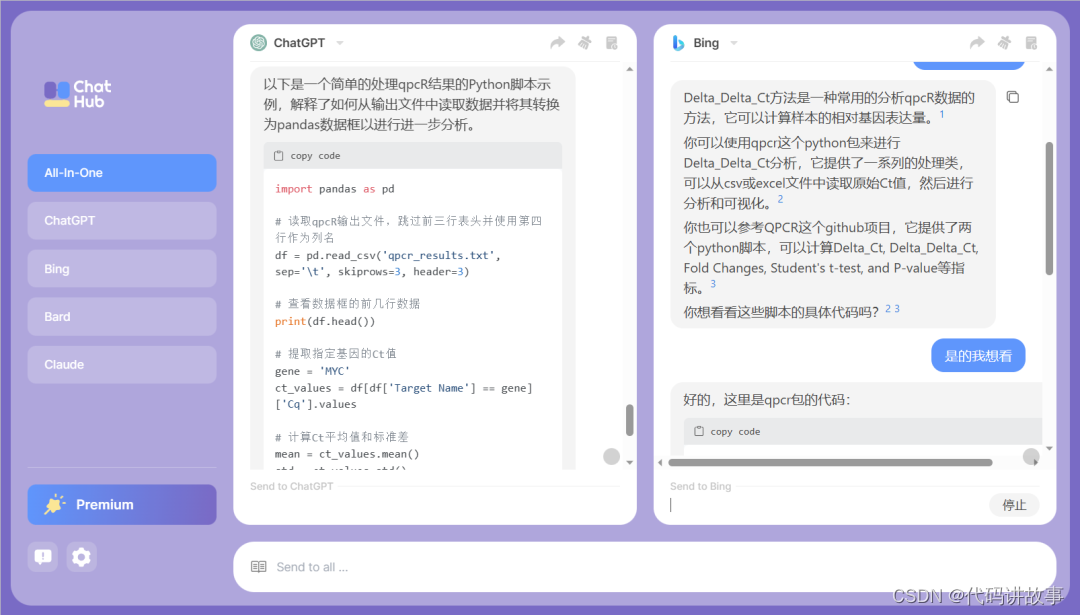
意外收获,原来以前已经有人写过了,重复造轮子没必要。
提供了一个github上的软件以及一个python包处理qPCR数据。
new bing回答:
[1]: https://pypi.org/project/qpcr/ "qpcr · PyPI"
[2]: https://github.com/zqfang/QPCR "GitHub - zqfang/QPCR: Calculate the Delta_Ct, Delta_Delta_Ct , Fold ..."
[3]: https://toptipbio.com/delta-delta-ct-pcr/ "How To Perform The Delta-Delta Ct Method - Top Tip Bio"
Delta_Delta_Ct方法是一种常用的分析qpcR数据的方法,它可以计算样本的相对基因表达量。1
你可以使用qpcr这个python包来进行Delta_Delta_Ct分析,它提供了一系列的处理类,可以从csv或excel文件中读取原始Ct值,然后进行分析和可视化。2
你也可以参考QPCR这个github项目,它提供了两个python脚本,可以计算Delta_Ct, Delta_Delta_Ct, Fold Changes, Student’s t-test, and P-value等指标。3
你想看看这些脚本的具体代码吗?
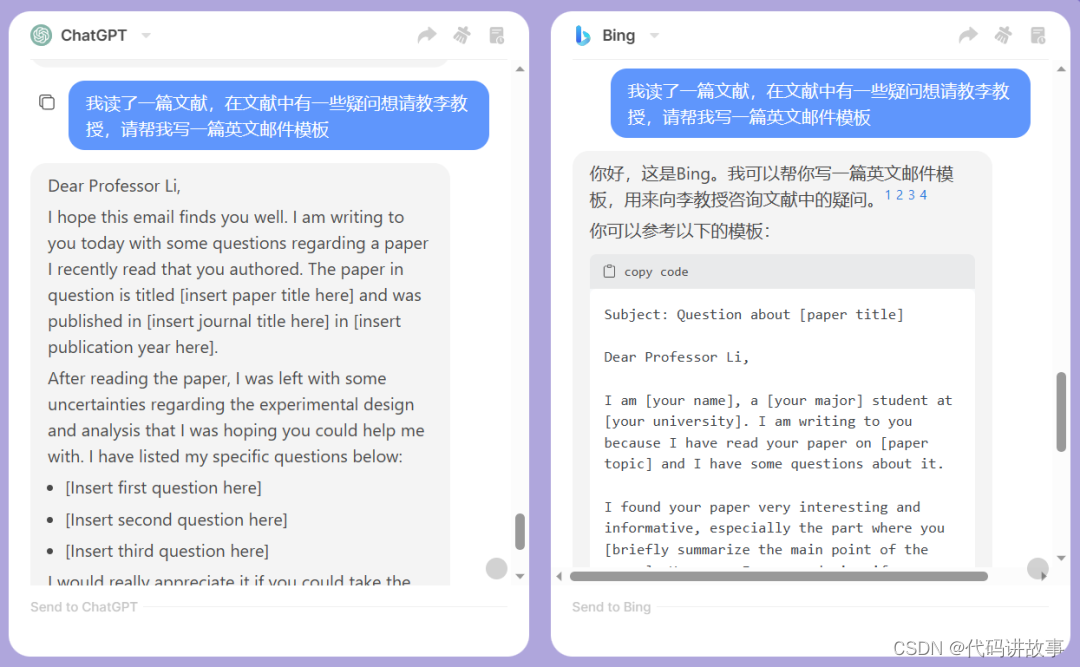
- 写邮件
问:我读了一篇文献,在文献中有一些疑问想请教李教授,请帮我写一篇英文邮件模板。
你觉得写得怎么样。
答:
Subject: Question about [paper title]Dear Professor Li,I am [your name], a [your major] student at [your university]. I am writing to you because I have read your paper on [paper topic] and I have some questions about it.I found your paper very interesting and informative, especially the part where you [briefly summarize the main point of the paper]. However, I was wondering if you could clarify some points for me.[Here you can list your questions, one by one, in a clear and polite way. For example:]- How did you choose the sample size for your experiment?
- What were the limitations of your methodology?
- How do you explain the discrepancy between your results and those of [another paper]?I would appreciate it if you could answer my questions or direct me to some relevant sources. I am very interested in learning more about your research and its implications for [your field of study].Thank you for your time and attention.Sincerely,
[your name]
[your email address]

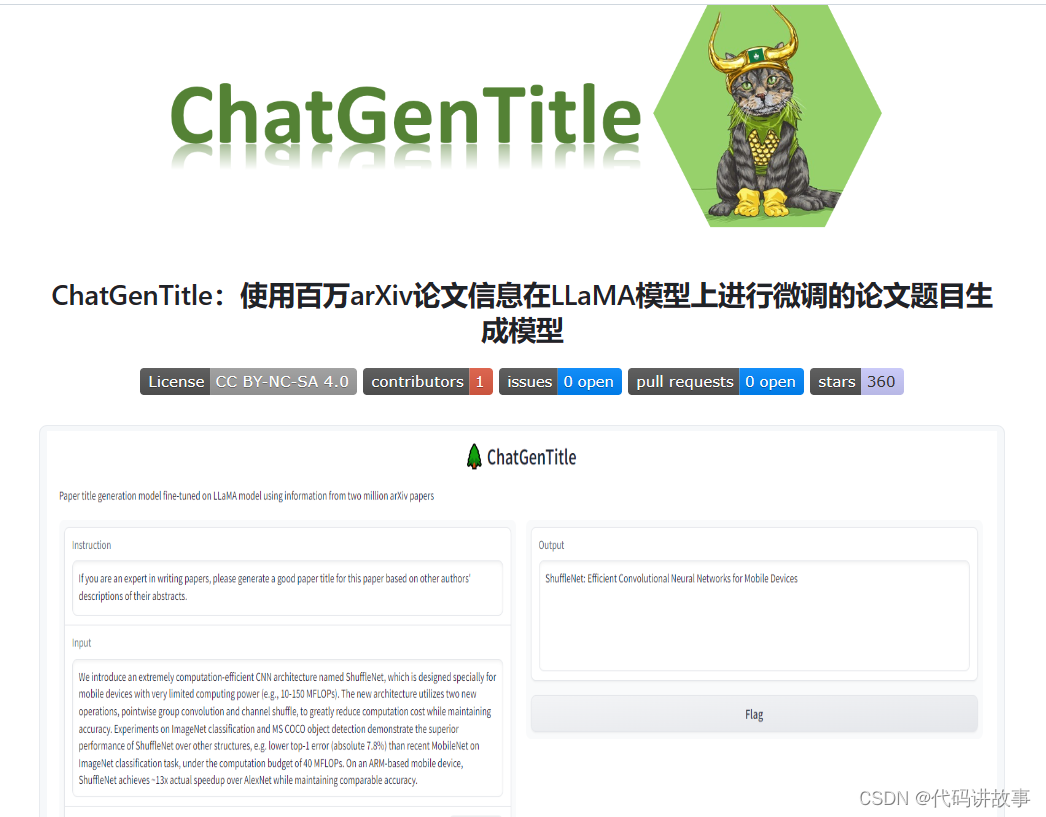
- 论文写作和润色
1)给文章起标题
有利用 LLAMA大模型 API开发的工具,github.com/WangRongsheng/ChatGenTitle
当然也可以自己写几个,让他帮忙改。
2)论文润色
同样有现成的工具chatPaper 1w star
github.com/kaixindelele/ChatPaper
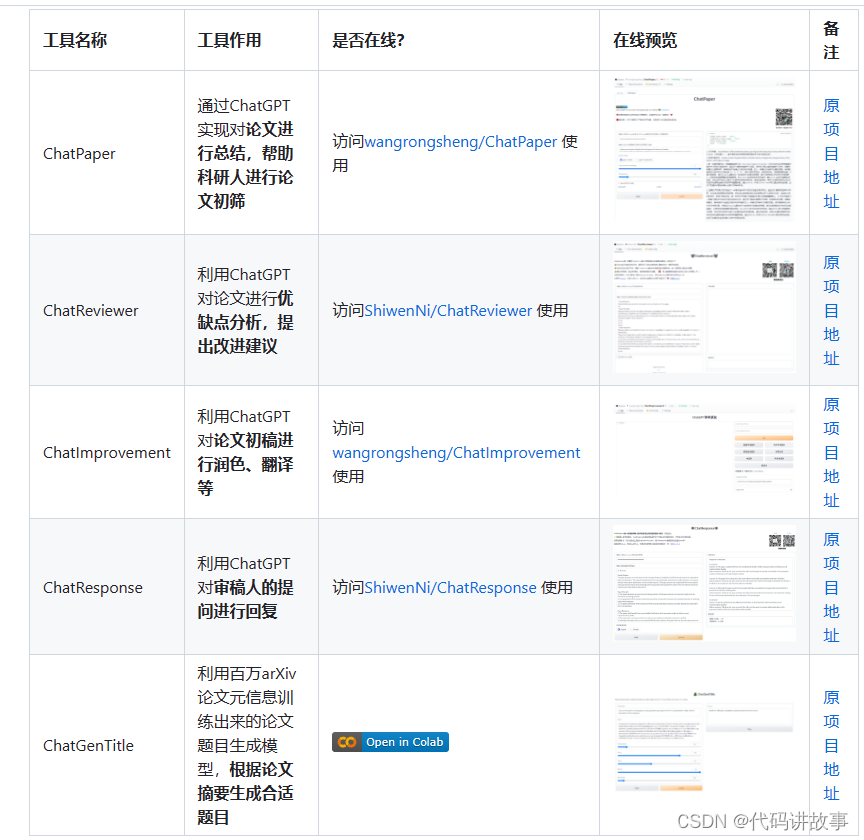
上面是利用 LLAMA大模型 实现的科研方面的功能,包括
这些东西我可以教你们如何使用和部署,如果同意上面的投票提出的方案。
阅读论文,总结论文 https://github.com/kaixindelele/ChatPaper
论文优缺点分析,提出建议 https://github.com/nishiwen1214/ChatReviewer
论文初稿的润色,翻译 https://github.com/binary-husky/ LLAMA大模型 _academic
回复审稿人 https://github.com/nishiwen1214/ChatReviewer
生成论文题目 https://github.com/WangRongsheng/ChatGenTitle
- 审稿件或者给自己的文章撰写提出建议和意见
LLAMA大模型 对于可以提升科研的效率,尤其对于一些陌生的领域,没有人带你,全靠自己摸索,将其称为你的虚拟导师也不为过,希望大家都可以尝试使用一下这个工具,我现在每天没有这个工具,可能都不会搞科研了。
以下是一些使用 LLAMA大模型 提高科研效率的开源项目,以及它们的简单介绍和链接:
-
ChatReviewer - 一个基于 LLAMA大模型 -3.5 API的论文自动审稿AI助手,可以对论文进行总结和评审,提高科研人员的文献阅读和理解效率。
- GitHub链接:ChatReviewer
-
ChatPaper - 使用 LLAMA大模型 总结arXiv论文的工具,帮助用户快速了解论文内容。
- GitHub链接:ChatPaper
-
** LLAMA大模型 _academic** - 中科院科研工作专用 LLAMA大模型 ,优化学术Paper润色体验,支持自定义快捷按钮,markdown表格显示,Tex公式双显示,代码显示功能。
- GitHub链接:[ LLAMA大模型 _academic](https://github.com/binary-husky/ LLAMA大模型 _academic)
-
Humata - 为PDF文件而生的GPT,可以将论文PDF拖入网页,然后通过对话框询问与论文相关的内容。
- GitHub链接:Humata
-
ChatPDF - 类似于Humata,可以“通读”PDF文档并回答问题。
- GitHub链接:ChatPDF
-
PandaGPT - 结合了Humata和ChatPDF的优点,提供prompt参考,并在回答中给出页码链接。
- GitHub链接:PandaGPT
-
** LLAMA大模型 Shortcut** - 整理并汇总了多种让生产力加倍的 LLAMA大模型 快捷指令,按照领域和功能分区。
- GitHub链接:[ LLAMA大模型 Shortcut](https://github.com/rockbenben/ LLAMA大模型 -Shortcut)
-
** LLAMA大模型 Web UI** - 为 LLAMA大模型 API提供Web图形界面,支持实时显示回答、重试对话等功能。
- GitHub链接:[ LLAMA大模型 Web UI](https://github.com/GaiZhenbiao/Chuanhu LLAMA大模型 )
-
OpenAI Translator - 基于 LLAMA大模型 API构建的划词翻译工具,支持多种语言的翻译、润色和总结功能。
- GitHub链接:OpenAI Translator
-
roomGPT - 通过上传房间照片或3D效果图,使用AI生成对应的梦幻房间效果图。
- GitHub链接:roomGPT
-
** LLAMA大模型 Academic** - 专门针对学术领域的 LLAMA大模型 ,帮助用户快速浏览文献,提供专业和可信的信息源。
- GitHub链接: LLAMA大模型 Academic
-
** LLAMA大模型 for Research** - 为科研人员设计的 LLAMA大模型 工具,提供文献搜索、数据分析、论文撰写等功能。
- GitHub链接:[ LLAMA大模型 for Research](https://github.com/research- LLAMA大模型 /research- LLAMA大模型 )
-
** LLAMA大模型 Code Assistant** - 使用 LLAMA大模型 辅助编程,提供代码建议、解释和优化。
- GitHub链接:[ LLAMA大模型 Code Assistant](https://github.com/code-assistant/ LLAMA大模型 -code-assistant)
-
** LLAMA大模型 Data Analysis** - 利用 LLAMA大模型 进行数据分析,提供数据可视化和统计分析建议。
- GitHub链接:[ LLAMA大模型 Data Analysis](https://github.com/data-analysis- LLAMA大模型 /data-analysis- LLAMA大模型 )
-
** LLAMA大模型 Time Management** - 使用 LLAMA大模型 创建研究计划和提醒,帮助科研人员更好地管理时间。
- GitHub链接:[ LLAMA大模型 Time Management](https://github.com/time-management- LLAMA大模型 /time-management- LLAMA大模型 )
-
** LLAMA大模型 Academic Writing** - 针对学术写作的 LLAMA大模型 工具,提供论文结构、编辑建议和润色服务。
- GitHub链接:[ LLAMA大模型 Academic Writing](https://github.com/academic-writing- LLAMA大模型 /academic-writing- LLAMA大模型 )
-
** LLAMA大模型 Research Ideas** - 利用 LLAMA大模型 生成新的研究问题、实验设计或研究方法。
- GitHub链接:[ LLAMA大模型 Research Ideas](https://github.com/research-ideas- LLAMA大模型 /research-ideas- LLAMA大模型 )
-
** LLAMA大模型 Literature Review** - 使用 LLAMA大模型 进行文献综述,快速了解研究领域的最新进展。
- GitHub链接:[ LLAMA大模型 Literature Review](https://github.com/literature-review- LLAMA大模型 /literature-review- LLAMA大模型 )
-
** LLAMA大模型 Experimental Design** - 协助科研人员设计实验,提供实验方法和数据分析建议。
- GitHub链接:[ LLAMA大模型 Experimental Design](https://github.com/experimental-design- LLAMA大模型 /experimental-design- LLAMA大模型 )
-
** LLAMA大模型 Research Communication** - 帮助科研人员撰写学术邮件、套磁信和审稿回复。
- GitHub链接:[ LLAMA大模型 Research Communication](https://github.com/research-communication- LLAMA大模型 /research-communication- LLAMA大模型 )
这篇关于0基础使用LLAMA大模型搞科研,自动阅读论文、代码修改、论文润色、稿件生成等等的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





